Cloud Functions とサーバーレス Spark で Google Cloud Storage ファイルを BigQuery に取り込む
Google Cloud Japan Team
※この投稿は米国時間 2022 年 3 月 31 日に、Google Cloud blog に投稿されたものの抄訳です。
Apache Spark は、データ エンジニアリング、データ探索、機械学習にかかわるユースケースにすべて対応できることから、広く支持されるプラットフォームとなりました。ですが Spark には、まだオンプレミスでのクラスタ管理と各ジョブに合わせたインフラストラクチャの調整が必要とされています。このようなサイロ化により、コストが増え、アジリティが低下し、ガバナンスの強化が困難になります。これは、企業が適切なタイミングで適切な利用者に分析情報を提供することの妨げとなります。Dataproc サーバーレスを使用すると、独自クラスタのプロビジョニングや管理をしなくても、Spark バッチ ワークロードを実行できます。ワークロード パラメータを指定してから、ワークロードを Dataproc サーバーレス サービスに送信します。このサービスは、マネージド コンピューティング インフラストラクチャでワークロードを実行し、必要に応じてリソースを自動スケーリングします。Dataproc サーバーレス料金は、ワークロードが実行されている時間に対してのみ適用されます。
Spark 用 Dataproc サーバーレス サービスでは、次の Spark ワークロード タイプを実行できます。
PySpark
Spark SQL
Spark R
Spark Java / Scala
このブログ投稿では、Cloud Functions、Pub/Sub、サーバーレス Spark などのサーバーレス サービスを使用してファイルを BigQuery に取り込むプロセスについて説明します。以下の例では、Daily Shelter Occupancy(シェルターの日次利用者数)に関するデータを使用します。
このソリューションの完全なソースコードは、GitHub 内にあります。
使用するアーキテクチャは次のとおりです。
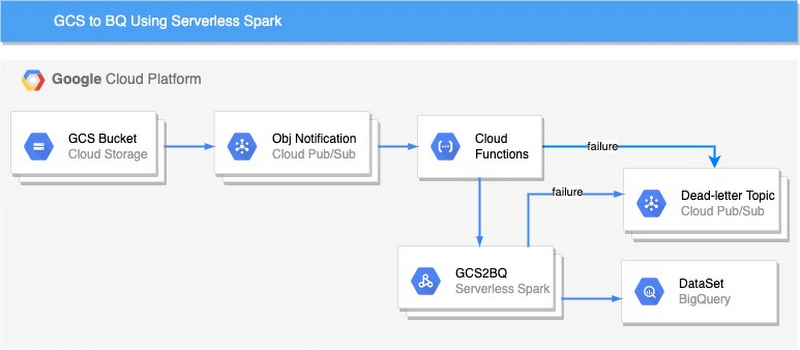
Cloud Functions とサーバーレス Spark を使用して GCS ファイルを BigQuery に取り込む方法をご紹介します。
1. バケットを作成します。バケットは GCP に取り込まれるデータを保持します。オブジェクトがバケットにアップロードされると、通知は Pub/Sub トピックに作成されます。
2. jar をビルドして GCS バケットにコピーします(GCS バケットがない場合、jar を保存する GCS バケットを作成します)。
手順に沿って GCS バケットを作成し、そのバケットに jar をコピーします。
3. サーバーレス Spark を実行するために必要なネットワーク構成を有効にします。
オープン サブネット接続: このサブネットにより、すべてのポートでサブネット通信を許可する必要があります。次の gcloud コマンドは、送信元と送信先が「serverless-spark」でタグ付けされている場合に、全ポートですべてのプロトコルを使用した上り(内向き)通信を許可するサブネットにネットワーク ファイアウォールを接続します。注: default-allow-internal ファイアウォール ルールを使用したプロジェクトのデフォルト VPC ネットワークは、上記の要件を満たしています。このルールによって、すべてのポート(tcp:0-65535、udp:0-65535、icmp protocol:ports)で上り(内向き)通信が許可されます。ただし、ネットワーク上の任意の VM インスタンスからの上り(内向き)も許可されます。
限定公開の Google アクセス: サブネットで限定公開の Google アクセスを有効にする必要があります。外部ネットワークへのアクセス: ドライバとエグゼキュータには内部 IP アドレスを割り当てます。VPC ネットワークの内部 IP を使用して送信トラフィックを許可するように Cloud NAT を設定できます。
4. サーバーレス Spark に必要な GCP リソースを作成します。
BQ データセットの作成: csv ファイルを読み込むデータセットを作成します。
- BQ テーブルの作成: schema/schema.json のスキーマを使用してテーブルを作成します。
- GCS バケットからの読み取りと BigQuery テーブルへの書き込みに必要なサービス アカウントと権限を作成します。
- BigQuery にデータを読み込む GCS バケットを作成します。
- デッドレター トピックとサブスクリプションを作成します。
注: すべてのリソースが作成されたら、trigger-serverless-spark-fxn/main.py の 27 行目から 31 行目で変数の値 () を変更します。この関数のコードについては、GitHub をご覧ください。
5. Cloud Functions の関数をデプロイします。
オブジェクトがバケットにコピーされると、Cloud Functions の関数がトリガーされます。Cloud Functions の関数は、BigQuery にデータを読み込むサーバーレス Spark をトリガーします。
6. エンドツーエンドのパイプラインを呼び出します。
エンドツーエンドのパイプラインを呼び出すには、「Daily shelter occupancy 2020(2020 年のシェルターの日次利用者数)」をダウンロードし、GCS バケット(GCS_BUCKET_NAME)にアップロードします(注: GCS_BUCKET_NAME は、手順 1 で作成したバケット名に置き換えてください)。
パイプラインをデバッグする
失敗したデータ パイプラインのエラー メッセージは、手順 4(デッドレター トピックとサブスクリプションの作成)で作成した Pub/Sub トピック(ERROR_TOPIC)に公開されます。Cloud Functions の関数と Spark で生じたエラーは、Pub/Sub に転送されます。Pub/Sub トピックには、同じデータ パイプライン インスタンスに複数のエントリが含まれることがあります。Pub/Sub トピックのメッセージは、「oid」属性を使用してフィルタできます。oid 属性はパイプラインの実行ごとに一意であり、世代 ID を備えた完全なオブジェクト名を保持します。
まとめ
この投稿では、Cloud Functions とサーバーレス Spark を使用して GCS ファイルを BigQuery に取り込む方法を紹介しました。Google Cloud 上の Spark の新しいソリューションへの早期アクセスをリクエストするには、こちらから関心事項をご登録ください。
- ビッグデータおよびアナリティクス クラウド担当コンサルタント Swati Sindwani- 戦略的クラウド エンジニア Bipin Upadhyaya



