Bigtable への SQL サポート導入によりデベロッパー エクスペリエンスを変革
Christopher Crosbie
Group Product Manager
Gary Elliott
Engineering Manager, Bigtable
※この投稿は米国時間 2024 年 8 月 3 日に、Google Cloud blog に投稿されたものの抄訳です。
Bigtable は高速で柔軟な NoSQL データベースであり、検索、Google 広告、YouTube といった Google のコアサービスや、プレイドやメルカリなどのお客様向けの重要なアプリケーションを支えています。このたび、Bigtable で GoogleSQL がサポートされるようになったことをお知らせします。GoogleSQL は、Spanner や BigQuery などの Google プロダクトで使用される ANSI 準拠の SQL 言語です。これにより、Bigtable で同じ SQL を使用して、AI、不正検知、データメッシュ、レコメンデーションのアプリケーションをはじめ、リアルタイム データのメリットを活かせるあらゆるアプリケーションを作成できるようになりました。
Bigtable での SQL サポートにより、開発チームは、使い慣れた GoogleSQL 構文を使用して Bigtable データをクエリできるため、Bigtable の柔軟性とスピードをより簡単に活かせるようになります。リリース時点で 100 以上の SQL 関数を備えているため、Bigtable 内で簡単に大量のデータの分析や処理を直接行うことができ、ログ分析用の JSON 操作、ウェブ分析用の HyperLogLog、ベクトル検索や生成 AI 用の kNN など、幅広いユースケースへの対応が可能になります。
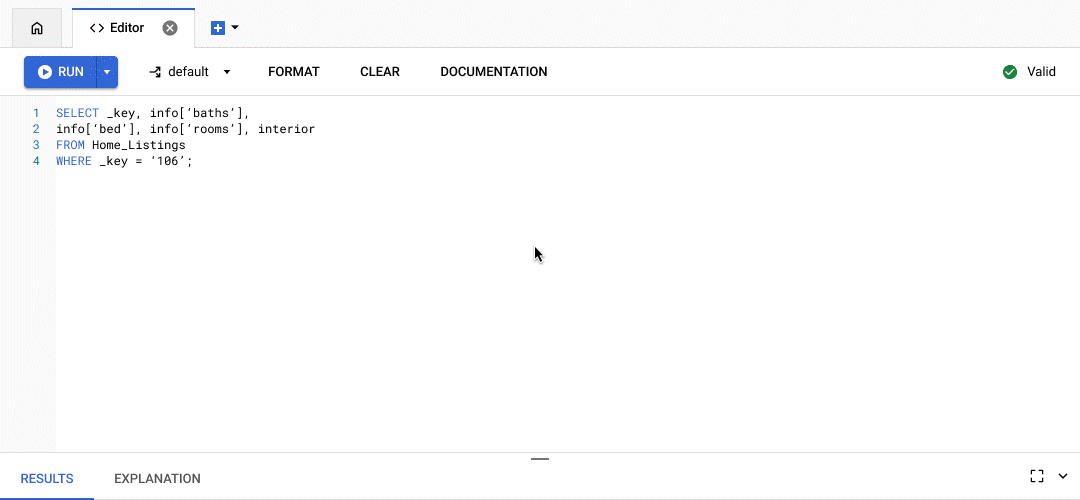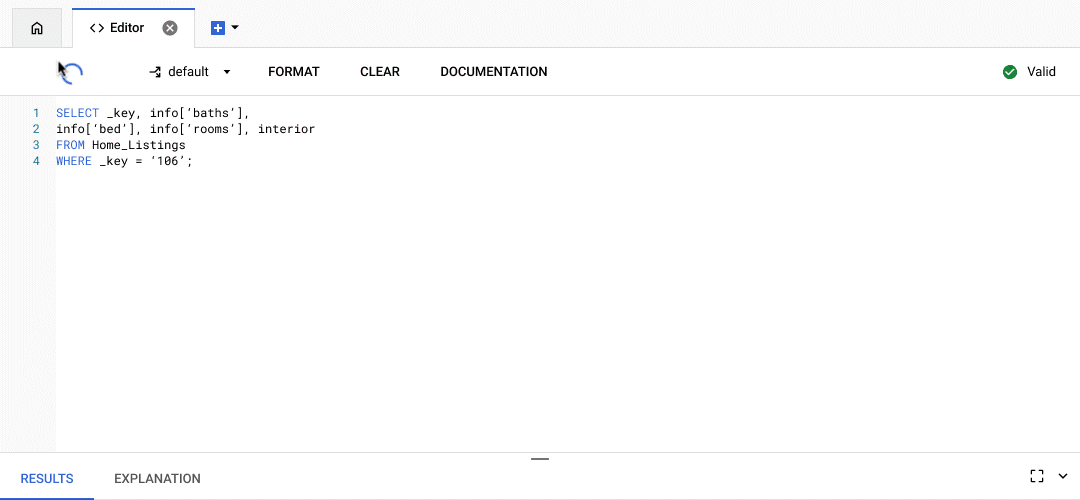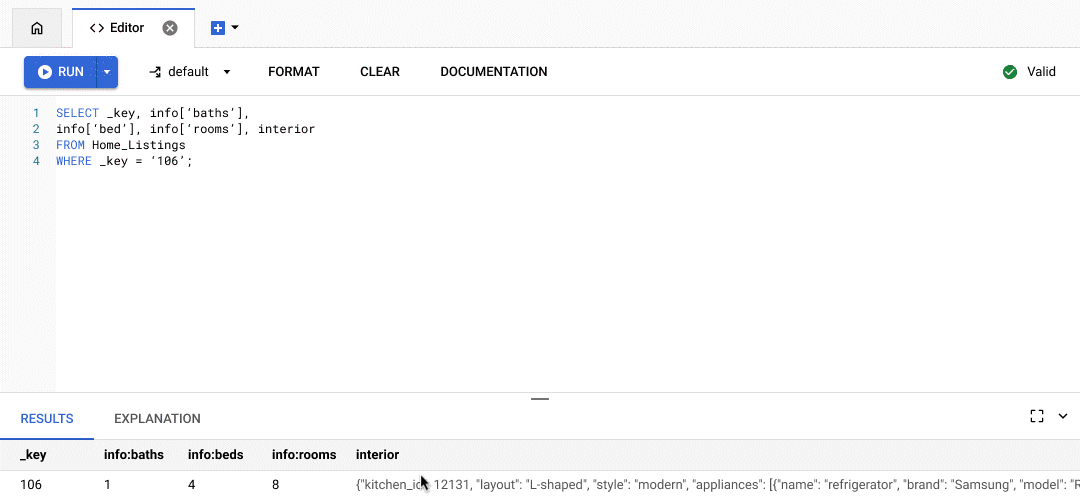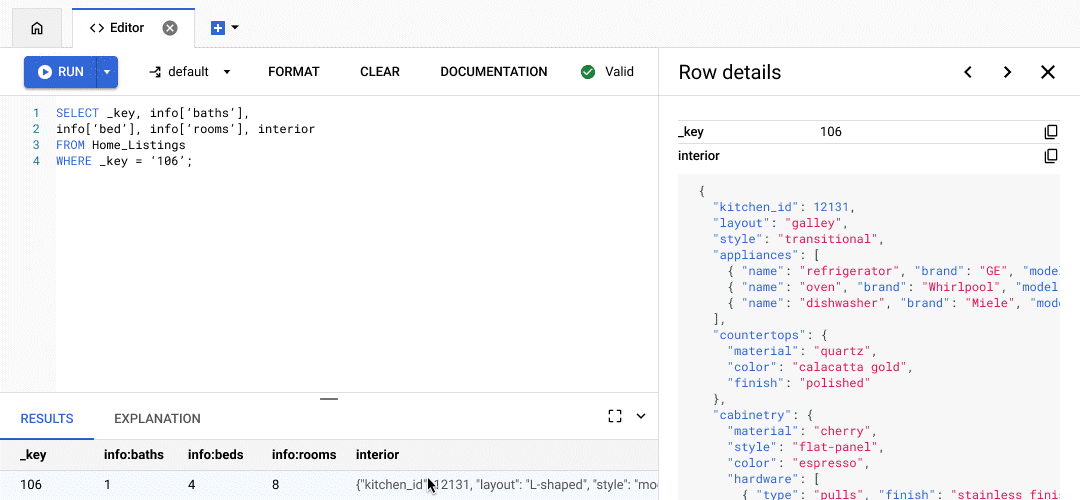
カスタマー エクスペリエンス(CX)ソリューションの大手プロバイダであるプレイドでは、Bigtable の強化された SQL サポートとカウンタが、開発者に画期的な変化をもたらしています。
「Bigtable のシームレスな SQL 統合と効率的なカウンタ機能のおかげで、お客様のためにより堅牢でスケーラブルなソリューションを構築できるようになります。当社は、Bigtable におけるイノベーションへの取り組みを称賛するとともに、これらの機能強化を活用することで、大規模かつ複雑で、めまぐるしく変化するデータの処理がシンプルになることを期待しています。」株式会社プレイド、執行役員兼エンジニアリング担当バイスプレジデント 日鼻 旬 氏
それでは、GoogleSQL が Bigtable のエクスペリエンスをどのように向上させるかを見ていきましょう。
NoSQL データベース用 SQL インターフェースの仕組み
Bigtable は、ビッグデータ ムーブメントの先駆的な技術の一つであり、Apache HBase や Cassandra などの人気のあるオープンソース プロジェクトに影響を与えています。その最たる特徴の一つが、ワイドカラム型データモデルであり、各行に、必要であれば数千もの列のセットを関連付けることができます。この柔軟性は多くのユースケースにとって有益ですが、SQL の起源である一般的なリレーショナル データベースとはまったく異なるデータモデルとアクセス パターンをもたらします。このため、何十年もの間、SQL が事実上のデータ マネジメント標準としてあらゆる開発者が備えるスキルであったにもかかわらず、ほとんどの NoSQL データベース システムは、独自の Key-Value 対応の API に頼らざるを得ませんでした。
Bigtable での SQL サポートでは、ワイドカラム型のデータ構造に対応する新しい型と関数が追加され、時系列機能で SQL を強化しています。Bigtable に SQL が導入されることで機能は拡張されますが、そのデフォルトの動作は、基本的なクエリが一般的な SQL に可能な限り近い動作をするように設計されています。しかしながら、Bigtable は依然として NoSQL システムであるため、スキーマ設計のベストプラクティスを使用してスキーマを最適化し、パフォーマンスを向上させる必要があります。したがって、低レイテンシでスケーラブルな NoSQL データベースを探しているが、新しいクエリ API を習得したくないといった場合に、データモデルの柔軟性を提供する Bigtable SQL が選択肢となります。
それでは、これらの機能拡張を利用して、SQL で柔軟なスキーマを実現する方法について詳しく見ていきましょう。
Map データ型による柔軟なデータモデルのサポート
Bigtable のワイドカラム型モデルには、行キーと、それぞれが列ファミリー内にグループ化された一連の値があります。これらの列ファミリーが SQL によってクエリされると、Bigtable は既存のテーブルを Map <key, value> の SQL 列のグループと行キーの _key 列として扱います。つまり、Bigtable の列ファミリーは SQL の Map データ型になります。
このアプローチにより、SQL の制約の中で柔軟なスキーマが維持されます。Bigtable の各行は、必要であれば、列ファミリー内で数千もの列を持つことができ、NULL 値のストレージに料金が発生することも、他のパフォーマンスの制約を受けることもなく、行によって完全に異なる列を持つことができます。
以下の例は、列ファミリー address 内から列属性 street を返す方法を示しています。
JSON
JSON もまた、柔軟で動的なデータを格納するためによく使用される形式です。Bigtable では、キー範囲に対して LIKE 演算子を使用することで、さまざまな JSON ドキュメントを迅速に取得できます。その後、GoogleSQL のさまざまな JSON SQL 関数を使用して、これらの JSON ドキュメントを操作できます。
たとえば、以下のクエリを使用して、session 列ファミリーの最新バージョンのデータから、JSON 属性 abc の値を行キーとともに取得できます。
タイムトラベルとバージョン履歴
Bigtable は、書き込みごとにタイムスタンプを取得します。これは、特定のアイテムの履歴をすぐに返したい場合に理想的なモデルであり、たとえば、センサーからの読み取り値を平均化したり、特定の商品の購入履歴を確認したりする場合に利用できます。また、列ファミリー内でグループ化されたアイテムに TTL を設定して、不要になったデータを削除するプロセスを自動化することもできます。
このパターンは便利ですが、各値が最後に書き込まれた値のみである従来の SQL テーブルとはまったく異なります。Bigtable SQLでは、デフォルトのレスポンスは、従来の SQL データベースで期待されるもの、つまり最後に更新された値のみが返されます。ただし、Bigtable SQL には履歴のコンセプトが導入されているため、過去のすべての結果を返すこともできます。
上記のクエリは、ユーザーの履歴全体における自宅の住所とともに、さまざまな変更がいつ行われたかを示すタイムスタンプを返します。
同様に、特定の時点の値をリクエストすることもできます。
この場合、以下の住所変更は 2020 年に行われ、次の変更は 2023 年まで行われなかったため、指定した 2022 年のタイムスタンプの時点での有効な値としてこの住所が返されます。
主なユースケース
このリリースで Bigtable の API に SQL サポートが加わったことで、さまざまなタイプのユーザーやユースケースに対応できるようになりました。この拡張は、SQL で効率的な運用システムを構築するアプリケーション デベロッパーや、GPU をフル活用して SQL クエリ リクエストに対する低レイテンシのレスポンスを求めるデータ サイエンティストのニーズに応えます。
ここでは、Bigtable で GoogleSQL を利用する最も一般的なシナリオのいくつかを紹介します。
-
NoSQL への移行: SQL のサポートにより、HBase や Cassandra などの他のワイドカラム型データベースからの移行が容易になります。GoogleSQL のサポートとワイドカラム型データモデルをサポートする拡張機能により、Cassandra の SQL に似たクエリ言語である CQL や、HBase 上の Apache Phoenix からの移行プロセスが大幅に簡素化されます。
「Globo では、SQL のサポートにより、これまで Cassandra に大きく依存していた Bigtable への移行が非常に容易になりました。」Globo、ソフトウェア エンジニア Michel Aquino 氏
-
インタラクティブで変化し続けるデータ: SQL へのワイドカラム型のアプローチにより、新しいデータポイントが出現したときに簡単に追加したり、古くなった情報を適切に削除したりできるため、進化するデータに対してアプリケーションの俊敏性と応答性を維持できます。
-
不均一なデータの低レイテンシでの検索: SQL を使用して、特定のキーで利用可能な情報の完全なコンテキストをすばやく取得することもできますが、各レコードには異なるフィールド セットが含まれています。異なるフィールドがある完全なコンテキストを低レイテンシで利用できることは、不正検出、RAG パイプライン、レコメンデーション エンジン、モデル トレーニングなどのリアルタイムの意思決定を行うアプリケーションに有用です。
-
BigQuery サービング レイヤ: BigQuery には、複雑な計算、データ操作、ML を実行するさまざまな機能が備わっています。しかし、非常に高い QPS、1 桁ミリ秒のレイテンシ、一定したレスポンス時間、グローバルなデプロイが必要な場合、この分析結果の配信が課題となることがよくあります。Ricardo などのお客様は、BigQuery と Bigtable サービング レイヤを組み合わせることで成功を収めています。事前に計算された BigQuery の結果を Bigtable に自動的に転送して、両方のシステムで SQL 言語を使用してデータを提供できます。
-
SQL ベースの時系列ソリューション: 測定値および測定値が記録された時刻で構成される大量のデータを取り込んでクエリする必要があるアプリケーションは、Bigtable のデータモデルを利用できます。時間データを操作する GoogleSQL の関数を使用して、費用対効果の高い方法でこのデータを収集、管理、分析できます。
-
書き込み時の集計: 書き込み時に値を集計する場合、Bigtable の分散カウンタを使用することで、値が大規模かつ世界中で正しく結合されるようにするための面倒な作業を処理できます。その後、HLL_COUNT.EXTRACT などの関数を含むシンプルな GoogleSQL の SELECT 句を使用して、これらの指標を表示できます。
使ってみる
Bigtable Studio に含まれている SQL エディタで SQL クエリを入力できます。
新しい SQL エディタのタブを起動するには、ランディング ページで <> [New Editor] ボタンをクリックします。
必要に応じて、[+] ボタンを使用してエディタ タブをさらに作成できます。
Bigtable SQL は、Java と Python のクライアント ライブラリからも利用できます。また、近日中にさらに多くのオプションが追加される予定です。
このプレビュー期間中は、SELECT ステートメントを使用した一般的な Key-Value のアクセス パターンをサポートすることに主眼を置いており、将来の機能の基盤を築くことを目的にしています。リレーショナル データベースで一般的な JOIN や GROUP BY などの操作はまだ利用できませんが、将来的にはできるようになる可能性があります。Bigtable の SQL サポートは、リアルタイム アプリケーションを開発するための包括的なアプリケーション ツールキットへと進化していきます。今後の機能強化にご期待ください。
詳細
ー Google、グループ プロダクト マネージャー Christopher Crosbie
ー Bigtable 担当エンジニアリング マネージャー Gary Elliott
