BigLake: データレイクとデータ ウェアハウスを複数のクラウド間で統合
Google Cloud Japan Team
※この投稿は米国時間 2022 年 4 月 7 日に、Google Cloud blog に投稿されたものの抄訳です。
組織が管理および分析すべき貴重なデータの量は、驚異的なスピードで増加し続けています。このようなデータは、データ ウェアハウス、データレイク、NoSQL ストアなど、複数の場所に分散して保存されることが多くなってきました。組織のデータがますます複雑化して異なるデータ環境に拡散されると、サイロが出現し、リスクや費用が増します。特にそのデータを移動する必要が生じた場合にはそれが顕著になります。これは Google Cloud のお客様を見ても明らかであり、お客様はこのことについて支援を必要としています。
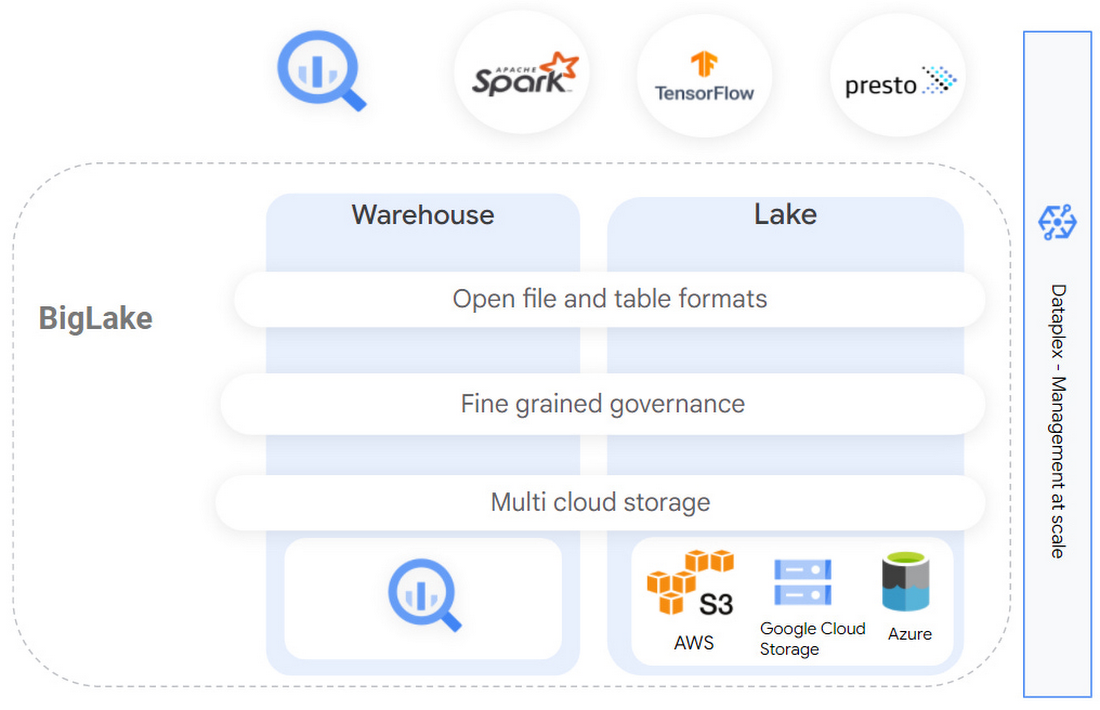
こうした状況を受けてこのたび発表するのが、データ ウェアハウスとデータレイクを統合するストレージ エンジン、BigLake です。BigLake は基盤となるストレージ形式やシステムを意識することなくデータを分析できるようにするもので、データの複製や移動が不要になり、コスト削減と効率化を図ることができます。
BigLake を使用することで、ユーザーは BigQuery や AWS と Azure 上のマルチクラウド データレイク全体にわたってきめ細かいアクセス制御を行えるだけでなく、パフォーマンスも大幅に向上します。また、Google Cloud とオープンソース エンジン全体で一貫したセキュリティを確保して、統合的にデータにアクセスできるようになります。
BigLake は 10 年に及ぶ BigQuery のイノベーションを、マルチクラウド ストレージ上のデータレイクにまでオープン フォーマットで拡張したもので、柔軟で費用対効果の高い、統合されたレイクハウス アーキテクチャが実現されます。
BigLake により、次のことが可能になります。
新しいインフラストラクチャを設定することなく、BigQuery をマルチクラウド データレイクや Parquet、ORC などのオープン フォーマットにまで拡張し、きめ細かいセキュリティ制御を行うことができます。
データの単一コピーを保持し、Google Cloud や Spark、Presto、Trino、Tensorflow などのオープンソース テクノロジーを含む、任意の分析エンジン全体にわたって一貫したアクセス制御を適用できます。
Dataplex とのシームレスな統合により、大規模なガバナンスと管理の統合を実現します。
BigLake の初期のお客様である Bol.com は、コストを低く抑えながらも分析の成果を加速させています。
「急速に成長する e コマース企業である当社では、データが急速に増加しています。BigLake を使用することで、ビューに対するアクセス制御が可能になると同時に、ユーザーに統一されたインターフェースを提供し、データ ストレージのコストを低く抑えることができます。これにより、データレイクの価値を解き放つことができました。さらに、ユーザー側ではデータセットをより迅速に分析できるようになりました」—Bol.com ソフトウェア エンジニア Martin Cekodhima 氏
BigQuery をマルチクラウド環境全体に拡張し、ガバナンスとともにデータ ウェアハウスとデータレイクを統合
BigLake テーブルを作成することで、BigQuery のお客様はワークロードを Google Cloud Storage(GCS)、Amazon S3、Azure Data Lake Storage Gen 2 で構築されたデータレイクに拡張できます。BigLake テーブルは、クラウド リソース接続を使用して作成されます。これはガバナンス機能を有効にするサービス ID ラッパーです。これを使用して、管理者は BigQuery テーブルに似たこれらのテーブルに対するアクセス制御を管理でき、エンドユーザーにオブジェクト ストアへのアクセスを提供する必要がなくなります。
データ管理者は、ポリシータグを使用して BigLake テーブルのテーブル、行、列の各レベルでセキュリティを構成できます。Google Cloud Storage 上で定義された BigLake テーブルの場合、BigLake コネクタを使用して、Google Cloud とサポートされるオープンソース エンジン全体にわたってきめ細かいセキュリティが常に適用されます。Amazon S3 と Azure Data Lake Storage Gen 2 を使う場合は、BigQuery Omni がセキュリティ制御を適用することで、管理されたマルチクラウド分析を可能にします。これにより、BigQuery とデータレイクにまたがってデータの単一コピーを管理できるため、データ ウェアハウジング、データレイク、データ サイエンスのユースケース間での相互運用が実現されます。

Google Cloud テクノロジーとオープンソース エンジンにまたがって分析ランタイム全体で一貫して機能するオープン インターフェース
Dataproc やセルフ マネージド デプロイメントを通じて Spark、Presto、Trino、Tensorflow などのオープンソース エンジンを実行しているお客様は、データレイクに対してきめ細かいアクセス制御を行えるようになり、クエリのパフォーマンスが加速されます。これにより、安全で管理されたデータレイクを構築でき、異なるユーザー グループごとに対応するビューを作成する必要がなくなります。これを行うには、Spark DDL などのサポート対象のクエリエンジンから BigLake テーブルを作成し、Dataplex を使用してアクセス ポリシーを構成します。構成したアクセス ポリシーは、このデータにアクセスするクエリエンジン全体で常に適用されるため、アクセス制御の管理が大幅に簡略化されます。
Dataplex とのシームレスな統合で大規模かつ統一されたガバナンスと管理を実現
BigLake は、Dataplex と統合して大規模な管理機能を提供します。お客様は BigQuery や GCS からレイクやゾーンにデータを論理的に整理してデータドメインにマッピングでき、そのデータを統制するポリシーを一元的に管理できます。これらのポリシーは、Google Cloud や OSS クエリエンジンによって一様に適用されます。また、Dataplex は Google Cloud ストレージを自動的にスキャンして BigQuery に BigLake テーブルの定義を登録し、Dataproc Metastore を介して使用できるようにするため、管理がより簡単になります。これにより、エンドユーザーは OSS アプリケーションと BigQuery のどちらを使用したデータ探索やクエリにも、これらの BigLake テーブルを使用できるようになります。
これらの機能を統合することで、レイクとウェアハウスにまたがってデータに対してさまざまな分析ランタイムを、管理された方法で実行できるようになります。これはデータのサイロを解消してインフラストラクチャ管理を大幅に軽減し、分析スタックを進化させて新たなユースケースを生み出す一助となります。
次のステップ
BigLake について詳しくは、ウェブサイトをご覧ください。または、クイックスタート ガイドを使用するか、Google Cloud セールスチームに問い合わせて、BigLake を今すぐ使ってみてください。
- Google Cloud ソフトウェア エンジニア Justin Levandoski
- Google Cloud プロダクト マネージャー Gaurav Saxena