Beam ノートブックを使った大規模でインタラクティブなパイプラインの実行
Google Cloud Japan Team
※この投稿は米国時間 2022 年 10 月 20 日に、Google Cloud blog に投稿されたものの抄訳です。
Apache Beam および Dataflow ユーザーの皆様へ
すでに Beam のテスト、パイプラインのプロトタイプ化、データセットに関する前提条件の検証が済んでいる場合、Beam ノートブックや、Google Colab または Jupyter Notebooks といったその他のインタラクティブな代替サービスを使ったことがあるかもしれません。
また、ノートブックで小さいプロトタイプのパイプラインを実行するのと、Dataflow で本番環境のパイプラインを実行する違いにもお気づきかもしれません。もし、より大規模な本番環境データセットの集約を、ノートブック内からインタラクティブに処理、検査したい場合はどうしたらよいでしょうか。ノートブックを実行している 1 つのマシンのみでパイプラインを実行することはできません。パイプラインを実行する能力が不足しているからです。
そこで、この投稿では、ノートブック管理クラスタ上のインタラクティブな FlinkRunner をご紹介します。これにより、パイプラインを大規模に実行し、結果をノートブック管理クラスタ上の FlinkRunner でインタラクティブに検査できます。FlinkRunner は、Flink を使った Dataproc と Docker のコンポーネントで構成されていて、長期的なクラスタのプロビジョニングを実現します。
今回の投稿では、3 つの例を使ってインタラクティブな FlinkRunner をご紹介します。すべてノートブック内で実行します。
小規模なノートブック管理クラスタによるスターターの文字カウントの例
より大きなクラスタを使用して数千万のフライト レコードを処理し、各航空会社で遅延しているフライトの数を把握する例
より大きなクラスタを再利用して、事前トレーニング済みのモデルで 5 万枚の画像に対して ML 推論を実行する例
こうした例の費用を管理したい場合は、パイプラインのオプションを使用してデータとクラスタのサイズを減少させることもできます。最初の例は 1 時間あたり最大 $1、他の 2 つは 1 時間あたり最大 $20 で利用できます(Dataproc の料金と VM インスタンスの料金から推定)。実際の費用は異なる場合があります。オプションとして、ソースデータとパイプライン オプションを構成することで、費用を削減することもできます。前提条件
前提条件
Beam ノートブックをインスタンス化していれば、空のノートブック(ipynb)ファイルを作成して、選択したノートブック カーネルで開くことができます。バグ修正、最適化、新機能を利用するために、常に最新の Beam バージョンでノートブック / IPython カーネルを使用するようにしてください。Dataflow でホストされている Beam ノートブックでは、バージョン 2.40.0 以降の Beam のノートブック カーネルを使用してください。
始める前に、ご自身のプロジェクトで必要なサービスが有効になっており、権限が付与されていることをご確認ください。ノートブックで以下を実行すると、現在のユーザーに関する関連情報を見つけることができます。
ノートブック管理クラスタ上のインタラクティブな Flink は、内部で Dataproc を使用しています。
スターターの例 - 文字カウント
文字カウントの例は、すでに何度かご覧になったことがあるかと思います。1 つのマシンで InteractiveRunner や DirectRunner を使って、カウントしたワードを処理、検査する方法もご存じでしょう。
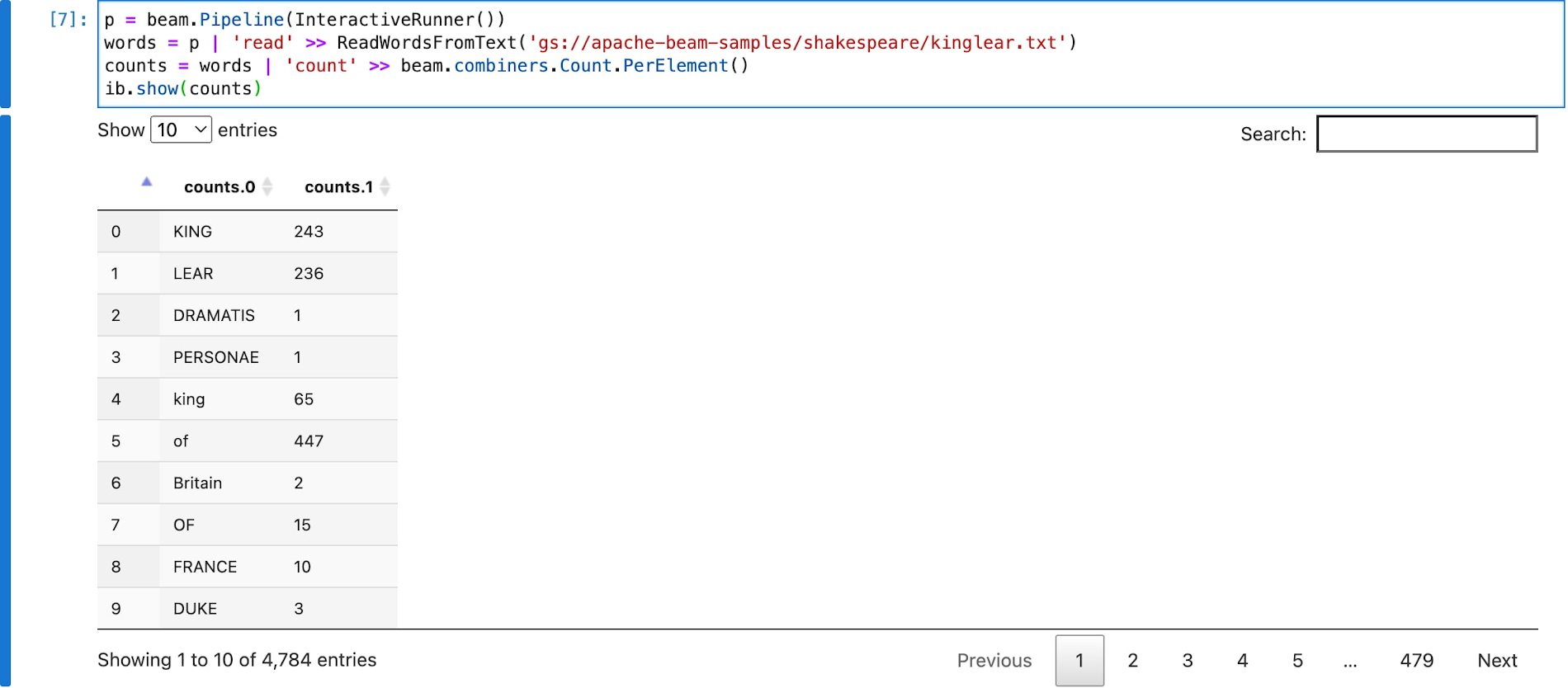
また、コピーや貼り付け、ワークスペースをまたいだ移動、Cloud SDK の設定をしなくても、まったく同じノートブック内から Dataflow 上のパイプラインをワンショットのジョブとして実行できます。
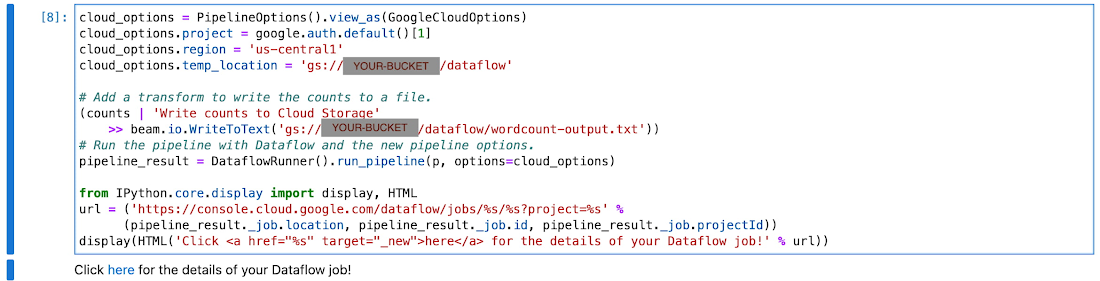
ノートブック管理クラスタ上で Flink を使ってインタラクティブに実行するには、ランナーを変更し、オプションでいくつかのパイプライン オプションを変更するだけです。
ノートブック管理の Flink クラスタは、パイプライン オプションを通して構成可能です。いずれの例でも、これらのインポートが必要です。
その後、開発と実行のための構成を設定します。
上記は最低限必要な構成です。この後の例で、さらにカスタマイズできます。
文字カウントの例のソースコードは、こちらでご覧になれます。これを interactive_flink_runner で修正し、ノートブックでパイプラインを構築します。この例では、入力ファイルとして gs://apache-beam-samples/shakespeare/kinglear.txt を使用しています。
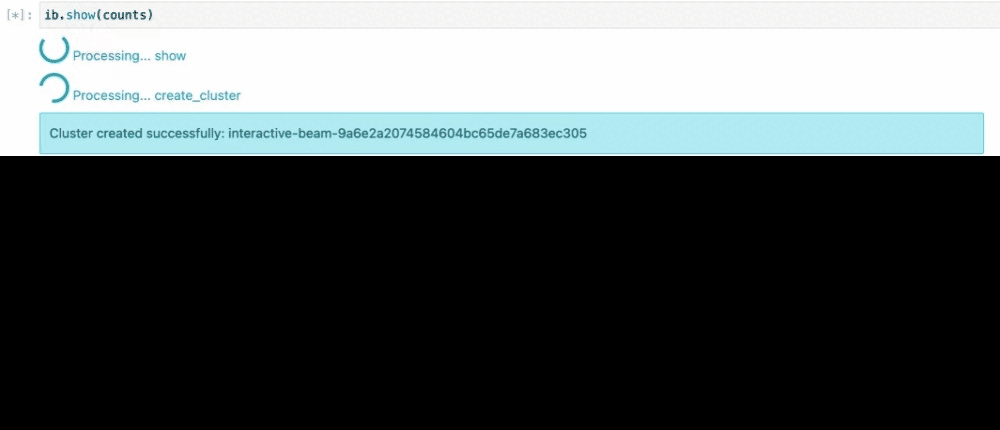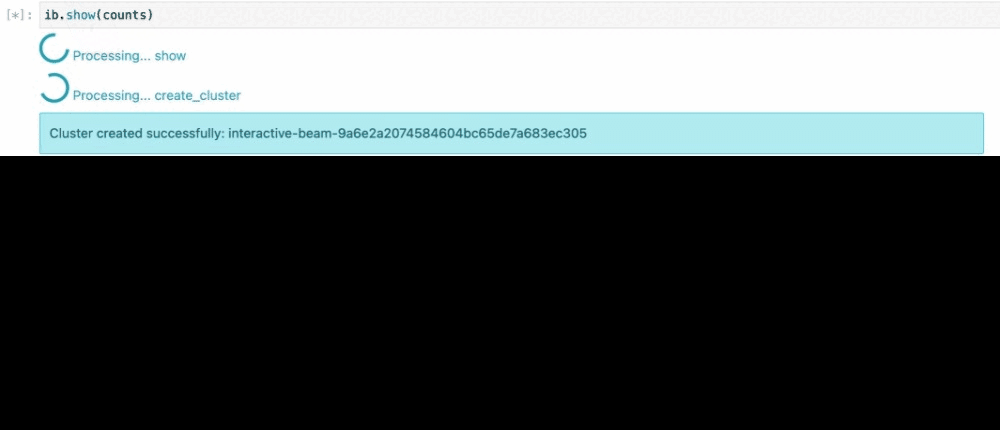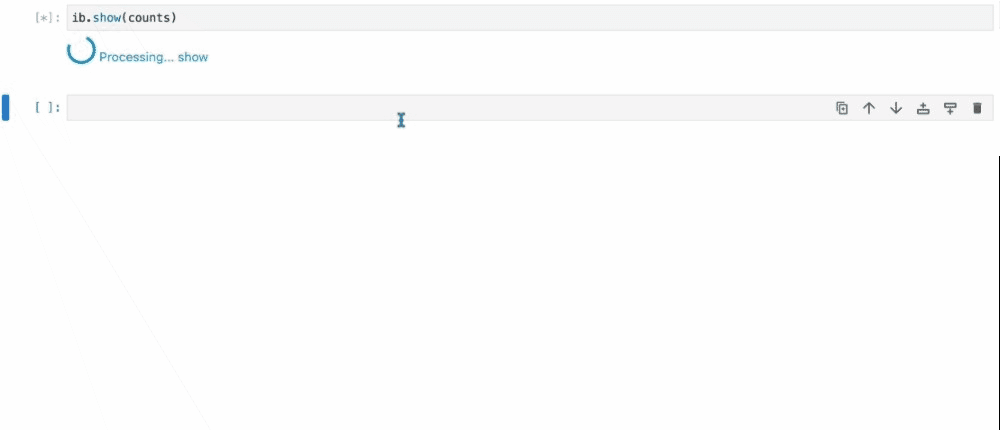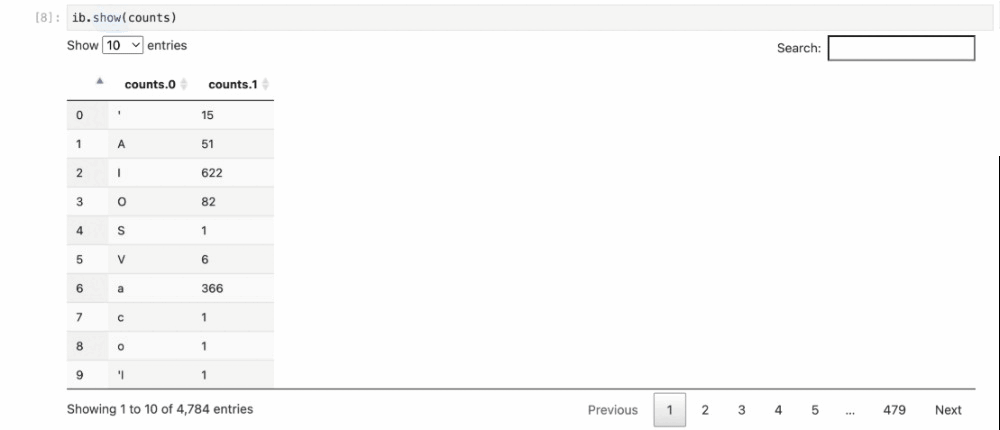
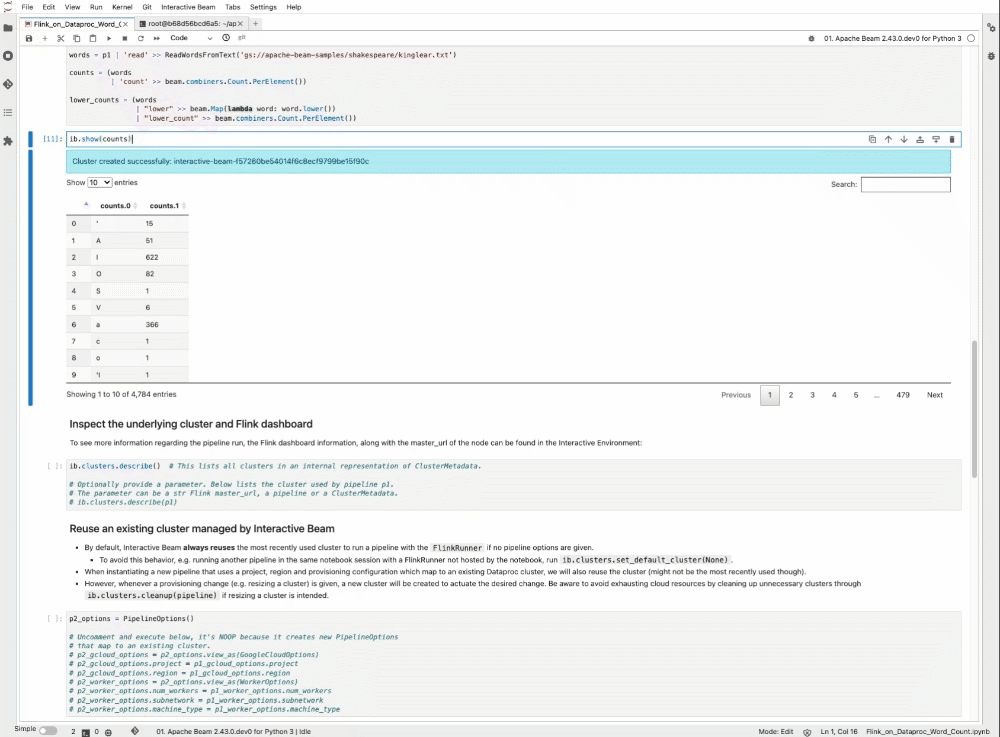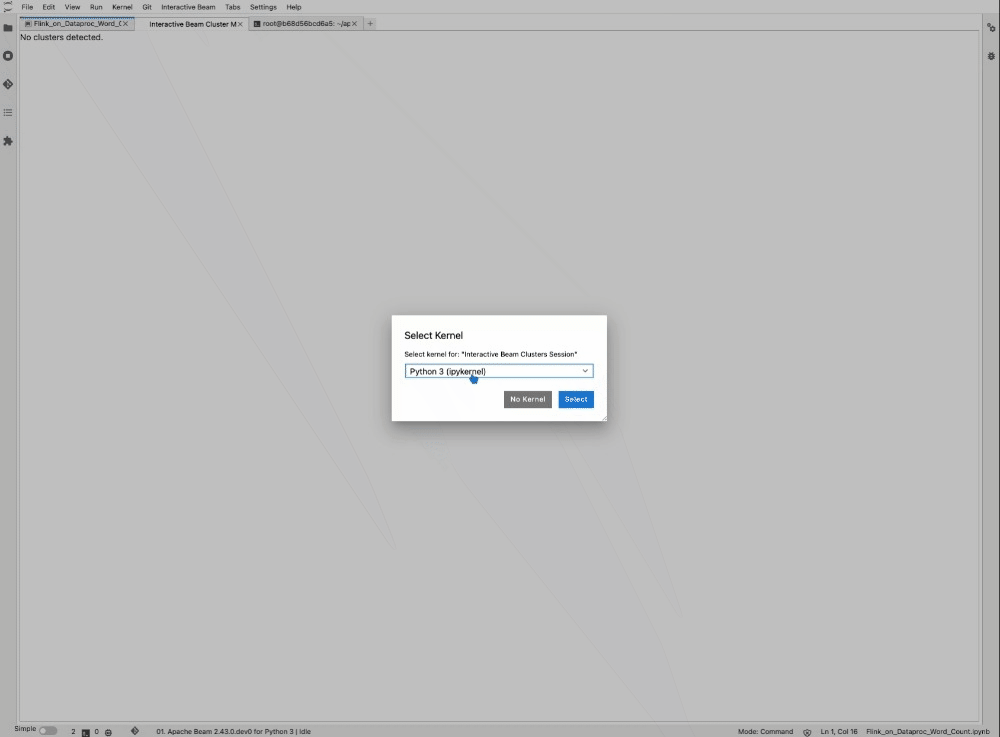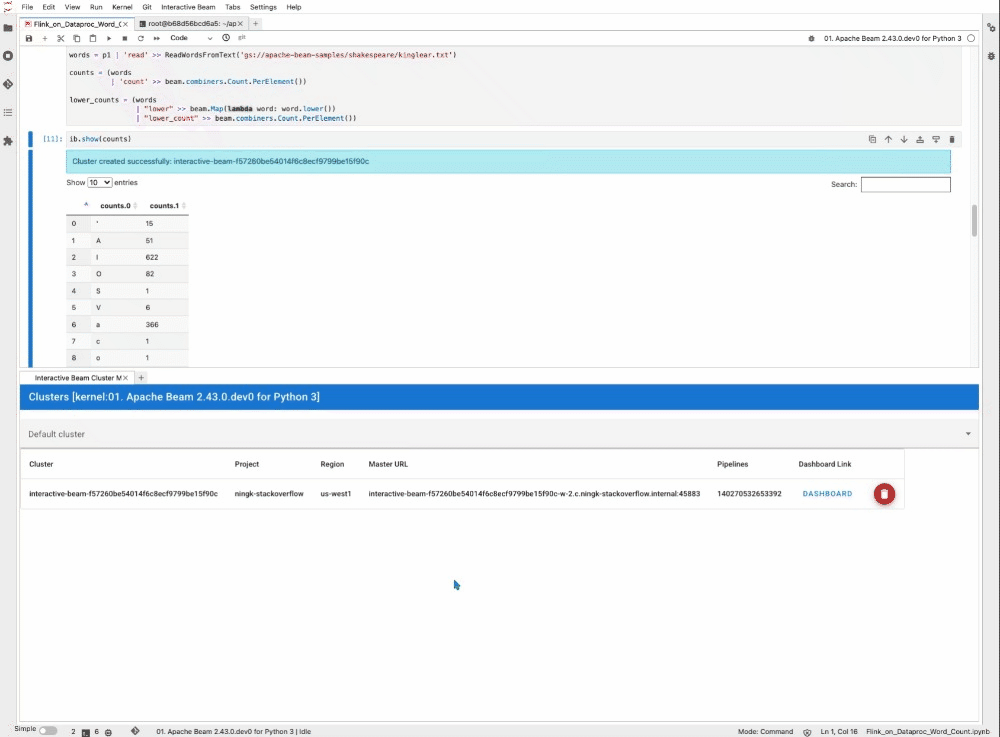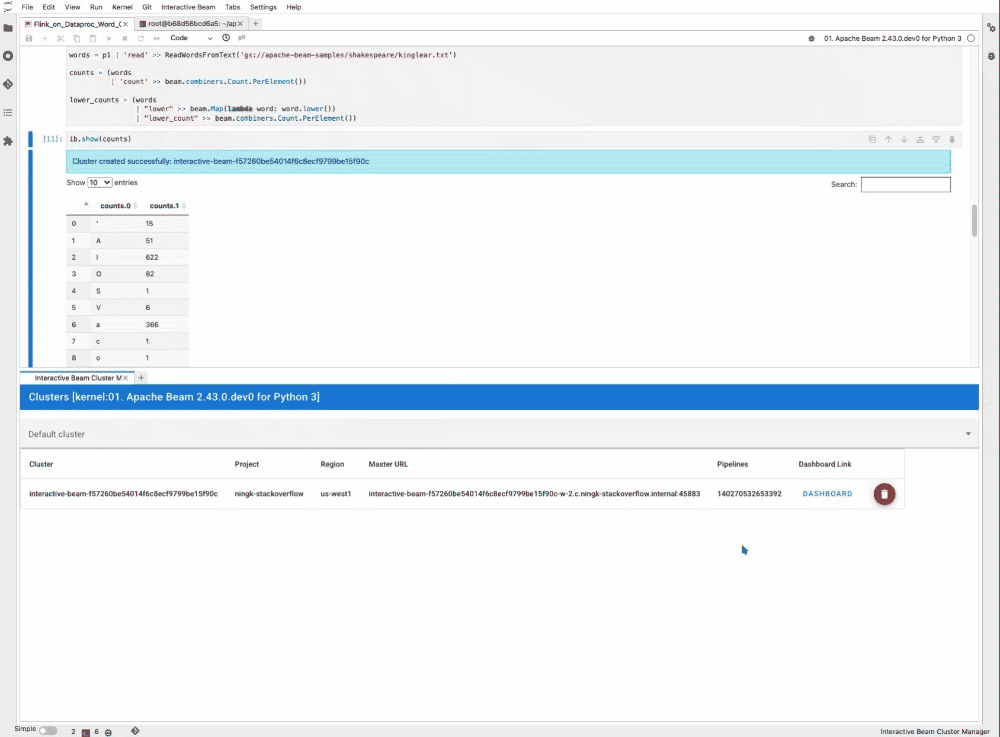
PCollection の counts を検査すると、暗黙的に Flink クラスタが起動し、パイプラインが実行され、その結果がノートブックにレンダリングされます。
例 2 - 遅延しているフライトの数を把握する
この例では、BigQuery のデータシート(bigquery-samples.airline_ontime_data.flights)から 1,700 万件以上の記録を読み込み、2010 年以降、すべての航空会社でどれくらいのフライトが遅延しているのかを数えています。
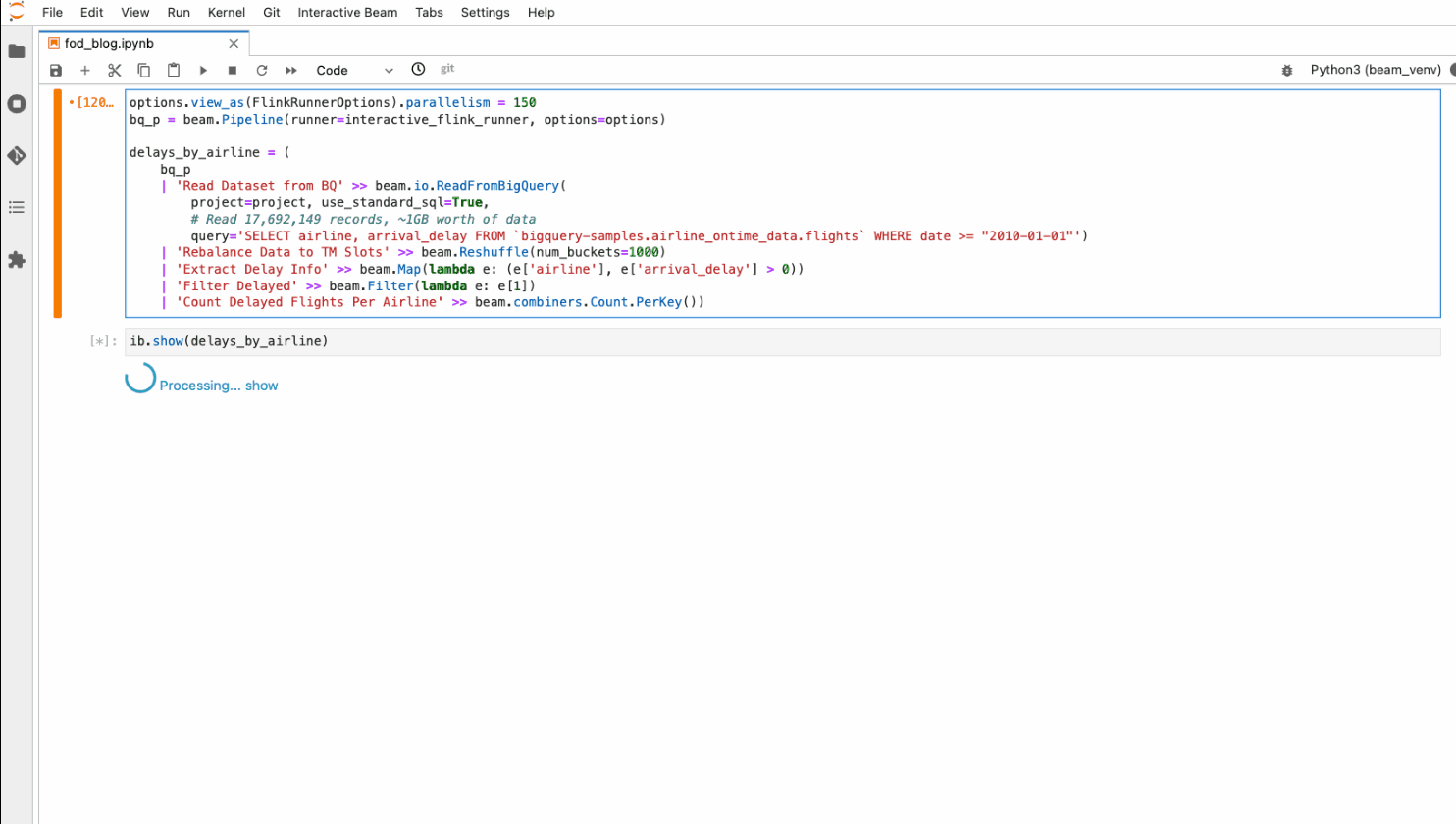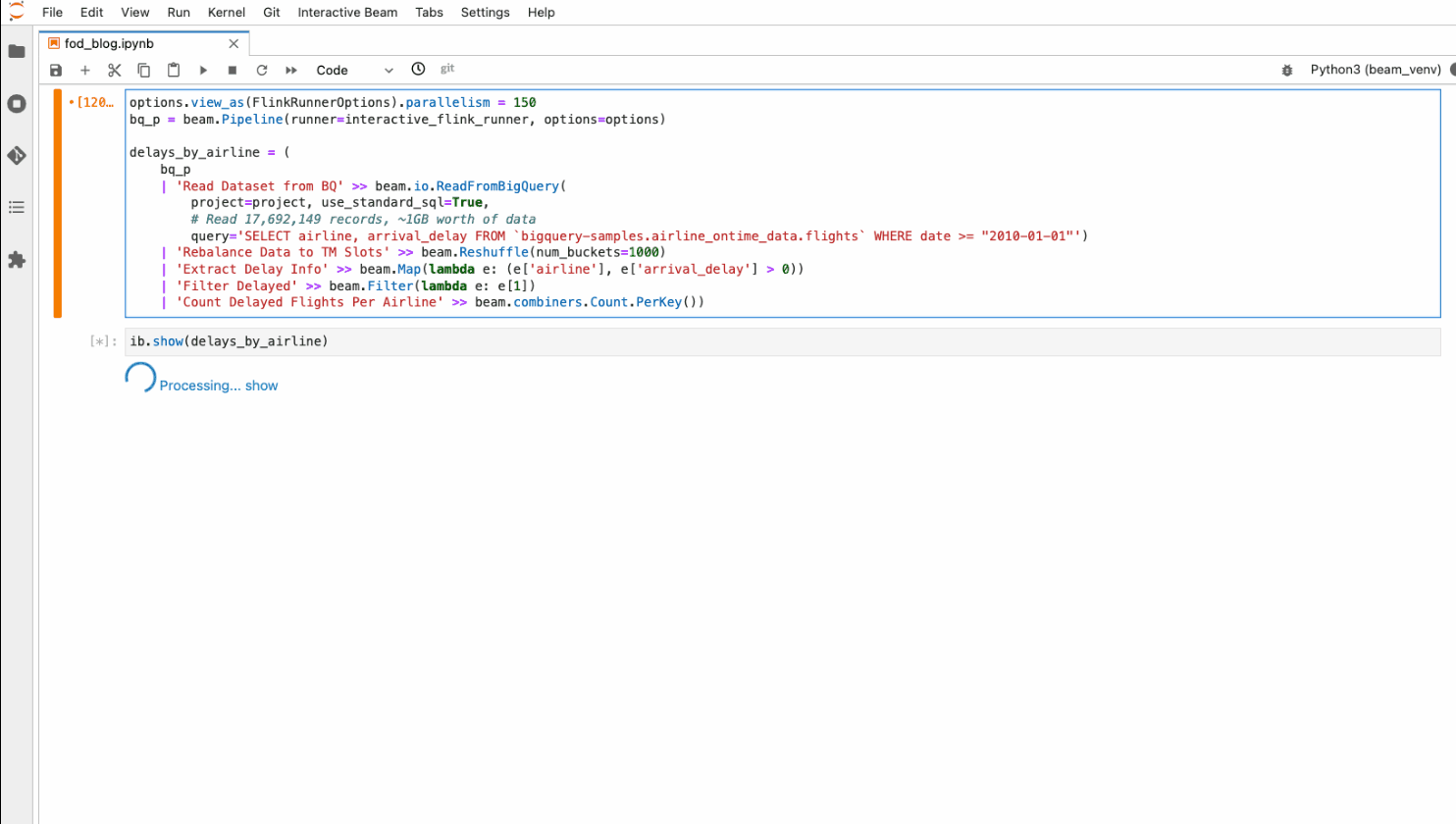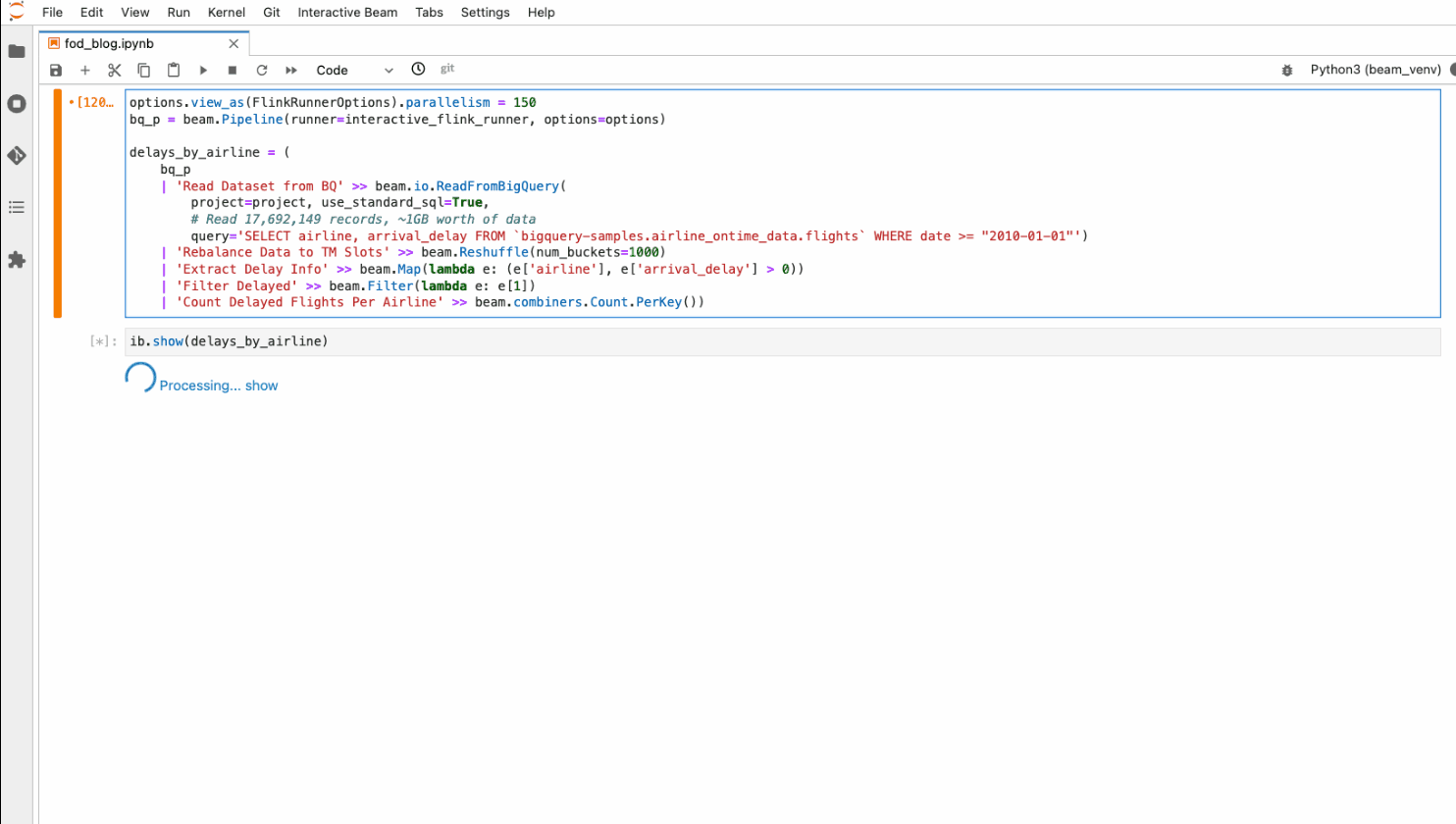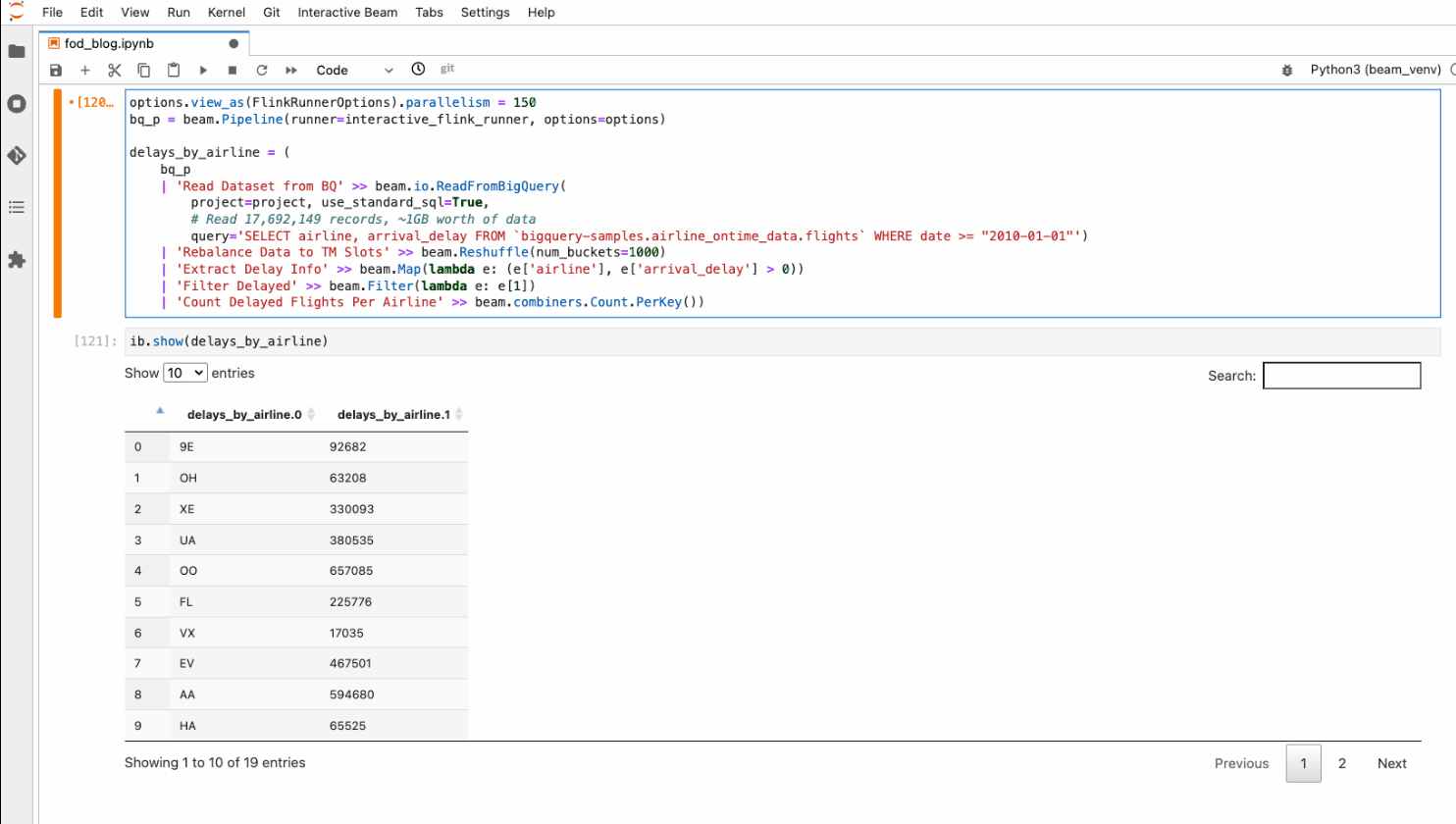
通常の InteractiveRunner を 1 つのノートブック インスタンスで直接実行した場合、データサイズは 1 GB 以下と比較的小さいのですが、レコード数が多いため、読み込みと処理に 1 時間以上かかることもあります。また、これ以上データが大きくなると、パイプラインが OOM したり、ディスク容量が不足したりする可能性もあります。ノートブック管理クラスタ上のインタラクティブな Flink を使えば、より大きな容量と高いパフォーマンス(たとえば 4 分以内)で作業しながら、パイプラインのステップを一つひとつ積み上げ、ノートブック内で結果を逐一検査することができます。
これには、BigQuery サービスを有効にしておく必要があります。
以下のオプションを使えば、より大きなクラスタを構成できます。BigQuery の読み込みクエリに「上限 1000」などの制約を追加して、読み込むレコードを制限できます。BigQuery から読み込んだデータのサイズに応じて、オプションの値を減らすこともできます。
ノートブックで ib.show() や ib.collect() を使って PCollection の結果を検査する際、Beam は暗黙的にパイプラインのフラグメントを実行してデータをコンピューティングします。実行の並列処理をインタラクティブに調整できます。
上記の構成によりノートブックでデータを検査する場合、Google Cloud 上の Flink クラスタ(内部は Dataproc)を 40VM で暗黙的に起動または再利用し、parallelism を 150 に設定してパイプラインを実行するよう Beam に指示しているということになります。
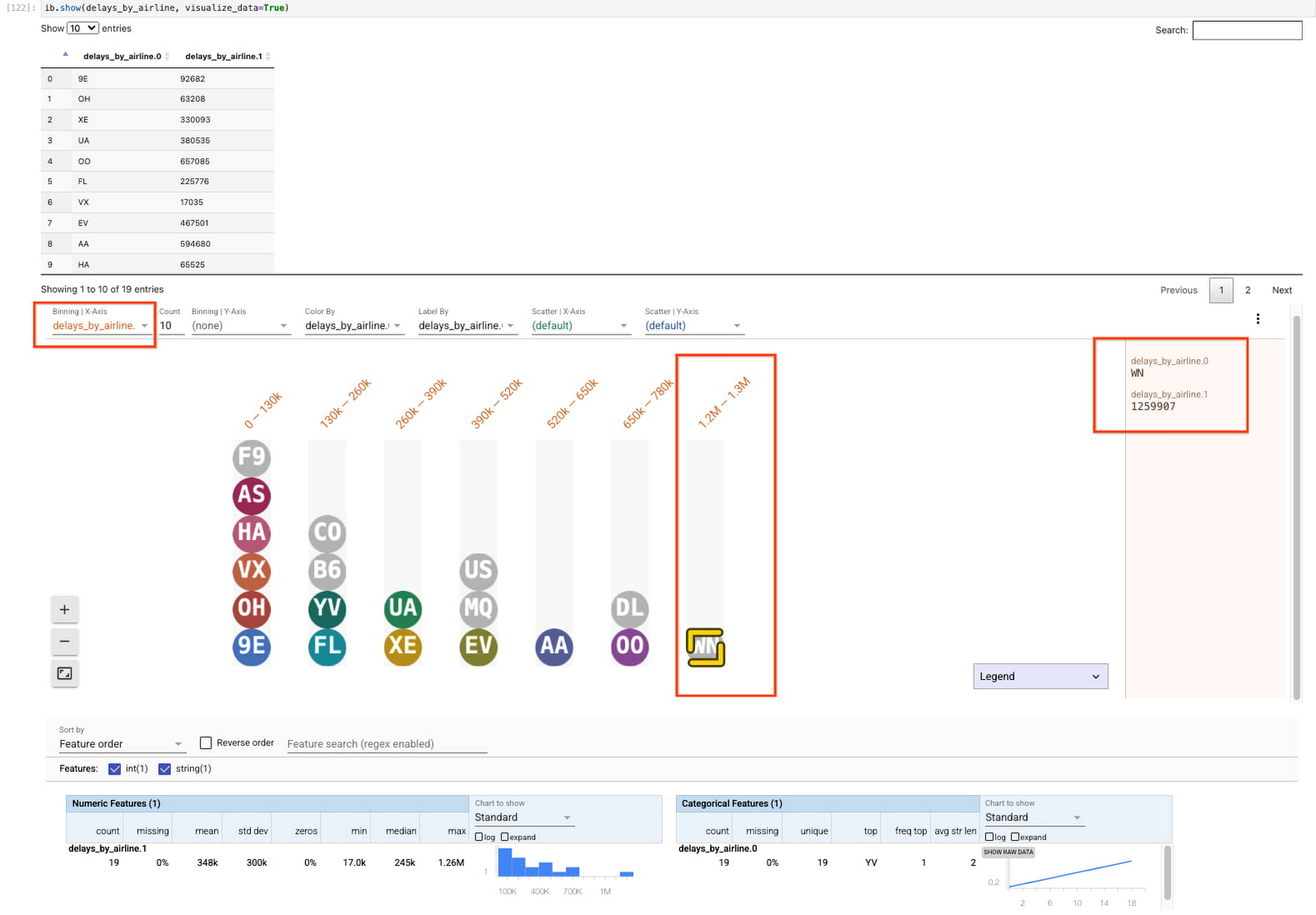
ib.show() でデータを検査する際に、visualize_data=True を含めることができます。可視化されたデータをその数でビニングすると、最も多くの遅延フライトがデータセットに記録されているのは、WN 航空であることがわかります。
例 3 - 大規模でインタラクティブな ML 推論を実行
RunInference の例では、ノートブック内の 50,000 の画像ファイル(280 GB 以下)を分類します。
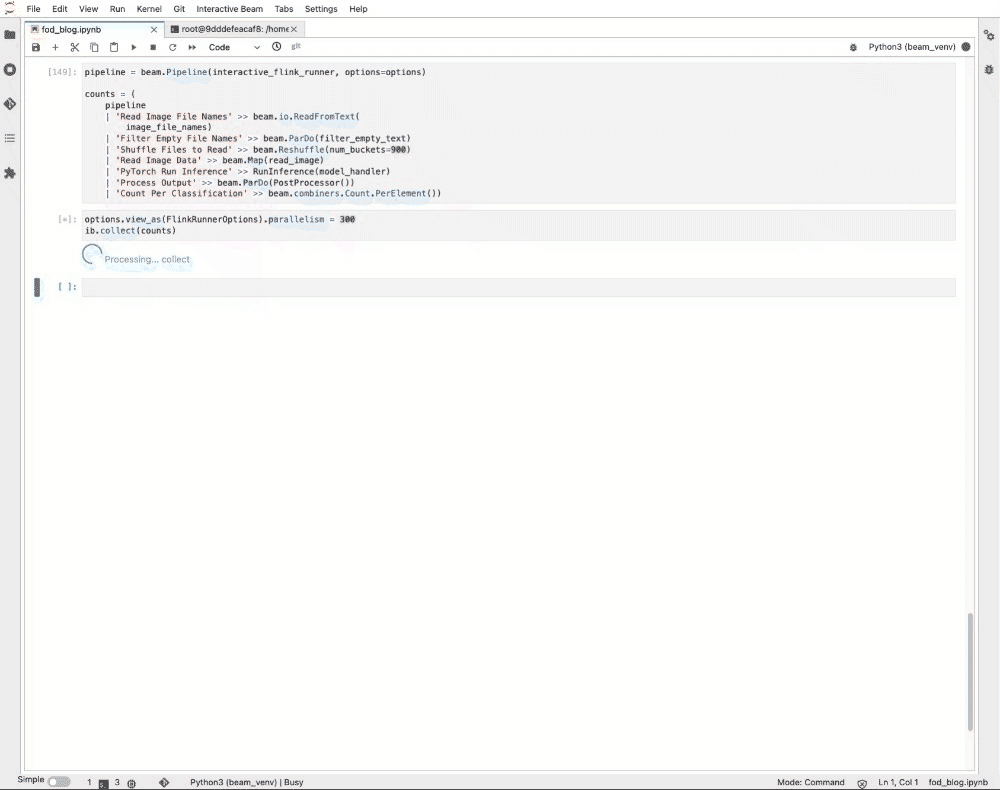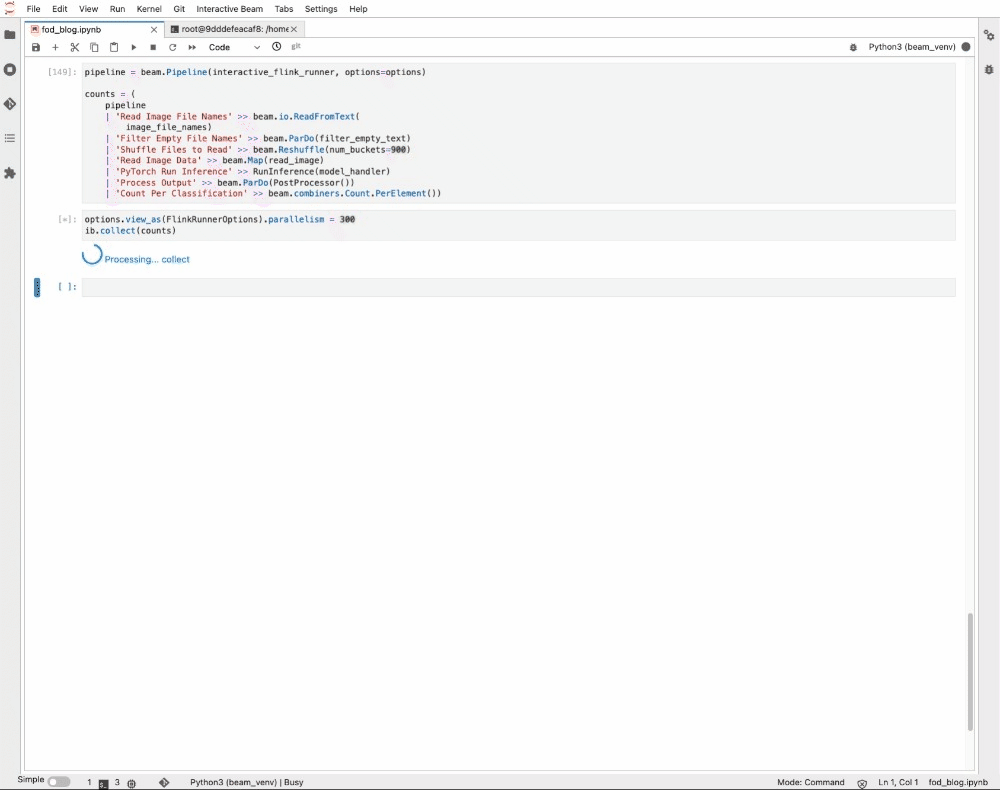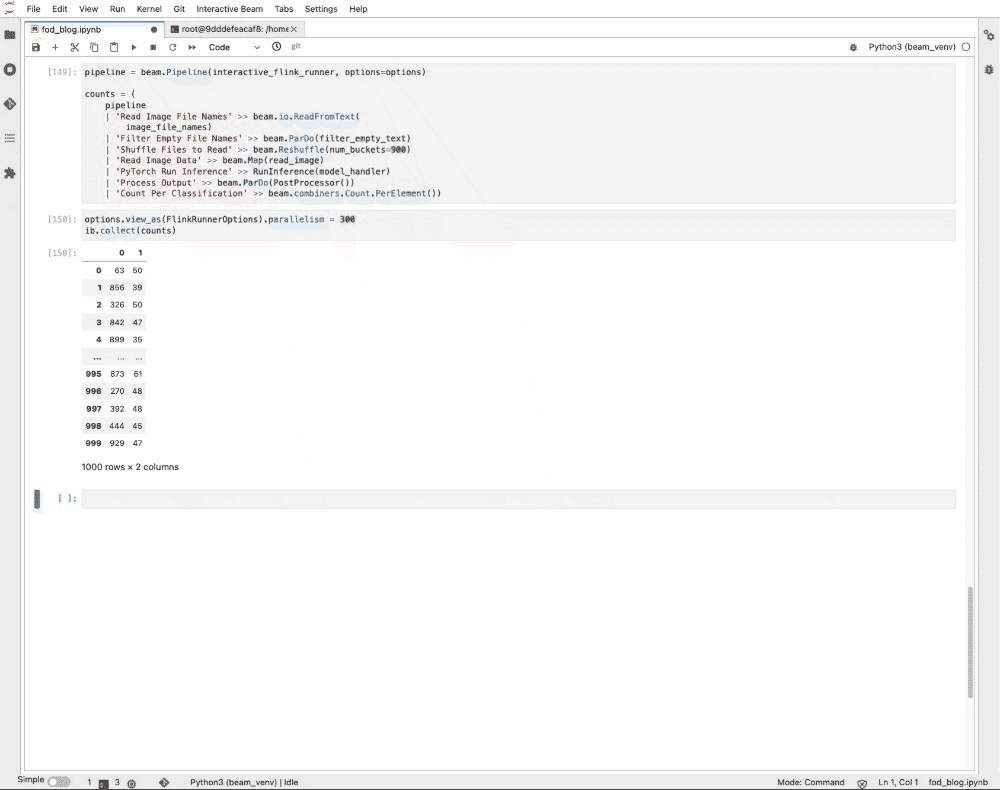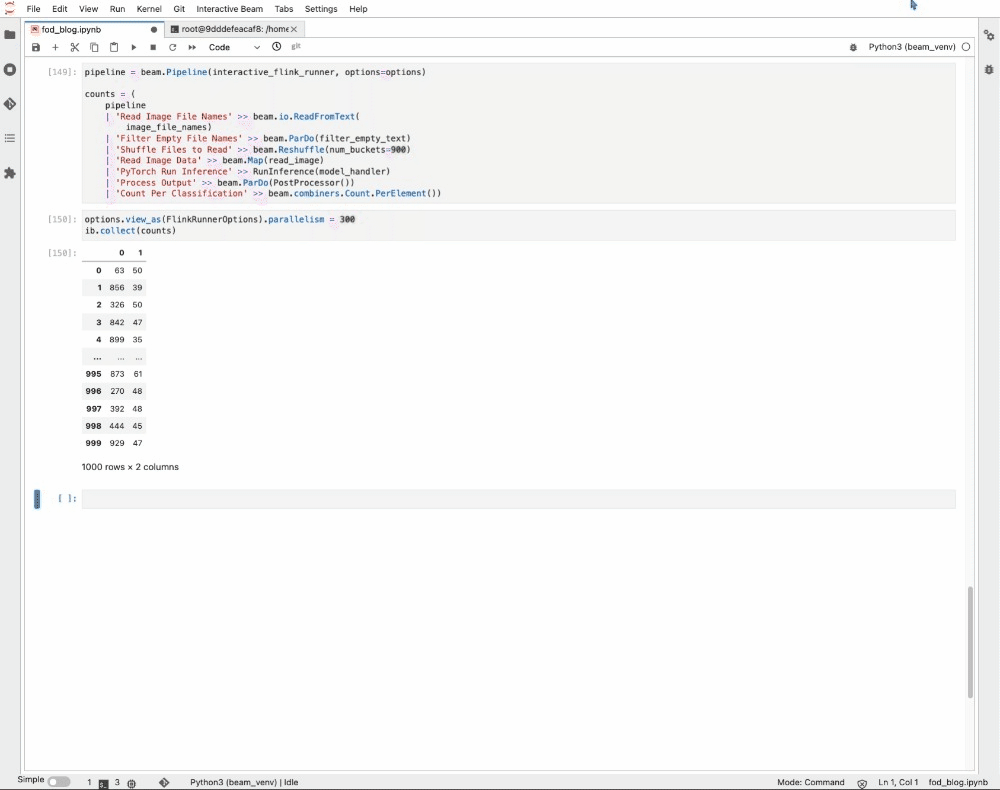
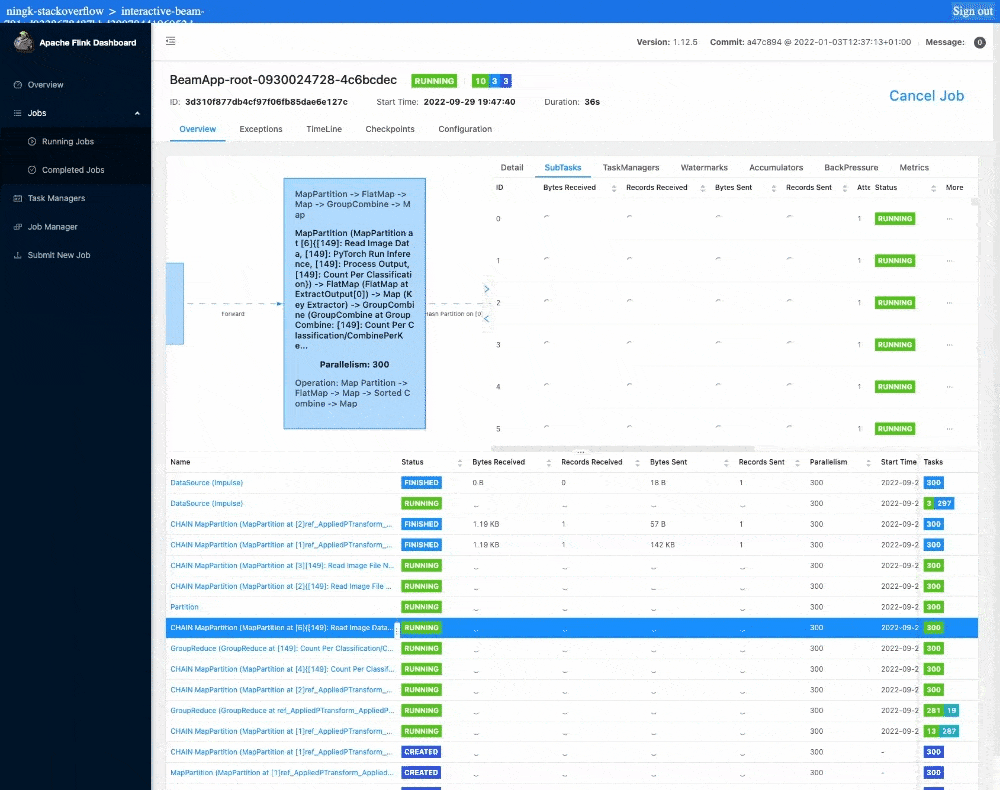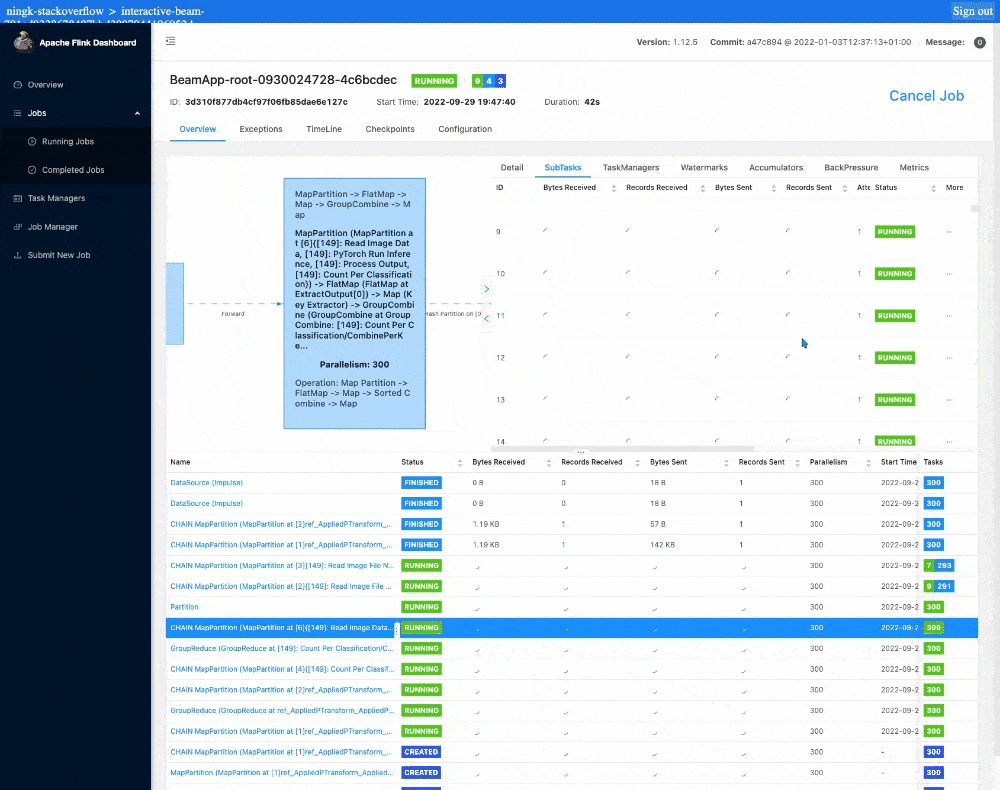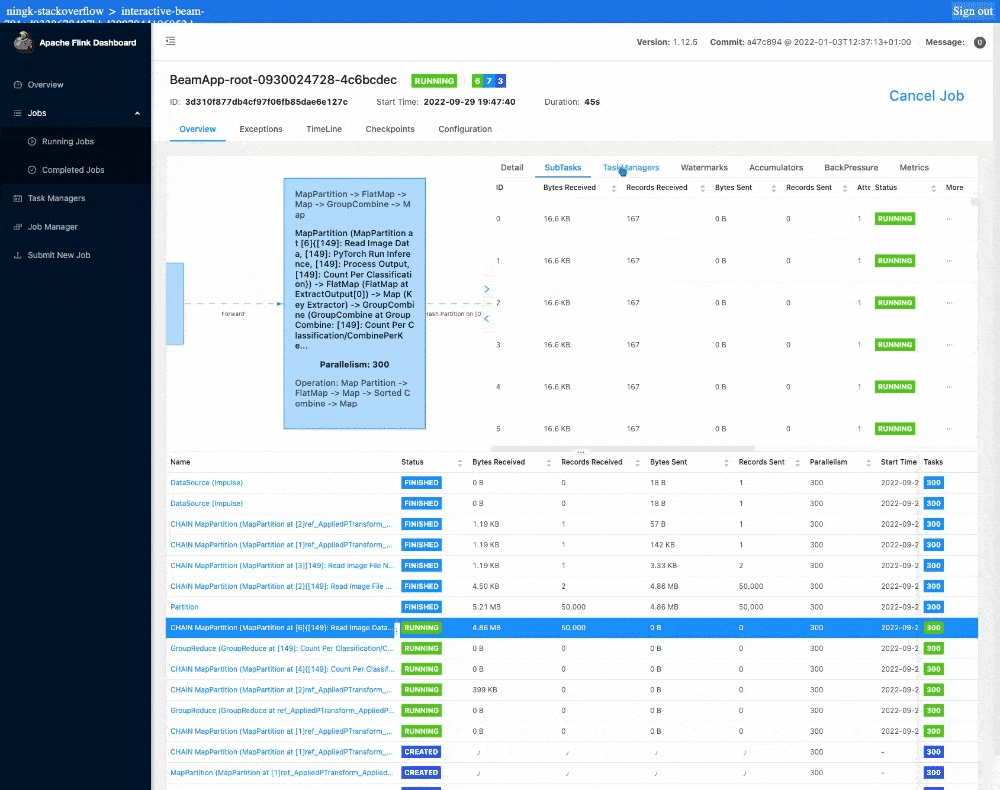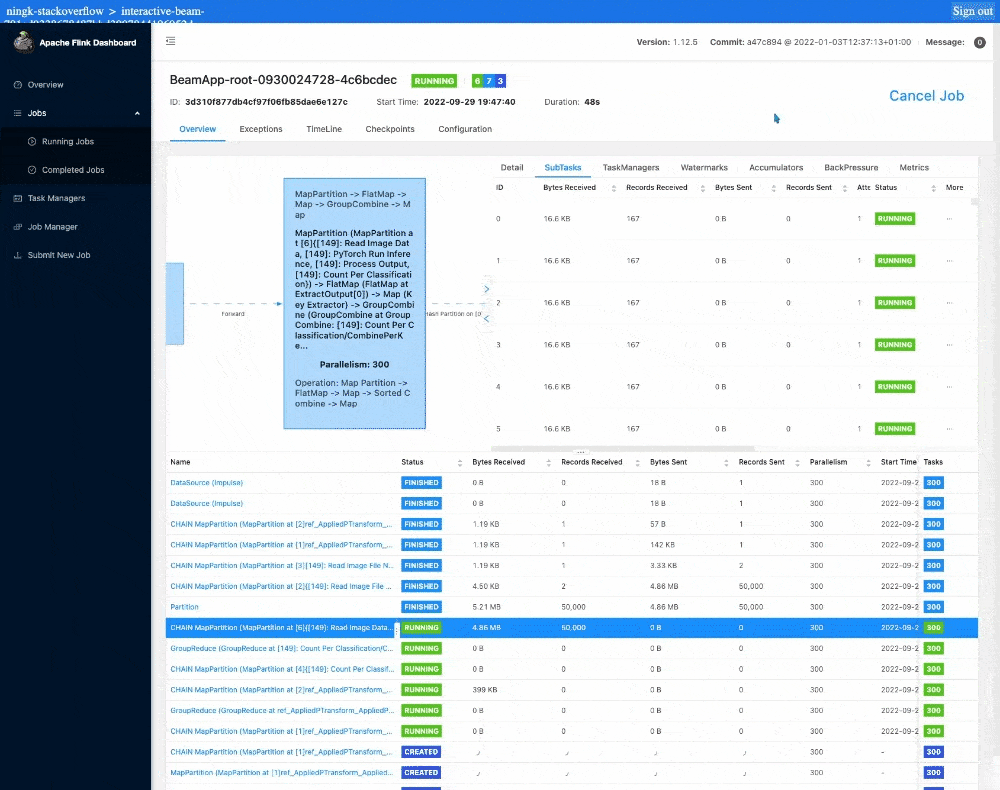
この作業には通常、1 つのノートブック インスタンスまたはワーカーにつき半日を要します。ノートブック管理クラスタ上のインタラクティブな Flink を使用すると、1 分以内に結果が表示されます。Flink のジョブ ダッシュボードを見てみると、実際の推論にはたったの 12 秒しかかかっていません。残りの実行時間はジョブのステージング、タスクのスケジューリング、集計結果の ib.options.cache_root への書き込み、ノートブックへの結果の転送、ブラウザでのレンダリングによるオーバーヘッドです。
設定
RunInference の例では、コンテナ イメージを構築する必要があります。ノートブックからコンテナ イメージを構築する方法について詳しくは、こちらのガイドをご覧ください。
この例で必要な追加の Python 依存関係は以下のとおりです。
この例では、ImageNet の検証画像セットと、PyTorch で事前トレーニング済みの ImageNetV2 モデルを使用しています。類似の依存関係をダウンロードすることも、独自の画像データセットとモデルを使用することもできます。事前トレーニング済みモデルをコンテナにコピーし、そのファイルパスを Beam パイプラインで使用するようにしてください。ImageNet や COCO(Common Objects in Context)などの画像データセットや、MobileNetV2 などの事前トレーニング済みモデルは、ImageNet モデル パッケージで多数提供されています。
構築したカスタム コンテナを使用するように、パイプラインのオプションを構成します。
パイプラインをビルドする
Beam パイプラインで推論を実行するには、以下をインポートする必要があります。
その後、パイプラインの各ステップの処理ロジックを定義します。DoFns と通常の関数を組み合わせて yield や return し、後で別の変換でパイプラインに取り込むことができます。
次に、変数をいくつか定義します。
そして、上記の構成要素でパイプラインを構築します。
パイプラインは、5 万件の画像ファイル名が記載されたテキスト ファイルを読み込みます。Reshuffle は、画像ファイルを読み込む前に、すべてのワーカーに対して画像ファイル名を調整して割り当てるために必要です。これがないと、どんなに高度な並列処理であっても、5 万ファイルすべてが 1 つのタスク / スレッド / ワーカーから読み込まれてしまいます。
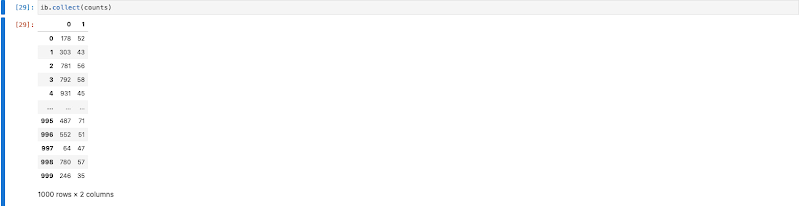
読み込まれた画像は、1,000 種類のクラス(猫、犬、花など)に分類されます。最後の集計は、各クラスの画像をカウントします。
ノートブックでは、Beam が各 PCollection のコンピューティング データをキャッシュしようと試みます。これらのデータは、メイン モジュールで定義された変数に割り当てられたり、ib.watch({‘pcoll_name’: pcoll}) でウォッチされたりしているものです。ここでは、スピードアップのため、最終的な集計を、唯一検査に値するデータである counts という PCollection 変数のみに割り当てています。
データ検査には、ib.show か ib.collect を使用します。データを初めて検査する場合は、暗黙的に Flink クラスタが起動されます。その後の検査では、コンピューティングされた PCollection は実行されません。新たに追加された変換によるデータの検査では、特に指示がない限り、同じクラスタを再利用します。
また、ib.clusters.describe(pipeline) を実行してクラスタを検査することもできます。
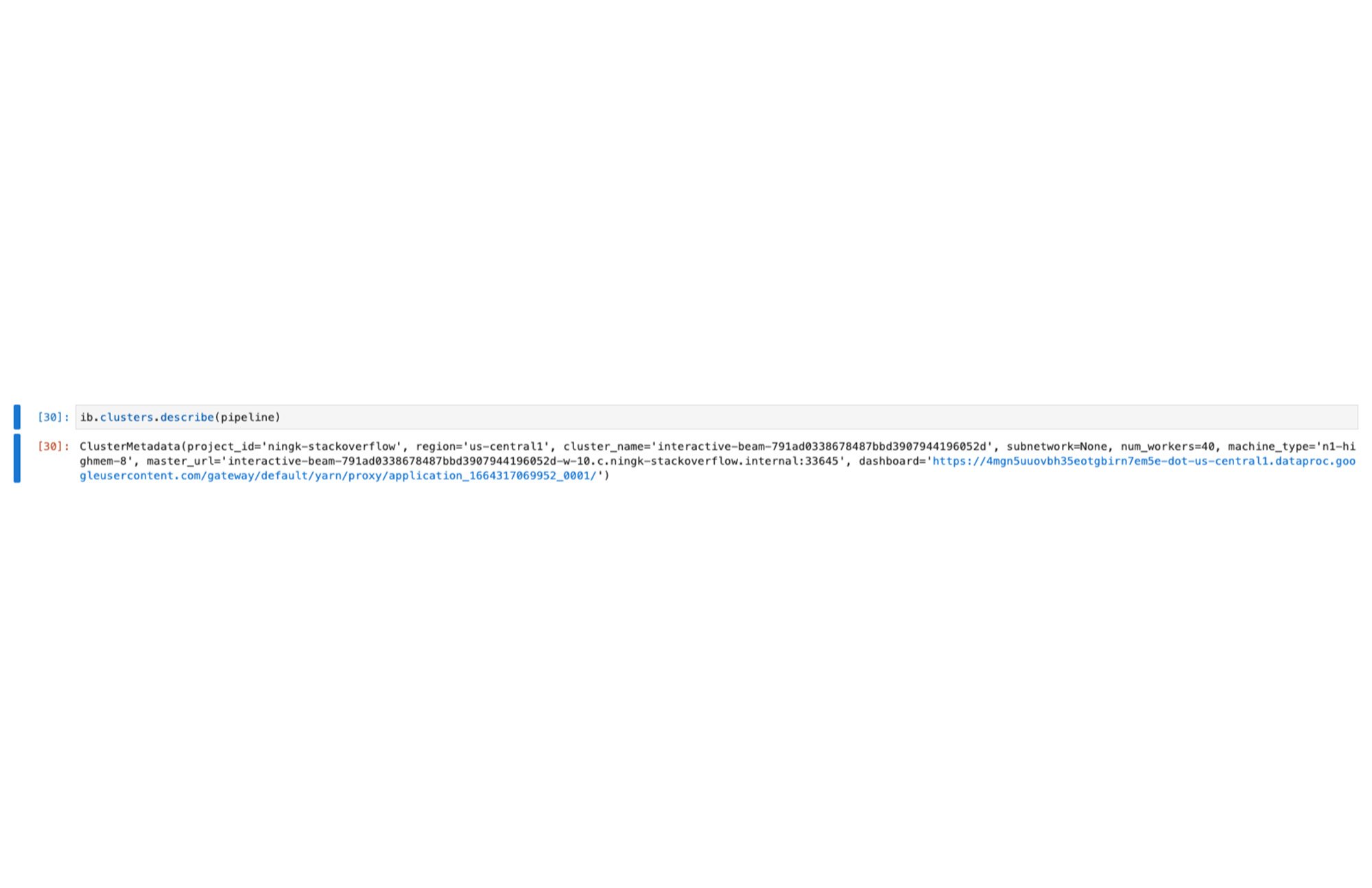
さらに、出力の中のリンクから Flink ダッシュボードに移動し、終了したジョブや今後実行するジョブを確認できます。
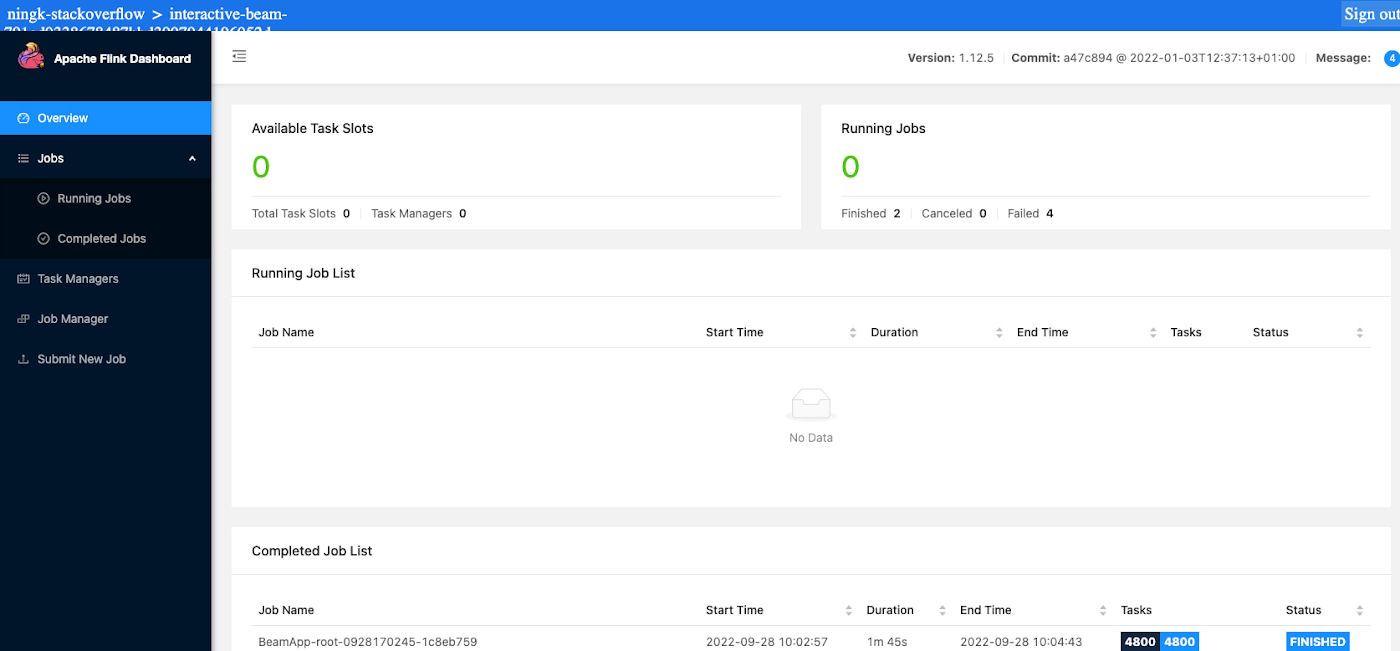
ご覧のとおり、5 万枚の画像(280 GB 以下)に対して推論を実行するのに、1 分 45 秒かかっています。
分類と人間が読める形式のラベルの間のマッピングを知ることで、さらにデータを拡充できます。
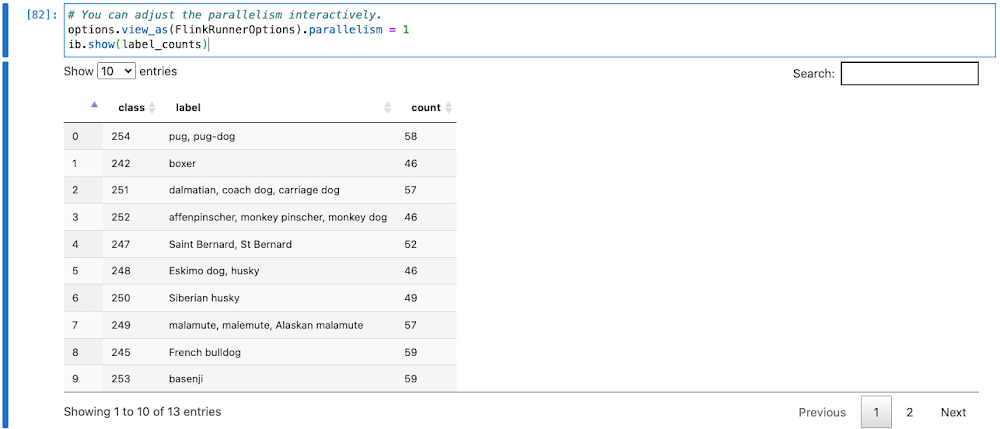
label_counts を検査する場合、コンピューティングされた counts は新しく追加された変換で再利用されます。集計後、出力データのサイズは、入力データと比較して小さくなることがあります。高度な並列処理は、小さなデータの処理の役に立たないどころか、不要なオーバーヘッドを発生させる可能性もあります。並列処理をインタラクティブに下げることで、新しく追加された変換で少数の要素のみを処理した結果を検査できます。
クリーンアップ
以下のコードを実行することで、ノートブックが作成したクラスタをクリーンアップし、意図しない課金を防ぎます。
オプションとして、Dataproc UI でクラスタを手動で管理できます。
オープンソース サポート
Apache Beam は、オープンソースのソフトウェアです。インタラクティブ機能は、すべての IPython カーネル バックアップ ノートブック ランタイムで動作します。これは、インタラクティブな FlinkRunner の機能を、独自のノートブックやクラスタの設定にも適応させられることを意味します。
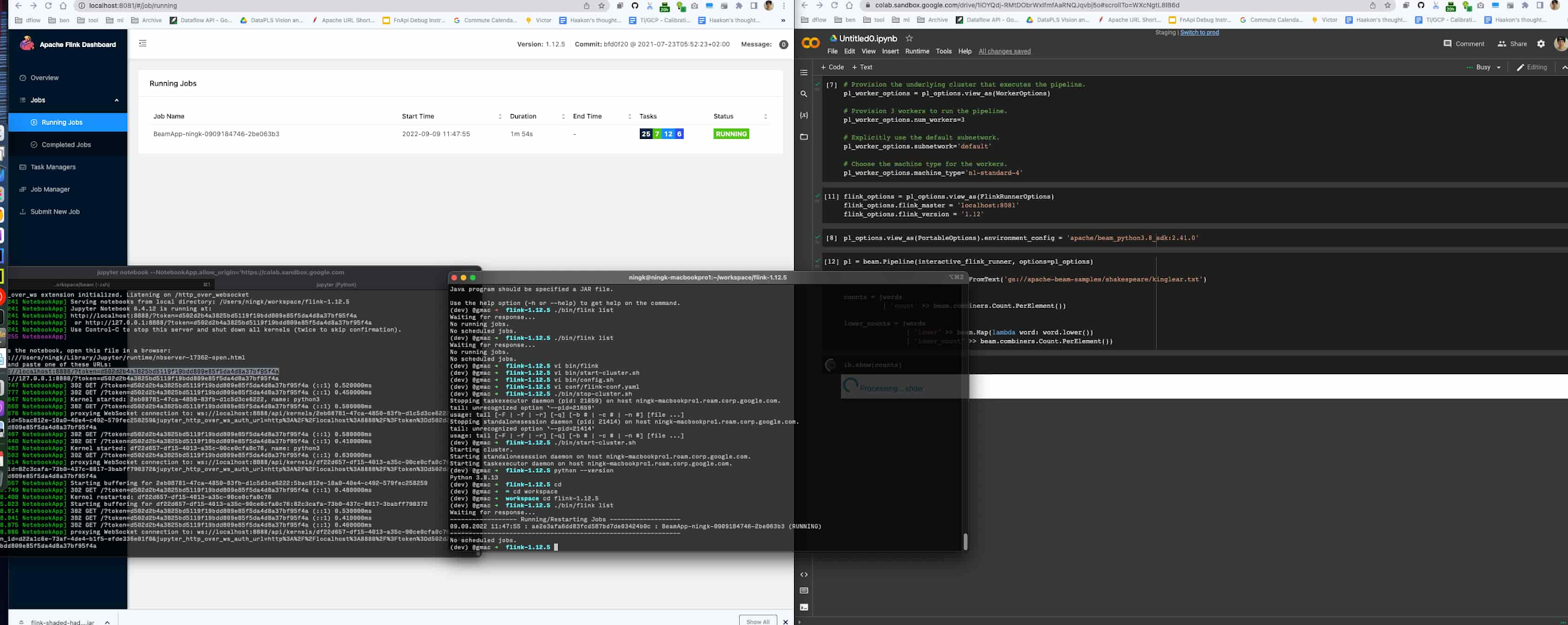
たとえば、Google Colab(Dataflow でホストされている Beam ノートブックの無料の代替サービス)を自分のワークステーションでローカル ランタイム(カーネル)と接続すれば、ホスト、管理している Flink クラスタに対し、インタラクティブにジョブを送信できます。
以下の必要なオプションを指定するだけで、Flink クラスタが利用できます。
ソースコードから構築した Beam(開発バージョン)を使う場合、互換性のあるコンテナ イメージを構成できます。
これで、Beam パイプラインのインタラクティブな実行を、独自の設定で大規模に行えるようになりました。
互換性
インタラクティブな Flink の機能は、(インタラクティブな)Beam の古いバージョンにはパッチバックされません。互換性の表を以下に示します。
Beam のバージョン | Dataflow でホストされている Beam ノートブック | その他のノートブックとクラスタの設定 |
2.40.0 未満 | サポート対象外 | サポート対象外 |
2.40.0 以上 2.43.0 未満 | サポート対象 | 並列処理を 1 に固定 |
2.43.0 以上 | サポート対象 | サポート対象 |
また、JupyterLab 拡張の apache-beam-jupyterlab-sidepanel にクラスタ マネージャーの UI ウィジェットがあります。Dataflow でホストされている Beam ノートブックにはプリインストールされています。独自で JupyterLab を設定する場合は、NPM かソースコードからインストールできます。Colab や従来の Jupyter ノートブックなど、他のノートブックのランタイムではサポートされていません。
次のステップ
Vertex AI workbench のページに移動して、Dataflow でホストされた Beam ノートブックの利用を開始しましょう。ノートブックの作成、共有、コラボレーションを簡単に行えます。ノートブックにアクセスできるユーザーや使用するリソースは、いつでも変更でき、柔軟に管理できます。
インタラクティブな Flink の機能について詳しくは、公開されているドキュメントをご覧ください。ヒント、注意点、問題が発生した場合のよくある質問が記載されています。
フィードバックやご提案、オープンソースの投稿をぜひお寄せください。
- Google、ソフトウェア エンジニア Ning Kang
