BigQuery で Gemini モデルを使用して顧客レビューの感情を読み解く
Nivedita Kumari
Data Analytics Customer Engineer
※この投稿は米国時間 2024 年 6 月 7 日に、Google Cloud blog に投稿されたものの抄訳です。
感情分析は、自然言語処理(NLP)を使用して、顧客レビューなどの文章の根底にある感情(肯定、否定、中立)を明らかにする優れたツールです。この分析により、顧客が自社のプロダクト、サービス、ブランド全体についてどのように感じているかについて貴重な分析情報が得られます。また、トピック モデリングやキーワード抽出といった手法を使用して、繰り返し現れるテーマを特定できます。このようなテーマの中で目立つプロダクトの特定の機能、カスタマー サービスの側面、一般的な課題を洗い出して、改善に向けたロードマップや、顧客のニーズに効果的に対処する方法を探ることができます。
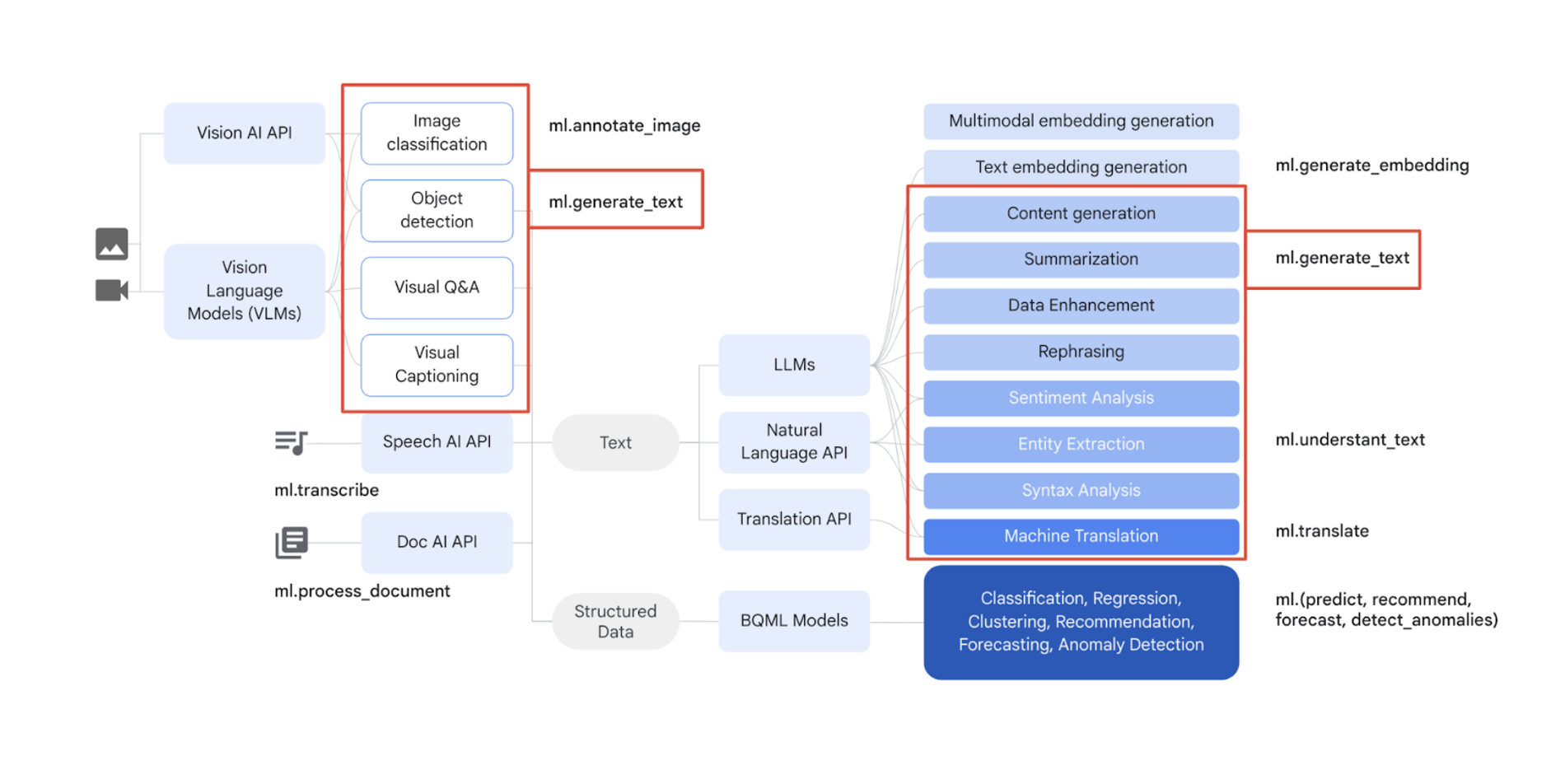
BigQuery の ML.GENERATE_TEXT 関数を使用すると、Google の Vertex AI が提供する高性能の大規模言語モデル(LLM)を SQL クエリ内で直接利用して、BigQuery テーブル内のテキストを分析できます。つまり、BigQuery 環境外にデータを移動することや複雑なコードを記述する必要なしに、BigQuery テーブルに保存されているデータに対して高度なテキスト生成タスクや分析タスクを実行できます。ML.GENERATE_TEXT 関数はまた、gemini-pro-vision マルチモーダル モデルをベースとするリモートモデルを使用して、ビジュアル コンテンツを説明するテキストを生成する場合にも使用できます。主に次のようなメリットがあります。
-
使いやすさ: BigQuery の SQL インテグレーションにより、別個の ML パイプラインやコーディングの専門知識の必要なく、高度な言語モデル機能を利用できます。
-
スケーラビリティ: BigQuery の強みである大規模なデータセットの処理と LLM を効果的に組み合わせることで、顧客レビューなどのテキストソースを大規模に処理できます。
-
分析情報生成: ML.GENERATE_TEXT を使用すると、以下のようなタスクを支援します。
-
感情分析: 顧客からのフィードバックの全体的な感情のトーン(肯定、否定、中立)を判断します。
-
テーマ抽出: レビューによく現れるトピックとトレンドを特定します。
-
要約: 長いレビューをキーポイントに集約します。
- テキスト補完と生成: 既存のレビューに基づいて、レスポンス、広告コピー、クリエイティブな文章の作成を支援します。
ML.GENERATE_TEXT の実例
次は、ML.GENERATE_TEXT の使用方法を見ていきましょう。架空のライドシェア企業を例にとります。
設定の手順:
-
開始する前に、GCP プロジェクトを選択し、請求先アカウントをリンクして、必要な API を有効にします。詳細な手順は、こちらをご覧ください。
-
クラウド リソース接続を確立し、接続のサービス アカウントを取得します。詳細なガイドは、こちらをご覧ください。
-
こちらの手順に沿って、サービス アカウントへのアクセスを許可します。
-
データを読み込みます。公開ストレージ アカウントから読み込むには、以下のコマンドを使用します。
-
- '[PROJECT_ID.DATASET_ID]' の部分を実際の project_id に置き換えて、データセットの名前を入力してください。
- このコマンドにより、データセット内に「customer_review」という名前でテーブルが作成されます。
感情分析
感情分析の実行例を順を追って見ていきましょう。
1. モデルを作成する
BigQuery に Vertex AI 基盤モデルを利用するリモートモデルを作成します。
構文:
サンプルコード:
-
'[PROJECT_ID.DATASET_ID.MODEL_NAME]'の部分を実際の project_id、dataset_id、モデル名に置き換えてください。 -
'[PROJECT_ID.REGION.CONNECTION_ID]' の部分を実際の project_id、リージョン、connection_id に置き換えてください。
2. テキストを生成する
作成したモデルと ML.GENERATE_TEXT 関数を使用すると、わずか数行の SQL で、BigQuery テーブル内のテキストやビジュアル コンテンツを分析できます。
ML.GENERATE_TEXT の構文は、リモートモデルがターゲットとする Vertex AI モデルによって異なります。ML.GENERATE_TEXT 関数のすべてのパラメータを確認する場合は、こちらのドキュメントをお読みください。
構文:
サンプルコード:
-
'[PROJECT_ID.DATASET_ID]'の部分を実際の project_id と dataset_id に置き換えてください。 '[PROJECT_ID.REGION.CONNECTION_ID]'の部分を実際の project_id、リージョン、connection_id に置き換えてください。
3. 結果:
プロンプトでコンテキストと 2 つの例をモデルに提供して、どのような形式で出力してほしいかを明確に伝えました。少数ショット プロンプト アプローチの一部としてモデルに提供した例に合わせて、生成された出力が調整されていることを確認できます。
少数ショット プロンプトでは、モデルの挙動を適切に導くために少数のレビュー例と一緒に対応する感情ラベルも含めることが重要になります。さまざまな状況でモデルが有効に機能するためには、多様なレビュー シナリオに対応した十分な数の例を適切に構造化して提供することが不可欠です。
次に、顧客レビューに対する感情分析を実行することで、顧客の嗜好に関する分析情報が得られるほか、プロダクトに関する課題を明らかにできます。レビューに現れる主なテーマを特定することで、有益なフィードバックをプロダクト チームに効果的に伝えることができます。チームは、十分な情報に基づいてデータドリブンな意思決定を下し、改善を図ることができます。
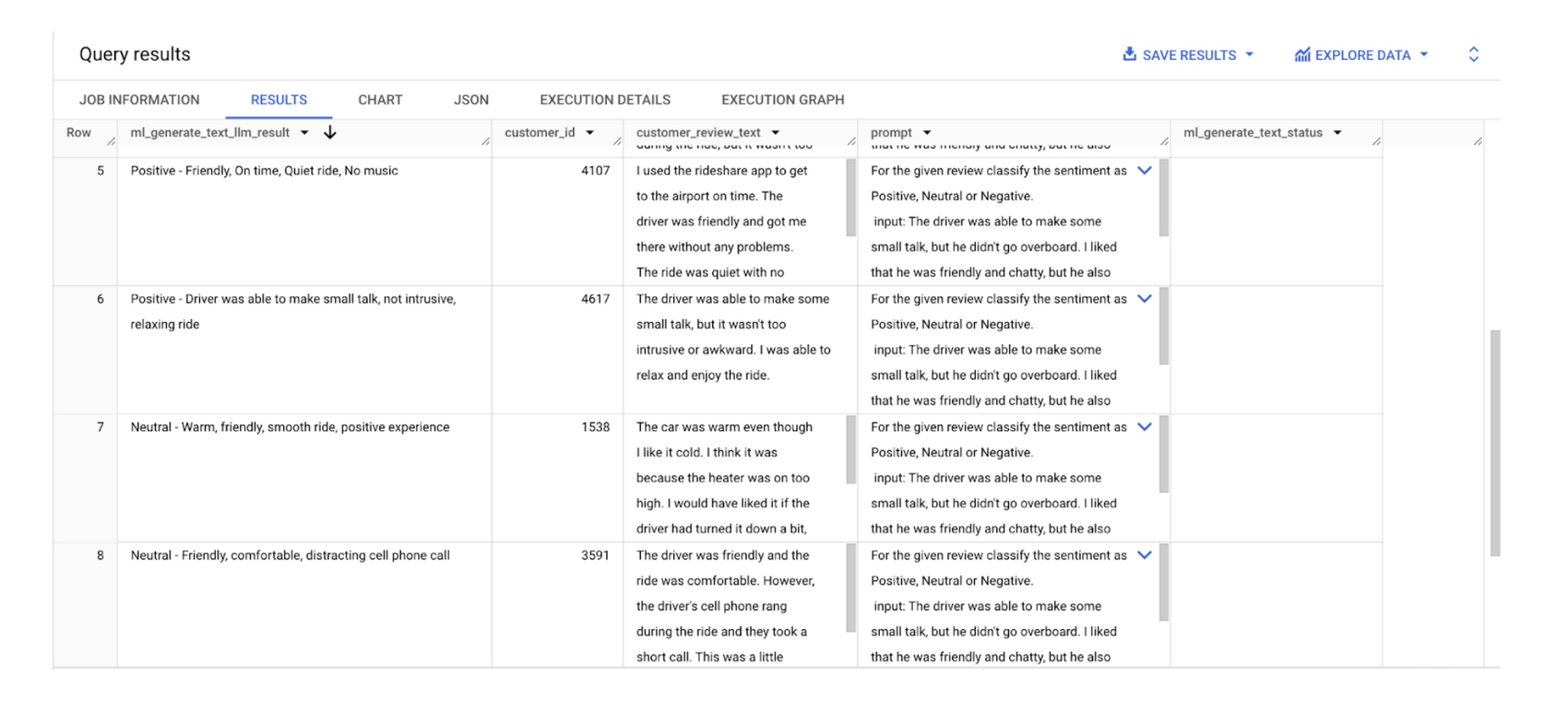
上記のテーブルで ML.GENERATE_TEXT の結果を確認できます。入力テーブルには以下の列が並んでいます。
-
ml_generate_text_result: これは JSON レスポンスであり、テキスト要素内にテキストが生成されます。
-
ml_generate_text_llm_result: 生成されたテキストが含まれている文字列値です。この列は、flatten_json_output が TRUE の場合に返されます。
-
ml_generate_text_rai_result: 安全性属性が含まれている文字列値です。この列は、flatten_json_output が TRUE の場合に返されます。
-
ml_generate_text_status: 対応する行の API レスポンス ステータスが含まれている文字列値です。オペレーションが成功した場合、この値は空になります。
テーマの抽出
次は、上記の手順で作成したモデルを使用して、レビューからテーマを抽出しましょう。
'[PROJECT_ID.DATASET_ID]'の部分を実際の project_id と dataset_id に置き換えてください。
結果:
BigQuery コンソールから ML.GENERATE_TEXT 関数と SQL を使用すると、顧客レビュー内の主なテーマを効率的に特定できます。これにより、顧客の認識に関する洞察を深め、プロダクトの改善に役立つ実用的なデータを得ることができます。
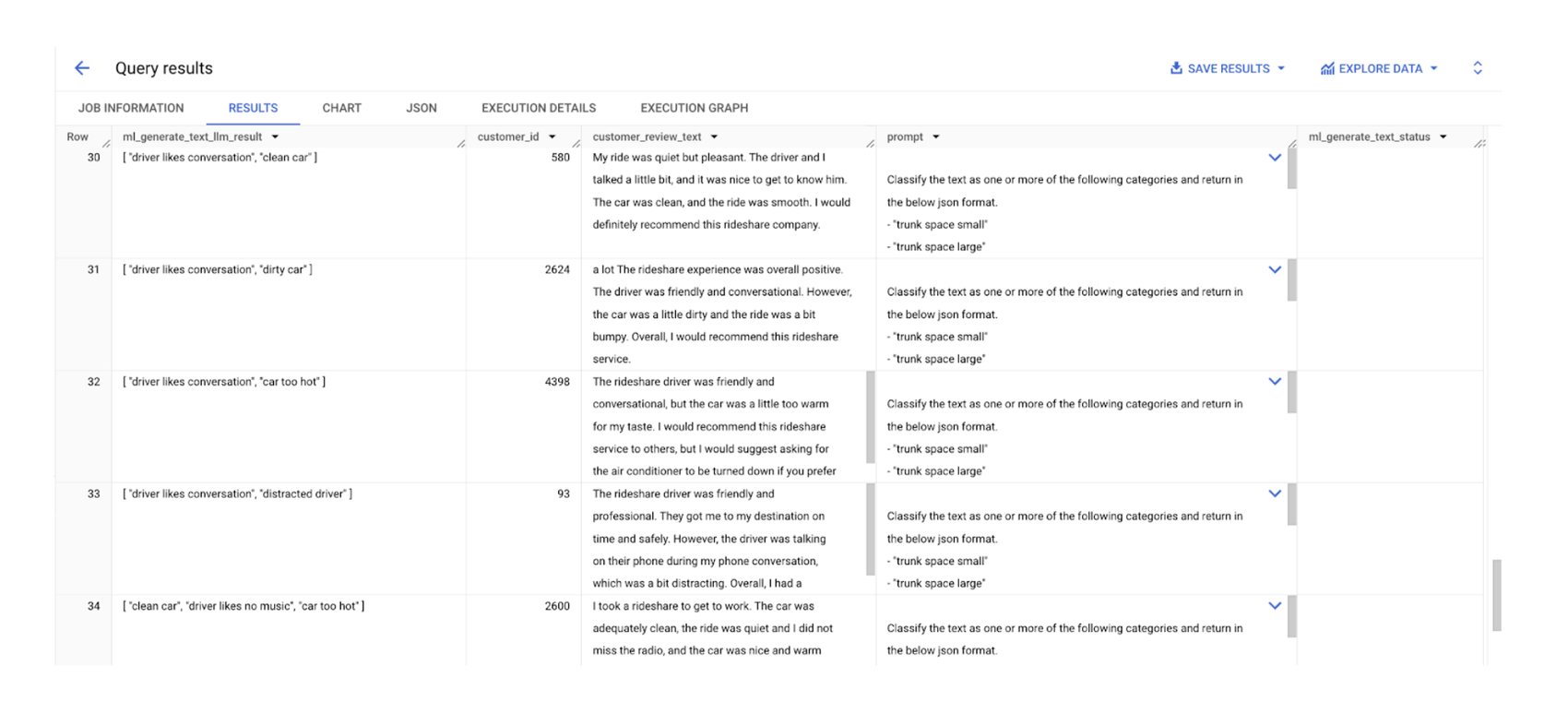
ML.GENERATE_TEXT は、Gemini モデルと密接に統合されています。このモデルは、入力 / 出力スケールを拡大して、分類や要約などのテキスト処理、感情分析、コード生成といった幅広いタスクで結果の質を高めるように設計されています。
テーマの分析
レビューに現れるテーマを特定してみたところで、今度は BigQuery のデータ キャンバスを使ってさらに掘り下げます。これは Google が Next' 24 で発表した、データ分析を刷新する AI 中心のエクスペリエンスです。BigQuery データ キャンバスを使用すると、自然言語を使用してデータを検出、変換、クエリ、可視化できます。また、グラフィカル インターフェースを使用してデータソース、クエリ、有向非巡回グラフ(DAG)の可視化を処理でき、メンタルモデルにマッピングされた分析ワークフローを確認できます。
テーマが「extract_themes」テーブルに保存されている前提で、さらに分析を進めるために、データ キャンバスを作成してみましょう。「+」アイコンの横にある下向き矢印をクリックし、[データ キャンバスを作成] を選択します。
「extract_themes」テーブルを検索できる画面が表示されます。早速、始めてみましょう。
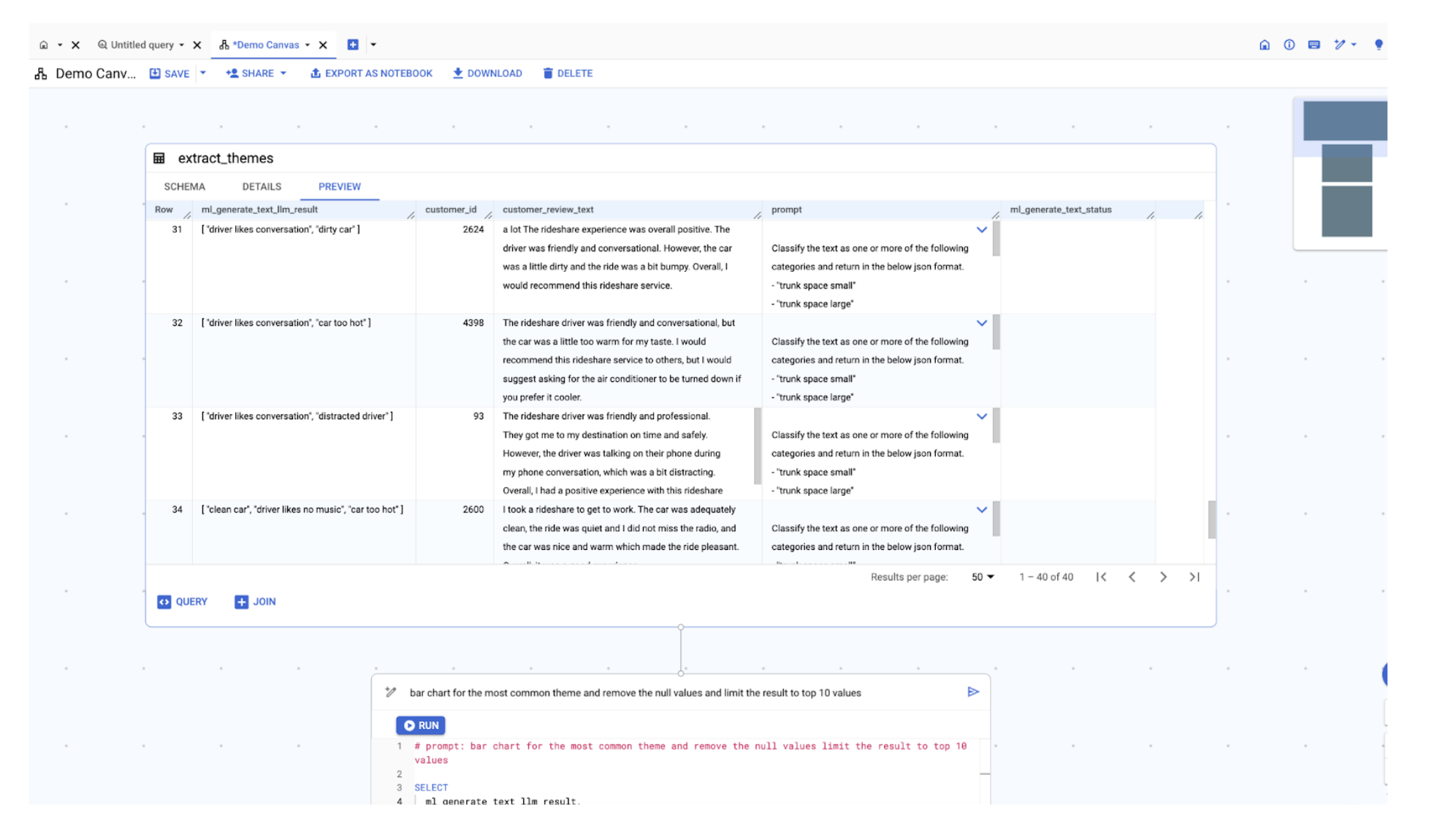
テーブルを選択すると、そのテーブルがキャンバスに表示されます。ここから直接テーブルにクエリを実行できるほか、他のテーブルと結合することもできます。
テーマの棒グラフを作成するには、[クエリ] ボタンをクリックし、「最もよく使用されるテーマを棒グラフで表し、null 値を削除したうえで、結果を上位 10 個の値に制限する」と入力します。AI は、入力したリクエストを理解し、対応する適切なクエリを自動的に生成します。これは「テーマ」という専用の列がない場合でも同じで、AI は「ml_genertae_text_llm_result」列でテーマが見つかると認識します。最後に、[実行] をクリックして、クエリ結果を表示します。
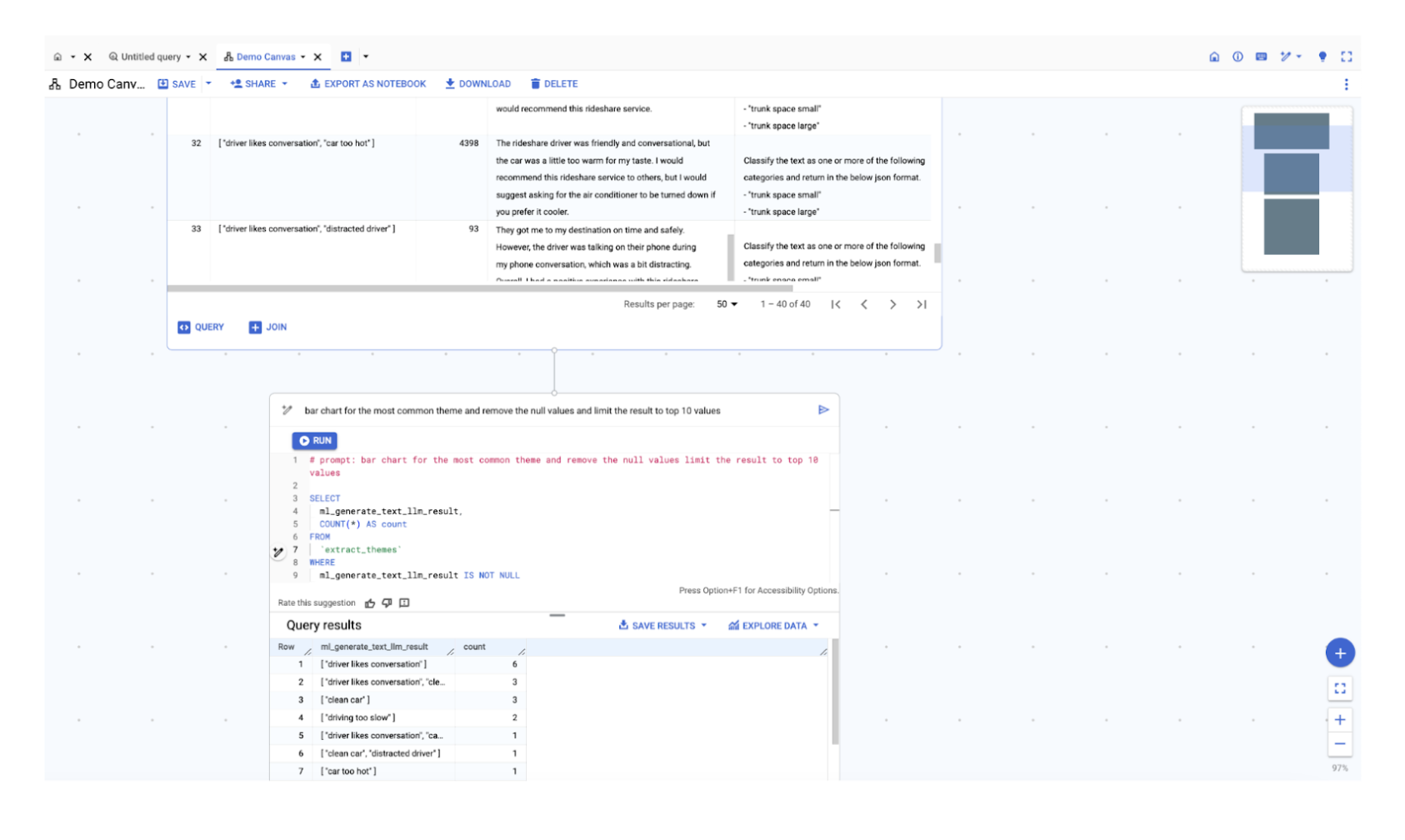
テーマデータを利用できる準備が整いました。[可視化] をクリックすると、すぐに棒グラフが表示されます。
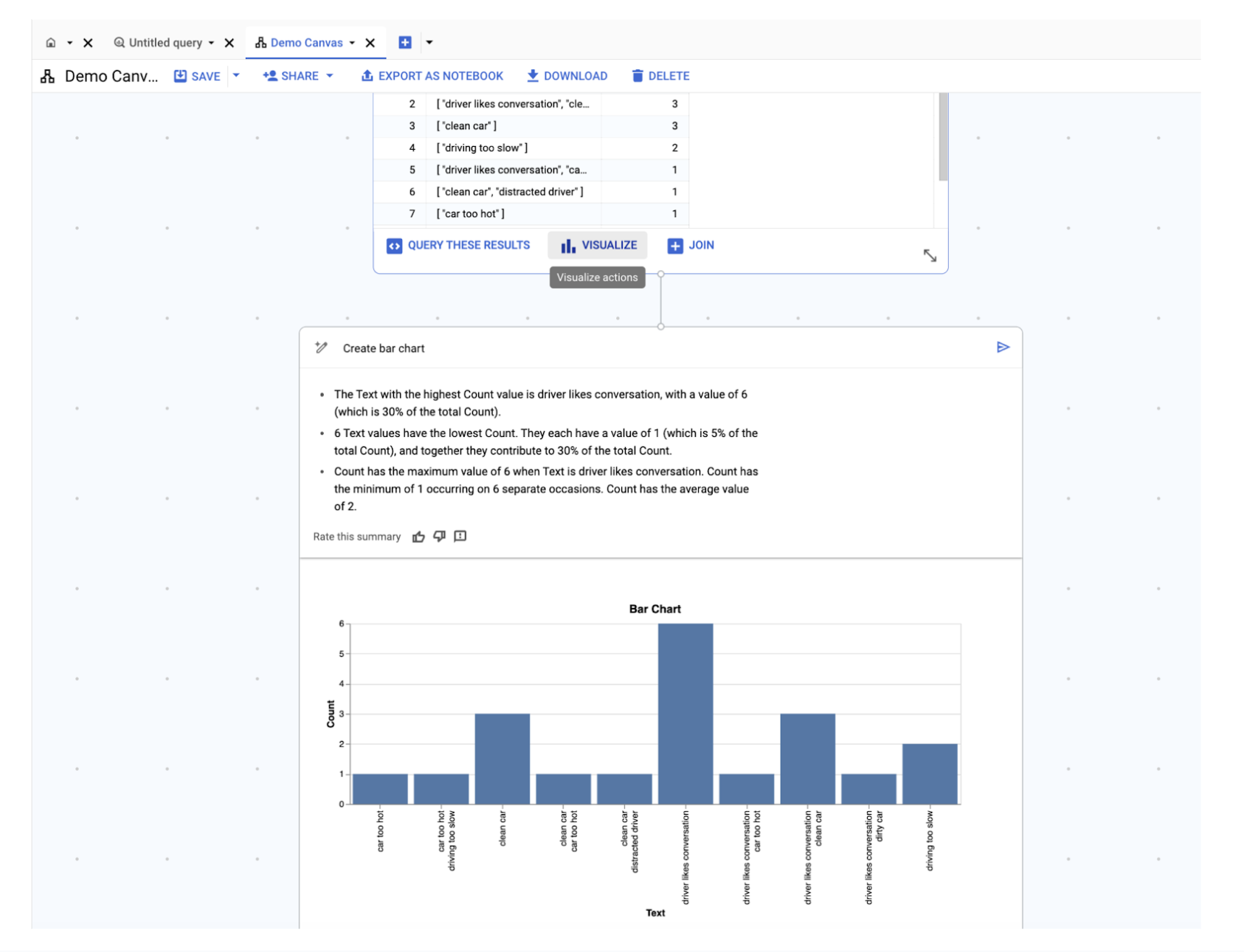
顧客レビューから抽出されたテーマが棒グラフで表示され、さらに検出データと説明に基づいて有用な分析情報が自動生成されます。
つまり、BigQuery データ キャンバスでは簡単な自然言語によるコマンドでデータを分析でき、分析に必要な、関連データを検出して顧客情報と結合する、主要な分析情報を得る、チームメンバーと連携する、レポートを作成するといった作業が 1 か所で完結します。また、こうして分析した結果を保存する、他のデータと結合してさらに分析を進める、ノートブックに抽出するといったことも可能です。
詳細については、ML.GENERATE_TEXT に関する公式のドキュメントをご覧ください。
ー データ分析カスタマー エンジニア、Nivedita Kumari



