Looker によってデータ サイエンスのワークフローを加速
Google Cloud Japan Team
※この投稿は米国時間 2021 年 2 月 26 日に、Google Cloud blog に投稿されたものの抄訳です。
Google Cloud の一部となった Looker は、最新のビジネス インテリジェンス(BI)および分析プラットフォームであり、単なる BI 報告ツールではありません。本格的なデータ アプリケーションおよび可視化プラットフォームです。Looker を使用すると、ユーザーはデータをキュレートして公開し、CSV、JSON、Excel、ファイルから SaaS や社内で構築されたカスタム アプリケーションに至るまで、さまざまな形式のさまざまなエンドポイントとの統合が可能になります。
この投稿では、データ アナリストやデータ サイエンティストが Looker を使ってデータ ガバナンス(企業システムにおけるデータの可用性、ユーザビリティ、完全性、セキュリティを管理するプロセス)を支援する方法をご説明します。データ ガバナンスは、スケーラブルで自動化された機械学習の運用をサポートするうえで必要となる最初の手順です。Looker を使ってデータ サイエンスのワークフローを自動化し、本番環境で使用する方法についてのライブデモと実例をご覧になりたい方は、こちら から 3 月 4 日に行われたウェブセミナーをオンデマンドでご覧ください。
データ サイエンティストは、データの読み込みやクリーニングなどのデータ準備作業に 45% の時間を費やしています。これは運用面でも財務面でも大きな負担となります。また、データ アナリストやデータ サイエンティストは、データ サイエンスへの投資からリターンを得られることに懐疑的な利害関係者に、ビジネス価値を迅速に示す必要に迫られることがよくあります。プロジェクトごとに独自のデータ パイプラインを構築する時間を費やす必要があることを考えると、これは困難です。
同時に、異なるチームが異なるデータソースや報告ツールを使って競合するレポートを作成しているため、データのサイロ化が継続します。ビジネスが成熟し、機械学習や AI を伴ったレポートが必要になると、状況はさらに複雑化します。このような状況ではデータ ガバナンスが極めて重要になりますが、最後まで検討されなかったり、忘れられてしまったりすることが多いものです。
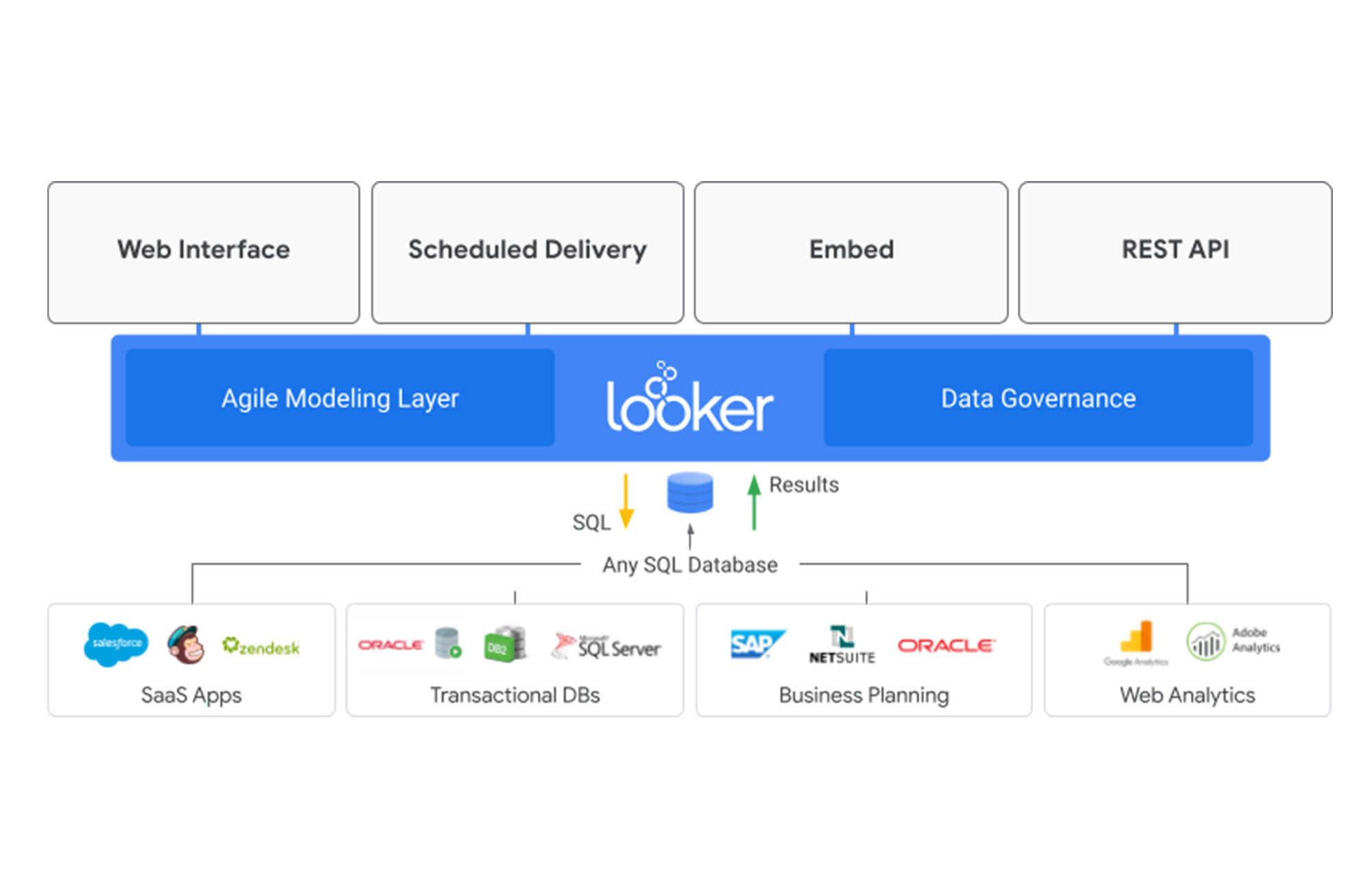
Looker のプラットフォームとパブリッシング機能により、ビジネス ユーザー、データ アナリスト、データ サイエンティストは、これを組織全体の中央データ クリアリングハウスとして使用できます。さらに、SQL クエリを抽象化した LookML という Looker のモデリング言語により、複数の SQL ベースのデータ ウェアハウス上で追加されるサービスとしてデータ ガバナンスを簡単に実装することができます。
データ ガバナンスとデータ公開をまとめて 1 か所で行うことで、データ アナリストやデータ サイエンティストがデータの取得や基本的なクリーニングに費やす時間を大幅に短縮できます。
その仕組みをイメージしやすくなる例をご紹介します。ある部屋に人が 3 人いるとします。1 人は家を建てたい、1 人は家具を作りたい、1 人は額縁を作りたいと考えています。何かを作るたびに、各自が自分の木を伐採し、別々に材木を用意して、自分で製材するのと、ホームセンターに行って必要な製材を購入し、作りたいものを作るのにすべての時間を費やすのとでは、どちらが効率的でしょうか?
最初のシナリオでは、各自が実際に作りたいものを作る前に、原材料を加工して使用可能な製材にするための作業をすべて行う必要があります。作業に必要な材料はすべて同じ供給源から得ているため、3 人が同じ上流サプライ チェーン プロセスを共有する方が効率的です。
この例で言えば、Looker はホームセンターになります。Looker は、基盤となるデータ ウェアハウスから得たデータを、各タイプのエンドユーザーが最終用途に直接消費できる形式に柔軟に再構築するセマンティック レイヤーとして機能することで、データを取得、QA、保管、そして最終的には各タイプのエンドユーザーが使用できる形式でデータを利用できるようにする処理を一元化する、データ小売スペースとしての役割を果たします。
Looker を導入することで、企業内の各部署や機能が独自のデータ パイプライン、Excel のレポート、報告ツールを構築するのではなく、誰もが同じ場所からデータを入手し、最終用途に特化したラスト ワンマイル変換の適用や配信に力を注げるようになります。
企業全体でデータが完全に管理されるため、データの基本的なクリーン性の基準が満たされているか(列タイプの変換、列名の意味の理解、NA の削除、対象データがデータセット内に存在するかの検証)を確認するために異種のソースからのデータと何日も格闘する必要があったデータ収集を、非常に簡単なクエリを実行して、検証済みのデータセットを AI ノートブックに取り込むのに数分で済むような、きれいにレイアウトされたデータ小売スペースで行えるようになるのです。
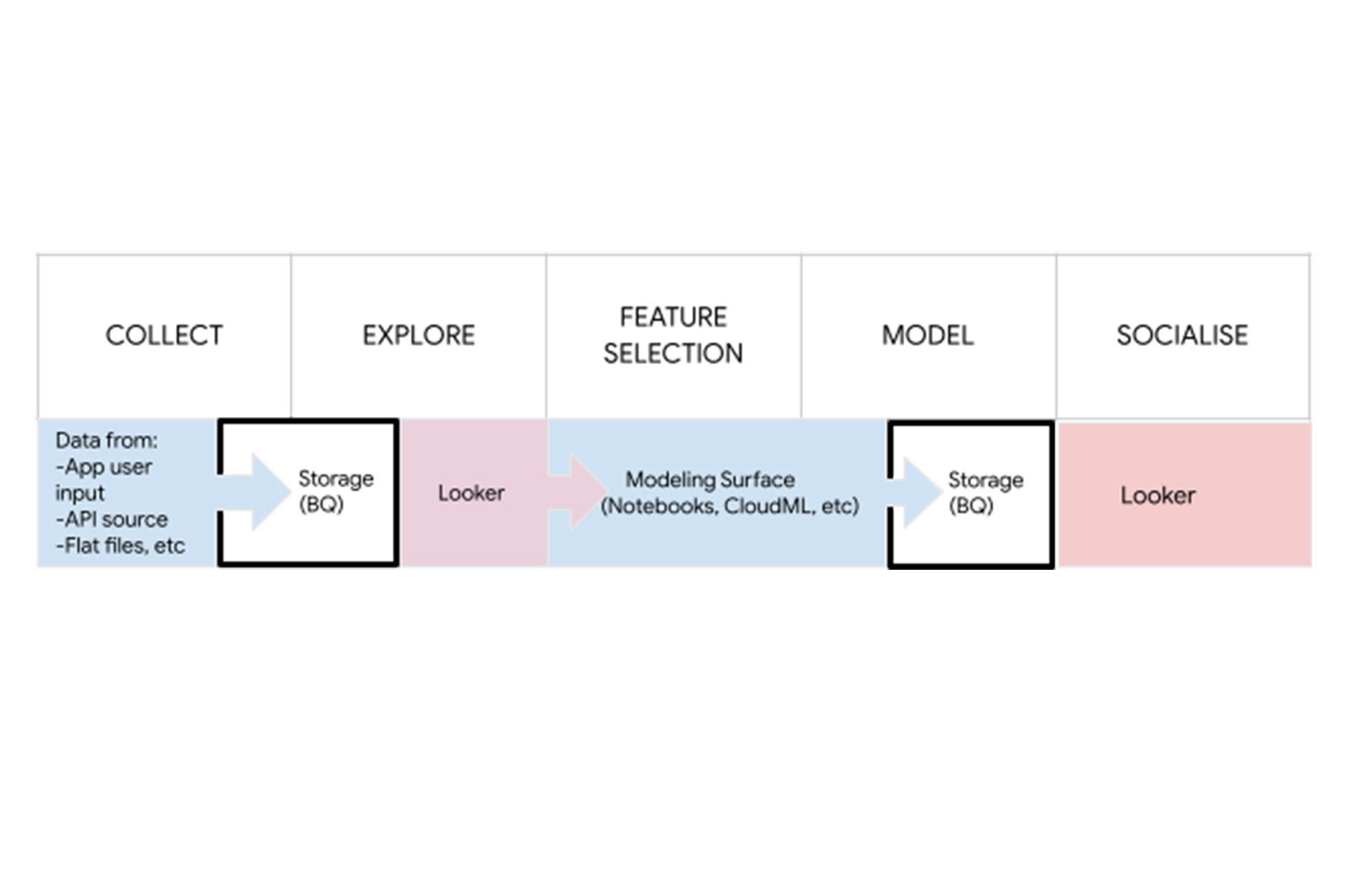
Looker は、モデルのパフォーマンスを共有できるだけでなく、モデルの結果を組織全体で簡単に調査して共有できるという点で、データ サイエンスのワークフローのバックエンドにも適しています。
-Google Cloud データ アナリスト コンサルタント Shingi Samudzi

{kind=link}
{kind=link}