BigQuery ML で多変量時系列予測を行う方法
Google Cloud Japan Team
※この投稿は米国時間 2023 年 1 月 20 日に、Google Cloud blog に投稿されたものの抄訳です。
現在、さまざまな業界の企業が、商品の需要予測、売上の予測、オンライン サブスクリプション / 解約の予測のほか、その他多くのユースケースで時系列予測に大きく依存しています。そのため、時系列予測は BigQuery ML で特に人気のあるモデルの一つになっています。
では、多変量時系列予測とは何でしょうか?多変量時系列予測は、複数の変数を考慮し、より正確な予測を行えるようにします。たとえば、アイスクリームの売上を予測する場合、外部共変量の「天候」と目標指標の「過去の売上」を使用して予測することができます。BigQuery で多変量時系列予測を行うことで、BigQuery からデータを移動させることなく、より精度の高い予測モデルを作成できます。
時系列予測では、より正確な予測を提供するために、対象となる時系列以外の共変量または特徴量がよく使用されます。BigQuery ML はこれまで、ARIMA_PLUS モデル(ドキュメント)を使用した単変量時系列モデリングのみをサポートしていました。これは、BigQuery ML モデルの中でも特に人気のあるモデルです。
ARIMA_PLUS は広く使われていますが、ターゲット変数のみを使った予測では不十分な場合があります。また、時系列の一部のパターンには、他の特徴量に強く依存するものがあります。共変量と特徴量を用いた予測を可能にする多変量時系列予測のサポートは、ユーザーから熱望されていました。
これに応えるべく、Google Cloud は最近、外部リグレッサーを使用した多変量時系列予測の公開プレビュー版を発表しました。導入したのは新しいモデルタイプの ARIMA_PLUS_XREG で、XREG は外部リグレッサーまたは付随する特徴量を指します。SELECT ステートメントを使用して、対象となる時系列に付随する特徴量を選択できます。この新しいモデルでは、付随する特徴量を含めるために BigQuery ML の線形回帰モデルを、そして線形回帰の残差をモデル化するために BigQuery ML の ARIMA_PLUS モデルを活用します。
ARIMA_PLUS_XREG モデルは、以下の機能をサポートしています。
数値、カテゴリ、配列の特徴量に対する自動特徴量エンジニアリング
季節的な傾向や休日の検出など、ARIMA_PLUS モデルのすべてのモデル機能
AI を活用した広告代理店の Headlight では、多変量予測モデルを使用し、コホートの年齢に基づいてサブスクリプション、解約など、ボトムファネルの指標のコンバージョン数を判断しています。Headlight の動画とデモは、こちらをご覧ください。
次のセクションでは、BigQuery ML で新しい ARIMA_PLUS_XREG モデルを使用する例をご紹介します。この例では、毎日の大気質と気象情報を含む bigquery-public-data.epa_historical_air_quality データセットを探索します。このモデルを使用して、PM2.5 を、その過去のデータと気温や風速などのいくつかの共変量に基づいて予測します。
例: 気象情報を用いたシアトルの大気質の予測
ステップ 1. データセットの作成
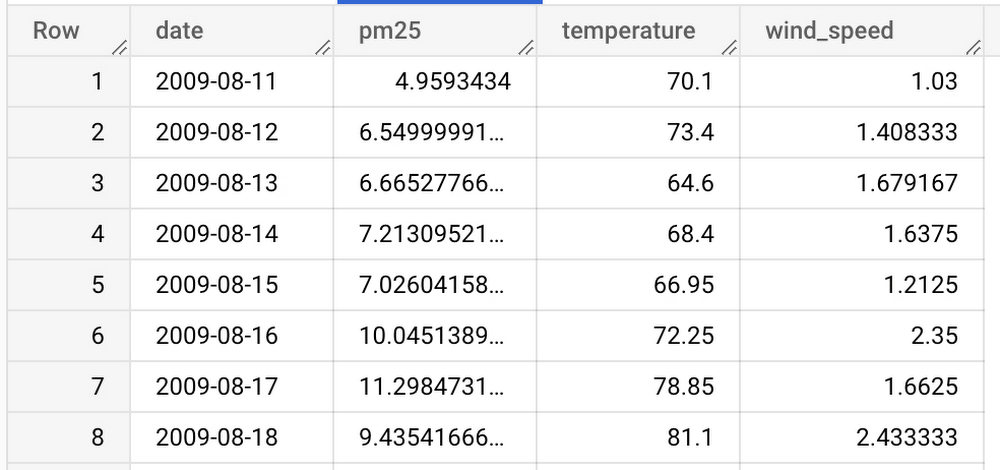
PM2.5、気温、風速のデータは、別々のテーブルにあります。クエリを簡素化するために、これらのテーブルを結合して、次の列がある新しいテーブル「bqml_test.seattle_air_quality_daily」を作成します。
date: 観測日
PM2.5: 各日の PM2.5 の平均値
wind_speed: 各日の平均風速
temperature: 各日の最高気温
新しいテーブルには、2009 年 8 月 11 日から 2022 年 1 月 31 日までの日次データが含まれます。
データのプレビューは次のとおりです。
ステップ 2. モデルの作成
新しい多変量モデル ARIMA_PLUS_XREG の「CREATE MODEL」クエリは、現在の ARIMA_PLUS モデルと非常によく似ています。主な違いは、MODEL_TYPE と、SELECT ステートメントに特徴量列が含まれる点です。
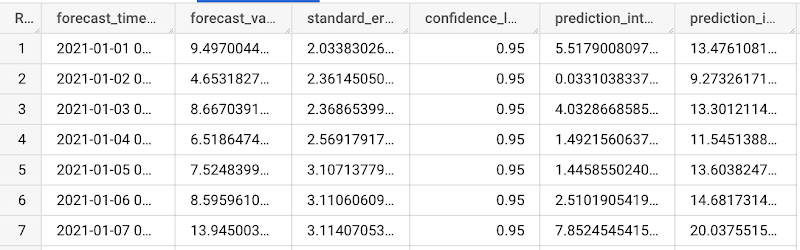
ステップ 3. 将来のデータの予測
作成したモデルで、ML.FORECAST 関数を使って将来のデータを予測できます。ARIMA_PLUS モデルとの違いは、将来の共変数を入力として指定する必要があることです。
上記のクエリを実行した後、予測結果を確認できます。
ステップ 4. モデルの評価
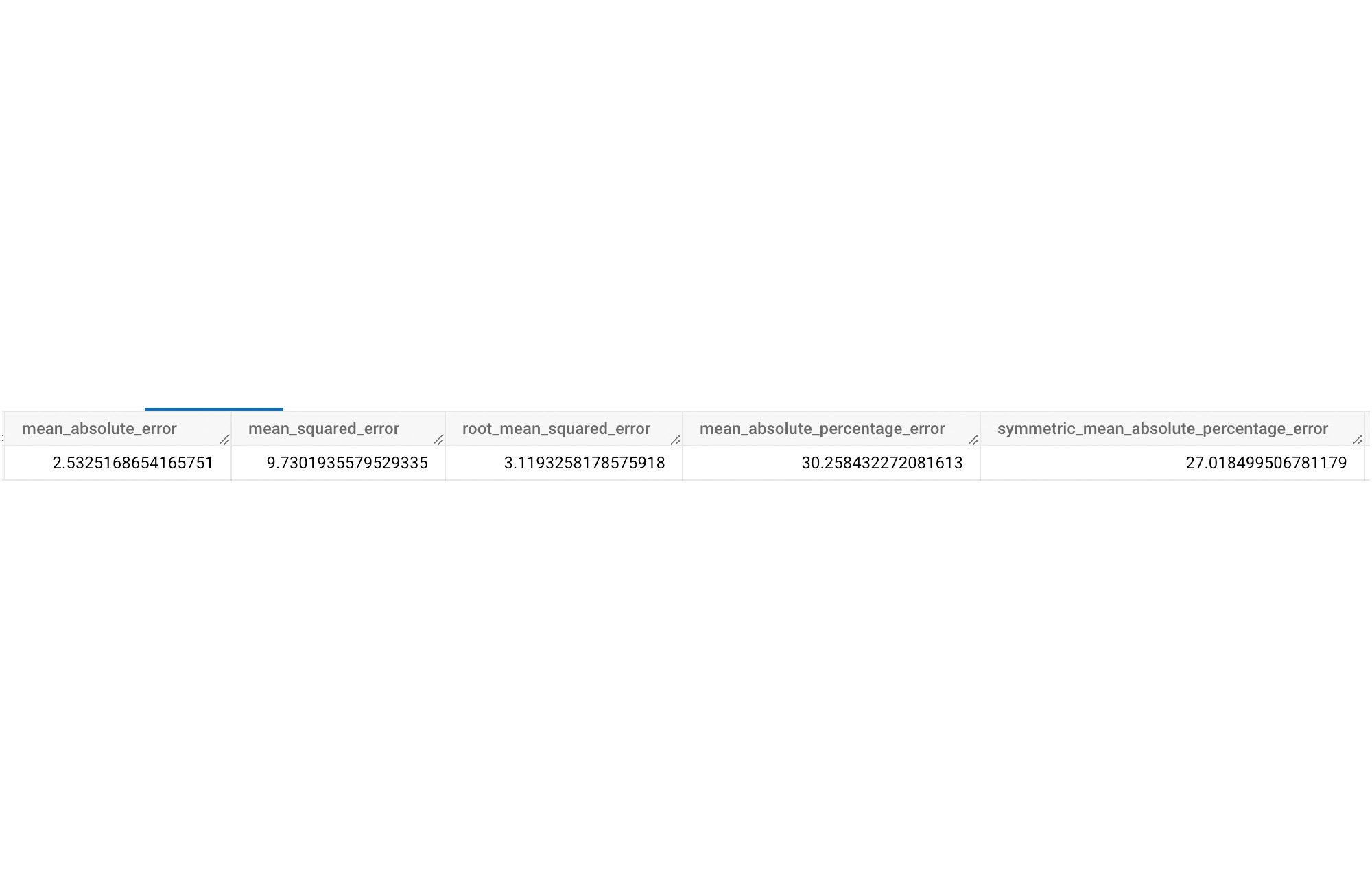
ML.EVALUATE 関数を使用して、誤予測を評価できます。perform_aggregation に「TRUE」を設定すると集約された誤差指標を取得でき、「FALSE」を設定するとタイムスタンプごとの誤差を確認できます。
ARIMA_PLUS_XREG の評価結果は以下のとおりです。
比較として、以下の表に単変量予測 ARIMA_PLUS の結果も示します。
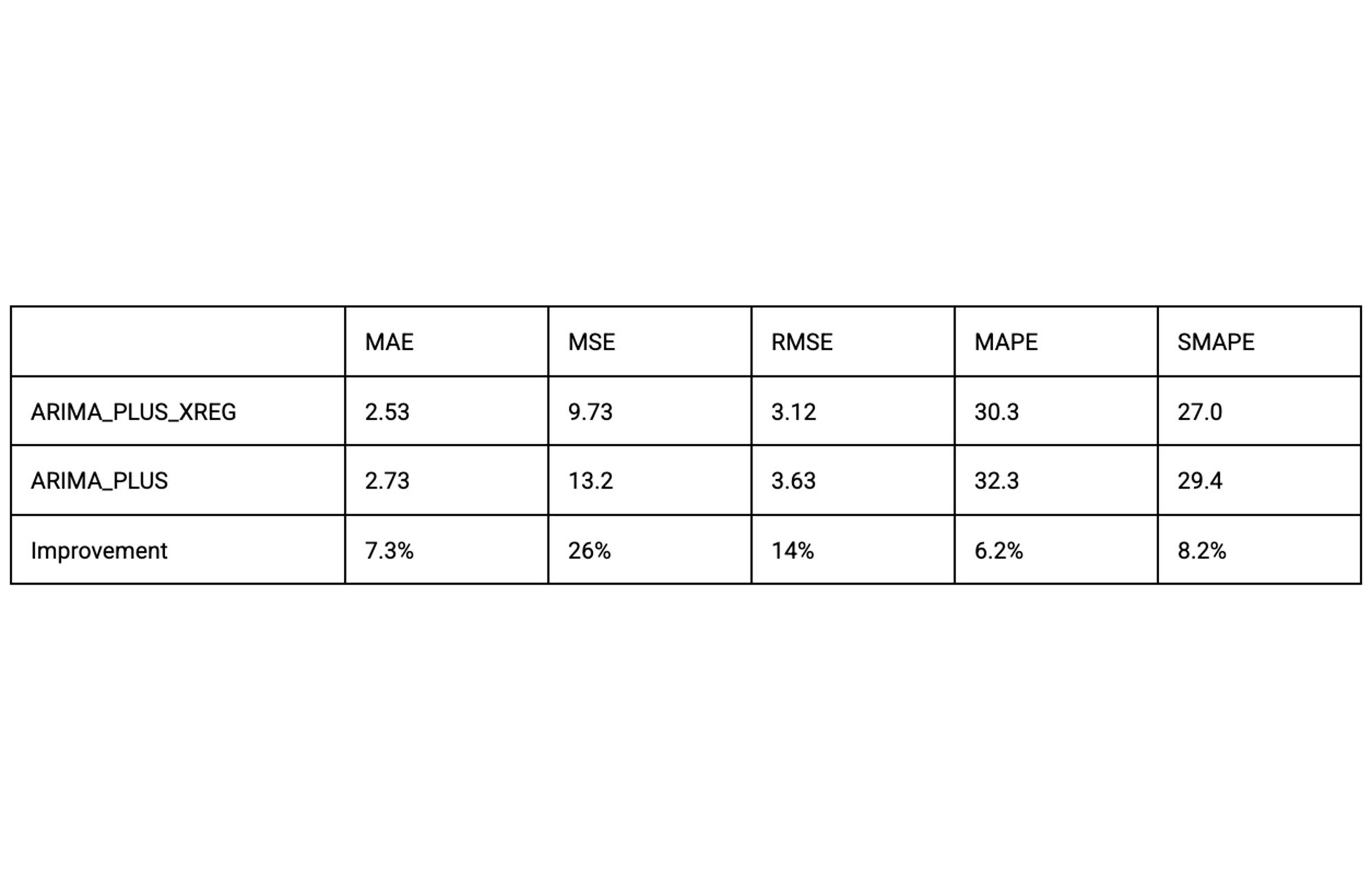
ARIMA_PLUS_XREG は、ARIMA_PLUS と比較して、この特定のデータセットと期間におけるすべての測定指標でパフォーマンスが優れていることがわかります。
まとめ
上記の例では、多変量時系列予測モデルを作成し、そのモデルを使用して将来の値を予測し、予測結果を評価する方法を説明しました。ML.ARIMA_EVALUATE と ML.ARIMA_COEFFICIENTS のテーブル値関数もモデルを調査するのに役立ちます。なお、このモデルでは、ユーザーのフィードバックに基づいて、その生産性を向上させるために以下を実現しています。
データの前処理に費やす時間を短縮し、ユーザーが機械学習を行う際にデータを BigQuery に保持する。
SQL の知識があるユーザーが BigQuery で機械学習の作業を行う際のオーバーヘッドを軽減する。
ARIMA_PLUS_XREG モデルについて詳しくは、こちらのドキュメントをご覧ください。
次のステップ
今回のブログ記事では、現在公開プレビュー版が提供されている、BigQuery ML の多変量時系列予測モデルについて説明しました。また、データ サイエンティスト、データ エンジニア、データ アナリストが多変量時系列予測モデルを実現するための、コードのデモを紹介しました。
以下の機能も近日提供予定です。
大規模な多変量時系列への対応(1 つの CREATE MODEL ステートメントで行う、数百万個の多変量時系列に対する数百万個のモデルのトレーニング)
多変量時系列の異常検出
BigQuery ML チームの Xi Cheng、Honglin Zheng、Jiashang Liu、Amir Hormati、Mingge Deng、Abhinav Khushraj、そして Google Resource Efficiency Data Science チームの Weijie Shen に感謝いたします。
1. 微粒子物質による大気汚染の計測
- BigQuery ML、ソフトウェア エンジニア Haoming Chen
- BigQuery ML、プロダクト マネージャー Yan Sun
