How do I move data from MySQL to BigQuery?
Pablo Estrada
Software Engineer
Griselda Cuevas
Product Manager
In a market where streaming analytics is growing in popularity, it’s critical to optimize data processing so you can reduce costs and ensure data quality and integrity. One approach is to focus on working only with data that has changed instead of all available data. This is where change data capture (CDC) comes in handy. CDC is a technique that enables this optimized approach.
Those of us working on Dataflow, Google Cloud’s streaming data processing service, developed a sample solution that lets you ingest a stream of changed data coming from any kind of MySQL database on versions 5.6 and above (self-managed, on-prem, etc.), and sync it to a dataset in BigQuery. We made this solution available within the public repository of Dataflow templates. You can find instructions on using the template in the README section of the GitHub repo.
CDC provides a representation of data that has changed in a stream, allowing computations and processing to focus specifically on changed records. CDC can be applied for many use cases. Some examples include replication of a critical database, optimization of a real-time analytics job, cache invalidation, synchronization between a transactional data store and a data warehouse-type store, and more.
How Dataflow’s CDC solution moves data from MySQL to BigQuery
The deployed solution, shown below, works with any MySQL database, which is monitored by a connector we developed based on Debezium. The connector stores table metadata using Data Catalog (Google Cloud’s scalable metadata management service) and pushes updates to Pub/Sub (Google Cloud-native stream ingestion and messaging technology). A Dataflow pipeline then takes those updates from Pub/Sub and syncs the MySQL database with a BigQuery dataset.
This solution relies on Debezium, which is an excellent open source tool for CDC. We developed a configurable connector based on this technology that you can run locally or on your own Kubernetes environment to push change data to Pub/Sub.
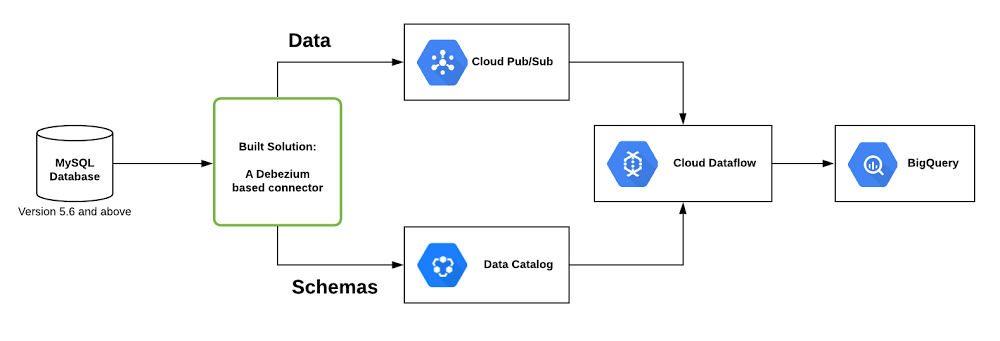
Using the Dataflow CDC solution
Deploying the solution consists of four steps:
Deploy your database (nothing to do here if you already have a database)
Create Pub/Sub topics for each of the tables you want to export
Deploy our Debezium-based connector
Start the Dataflow pipeline to consume data from Pub/Sub and synchronize to BigQuery
Let’s suppose you have a MySQL database running in any environment. For each table in the database that you want to export, you must create a Pub/Sub topic and a corresponding subscription for that topic.
Once the Pub/Sub topics and the database are in place, run the Debezium connector. The connector can run in many environments: locally built from source, via a Docker container, or on a Kubernetes cluster. For instructions on running the Debezium connector and the solution in general, check out the README for detailed instructions.
Once the Debezium connector starts running and capturing changes from MySQL, it will push them to Pub/Sub. Using Data Catalog, it will also update schemas for the Pub/Sub topic that corresponds to each MySQL table.
With all of these pieces in place, you can launch the Dataflow pipeline to consume the change data from Pub/Sub and synchronize it to BigQuery tables. The Dataflow job can be launched from the command line. Here’s what it looks like once you launch it:
Once the connector and pipeline are running, you just need to monitor their progress, and make sure that it’s all going smoothly.
Get started today
Got a use case that aligns with Dataflow’s CDC capabilities? For example, optimization of an existing real-time analytics job. If so, try it out! First, use this code to get started with building your first CDC pipeline in Dataflow today. And share your feedback with the Dataflow team in the GitHub issue tracker.
At Google Cloud, we’re excited to bring CDC as an incredibly valuable technique to optimize streaming data analytics. We look forward to seeing both development and feedback with these new capabilities for Dataflow.



