MLB のファンデータ チーム、データ ウェアハウスのモダナイゼーションにより大成功を収める

Google Cloud Japan Team
※この投稿は米国時間 2020 年 8 月 12 日に、Google Cloud blog に投稿されたものの抄訳です。
編集者注: 本ブログ投稿では、MLB のデータ エンジニアリング担当バイス プレジデントである Robert Goretsky 氏が、MLB のデータ ウェアハウス モダナイゼーションの過程について、詳細に解説しています。Next OnAir のセッション MLB のデータ ウェアハウス モダナイゼーションで全編をご確認いただけます。
メジャーリーグ ベースボール(MLB)では、ファンの皆様によるインターネットを通じたトランザクションとデータ送受信、球場内でのトランザクションとデータ送受信により生成されるデータを活用して、サービスの機能を迅速に練り直し、ファンの皆様それぞれに合わせたコンテンツとキャンペーンを準備して、ファンの皆様に野球をお楽しみいただいています。MLB のファンデータ エンジニアリング チームは、350 以上のデータ パイプラインを管理して、組織内外のデータ提供元からデータを取得し、企業用データ ウェアハウス(EDW)に集約しています。MLB の EDW は、主に、組織内のサービス部門、マーケティング部門、財務部門、発券部門、ショップ部門、分析部門、データ サイエンス部門、ならびに MLB 全 30 球団から出されるデータ関連の計画を推進するために使用されています。これらの計画の例として、以下が挙げられます。
- MLB.com でファンの皆様それぞれに公開する新しい記事を、応援するチームを基に選び出す。
- ファンの皆様が観戦する試合の開始前に、関連情報を伝える。
- MLB.tv 会員様向けの収益予測と離脱率分析を実施する。
- ファンの皆様の将来の購入活動を予測するための機械学習モデルを構築する。
- ファンの皆様のトランザクションとエンゲージメントに関するデータを MLB 本部から MLB 30 球団に伝え、各球団が個別に正しい情報に基づいて意思決定を行えるようにする。
MLB は、2018 年に技術面の評価を行った後、EDW を Teradata から Google Cloud の BigQuery に移行することを決断しました。2019 年初頭には概念実証を無事完了し、2019 年 5 月から 2019 年 11 月まで、Teradata から BigQuery への完全移行のプロジェクトを実施しました(本当に 7 か月で移行を完了しました)。MLB は、移行を完了してから、最新のクラウド優先型データ ウェアハウス プラットフォームへの移行の多くの利点に気付きました。ここでは、MLB がどのように EDW の移行を果たしたかを紹介します。
MLB はどのように BigQuery に移行したか
MLB は、Teradata から BigQuery への移行のため、以下のとおり複数のワークストリームを同時に実施しました。
- 複製: Teradata に保存され、定期的に更新される約 1,000 個のテーブルそれぞれに対し、Apache Airflow を使用してデータ複製ジョブをデプロイし、Teradata のデータを BigQuery にコピーしました。各ジョブは、データが該当の上流ソースから Teradata に格納された後にのみ複製を実施するよう構成されました。つまり、データは、常に Teradata と BigQuery で同様に最新の状態に保たれました。BigQuery に最新状態のデータを格納したことで、下流のデータ使用者全員(ビジネス インテリジェンス チーム、分析チーム、データ サイエンス チーム、マーケティング チームのメンバーを含む)が、大部分の ETL 変換の完了前にプロジェクトの早い段階から BigQuery ですべての新しいプロセス、分析結果、レポートを作成開始できました。
- ETL 変換: Google は、350 件を超える ETL ジョブを Airflow と Informatica で実行しており、各ジョブが Teradata にデータを格納したり、Teradata からデータを抽出したりしていました。各ジョブは、BigQuery とやり取りできるよう変換する必要がありました。これらのジョブの変換と移行の順序を決めるため、依存関係図を作成して、どのテーブルと ETL ジョブが互いに上流と下流の関係にあるかを特定しました。下流方向の依存関係が少なく、あまり複雑ではないジョブは、最初に移行できました。1 つの言語から別の言語への SQL の機械的変換を処理できる CompilerWorks の SQL Transpiler ツールがここで役立ちました。データ エンジニアは、このツールの出力を個別に検証し、結果が正しいか確認して、必要に応じて適宜クエリのロジックを調整する必要がありました。結果の確認に役立てるため、BigQuery で実行するテーブル比較ツールを作成し、ETL ジョブの出力データを比較しました。
- レポート変換: MLB では、Business Objects と Looker の 2 つのツールを使用して、エンドユーザー向けレポートを作成しています。Business Objects の各レポートと Looker の各ダッシュボードについて、MLB のビジネス インテリジェンス チームが SQL ロジックとレビュー済みレポート出力を変換して、正確性を担保しました。このワークストリームは、ビジネス インテリジェンス チームが Teradata から BigQuery に直接複製されたデータを利用できたため、ETL 変換ワークストリームとは関係なく実行できました。
- エンドユーザー トレーニング: マーケティング チーム、データ サイエンス チーム、分析チーム内のユーザーがプロジェクトの早い段階で、Teradata から複製されたデータを活用して、BigQuery のトレーニングを受けました。これにより、各チームが十分な時間をかけて BigQuery の構文を学習し、使用しているツールを BigQuery に接続できました。
- セキュリティ構成: ユーザーは、Okta と G Suite を介した MLB の既存 SSO 設定を利用することで、自分のパソコンまたはメールにアクセスするために使用しているものと同じ認証情報を使用して BigQuery にアクセスできるようになりました。別の認証情報を設定する必要がなく、MLB を退職したユーザーのデータアクセス権は直ちに解除されました。
移行により MLB が受けた恩恵
料金: BigQuery のオンデマンド型課金モデルのおかげで、最小限の費用で、コミットメントを購入することなく、並行してパフォーマンス テストを実施できました。パフォーマンス テストでは、MLB で最も大規模かつ多様性に富んだデータセットをいくつかコピーし、実際の SQL クエリを実行して実行時間を比較しました。移行作業を進めるに従い、移行したワークロードの数に比例して BigQuery の費用が増大しました。オンデマンド型から BigQuery Reservations を使用する定額型の課金に切り替えることで、費用の問題を解消し、過剰な負荷を防止し(最大テーブルを対象に 「SELECT * FROM」を誤って実行するユーザーが必ずいます)、未使用の容量をデータ サイエンス チームや分析チームなど組織内の他部門と共有できます。
データの民主化: ユーザーに直接 Teradata にアクセスさせるのは、ネットワーク接続の制約とクライアント ソフトウェアの設定の問題から、不可能ではないにせよ、多くの場合面倒なことでした。これに対し、BigQuery の導入により、ボタンをクリックするだけで G Suite のユーザーまたはグループとデータセットを安全に共有できるようになりました。ユーザーは、BigQuery のウェブ コンソールにアクセスして、自身と共有されているデータを即座に確認して、そのデータに対し SQL クエリを実行できます。コネクテッド シートを使用すると、なじみのあるインターフェースでピボット テーブルを活用して大規模なデータセットを分析することもできます。また、ファイルおよび他のデータベースからデータをインポートして、非公開のデータセットをデータ エンジニアリング チームが一元的に共有しているデータと結合できます。
MLB 本部は、さまざまなデータソースからのデータの取り込みと処理を担当し、組織内では「操舵室」と呼ばれる構想の中で球団固有のデータを各球団と共有しています。以前の操舵室のデータ共有インフラストラクチャでは、Teradata から S3 に毎日データダンプを球団ごと、データセットごとに 1 つずつ出力していたため、レイテンシと同期の問題に悩まされていました。操舵室の新しいインフラストラクチャでは、BigQuery の承認済みビューを利用して、球団に関連のあるデータの特定行にリアルタイムにアクセスさせることができます。たとえば、MLB は、全 30 球団向けの StubHub 売上データを受信しており、各球団が自身のチームの売上のみを閲覧できるよう、球団ごとに承認されたビューを設定しています。BigQuery のインフラストラクチャではサーバーを使用しないため、あるユーザーが他の全ユーザーのパフォーマンスに悪影響を及ぼす心配はありません。このわかりやすいアーキテクチャを以下の図で示します。
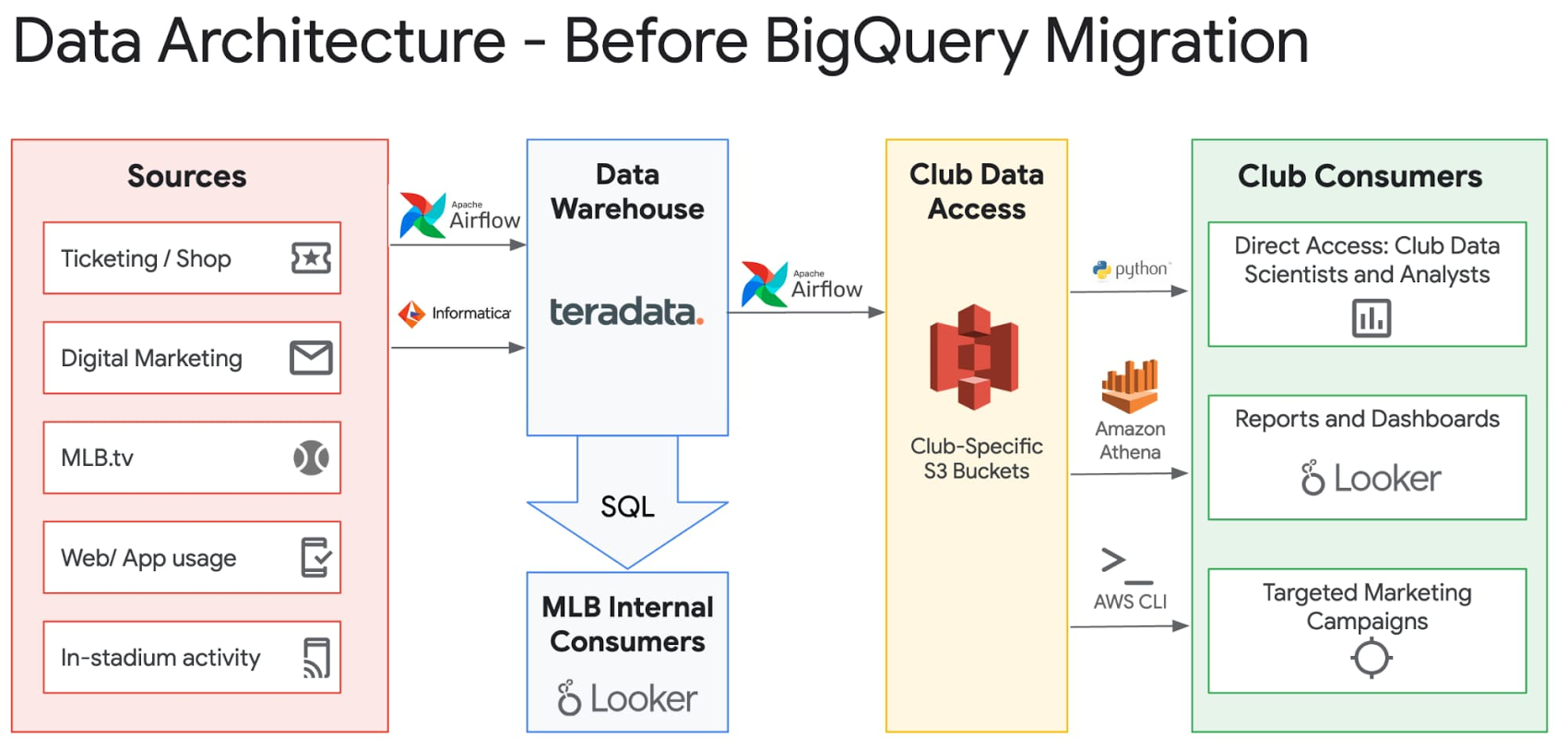
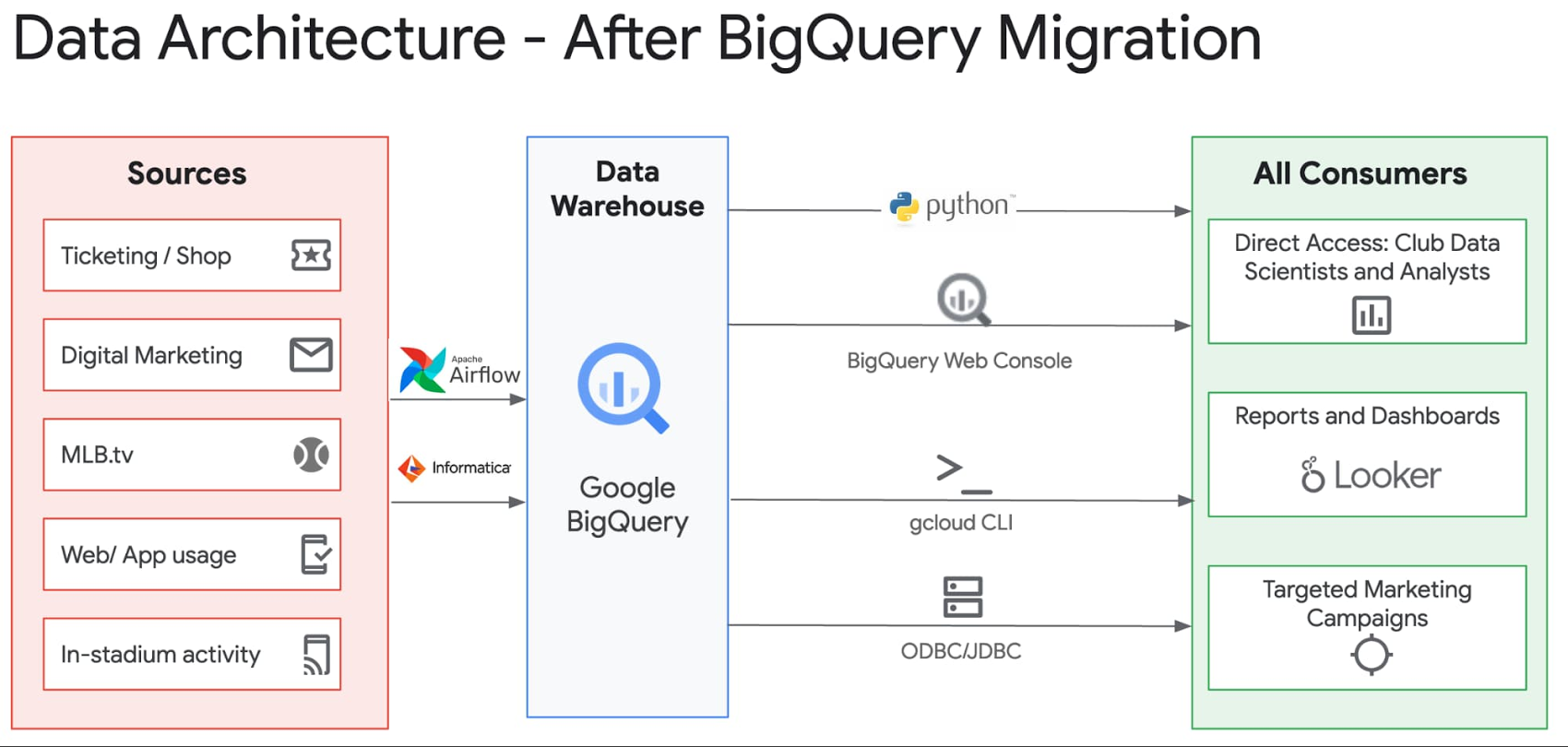
BigQuery への移行による IT 面の成果
パフォーマンスの改善: BigQuery では、Teradata と比較して、クエリが全体的に 50% 早く完了します。多くの場合、Teradata ではただタイムアウトするか失敗する(また、その過程でシステム全体に影響を及ぼす)クエリ、または Teradata にかかる負荷を考えても実行できなかったクエリが、BigQuery では問題なく実行できます。このことは特に、容量が 1 年あたり 150 TB を超え、MLB のウェブサイトとアプリから送信されるヒットレベルのクリックストリームで構成される最大のデータセットに言えることでした。以前は、このデータセットをデータ ウェアハウスの外部に保存し、Hadoop エコシステムから別々のツールで処理する必要があったため、このデータを他のトランザクション関連データセットと結合したいと考えることの多かったアナリストにとっては悩みの種でした。
統合による知見の拡充: BigQuery Data Transfer Service を使用すると、Google 広告、Google キャンペーン マネージャー、Firebase など、MLB が現在使用している複数のサービスとの統合を簡単に設定できます。以前は、こういった種類の統合を設定する場合、手作業でのコーディングが必要な時間のかかる ETL 処理を実行していました。MLB で使用している BI ツールの Looker は、BigQuery とシームレスに統合でき、ビジネス ユーザーがデータにアクセスして詳細な検討を行うための洗練された高機能インターフェースを備えています。また、サードパーティ ベンダーも BigQuery を強く支持してくれています。例を挙げると、MLB のマーケティング分析チームは、Google 広告から取得したデータを使用して、広告の費用と配置に関する決定内容を通知できます。
運用上のオーバーヘッドの削減: Teradata を使用しているときは、フルタイムの DBA チームを設けて、不適切なクエリ、バックアップの問題、スペースの割り振り、ユーザーの権限付与などのデータベースに関する問題に 24 時間 365 日対応させる必要がありました。BigQuery を導入したことで、このチームがもう必要ないことがわかりました。Google Cloud は、サービス上の重大な問題にも対応してくれ、今ではテーブル バックアップの復元など、以前行っていた管理業務をエンドユーザーが簡単に実施でき、IT チームがより戦略に重点を置いた業務に集中できます。
デベロッパーの満足度向上: MLB のデータ エンジニアリング スタッフ、データ サイエンス スタッフ、分析スタッフは、Teradata 内でマニュアルが用意されていないこと、わかりにくい隠れた欠点があることでしばしば不満を感じていました。Teradata がより規模の大きい企業向けデプロイで主に使用されていたことを考えると、Stack Overflow などのサイトに掲載されるオンライン マニュアルは限られていました。これに対し、BigQuery はマニュアルが充実しており、抵抗なく利用を開始できる(Google Cloud ユーザーなら無料でお試し可能)ことから、すでに問題解決、Q&A の確認、サービスの機能の学習のためオンラインで利用可能なリソースが Teradata より多く準備されているように思われます。
価値創出までの時間の短縮: BigQuery エンジニアリング チームが定期的に追加してくれる有用な新機能を即座に利用するために、システムを停止させたり、アップグレード計画を立てたりする必要がありません。
BigQuery がビジネスにもたらす影響
BigQuery への移行を完了した今、ファンの皆様に関するデータを活用して、ファンの皆様とリーグにサービスを提供するため、より包括的で困難のない手法を取ることができます。BigQuery への移行により、すでに以下のプロジェクトが推進されています。
- OneView: これは、30 件を超える関連データソースを 1 個のテーブルに編纂し、ファンの方 1 人につき 1 行を割り当てて、下流方向のパーソナライズと分類の構想実現を推進するため、MLB のデータ プラットフォーム プロダクト チームが立ち上げた新しい構想です。以前であれば、このテーブルにデータを格納するため、増分読み込みプロセスを長時間かけて開発し、その問題解決に当たる必要があったと思います。今では、BigQuery のおかげで、このテーブル全体を定期的に更新しても作業がすぐに完了し、他のデータ ワークロードのパフォーマンスに悪影響が出ることはありません。また、BigQuery の ARRAY データタイプと Struct データタイプを使用して、このテーブルの個別の列内に繰り返しのデータ要素をネストすることで、ユーザーが検索や結合を行うことなくより詳細なデータを検証できます。この OneView テーブルは、ファンの方それぞれに合わせたニュース記事配信を強化するためにすでに使用されています。
- フォーム送信のリアルタイムでの報告: Google 提供の Dataflow テンプレートを使用して Pub/Sub から BigQuery にリアルタイムにデータをストリーム配信することで、「Opening Day Pick ‘Em」などの企画でのフォーム送信に関するリアルタイム報告機能を備えた Looker ダッシュボードを作成できます。これにより、MLB の編集チームが最新の結果分析レポートを作成できます。
MLB の新しいデータ ウェアハウスが導入されたおかげで、以前よりもデータ ステークホルダーに対し優れたサービスを提供できるようになりました。ファンの皆様により良いオンライン サービスと対面でのサービスをデータドリブンに提供できることを大変嬉しく思っています。
-メジャーリーグ ベースボール、データ エンジニアリング担当バイス プレジデント Robert Goretsky
