One database to rule them all with Bigtable hybrid transactional and analytical processing (HTAP)
Billy Jacobson
Developer Advocate: Bigtable
Generally speaking, databases handle two kinds of workloads: online transaction processing (OLTP) and online analytical processing (OLAP). For example, you might have an AI system that needs to be able to serve models and vectors in real time at scale with low latency — that’s an OLTP workload. At the same time, you might need to regularly perform batch uploads of new datasets and results from newly trained models — that’s OLAP. However, these types of workloads have conflicting requirements: OLTP require delivering a large number of concurrent queries for a small amount of data at low latency while OLAP workloads involve a small number of concurrent queries accessing a large amount of data without as much latency sensitivity.
Google Bigtable is a fully managed, NoSQL database service that’s used across financial, healthcare and retail industries for storing and accessing large amounts of data. Recently, we’ve added distributed counters, request priorities, write flow control, and Data Boost features to Bigtable that help you perform both OLAP and OLTP with a single database more easily, also know as hybrid transactional and analytical processing, or HTAP. The new features allow you to spread your batch jobs out over time with greater reliability and reduced operational management, use fewer resources and avoid impact on your serving workload.
In fact, HTAP benefits from working against a single data source — there’s one source of truth for your data, you don't need to run pipelines to move the data around for different use cases, you can access real-time data in your batch jobs, etc. Historically, analytical queries impacted OLTP-type serving workloads, so you needed to heavily over-provision serving systems or duplicate data to another database. Those solutions add cost, management overhead and data inconsistency problems.
In this blog post, we discuss best practices for improving hybrid services to reduce your Bigtable total cost of ownership (TCO), how to use these new features, and how they operate.
Best practices for hybrid services
Bigtable is a unique database: it can deliver low-latency point reads at high QPS, high scan throughput, and high write throughput, all in one convenient package. Some systems use Bigtable for a single access pattern, but it is common for a cluster to serve mixed workloads.
Here are some recommended strategies for a high-performance hybrid setup. You may need to use a combination of them to achieve the best performance, and the recently launched request prioritization, flow control, and Data Boost features are complimentary to the existing strategies.
Data Boost
For read-only workloads that don’t have strict latency requirements like such as analytics or ML training, you can use Data Boost, which provides a direct pathway to your underlying Bigtable data without using compute resources that are optimized for low-latency operations.
To enable Data Boost for your workload, use a Data Boost enabled application profile. You can create a new profile or update an existing one, so in many cases you won't even have to modify your code or stop your pipelines.
Distributed counters
Bigtable’s aggregate types allow fast and efficient incremental updates optimized for counting, set operations and statistics over streaming data, simplifying use cases that typically require complex Lambda architectures. Aggregates support multi-cluster routing and should be preferred over ReadModifyWrite when possible for best performance. They can be used on any table alongside other column types, making it possible to combine content serving and real-time analytics in a single database.
Request prioritization
Set request priorities on your application profile to tell your Bigtable instance how to handle incoming requests. Bigtable supports three different priority levels that can be set on an app profile:
-
PRIORITY_HIGH
-
PRIORITY_MEDIUM
-
PRIORITY_LOW
Requests with higher priorities are executed before requests with lower priorities allowing heterogeneous workloads on a Bigtable instance with better performance for high-priority workloads.
Request priorities don't provide total isolation like Data Boost but support both reads and writes. They also use already provisioned nodes with no additional cost whereas Data Boost uses additional compute resources. If the traffic is more than your provisioned nodes can handle, they will begin throttling low-priority requests. For some low-priority workloads, throttling is allowable, but if you need consistent high throughput, use Bigtable autoscaling to provision more nodes before throttling occurs.
Autoscaling with flow control
Bigtable clusters can be configured with autoscaling based on CPU utilization. The Bigtable service adds or removes nodes within a set limit to stay under your CPU utilization target threshold. Most jobs work well with Bigtable autoscaling, but batch write jobs that perform high-throughput writes with minimal ramp-up can cause an issue. For optimal performance with scaling, we recommend following the 10000/10/1 rule: starting at 10K QPS, increase traffic by 10% every minute. Flow control is an additional feature that solves this issue by rate-limiting writes during scaling.
Flow control pairs with autoscaling to steadily increase write traffic and trigger Bigtable autoscaling without overloading the cluster. This increases the job success rate, improves performance, and reduces impact to serving traffic. Once more nodes are added, throttling is reduced.
Pre-scaling
It is common to be able to anticipate a significant change in workload traffic: a daily batch job that runs after midnight or a business event that results in escalated platform use.
If you intend to grow faster than the 10000/10/1 rule, it may be useful to scale your cluster in advance to prepare your Bigtable instance for this step up in traffic. Leverage Bigtable performance guidelines to determine the number of nodes you think you will need. When using autoscaling this means raising your minimum node configuration. Bigtable autoscaling continues to automatically adjust the size of your clusters to meet your workload needs.
Pre-scaling your workload can work seamlessly along with request priorities and flow control to ensure the desired level of performance.
Technical architecture: Flow control and request priorities
The flow control feature rate-limits write requests to Bigtable to help ensure the job's success.
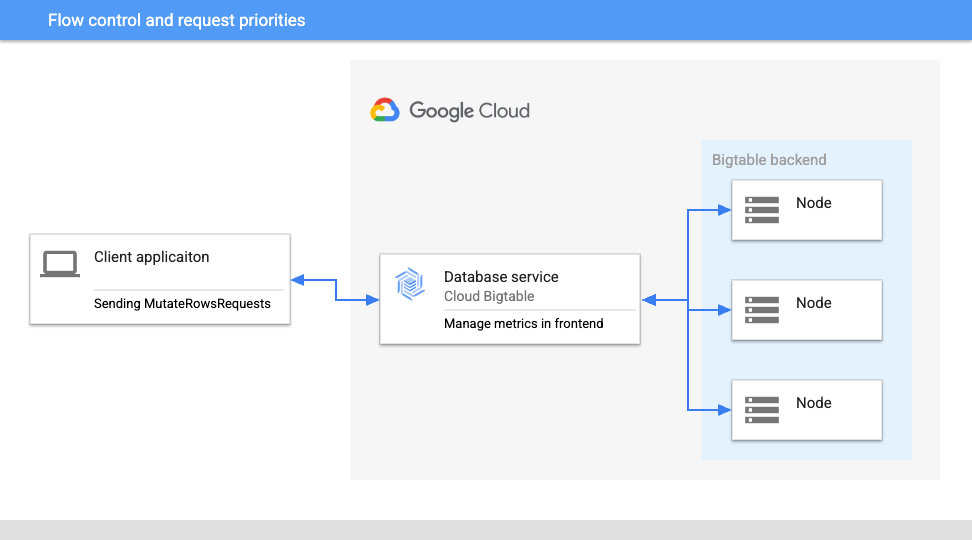
The Bigtable service frontend server monitors system capacity and sends recommended traffic adjustments to the client. Then, the client can increase or throttle the outgoing requests based on that information. In a Dataflow job importing data to Bigtable, Dataflow stops fetching new elements when requests need to be throttled, so a large queue of data doesn’t build up in worker memory.
Best practices in action
Using request priorities and write flow control requires minimal changes to your code. Create an app profile with a low request priority then use that app profile for your batch write jobs.
Here is an example setting the app profile for a Dataflow job that will be writing to Bigtable.
Use caution when running multiple batch jobs in a cluster if you don't use low-priority app profile routing on all of them. Since the flow control is determined by your cluster's resources, one job could "starve" another by hogging all the resources and claiming them before your other job can.
To find the correct configuration in Dataflow involves a bit of experimentation due to variety in workloads. In general, more Dataflow workers and a higher Bigtable autoscaling maximum can let the run job faster. We recommend performing a trial run with a smaller dataset or test table. Monitor your Dataflow cluster utilization, and then adjust the maximum number of Dataflow workers and Bigtable autoscaling configuration accordingly.
Next steps
Now, you should be familiar with the new features for hybrid services on Bigtable and better understand how to achieve the best performance with these features. Here are some next steps to take these techniques and features and implement them in your application:
-
Read more about flow control in the product documentation
-
Update your client to the latest version and enable flow control on your batch jobs
-
Learn how to configure request priorities on your application profiles
-
Read about how autoscaling could help you cut costs for Bigtable
-
Learn more about building distributed counters with Bigtable


