MakerBot implements an innovative autoscaling solution with Cloud SQL
Erik Ahrend
Lead Cloud Software Architect, MakerBot
Editor’s note: We’re hearing today from MakerBot, a pioneer in the desktop 3D printing industry. Their hardware users and community members needed easy access to 3D models, and IT teams needed to offload maintenance operations to focus on product innovation. Here’s how they moved to Google Cloud to save time and offer better service.
MakerBot was one of the first companies to make 3D printing accessible and affordable to a wider audience. We now serve one of the largest install bases of 3D printers worldwide and run the largest 3D design community in the world. That community, Thingiverse, is a hub for discovering, making, and sharing 3D printable things. Thingiverse has more than two million active users who use the platform to upload, download, or customize new and existing 3D models.
Before our database migration in 2019, we ran Thingiverse on Aurora MySQL 5.6 in Amazon Web Services. Looking to save costs, as well as consolidate and stabilize our technology, we chose to migrate to Google Cloud. We now store our data in Google Cloud SQL and use Google Kubernetes Engine (GKE) to run our applications, rather than hosting our own AWS Kubernetes cluster. Cloud SQL’s fully managed services and features allow us to focus on innovating critical solutions, including a creative replica autoscaling implementation that provides stable, predictable performance. (We’ll explore that in a bit.)
A migration made easier
The migration itself had its challenges, but SADA—a Google Cloud Premier Partner—made it a lot less painful. At the time, Thingiverse’s database had ties to our logging ecosystem, so a downtime in the Thingiverse database could impact the entire MakerBot ecosystem. We set up a live replication from Aurora over to Google Cloud, so reads and writes would go to AWS and, from there, shipped to Google Cloud via Cloud SQL’s external master capability.
Our current architecture includes three MySQL databases, each on a Cloud SQL Instance. The first is a library for the legacy application, slated to be sunset. The second stores data for our main Thingiverse web layer—users, models, and their metadata (like where to find them on S3 or gif thumbnails), relations between users and models, etc—that has about 163 GB of data.
Finally, we store statistics data for the 3D models, such as number of downloads, users who downloaded a model, number of adjustments to a model, and so on. This database has about 587 GB of data. We leverage ProxySQL on a VM to access Cloud SQL. For our app deployment, the front end is hosted on Fastly, and the back end on GKE.
Worry-free managed service
For MakerBot, the biggest benefit of Cloud SQL’s managed services is that we don’t have to worry about them. We can concentrate on engineering concerns that have a bigger impact on our organization rather than database management or building up MySQL servers. It’s a more cost-effective solution than hiring a full-time DBA or three more engineers. We don’t need to spend time on building, hosting, and monitoring a MySQL cluster when Google Cloud does all of that right out of the box.
A faster process for setting up databases
Now, when a development team wants to deploy a new application, they write out a ticket with the required parameters, the code then gets written out in Terraform, which stands it up, and the team is given access to their own data in the database. Their containers can access the database, so if they need to read-write to it, it’s available to them. It only takes about 30 minutes now to give them a database, a far more automated process thanks to our migration to Cloud SQL.
Although autoscaling isn’t currently built into Cloud SQL, its features enable us to implement strategies to get it done anyway.
Our autoscaling implementation
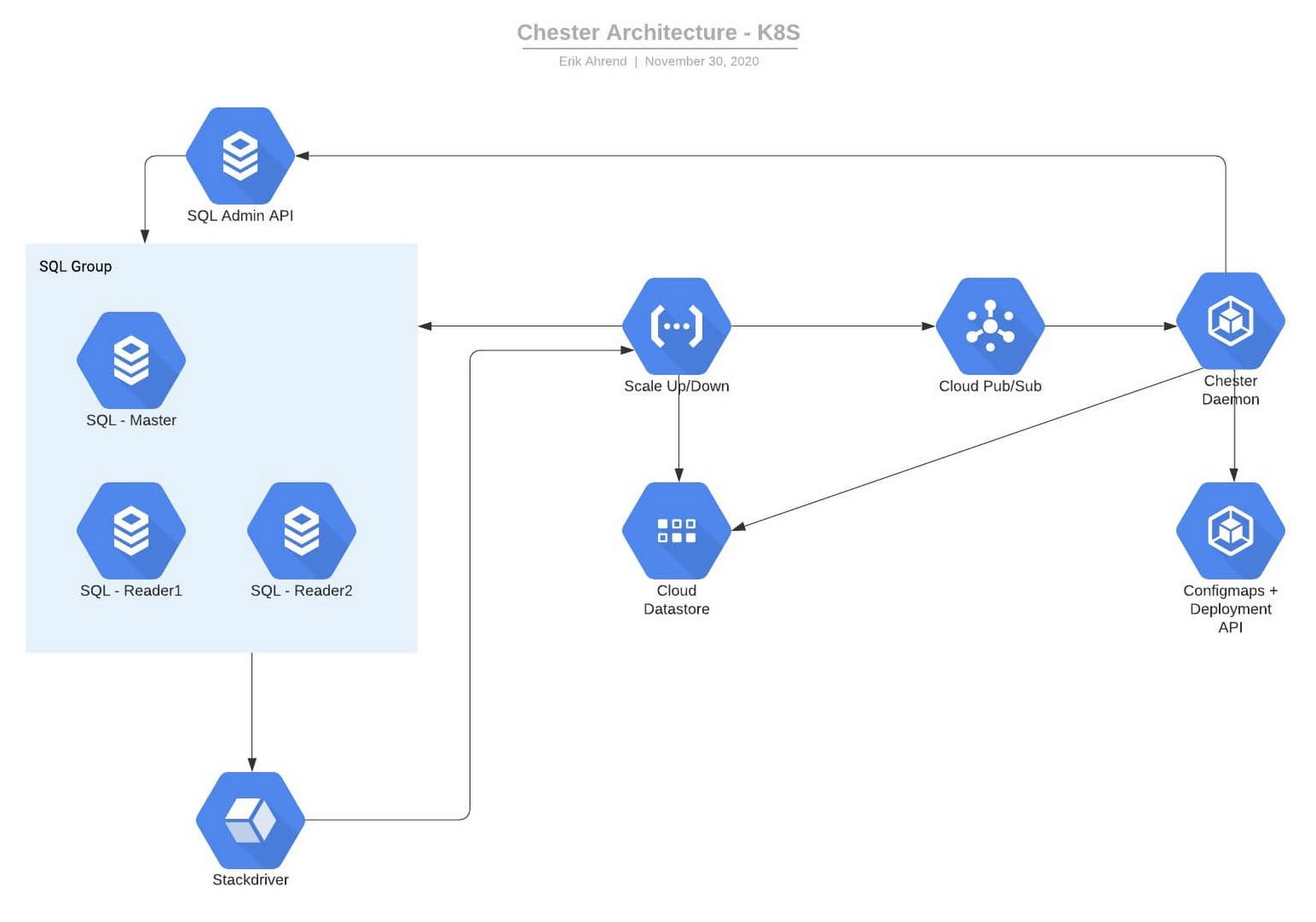
This is our solution for autoscaling. Our diagram shows the Cloud SQL database with main and other read replicas. We can have multiple instances of these, and different applications going to different databases, all leveraging ProxySQL. We start by updating our monitoring. Each one of these databases has a specific alert. Inside of that alert’s documentation, we have a JSON structure naming the instance and database.
When this event gets triggered, Cloud Monitoring fires a webhook to Google Cloud Functions, then Cloud Functions writes data about the incident and the Cloud SQL instance itself to Datastore. Cloud Functions also sends this to Pub/Sub. Inside GKE, we have the ProxySQL name space and the daemon name space. There is a ProxySQL service, which points to a replica set of ProxySQL pods. Every time a pod starts up, it reads the configuration from a Kubernetes config map object. We can have multiple pods to handle these requests.
The daemon pod receives the request from Pub/Sub to scale up Cloud SQL. With the Cloud SQL API, the daemon will add/remove read replicas from the database instance until the issue is resolved.
Here comes the issue—how do we get ProxySQL to update? It only reads the config map at start, so if more replicas are added, the ProxySQL pods will not be aware of them. Since ProxySQL only reads the config map at the start, we have the Kubernetes API perform a rolling redeploy of all the ProxySQL pods, which only takes a few seconds and this way we can also scale up and down the number of ProxySQL pods based on load.
This is just one of our plans for future development on top of Google Cloud’s features, made easier by how well all of its integrated services play together. With Cloud SQL’s fully managed services taking care of our database operations, our engineers can get back to the business of developing and deploying innovative, business-critical solutions.
Learn more about MakerBot and about Google Cloud’s database services.



