Google Cloud 上の Spark: サーバーレス Spark ジョブでデータの利用がすべてシームレスで可能に
Google Cloud Japan Team
※この投稿は米国時間 2021 年 10 月 19 日に、Google Cloud blog に投稿されたものの抄訳です。
Apache Spark は、データ エンジニアリング、データ探索、機械学習にかかわるユースケースにすべて対応できることから、広く支持されるプラットフォームとなりました。ですが Spark には、まだオンプレミスでのクラスタ管理と各ジョブに合わせたインフラストラクチャの調整が必要とされています。また、エンドツーエンドのユースケースでは、Spark の使用に TensorFlow などのテクノロジーや SQL や Python などのプログラミング言語が求められます。現在、非構造化データレイクでは Spark を使用、データ ウェアハウスでは SQL を使用、まったく別の機械学習プラットフォームでは TensorFlow を使用といったように、運用がサイロ化されています。このようなサイロ化により、コストが増え、アジリティが低下し、ガバナンスの強化が困難になります。これは、企業が適切なタイミングで適切な利用者に分析情報を提供することの妨げとなります。
サーバーレスとインテグレーションを実現する Google Cloud 上の Spark を発表
Google Cloud やオープンソースの優れたツールとシームレスで統合し、業界初の自動スケーリングに対応したサーバーレス Spark を実現する Google Cloud 上の Spark を発表しました。ETL、データ サイエンス、データ分析にかかわるユースケースを大規模で簡単に強化できるようになります。Google Cloud は、Dataproc でオープンソースの Spark を使用して、6 年以上にわたり企業のお客様向けにビジネス クリティカルな Spark ワークロードを大規模に運用してきました。現在、次の機能を提供し、さらなる取り組みを進めています。
Spark クラスタを管理する時間を削減: サーバーレス Spark では、Spark ジョブを送信すれば、後はプロビジョニングとスケーリングが自動で行われます。
すべてのレベルでデータの利用を可能に: BigQuery、Vertex AI、Dataplex など、目的のインターフェースから 2 クリックで、Spark ジョブに接続し、ジョブを分析、実行できます。カスタム インテグレーションは不要です。
用途に柔軟に対応: どんな場合にも使える手法は存在しません。Spark をサーバーレスで使うことで、要件に基づいて Google Kubernetes Engine(GKE)やコンピューティング クラスタでデプロイできます。
Google Cloud 上の Spark により、クラウド ネイティブな手法(サーバーレス)で Spark を使用できるようになります。また、データ エンジニア、データ アナリスト、データ サイエンティストが用途に応じて使うツールにシームレスに連携できます。このようなツールは、着手したデータ プラットフォームの再設計の実現に役立ちます。
「Deutsche Bank は、さまざまなユースケースで Spark を利用しています。GCP への移行と Dataproc に対応したサーバーレス Spark の導入で、リソースの使用率を最適化し、手動での作業を減らすことができました。これにより、エンジニアリング チームは、インフラストラクチャの管理に代わって、ビジネス向けのデータ プロダクトのデリバリーに集中できます。同時に、既存のコードベースとエンジニアのノウハウを保てるため、導入が促進されシームレスに移行できます。」 - Deutsche Bank ビッグデータ プラットフォーム担当ディレクター Balaji Maragalla 氏
「サーバーレス Spark は、当社のデータ戦略で中心的な役割を果たしています。サーバーレス Spark は、ビッグデータ テクノロジーに精通していないチームや、独自の処理のニーズを解決するために Spark の特異性を気にする必要のないチームに、効率的でシームレスなソリューションをもたらします。このサービスのサーバーレスな面と、BigQuery、Vertex AI、Dataplex などのデータサービスとのシームレスなインテグレーションに期待しています。」 - Snap Inc. エンジニアリング、インフラストラクチャおよびデータ担当ディレクター Saral Jain 氏
Spark 向け Dataproc Serverless
IDC によると、デベロッパーは 40% の時間をコードの記述に費やし、60% の時間をインフラストラクチャの調整とクラスタの管理に費やしています。さらに、Spark 担当のデベロッパーが、インフラストラクチャの専門家であるとは限らないため、コストと生産性への影響が大きくなります。サーバーレス Spark を使用すると、デベロッパーはコードとロジックにすべての時間を費やすことができます。クラスタの管理やインフラストラクチャの調整は必要ありません。選択したインターフェースから Spark を送信すれば、ジョブのニーズに合わせて自動スケーリングで処理されます。さらに Spark では目下、インフラストラクチャを実行した時間に対して支払いが発生しますが、サーバーレス Spark ではジョブの実行時間に対してのみ支払いが発生します。
BigQuery を介した Spark
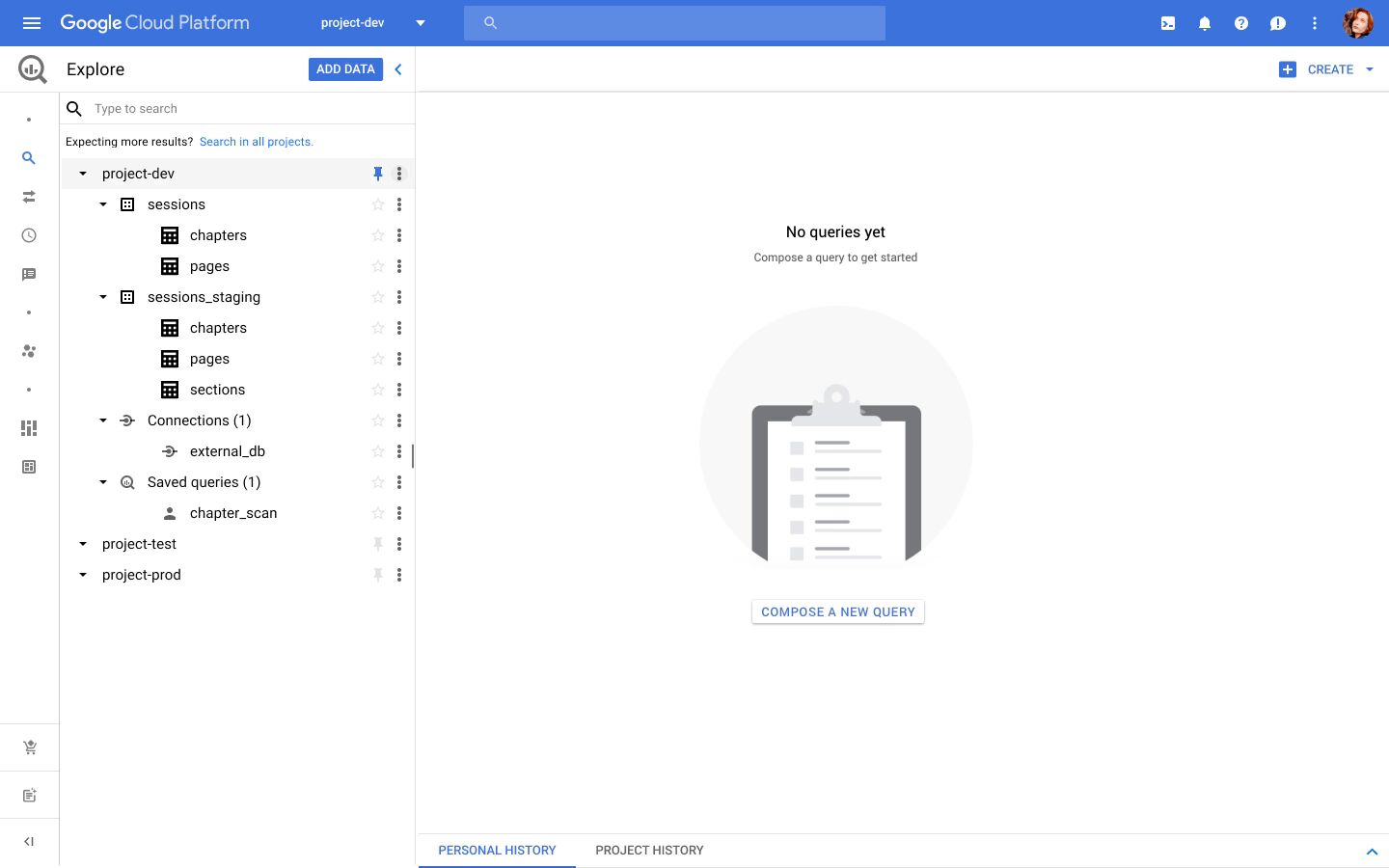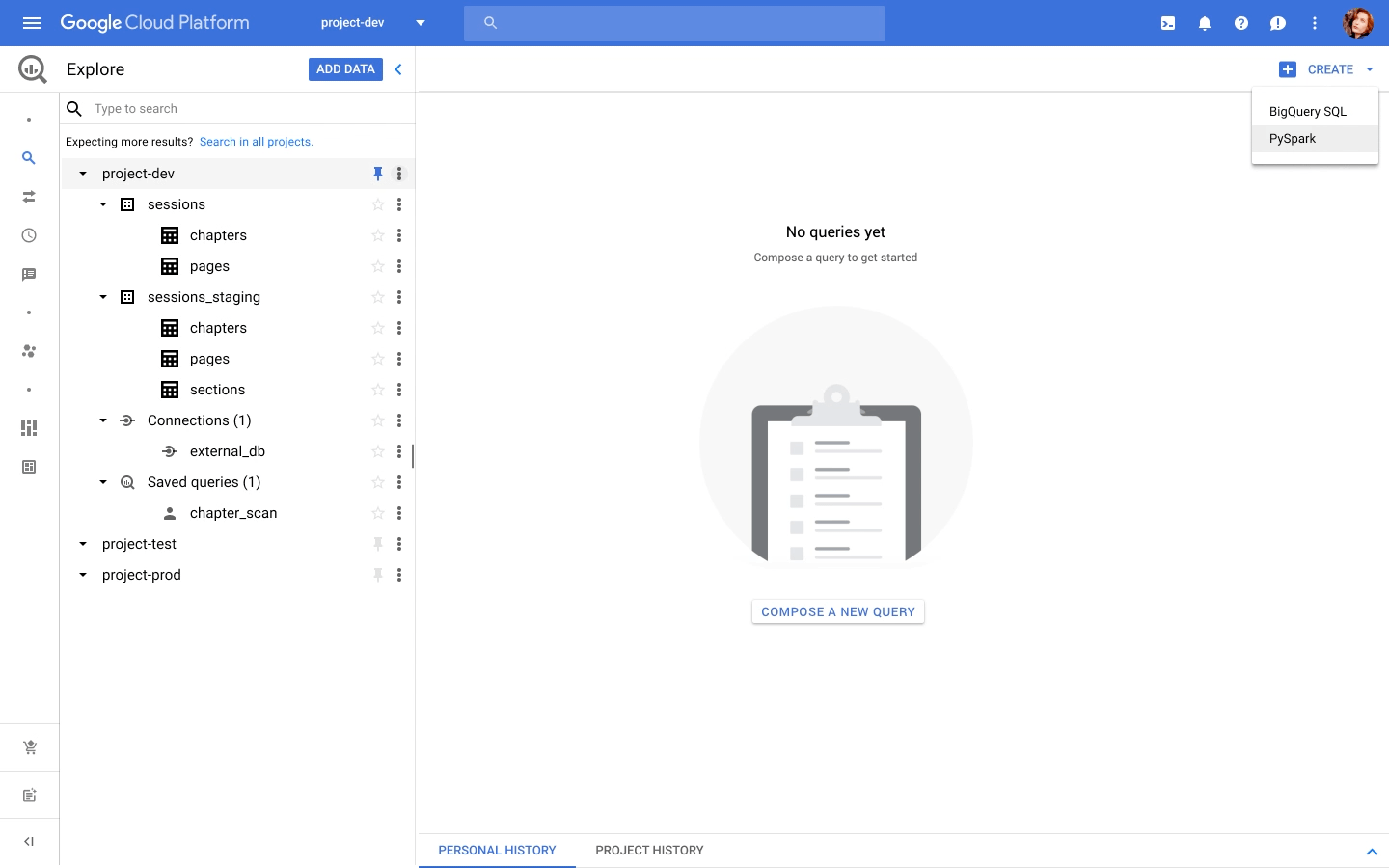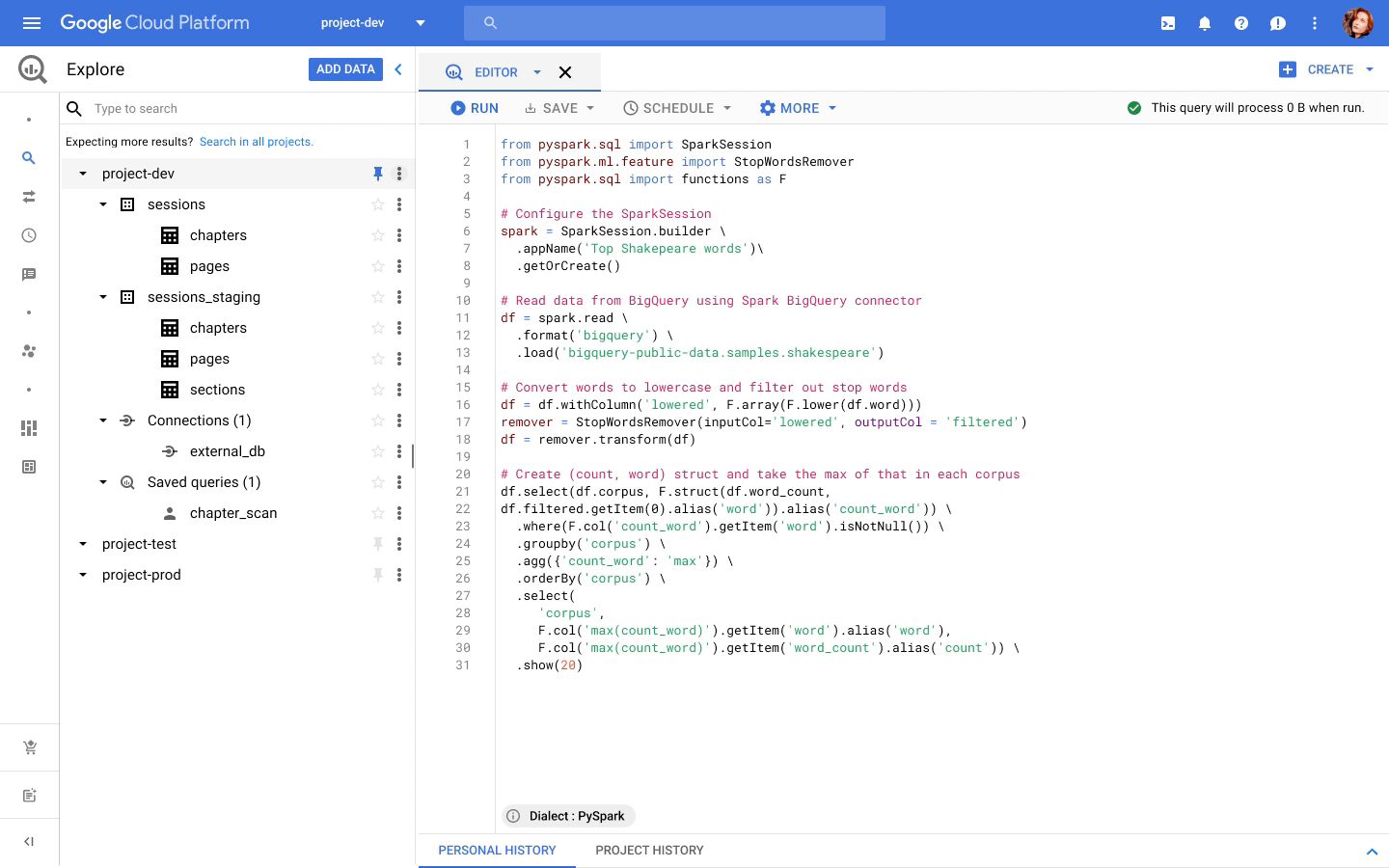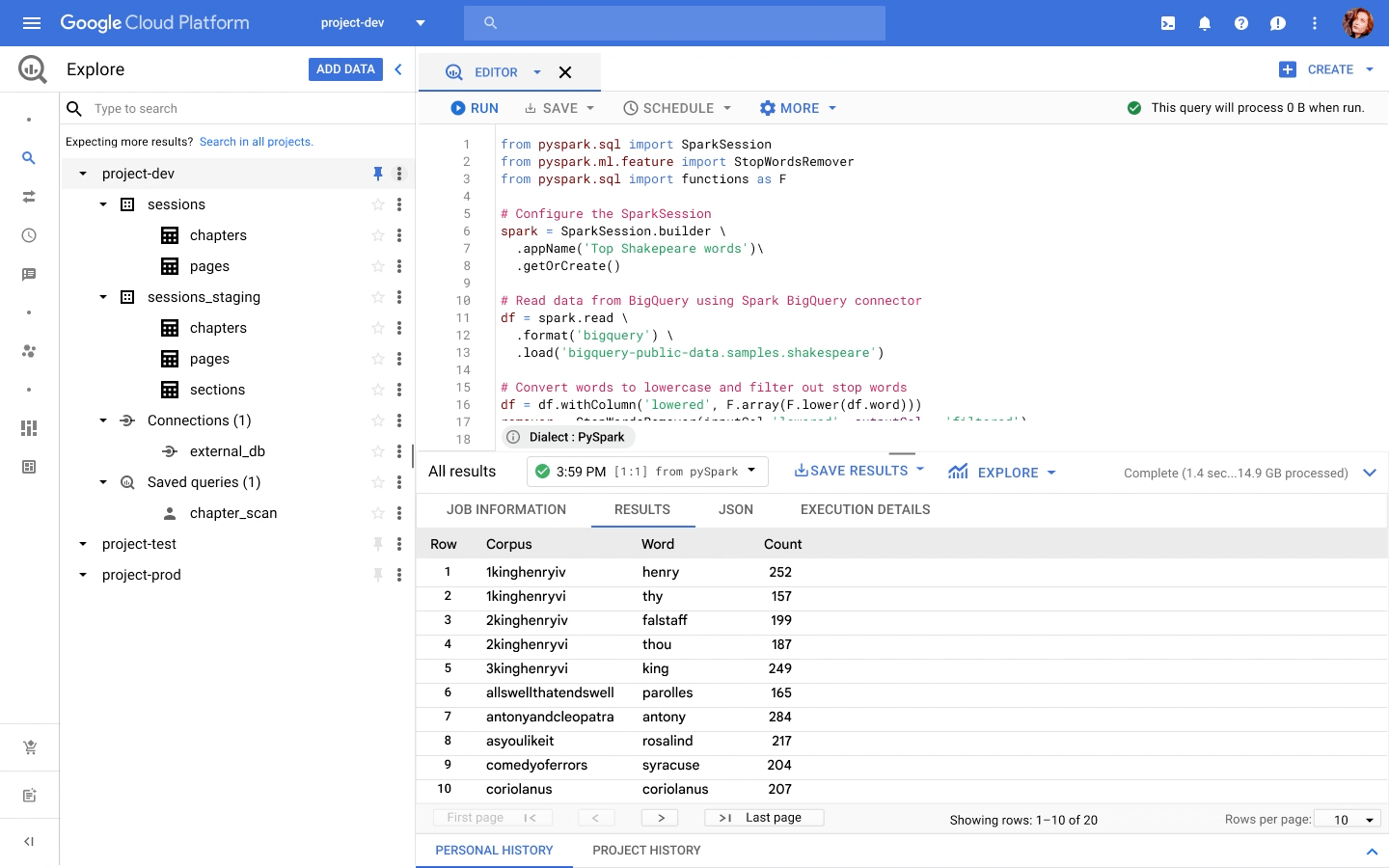
主要なデータ ウェアハウスである BigQuery は、データ アナリストが SQL または PySpark を記述するための一元化されたインターフェースを提供します。コードは、サーバーレス Spark をシームレスに使用して実行されます。インフラストラクチャのプロビジョニングは不要です。BigQuery は、サーバーレスでのデータ ウェアハウジングの先駆者です。サーバーレス Spark を新たにサポートし、Spark ベースの分析に対応するようになりました。
Vertex AI を介した Spark
データ サイエンティストは、ノートブックで Spark を使って、カスタム インテグレーションを行う必要がもうありません。Vertex AI Workbench を介して、ワンクリックで Spark に接続し、インタラクティブな開発を行えます。Vertex AI を使用すると、Spark を TensorFlow、Pytorch、scikit-learn、BigQuery ML などの機械学習フレームワークと簡単に併用できるようになります。Google Cloud のセキュリティ、コンプライアンス、IAM は、すべて自動で Vertex AI と Spark にまたがり適用されます。ML モデルのデプロイの準備ができると、ノートブックは Spark ジョブとして Dataproc で実行され、Vertex AI パイプラインの一部としてスケジュールされます。
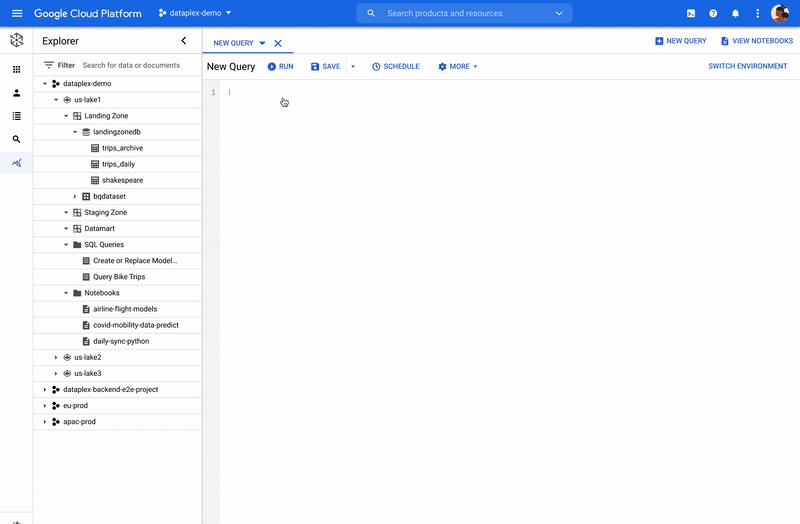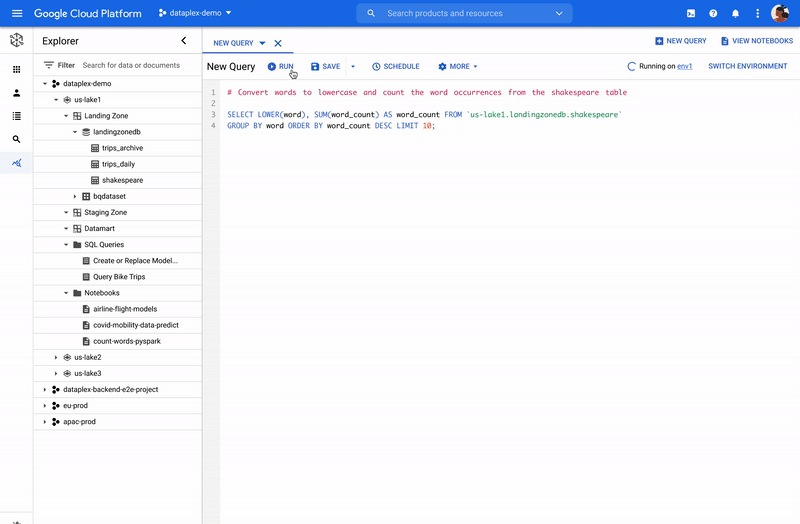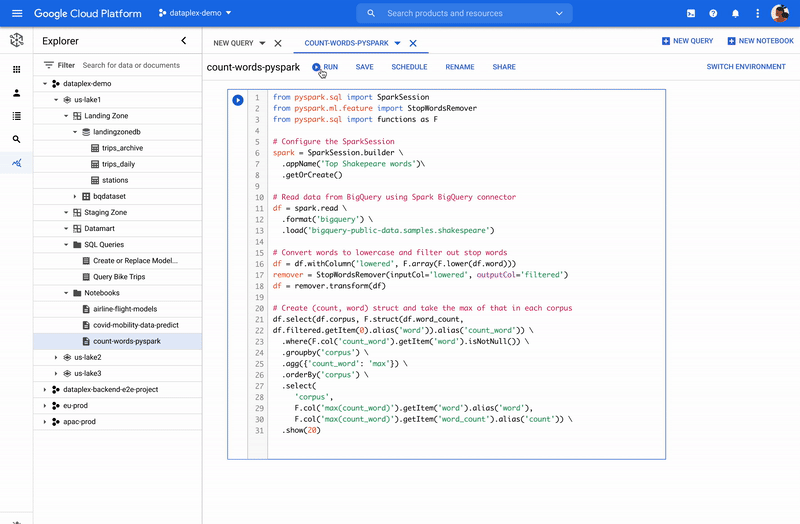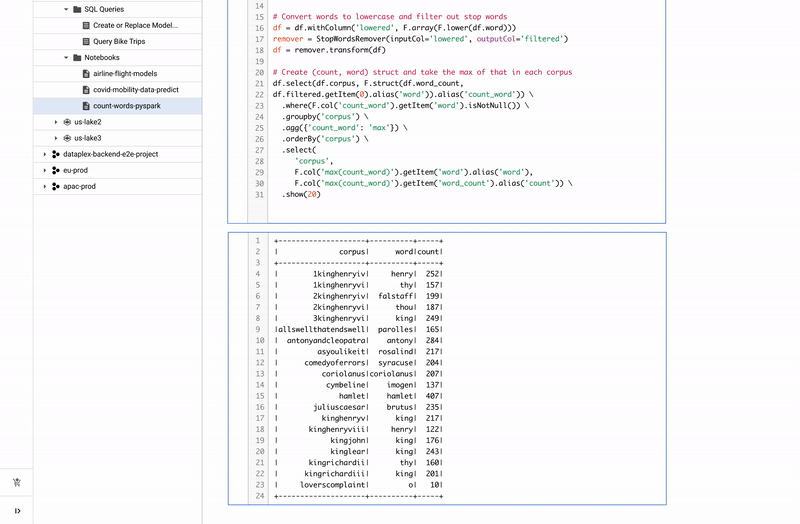
Dataplex を介した Spark
Dataplex は、データレイク、データ ウェアハウス、データマート全体でデータを一貫して制御し、一元的に管理、モニタリング、統制できるようにするインテリジェント データ ファブリックです。信頼できるデータへアクセスできるようになり、組織での大規模な分析を可能にします。また、Dataplex を介して分散されたデータにネイティブに Spark を使用できるようになりました。Dataplex により、SparkSQL、Notebooks、PySpark へワンクリックでアクセスできるコラボレーティブな分析インターフェースが提供されます。また、データと同時にノートブックとスクリプトも保存、共有、検索できるようになります。
用途に柔軟に対応
Google は、どんな場合にも使える手法は存在しないと理解しています。Spark は、特定のニーズによって 3 つの異なる方法で使用できます。インフラクチャの管理のために Kubernetes で標準化する場合は、Google Kubernetes Engine(GKE)で Spark を実行して、リソースの使用率を改善し、インフラクチャの管理を簡素化できます。Hadoop スタイルのインフラストラクチャの管理を求めている場合は、Google Compute Engine(GCE)で Spark を実行します。NoOps での Spark デプロイを求めている場合は、サーバーレス Spark を使用します。
ESG シニア アナリストの Mike Leone 氏は、次のように述べています。「Google Cloud により、Spark は単一の統一プラットフォームを通じて使い勝手が向上し、広範囲にわたるユーザーがよりアクセスしやすくなっています。BigQuery や Vertex AI を介してサーバーレスで Spark を実行する機能により、生産性が大幅に向上するでしょう。さらに、Google はセキュリティとガバナンスに重点を置いているので、この Spark ポートフォリオは、Google Cloud への移行を続けるすべての企業に役立ちます。」
スタートガイド
Spark 向け Dataproc Serverless は、あと数週間で一般提供される予定です。BigQuery と Dataplex のインテグレーションは、限定公開プレビュー版での提供となります。Vertex AI Workbench は、公開プレビュー版での提供となり、こちらから始められます。全機能に対応するには、このフォームからプレビュー版へのアクセスをリクエストしてください。
Google Cloud パートナーと提携して開始することもできます。
「Google Cloud とパートナーを組み、共通のお客様に、Spark での最新のイノベーションを提供することを楽しみにしています。Spark は、多様な分析と ML のユースケースに活用されるでしょう。Google は、Spark をサーバーレスにし、BigQuery、Vertex AI、Dataplex を介して、幅広いユーザーが利用できるようにすることで、Spark をさらに一歩先に進めました。」 - Accenture クラウド ファースト データおよび AI リード担当 Sharad Kumar 氏
詳細については、Google Cloud のウェブサイトにアクセスするか、お知らせ動画と Next '21 での Snap 社との会談をご覧ください。
- Google Cloud プロダクト マネジメント担当ディレクター Irina Farooq
- Google Cloud シニア プロダクト マネージャー Abhishek Kashyap
