MakerBot が Cloud SQL により革新的な自動スケーリング ソリューションを実装
Google Cloud Japan Team
※この投稿は米国時間 2020 年 12 月 11 日に、Google Cloud blog に投稿されたものの抄訳です。
編集者注: この記事は、デスクトップ 3D プリントの業界パイオニアである MakerBot の語ったものです。同社のハードウェアのユーザーとコミュニティのメンバーは、3D モデルに簡単にアクセスできる方法を必要とし、IT チームは保守作業から解放されて製品の革新に集中することを必要としていました。同社が Google Cloud に移行して、どのように時間を節約し、優れたサービスを提供できるようになったのかを紹介します。
MakerBot は、広い層の顧客が使用可能で低コストな 3D プリントを最初に発売した会社の一つです。当社は現在、全世界の 3D プリンタで最大のインストール ベースを持つ会社の一つで、世界最大の 3D 設計コミュニティを運営しています。このコミュニティである Thingiverse は、3D プリントが可能なものの検索、作成、共有のハブとなっています。Thingiverse のアクティブ ユーザーは 200 万人を超え、このプラットフォームを使用して新規と既存の 3D モデルのアップロード、ダウンロード、カスタマイズを行っています。
2019 年にデータベースを移行するまで、当社は Amazon Web Services の Aurora MySQL 5.6 で Thingiverse を運用していました。費用の削減と、技術の統合と安定化のため、当社は Google Cloud への移行を選択しました。現在では当社のデータは Google Cloud SQL に保存され、アプリケーションは当社独自の AWS Kubernetes クラスタの代わりに Google Kubernetes Engine(GKE)で実行されるようになりました。Cloud SQL のフルマネージド サービスと機能により、当社はクリエイティブなレプリカの自動スケーリングの実装など革新的な重要ソリューションに集中できるようになり、安定した予測可能なパフォーマンスが得られるようになりました(この点については、後でもう少し説明します)。
支援によって移行がより簡単に
移行自体にも困難はありましたが、Google Cloud プレミア パートナーである SADA により労力は大幅に低減されました。当時の Thingiverse データベースは当社のロギング エコシステムに結合されていたため、Thingiverse データベースが停止すると MakerBot のエコシステム全体に影響が及ぶ可能性がありました。当社は Aurora から Google Cloud へのライブ複製を設定し、読み取りと書き込みが AWS に送られ、そこから Cloud SQL の外部マスター機能を使用して Google Cloud に転送されるように設定しました。
当社の現行のアーキテクチャには 3 つの MySQL データベースが含まれ、それぞれが Cloud SQL インスタンス上に配置されています。最初のデータベースは以前のアプリケーション用のライブラリで、今後は使用されなくなっていく予定です。2 番目のデータベースには、主な Thingiverse ウェブレイヤのデータであるユーザー、モデル、それらのメタデータ(そのデータが S3 のどこで見つけられるかや、gif のサムネイルなど)、ユーザーとモデルとの関係などが保存され、データ量は約 163 GB です。
最後に、当社は 3D モデルについてダウンロード数、モデルをダウンロードしたユーザー、モデルに調整が加えられた回数などの統計データを保存しています。このデータベースのデータ量は約 587 GB です。当社は VM 上の ProxySQL を利用して Cloud SQL にアクセスします。アプリのデプロイについては、フロントエンドを Fastly に、バックエンドを GKE にホストしています。
安全なマネージド サービス
MakerBot にとって Cloud SQL のマネージド サービスに関する最大の利点は、その動作について心配する必要がないことです。当社はデータベース管理や MySQL サーバーの構築に煩わされることなく、自社組織に大きく影響するエンジニアリングの問題に集中できます。これは、フルタイムの DBA を雇ったり、エンジニアを 3 人増やしたりするよりも費用対効果の高いソリューションです。当社が MySQL クラスタの構築、ホスティング、モニタリングに時間を費やす必要はなく、それらの作業は Google Cloud により行われ、介入は不要です。
データベースのセットアップの高速化
現在では、開発チームが新しいアプリケーションをデプロイするとき、必要なパラメータを含むチケットを作成します。その後で Terraform でコードが作成され立ち上げられて、チームはデータベースで自分のデータにアクセスを許可されます。チームのコンテナがデータベースにアクセスできるため、チームは必要に応じて読み書きを行えます。Cloud SQL への移行によって大幅にプロセスが自動化され、現在ではデータベースへの権限を約 30 分で与えることができるようになっています。
Cloud SQL には現在のところ自動スケーリングが組み込まれていませんが、Cloud SQL の機能を使用すれば自動スケーリングを実現することは可能です。
当社の自動スケーリング実装
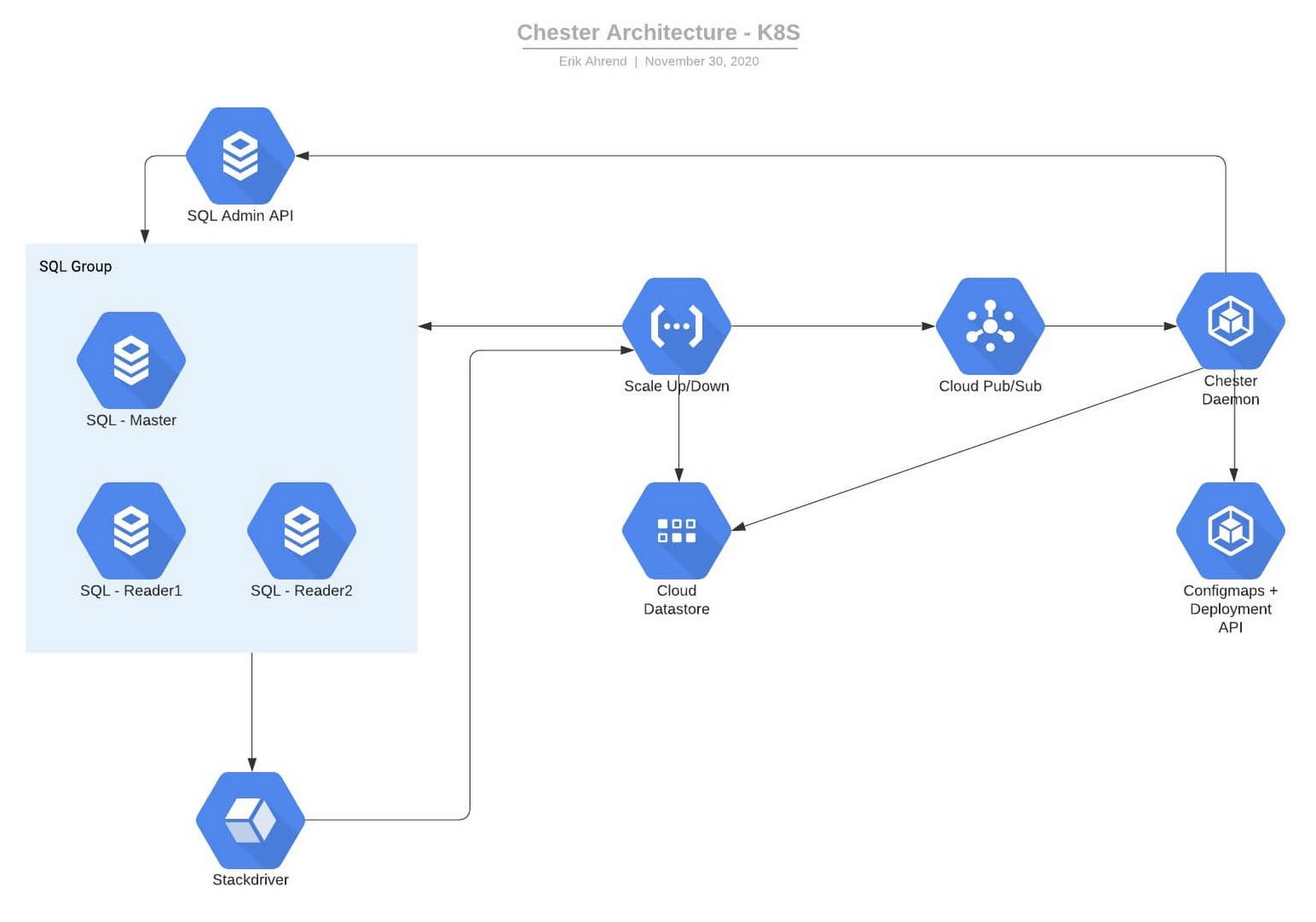
これが当社の自動スケーリング ソリューションです。この図には、メインと他の読み取り専用レプリカを持つ Cloud SQL データベースが示されています。これらのレプリカのインスタンスは複数存在でき、各アプリケーションは ProxySQL を利用してさまざまなデータベースにアクセスします。自動スケーリングの最初のステップはモニタリングの更新です。各データベースには固有のアラートが存在します。そのアラートのドキュメントには、インスタンスとデータベースの名前を指定する JSON 構造体が含まれています。
イベントがトリガーされると、Cloud Monitoring によって Google Cloud Functions への Webhook が起動され、Cloud Functions がインシデントに関するデータと Cloud SQL インスタンス自体を Datastore に書き込みます。Cloud Functions は、Pub/Sub にもこれらを送信します。GKE 内には ProxySQL 名前空間とデーモン名前空間が存在します。ProxySQL サービスが存在し、ProxySQL ポッドのレプリカの組を指し示します。ポッドが起動するたびに、Kubernetes 構成マップ オブジェクトから構成を読み取ります。複数のポッドを使用して、これらのリクエストを処理できます。
デーモンポッドは Pub/Sub からリクエストを受信し、Cloud SQL をスケールアップします。デーモンは Cloud SQL API を使用して、問題が解決するまでデータベース インスタンスで読み取りレプリカの追加と削除を行います。
ここに問題があります。ProxySQL をどのようにして更新すればいいのかです。ProxySQL は起動時にのみ構成マップを読み取るため、レプリカが追加されても ProxySQL ポッドはそれを認識しません。ProxySQL は起動時にのみ構成マップを読み取るため、Kubernetes API を使用してすべての ProxySQL ポッドのローリング再デプロイを行います。この動作はわずか数秒で行われ、これによって ProxySQL ポットの数を負荷に応じてスケールアップやスケールダウンすることもできます。
これは Google Cloud の機能を基礎とした将来の開発の一案にすぎません。Google Cloud の統合サービスが非常に的確に連係動作しているため、このような開発が簡単に行えます。Cloud SQL のフルマネージド サービスがデータベースの運用を行うので、当社のエンジニアは革新的でビジネスに重要なソリューションの開発とデプロイという業務に専念することができます。
MakerBot と Google Cloud のデータベース サービスの詳細をご覧ください。
-MakerBot、主任クラウド ソフトウェア アーキテクト Erik Ahrend


