サーバーレス Spark 上でのノートブック オーケストレーションのベスト プラクティス
Google Cloud Japan Team
※この投稿は米国時間 2023 年 4 月 15 日に、Google Cloud blog に投稿されたものの抄訳です。
データ サイエンティストは、Project Jupyter や Apache Spark などのさまざまな分散処理フレームワークとインタラクティブなコラボレーション コンピューティング プラットフォームを使用して、データの処理と ML ワークフローの実行を行います。こうしたワークフローをすべてオーケストレートするには、Apache Airflow を使用するのが一般的です。
しかし、エンタープライズ グレードのデータ サイエンスや ML ワークロードをパブリック クラウドで大規模に実行するとなると、いくつかの課題に直面します。
パフォーマンス: エンタープライズ アプリケーションの場合、データやモデルのサイズ、規模が複雑です。また、時間の経過とともにサイズと規模が拡大し、パフォーマンスに影響を及ぼす傾向があります。
スケーラビリティ: アプリケーションが複雑化するほど、容量の上限、帯域幅の問題、トラフィックの急増に対処するのがより難しくなります。
インフラストラクチャと料金: 典型的なエンタープライズ ML のデプロイでは、適切なクラスタサイズ、マシンタイプ、パフォーマンス調整、メンテナンス費用を計画して構成する作業は複雑です。より柔軟で費用対効果に優れ、管理しやすく、ビジネスにとって最も重要な ML のコアなビジネス ロジックに注力できるようなソリューションが必要です。
Google Cloud では、データ エンジニアとデータ サイエンティストが Hadoop と Spark のワークロードを Dataproc で実行し、Jupyter ベースのノートブックを Vertex AI マネージド ノートブックで開発できます。
サーバーレス Spark を使用すれば、ノートブックを含む任意の Spark バッチ ワークロードを実行できます。独自のクラスタのプロビジョニングや管理は必要ありません。ワークロードのパラメータを指定することも、適切なデフォルト値を使って自動スケーリングを適用することもできます。ワークロードはマネージド コンピューティング インフラストラクチャで実行され、必要に応じてリソースが自動スケーリングされます。
Vertex AI マネージド ノートブック インスタンスでは、インタラクティブなノートブックを開発できます。これらのインスタンスは JupyterLab で事前にパッケージ化され、ディープ ラーニング パッケージのスイート(TensorFlow と PyTorch のフレームワークのサポートを含む)がプリインストールされています。マネージド ノートブック インスタンスでは GPU アクセラレータがサポートされていて、ソース リポジトリとの同期機能も利用できます。マネージド ノートブック インスタンスは Google Cloud の認証と認可によって保護されます。必要であれば、アイドル状態でのシャットダウンを使用して環境をシャットダウンし、費用を節約できます。この場合、すべての作業とデータは Cloud Storage に保持されます。
最近では、こうしたワークフローをオーケストート、スケジュール、モニタリングするために、Cloud Composer を使用できるようになっています。
このブログ投稿では、サーバーレス Spark 上で任意の Jupyter ベースのノートブックをバッチジョブとして実行する方法に着目します。
シナリオ: Google Cloud へのノートブックのリフト&シフト
通常、お客様は既存のノートブックをオンプレミスや他のクラウド プロバイダからサーバーレス Spark に移行して実行します。Fortune 50 にランクインしているある小売業者は、すべてのデータ サイエンス ワークロードをオンプレミスからサーバーレス Spark と Vertex AI マネージド ノートブックに移行して、毎日 5 億を超える商品の品揃え分析を実行しています。
ノートブックの移行プロセスは、次の 2 つのステップで構成されています。
1. ノートブックを従来のデータレイクから移行して、Google Cloud Storage(GCS)バケットにステージングします。
2. ステージングしたノートブックをサーバーレス Spark でオーケストレートしてデプロイします。このブログ投稿で着目するのは、Spark を活用して ELT / ETL を行う JupyterLab ベースのノートブックです。
次の図は、ノートブックのオペレーション フローを示しています。
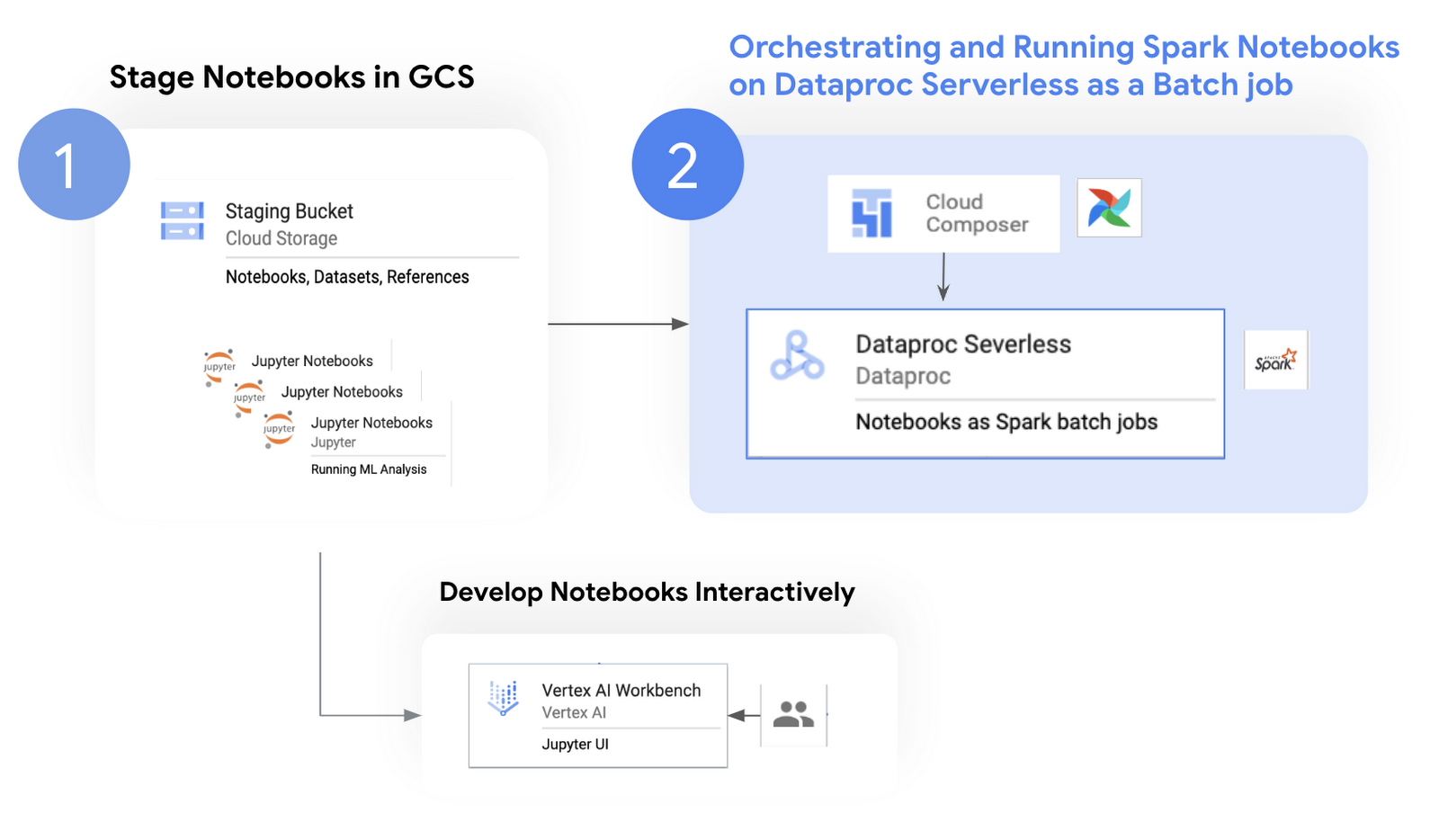
Cloud のコンポーネント
ノートブックの開発とオーケストレーションに使用される一般的なサービスは次のとおりです。
Vertex AI Workbench: デベロッパーはこのサービスで提供される Jupyter ノートブック インターフェースを使用して、インタラクティブにデータを分析して可視化できます。Vertex AI Workbench には BigQuery、GCS、Git インテグレーションなどの機能が統合されており、いずれもノートブック インターフェース内で使用できます。これらの機能により、ユーザーはノートブックを離れることなく、UI でさまざまなタスクを実行できます。たとえば、単体テストを実施するときは、複数のデベロッパーが連携してテストのワークフロー全体をインタラクティブに呼び出し、テスト結果とリアルタイムのフィードバックを共有できます。
下のスクリーンショットに示されているサンプル Spark ノートブックは、Vertex AI Workbench 上で変更を加えて、サーバーレス Spark でオーケストレートしたものです(vehicle_analytics.ipynb)。
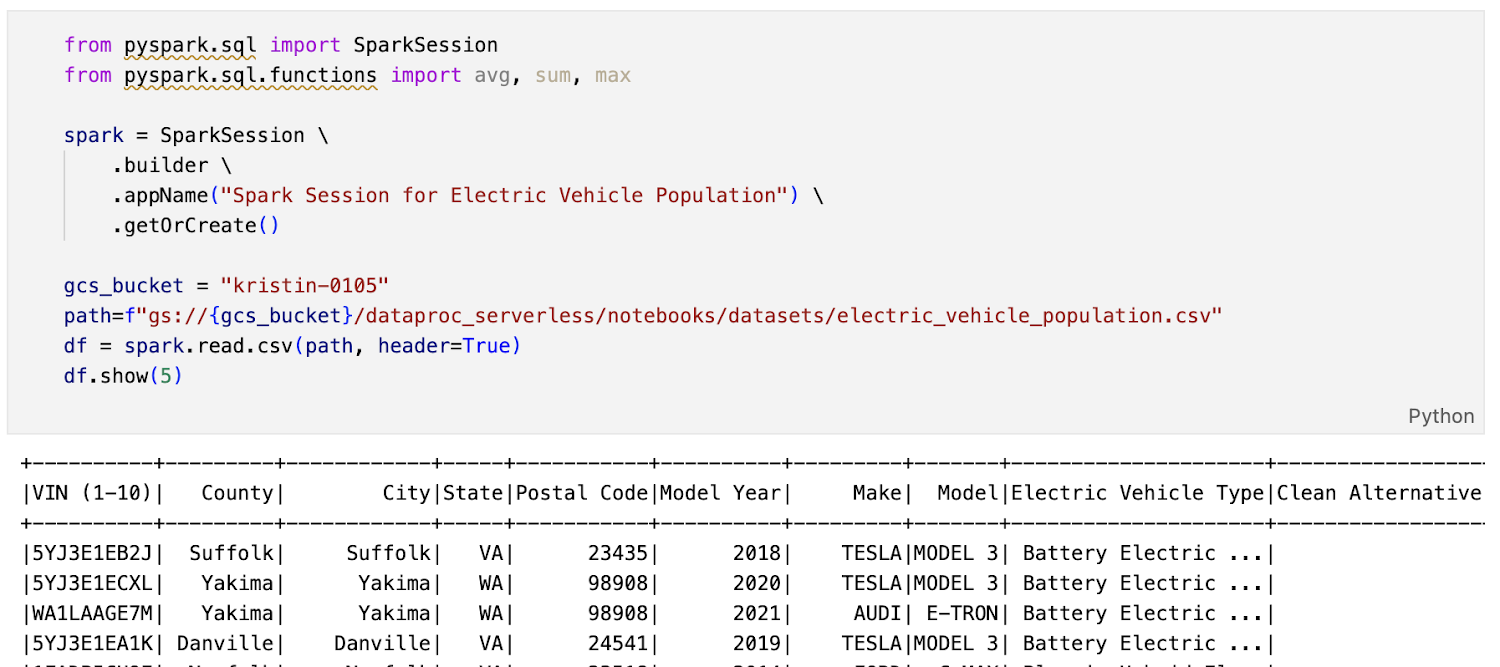
図 2. 自動車分析用のサンプル Spark ラボ(vehicle_analytics.ipynb)
サーバーレス Spark: このサービスは独自の動的リソース割り当てを使用してリソース要件を判断し、必要に応じて自動スケーリングも行います。
Cloud Composer: Google Cloud の演算子、センサー、プローブを使用してワークロードをオーケストレートする、マネージド Airflow です。このサービスには次の特徴があり、それにより Dataproc ワークロードもシームレスにオーケストレートできます。
フルマネージド: Cloud Composer では、Dataproc ワークフローを作成、削除、管理するプロセス全体を自動化できます。そのため、人為的ミスが発生する可能性を最小限に抑えられます。
Google Cloud の他のサービスとのインテグレーション: Cloud Composer では、BigQuery、Dataflow、Dataproc、Cloud Storage、Pub/Sub などのさまざまな Google プロダクトとの組み込みインテグレーションが提供されています。
スケーラビリティ: Cloud Composer の自動スケーリングでは、スケーリング ファクタのターゲット指標を使用してワーカー数を調整し、スケジュールされたタスクの需要に対応します。
サーバーレス Spark でノートブックを実行する際のベスト プラクティス
1. サーバーレス Spark でノートブックをオーケストレートする
GUI や CLI を使って手動で Dataproc ジョブを作成する代わりに、オープンソース Apache Airflow ベースの Google Cloud Dataproc 演算子を使用してオペレーションの構成とオーケストレーションを行うことができます。
Airflow DAG を作成する際は、最適なパフォーマンスとスケーラビリティを実現できるように、こちらのベスト プラクティスに沿って Cloud Composer プロセスを最適化してください。
Cloud Composer でオーケストレートするには、
DataprocCreateBatchOperator() という Dataproc バッチ演算子を使用します。この演算子によって、ワークロードがサーバーレス Spark で実行されます。
https://cloud.google.com/composer/docs/composer-2/run-dataproc-workloads#custom-container
DataprocCreateBatchOperator() を使用して、次の Python スクリプトをサーバーレス Spark に送信できます。
図 3. バッチジョブをサーバーレス Spark に送信するための Cloud Composer DAG
Python スクリプト内にラップした papermill ユーティリティを使用してパラメータを渡し、ノートブックを実行して、その出力を別のノートブックに返すことをおすすめします。以下に例を示します。
図 4. ラッパー vehicle_analytics_executor.py で papermill を使用してノートブックを実行する
2. 依存関係をインストールしてファイルをアップロードする
ノートブックに追加の Python パッケージが必要な場合は、バッチジョブをサーバーレス Spark に送信するときに requirements.txt ファイルのパスを渡します。Google のテストでは、requirements.txt に pendulum==2.1.2 を追加しました。
以下に示すように、GCS にある Python ファイル、JAR、その他の参照ファイルもサーバーレス Spark への送信時に追加できます。
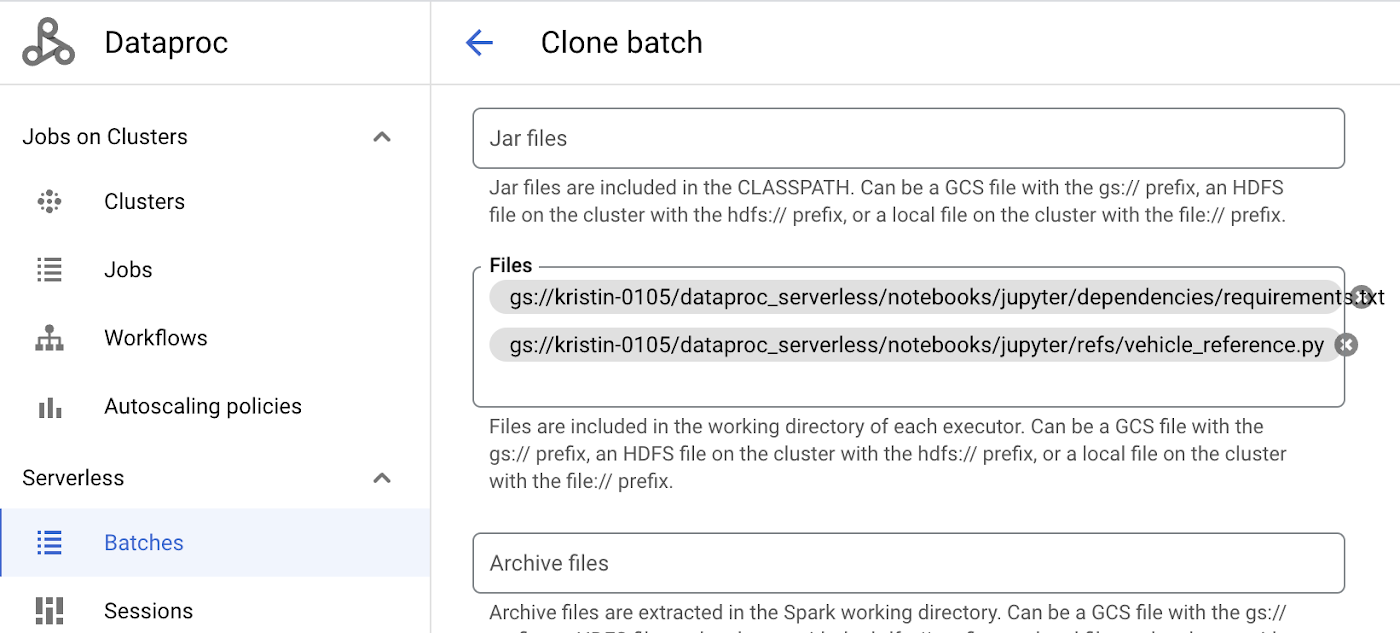
図 5. [1] Python パッケージをインストールするための requirement.txt を追加し、[2] ノートブック(vehicle_analytics.ipynb)で実行する vehicle_reference.py を追加する



図 8. ノートブック(vehicle_analytics.ipynb)で vehicel_reference.py を正常に実行するための %run コマンド
3. Spark のロギングとモニタリングに永続履歴サーバーを使用する
サーバーレス Spark のバッチ セッションはエフェメラルであるため、アプリケーションが完了するとすべてのアプリケーション ログが失われます。
永続履歴サーバー(PHS)を使用すると、完了した Spark アプリケーションの詳細にアクセスして、さまざまなエフェメラル クラスタやサーバーレス Spark で実行されたジョブについて確認できます。実行中のアプリケーションと完了したアプリケーションを一覧表示できるだけでなく、アプリケーションのイベントログや、エフェメラル クラスタとサーバーレス Spark の YARN コンテナログが GCS バケットに収集されます。これらのログファイルは、モニタリングとトラブルシューティングに不可欠です。
PHS の設定に関するベスト プラクティス:
https://cloud.google.com/blog/products/data-analytics/running-persistent-history-servers
4. パフォーマンスの調整
バッチジョブをサーバーレス Spark に送信すると、Spark の適切なデフォルト値と自動スケーリングがデフォルトで指定(有効化)されます。これによって必要に応じてエグゼキュータがスケールされるため、最適なパフォーマンスを得ることができます。
ジョブに基づいて Spark の構成とスコープを調整する場合は、エグゼキュータの数、エグゼキュータのメモリ、エグゼキュータのコア数をカスタマイズしてベンチマークを実行し、spark.dynamicAllocation を微調整して自動スケーリングを制御できます。Spark ジョブ調整のヒントをご覧ください。
5. 複数のノートブックを同時に実行する
複数のノートブックを同時にサーバーレス Spark に送信できます。各リージョンの Google Cloud プロジェクトごとに、1 分あたり最大 200 件の同時バッチジョブを実行できます。それぞれのバッチジョブをそのジョブ固有の Spark 構成で実行することで、最適なパフォーマンスを得ることができます。
ノートブックごとに個別のエフェメラル クラスタが割り当てられるため、あるノートブック ジョブのパフォーマンスが他のノートブック ジョブのパフォーマンスに影響することはありません。Spark バッチ ワークロードを送信する際に、すべてのジョブの Spark イベントログをモニタリングするように PHS クラスタを構成してください。
6. ソース管理と CI / CD
ノートブックはコードであるため、必ずソース管理で維持し、堅牢な CI / CD プロセスを通じてそのライフサイクルを管理してください。CI / CD(継続的インテグレーション / 継続的デリバリー)には、バージョン管理用の Google Cloud Source と Cloud Build を使用できます。
ソース管理には、本番環境(マスター)、開発環境、機能ブランチを使用するのが一般的です。
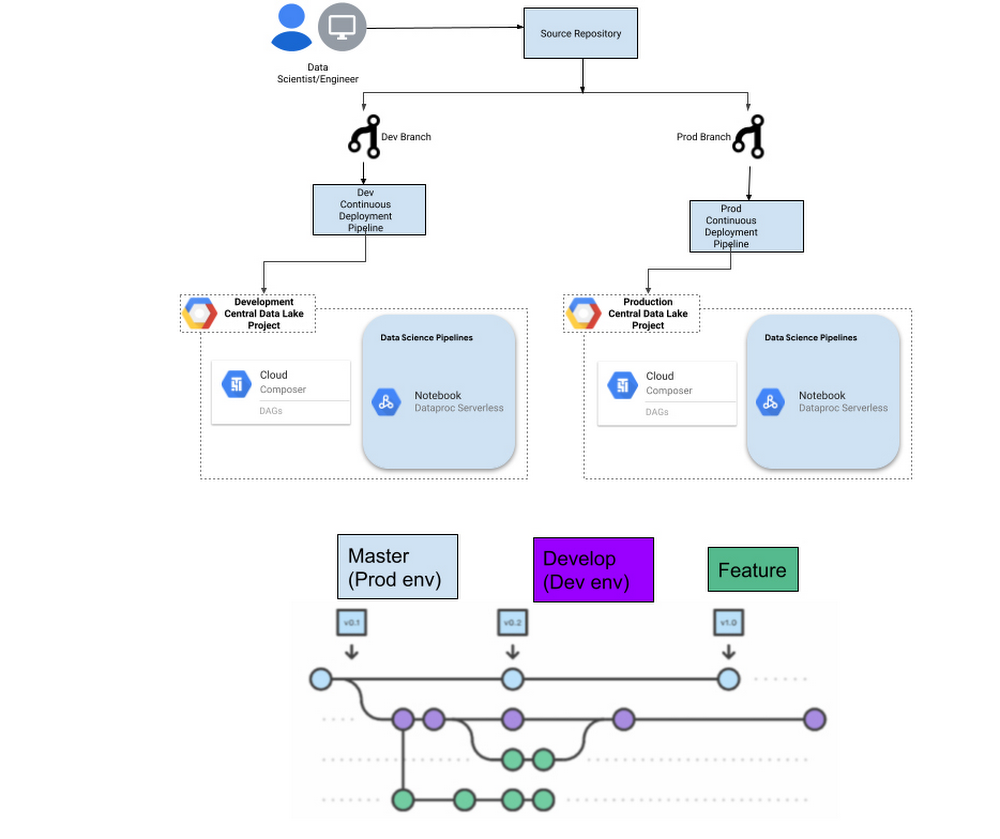
図 8. 本番環境と開発環境のプロジェクトに対する CI / CD の実装
CI の一連のベスト プラクティスに沿って、CI / CD サイクルに最初のステップとしてビルドプロセスを組み込み、クリーンな環境内でソフトウェアをパッケージ化してください。
ノートブック、Python スクリプト、Cloud Composer DAG、GCS バケット内の依存関係といったワークフローには、アーティファクトのステージングが必要になります。コード リポジトリのブランチを Google Cloud の環境に関連付けることができます。たとえば、マスター ブランチへの commit が行われると、一連の事前構成されたタスク(リポジトリからの最新コードの読み取り、コンパイル、自動化された単体テスト検証の実行、コードのデプロイなど)が CI / CD パイプラインによってトリガーされます。
これにより、コード リポジトリと Google Cloud プロジェクトでデプロイされたものとの間で一貫性を確保できます。
実行中のデータ サイエンスのワークフローに影響を及ぼさないように、CI / CD パイプラインでアーティファクトをステージングするための専用バケットを用意し、それとは別のバケットに Cloud Composer や Dataproc などのサービスがアクセスするファイルを保管することをおすすめします。
次のステップ
サーバーレス Spark でデータ サイエンスのバッチ ワークロードを実行することを検討している方は、次のラボとリソースをご覧ください。
Cloud Composer を使用してエフェメラル Dataproc クラスタでノートブックをオーケストレートすることを検討している方は、このサンプルをご覧ください。
その他のリソース
このソリューション チュートリアルで取り上げたサービスの料金に関する情報は、以下のリソースで確認できます。
最新機能の情報を見逃さないよう、次のプロダクトのリリースノートを随時ご確認ください。
クレジット: Blake DuBois、Kate Ting、Oscar Pulido、Narasimha Sadineni
- Cloud テクニカル レジデント Kristin Kim
- 戦略的クラウド エンジニア Anu Venkataraman


