MySQL から BigQuery にデータを移行する方法
Google Cloud Japan Team
※この投稿は米国時間 2020 年 4 月 11 日に、Google Cloud blog に投稿されたものの抄訳です。
市場でストリーミング分析の人気が高まりつつある現在、データ処理を最適化することで、データの品質と整合性を保ちながらコストを削減できることが重要になってきています。データ処理を最適化する方法の一つは、使用可能なデータすべてではなく、変更データの処理に的を絞ることです。その場合に役立つのが変更データ キャプチャ(CDC)です。この技術を利用すれば、こうした最適化アプローチを実現できます。
Google Cloud のストリーミング データ処理サービスを担当する Dataflow チームは、バージョン 5.6 以降のあらゆる MySQL データベース(セルフマネージド、オンプレミスなど)から変更データのストリームを取り込んで、BigQuery のデータセットに同期できるサンプル ソリューションを開発しました。このソリューションは、Dataflow テンプレートの公開リポジトリ内でご利用いただけるようになっています。テンプレートの使用方法については、GitHub リポジトリの README セクションをご覧ください。
CDC がストリーム内で変更されたデータの表現を提供するので、変更されたレコードに焦点を当ててコンピューティング処理を行えるようになります。CDC は多様なユースケースに適用できます。いくつか例を挙げると、重要なデータベースのレプリケーション、リアルタイム解析ジョブの最適化、キャッシュの無効化、トランザクショナル データストアとデータ ウェアハウス型ストア間の同期などがあります。
Dataflow の CDC ソリューションが MySQL から BigQuery にデータを移動させる仕組み
デプロイされたソリューションは、以下に示すとおり、あらゆる MySQL に対応しています。これは Debezium をベースにして開発されたコネクタによってモニタリングされます。コネクタは Data Catalog(Google Cloud のスケーラブルなメタデータ管理サービス)を使ってテーブルのメタデータを保存し、更新内容を Pub/Sub(Google Cloud のネイティブのストリーム取り込み、メッセージング テクノロジー)にプッシュします。次に Dataflow パイプラインが Pub/Sub からこうした更新内容を読み取り、MySQL データベースを BigQuery データセットと同期します。
このソリューションでは CDC 用の優れたオープンソース ツールであるDebezium を利用しています。Google ではこの技術をベースにして、ローカルまたは独自の Kubernetes 環境で実行し、変更データを Pub/Sub にプッシュできる、構成可能なコネクタを開発しました。
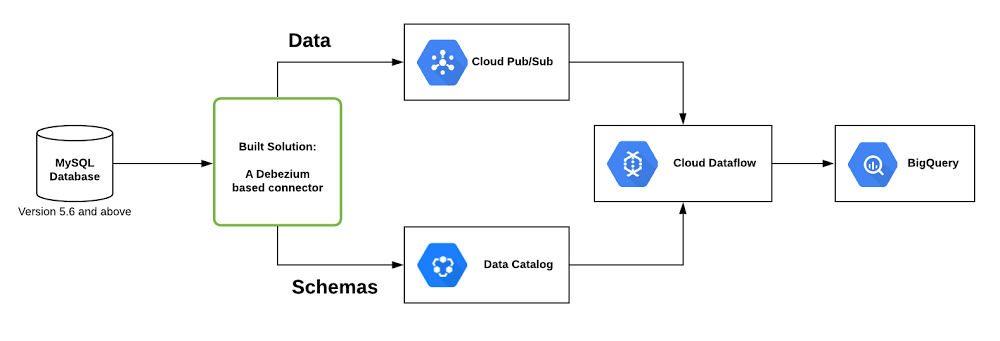
Dataflow CDC ソリューションの使用
ソリューションのデプロイには次の 4 つの手順があります。
データベースをデプロイする(すでにデータベースがある場合はこの手順は不要)
エクスポートするテーブルごとに Pub/Sub トピックを作成する
Google Cloud の Debezium ベースのコネクタをデプロイする
Dataflow パイプラインを起動し、Pub/Sub からデータを消費して BigQuery に同期する
任意の環境で実行している MySQL データベースがあるとします。この場合、エクスポートするデータベースのテーブルごとに、Pub/Sub トピックとトピックに対応するサブスクリプションを作成する必要があります。
Pub/Sub トピックとデータベースの準備が整ったら、Debezium コネクタを実行します。コネクタは、たとえばソースからローカルでビルドして実行する、Docker コンテナを使って実行する、あるいは Kubernetes クラスタで実行するなど、さまざまな環境で実行できます。Debezium コネクタの実行方法やソリューション全般については、README で詳しい手順をご確認ください。
Debezium コネクタは、実行を開始し MySQL から変更をキャプチャすると、Pub/Sub にプッシュします。また、Data Catalog を使用して、各 MySQL テーブルに対応する Pub/Sub トピックのスキーマも更新します。
すべての準備が整ったら、Dataflow パイプラインを起動し、Pub/Sub から変更データを消費して BigQuery テーブルに同期します。Dataflow ジョブはコマンドラインから起動できます。起動すると次の画面のようになります。
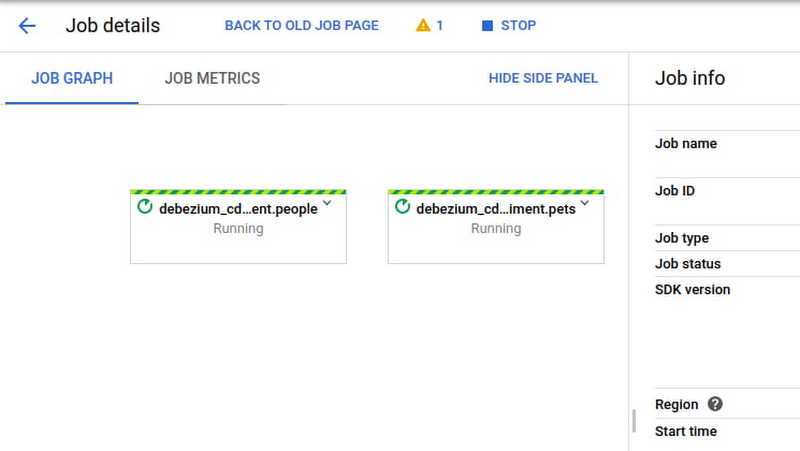
コネクタとパイプラインが実行されたら、後は進行状況をモニタリングし、すべてが問題なく進行していることを確認するだけです。
使ってみる
Dataflow の CDC 機能に適したユースケース(既存のリアルタイム解析ジョブの最適化など)がある場合は、ぜひお試しください。まず、こちらのコードを使用して、Dataflow で最初の CDC パイプラインを早速ビルドしてみましょう。また、Dataflow チームに GitHub バグトラッカーでフィードバックをお寄せください。
ストリーミング データ分析を最適化するための非常に重要な技術の一つとして Google Cloud の CDC をご活用いただければ幸いです。こうした Dataflow の新機能を活用した開発例やフィードバックをぜひお寄せください。
- By Google Cloud Dataflow ソフトウェア エンジニア Pablo Estrada、プロダクト マネージャー Griselda Cuevas

