Cloud Data Fusion による SAP との統合のご紹介
Google Cloud Japan Team
※この投稿は米国時間 2021 年 4 月 13 日に、Google Cloud blog に投稿されたものの抄訳です。
企業では現在、データ分析と分析情報に基づいたアクションを求める声が高まっています。通常、これらを支える貴重なデータはミッション クリティカルな運用システムに保存されています。Google Cloud は、今日市場に出回っている数々のアプリケーションの中でも ERP ソフトウェアのリーディング プロバイダである SAP との統合を実現いたしました。この統合は、SAP データの価値を迅速かつ容易に引き出せるようにするものです。
また、Google Cloud ネイティブなデータ統合プラットフォームである Cloud Data Fusion で、SAP Business Suite、SAP ERP、S/4HANA のデータをシームレスに取得できるようになりました。Cloud Data Fusion は、クラウド ネイティブなフルマネージド データ統合および取り込みサービスです。ETL デベロッパー、データ エンジニア、ビジネス アナリストの効率的な ETL / ELT パイプラインの構築、管理を支援し、BigQuery 上のデータ ウェアハウス、データマート、データレイクや、Cloud SQL、Spanner などのシステム上のオペレーション レポート システムの構築を高速化します。本日、SAP データの価値を今までより簡単に引き出せる SAP テーブル バッチソースを一般公開することを発表いたします。この機能により、Cloud Data Fusion を使用して SAP アプリケーション データを簡単に統合し、Looker を通じて有益な情報を取得することが可能になりました。また、クラス最高の機械学習サービスを Google Cloud 上で活用し、さまざまなデータセットと SAP データを組み合わせることで、ビジネスに関する分析情報を得ることができます。具体的な使用例としては、ERP のトランザクション データと IoT データを結合したデータで機械学習を実行することによる予測メンテナンス、SAP アプリケーションと Cloud SQL ベースのアプリケーションの統合、不正行為の検出、支出分析、需要予測などがあります。
SAP テーブル バッチソースを Cloud Data Fusion で使用する際のメリットは以下のとおりです。
デベロッパーの生産性
Cloud Data Fusion ではすべての操作を視覚的に行えるため、Pipeline Studio を使用して、SAP ECC や S/4HANA から読み取るパイプラインをすばやく設計できます。Data Fusion の事前構築済みの変換を使用すると、SAP と SAP 以外のシステムのデータを容易に結合し、データ クレンジング、集計、データ準備、ルックアップなどの複雑な変換を行い、データから分析情報をすばやく得ることができます。
価値創出までの時間
今までのアプローチでは、データ ウェアハウジング システム上でモデルを定義する必要がありました。Cloud Data Fusion では、BigQuery を使用することで、この作業を自動化できます。BigQuery への書き込みを行うデータ パイプラインを設計し、実行すると、Data Fusion が BigQuery でスキーマを自動生成します。モデルの事前構築が不要なため、今までより早くデータの分析情報を取得でき、組織の生産性を高めることができます。
パフォーマンスとスケーラビリティ
Cloud Data Fusion は水平スケーリングを行ってパイプラインを実行します。ユーザーは、エフェメラル クラスタか専用のクラスタを活用してパイプラインを実行できます。SAP のバッチソース プラグインは、SAP システムからデータを抽出する際に、SAP アプリケーション サーバーのリソースと Cloud Data Fusion のランタイム リソースの双方に基づいてデータ パイプラインを自動的に調整し、パフォーマンスを最適化します。並列処理の構成に誤りがあっても、プラグインのフェイルセーフ メカニズムにより、ソースシステムで問題が発生することはありません。
SAP テーブル バッチソースの仕組み
すべてのテーブルデータを SAP から BigQuery や他のシステムに転送する
Pipeline Studio では、複数の SAP ソーステーブルをデータ パイプラインに追加してから、Joiner 変換で別の SAP ソーステーブルと結合できます。Joiner は Cloud Data Fusion の処理レイヤで実行されるため、SAP システムに影響が及ぶことはありません。たとえば、顧客マスター データマートを作成する場合は、まずプラグインを使用して SAP の関連テーブルをすべて結合してから、Cloud Data Fusion の Pipeline Studio でそのデータ用に複雑なパイプラインを構築できます。
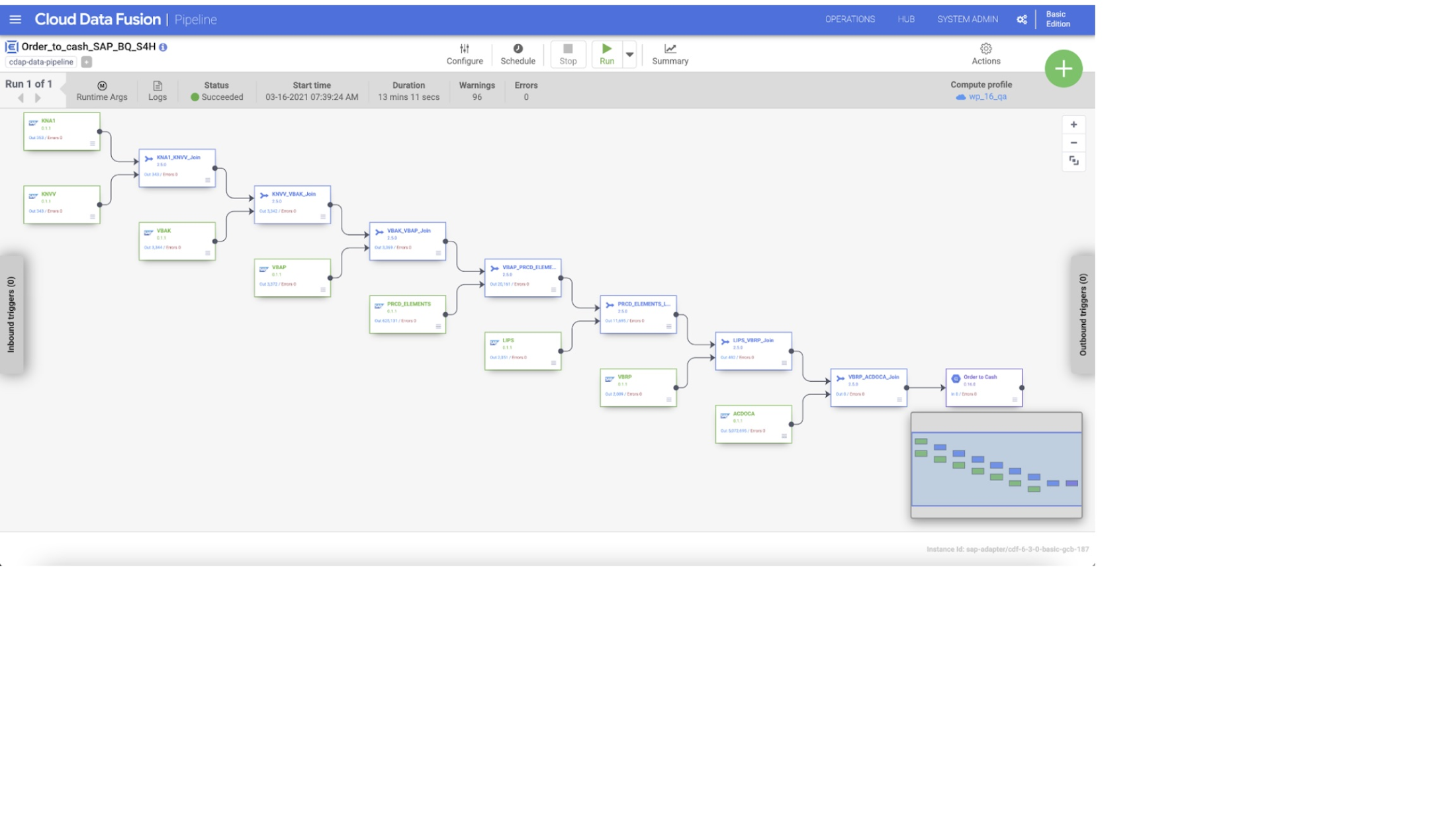
テーブル レコードを並行して抽出する
レコードを並行して抽出するには、[Number of Splits to Generate(生成する分割数)] プロパティを使用して SAP テーブル バッチソース プラグインを構成します。このプロパティが空白でも、システムが適切な値を設定してパフォーマンスを最適化します。
条件に基づいてレコードを抽出する
SAP テーブル バッチソース プラグインを使用すると、[Filter Options(フィルタ オプション)] プロパティを使用してフィルタ条件を指定できます。フィルタ条件は、OpenSQL 構文で指定します。このプラグインは SQL の WHERE 句を使用してテーブルをフィルタします。レコードは、指定された一連の値または値の範囲を持つ特定の列などの条件に基づいて抽出できます。また、複数の条件と AND 句または OR 句を組み合わせた複雑な条件(例: TIMESTAMP >= ' 20210130100000' AND TIMESTAMP <= ' 20210226000000)も指定できます。
抽出するレコード数を制限する
[Number of Rows to Fetch(取得する行数)] プロパティを使用して、指定したテーブルから抽出するレコード数を制限することもできます。これは、開発シナリオやテストシナリオで特に有用です。
データから得られる利益を最大化する
Google Cloud Platform を使用すれば、膨大な量のソーシャル データ、運用データ、トランザクション データ、IoT データをスケーリングおよび処理して、価値を引き出し、分析情報をすばやく得ることができます。さらに Cloud Data Fusion は、既存のエンタープライズ アプリケーションとデータ ウェアハウスへの数多くのコネクタを提供します。Cloud Data Fusion で SAP データを統合し、BigQuery で価値を引き出すネイティブ機能を使用して、迅速にインテリジェントな意思決定を行うことで、目標に一歩近づき、今まで以上に多くの成果を上げることができます。
SAP テーブル バッチ コネクタを試すには、Data Fusion の新しいインスタンスを作成して、ハブから SAP プラグインをデプロイしましょう。詳しくは、SAP テーブル バッチソースのユーザーガイドをご参照ください。また、大手企業がデータ統合などの Google のデータ ソリューションを活用してイノベーションを実現した経緯や方法について、5 月 26 日に開催される Google Cloud のデータクラウド サミットで詳しくご紹介します。ぜひご覧ください。
-プロダクト管理データ分析担当 Chaitanya(Chai)Pydimukkala



