Google Cloud を使用するエンタープライズ データ プラットフォームによって新たな収益ストリームを生み出す
Google Cloud Japan Team
※この投稿は米国時間 2023 年 10 月 10 日に、Google Cloud blog に投稿されたものの抄訳です。
ある米国の食料品店チェーンが、ビジネスのさまざまな分野のデータを活用して運営を拡張し、追加の収益を生み出そうとしていました。この会社は、異種のレガシー システム、データ品質の問題、クラウドに関する専門知識の欠如など、いくつかの課題に直面していました。
これらの課題に対処するため、同社は Pythian や Google Cloud と共同で、セキュアかつスケーラブルで柔軟なエンタープライズ データ プラットフォーム(EDP)を Google Cloud 上に設計しました。この EDP により、次のことが可能になりました。
- 需要を リアルタイムでモデル化することによる運用効率の向上。
- プロダクトをより的確におすすめすることによる、オンラインでの売り上げの増加。
- 匿名化データの販売による追加収益の創出(利益率が 30% を超えると予想され、年間収益が 2 倍になりました)。
この EDP は、同社に固有のセキュリティ、プライバシー、スケーラビリティの要件を満たすように設計され、データの分類、ロールベース アクセス制御、包括的なメタデータ トラッキングが組み込まれています。
お客様の目標を達成するため、Pythian は Google Cloud と共同で、現代のアナリティクスのニーズを満たすエンタープライズ データ プラットフォームを設計しました。この EDP はセルフサービスかつクリーンで、多くのタイプのデータを組み込むことができ、さらには、強固なセキュリティ制御とデータ ガバナンスを保証しながらスケーリングも可能です。
エンタープライズ向けのデータ プラットフォームの設計
セキュアなエンタープライズ規模のデータ プラットフォームの設計には、いくつかの主要な能力が必要です。
初めから確保されているセキュリティ
このデータ プラットフォームは、最初の取り込みからエンドユーザーへの配信まで、常にセキュアである必要があります。これには、プラットフォームを監査して潜在的な侵害を検出するためのセキュアなプロセスの設置も含まれます。
自動化によるプログラマティックな構成管理
プログラマティックな構成管理は、ソフトウェア システムの構成メタデータを追跡およびモニタリングするもので、多くの場合、バージョン管理や CI / CD パイプラインと併用されます。構成データの更新を自動的に管理およびモニタリングして、堅牢で安定したシステムを構築するために使用されます。
可能な限りマネージド サービスを使用
Google Cloud のマネージド サービスはビジネス向けの優れた選択肢です。これと同等なソリューションを作成するのは困難で、ほとんどの IT チームにとって手の届かないリソースが必要です。
スケーラビリティを考慮した設計
クラウドベースのデータ プラットフォームには、需要に応じてリアルタイムで別々にスケールできる、モジュール式のアーキテクチャが必要です。それによって、プラットフォームの成熟に応じたスケーラビリティを保証しつつ、運用費を最小限に抑えて試験運用を可能にします。
複数のフォーマットと互換性があるデータ取り込みレイヤ
高度にセキュアなデータ取り込みレイヤにより、各種のデータソースからの多様なファイル形式を処理します(例: Oracle、Oracle 以外、SQL、No-SQL)。このレイヤは、モニタリングされるランディング ゾーンとして動作し、元データを適切な Google Cloud またはサードパーティ製のツールによって処理できるようにします。
データが到着して最初の処理が行われると、Avro / Parquet 形式に標準化され、以後の処理ロジックが簡単になります。データ取り込みレイヤは、エンタープライズ データ ウェアハウスの現代化に不可欠な、データベース ログをベースとする CDC またはバッチ処理をサポートしています。
異種のエンジンによるデータ処理
さまざまなデータのユースケースは、それぞれに固有の処理要件が存在することが多く、単一のビッグデータ処理エンジンとはかみ合わないこともあります。Google Cloud は、Dataproc、Dataflow、Dataform、その他各種のビッグデータ処理ツールを提供しています。
特定のジョブ要件を満たすため、データ プラットフォームは最も適切な環境でプロセスを実行できるよう、十分な柔軟性が必要です。たとえば、ML 用に Avro 形式へのデータ変換を行うタスクは、堅牢な Pandas Dataframes ライブラリを持つ Spark を活用できます。一方で、ストリーミング プロセスでは開発が簡単な Dataflow を活用でき、BigQuery に保存されているデータは集計や KPI 計算などのネイティブ SQL パイプラインに Dataform を使用することにより恩恵を受けられます。最後に、大量のデータセットのため高速なクエリが必要なら、Apache Iceberg テーブルに外部の BigLake テーブルとして BigQuery から直接アクセスして活用できます。
オープンで柔軟なデータ プラットフォームを採用することで、お客様はワークロードに基づいて処理エンジン、ソースのデータ形式、ターゲット システムを自由に選択できます。これにより、現在そして将来も、Google Cloud の広範な能力を最大限に活用できます。
データの分類
データの分類では、ユースケース、情報の種類、データの機密度、必要なアクセスレベルに基づいてデータをグループ化します。データが分類されると、各データ セグメントについて、別々のセキュリティ パラメータと認証ルールが規定されます。
データリネージ
データリネージは、データのフローをソースから宛先まで追跡し、データ クリーニング、集計、計算などの変換をキャプチャします。堅牢なデータリネージのプロセスには、ビジネス グロッサリ(例: Looker の LookML モデル)による列の定義、データオーナーの関与による正確なデータ表現、リネージの自動収集プロセスによるパイプライン ギャップの回避が含まれます。
エンタープライズの環境下ではデータリネージの実装が困難なことがあり、包括的なカバーが常に可能とは限りません。その代わりに、主要なリネージのフローに集中し、最初から完全な実装を目指さずに、プラットフォーム全体にわたって次第に増強していきます。データリネージについてさらに詳しい指針を得るには、このガイドを参照するか、Pythian など技術のあるデータリネージ パートナーにお問い合わせください。
ロールベース アクセス制御
ロールベース アクセス制御(RBAC)は、アクセス許可を正確かつ詳細に構成し、環境内でのユーザーやグループによるオブジェクトの操作を規定するための仕組みです。EDP では、RBAC を使用してデータレイクなどの一元化された場所にデータを保管しながら、ユーザーの要件に合わせた細かいアクセス制御を維持できます。
コンピューティングとストレージの分離
コンピューティングとストレージの分離は、スケーラブルで費用対効果の高いデータ プラットフォームを構築するために不可欠です。ほとんどのクラウド料金モデルでは、ストレージの方がコンピューティングよりも低費用です。エンタープライズ データの量は飛躍的に増大していくため、HDFS のようにコンピューティングと分離できないストレージにデータを長期的に保管することは非現実的になります。
ストレージをコンピューティングから分離すると、オブジェクト ストレージを活用できるようになります。これは低費用で事実上無制限の、スケーラブルかつ本質的に高可用性を備えたストレージです。
組み込みの AI / ML 機能
AI / ML はタスクの自動化、データ品質の向上、データからの分析情報の生成に使用できます。
BigQuery ML では、GoogleSQL クエリを使用して、ML モデルの作成と実行を行えます。BigQuery は Vertex AI とも統合され、オンライン モデルのサービングや MLOps 機能を使用できます。Duet AI は Google Cloud に搭載された AI によるコラボレータで、SQL クエリの生成や完了のほか、説明にも役立ち、BigQuery を補完します。
完全なメタデータのトラッキング
メタデータのトラッキングにより、データ プラットフォーム内でデータに関するデータをトラッキングできます。メタデータはデータ プラットフォームの長期サポートに不可欠です。多くの場合、特定のパイプラインが現在実行中か、または以前に動作したかを知るための唯一の方法です。メタデータは、DataOps チームが問題点をトラッキングおよびアラートし、迅速かつ多くの場合は自動的に応答するために多用されます。
Pythian の Google Cloud 用 EDP は、BigQuery をベースとする統合されたクラウドネイティブな最新のアナリティクス プラットフォームを、ニーズに合わせてカスタマイズするため必要なプロフェッショナル サービスと組み合わせたものです。紹介されているユースケースにあるように、Pythian はデータソースを使用し、Looker や Tableau などの最新のビジネス インテリジェンス(BI)ツールによって、データを分析情報に変換できます。
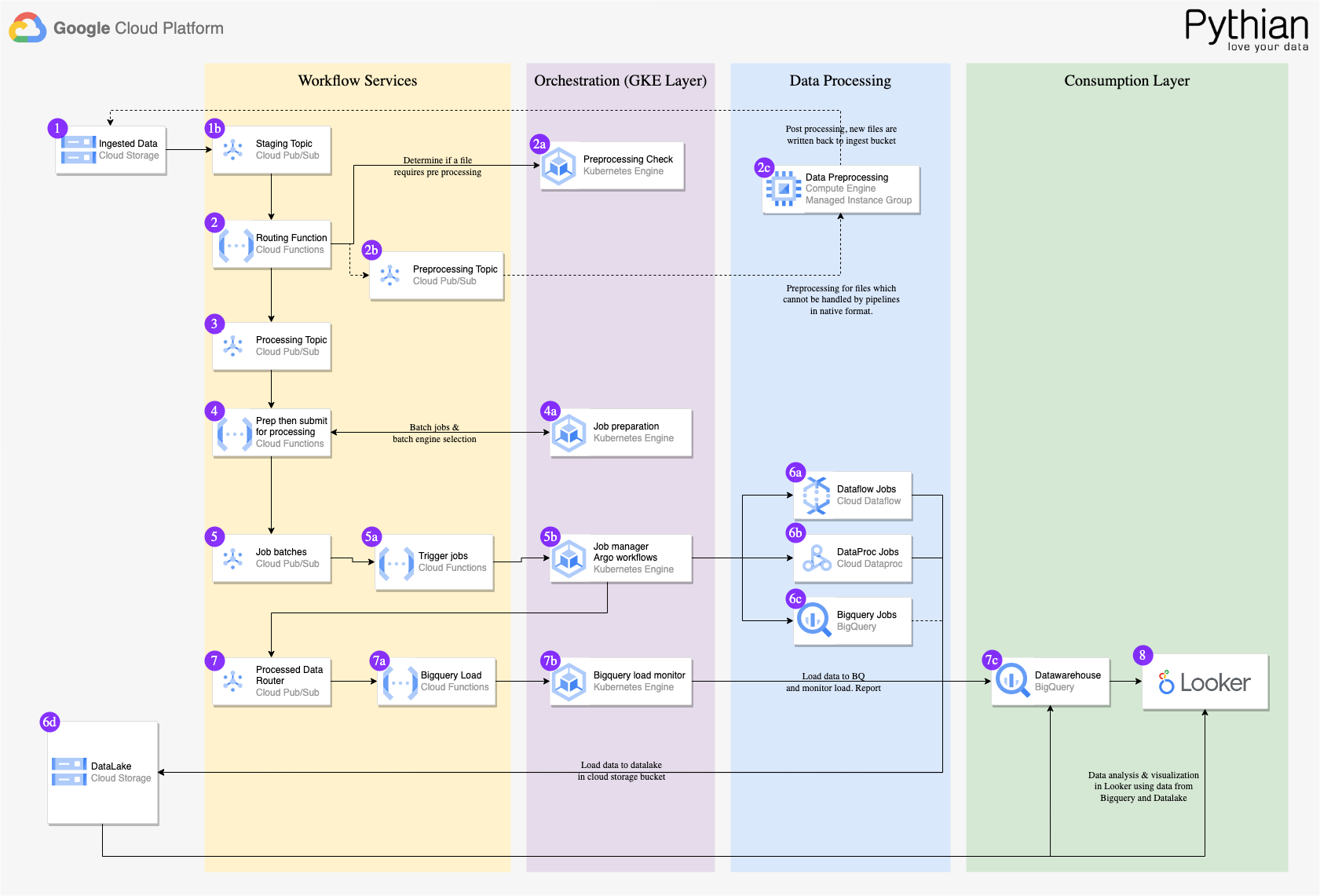
Pythian EDP のコンポーネント
- Cloud Storage - あらゆる規模の企業に対応するオブジェクト ストレージ。
- Pub/Sub - メッセージ キューとして、およびデータ プラットフォーム全体で処理の制御のために使用され、コンピューティング プロセッサが使用できないときに復元性を提供します。
- Cloud Functions - Cloud Functions は EDP の内部で、キュー内の次のタスクを見つけるなど、すべてのオーケストレーション ロジックの管理に使用されます。
- Composer - タスクの依存関係とプロセスの再試行を管理します。Composer により、Pythian はあらゆる Airflow 環境で動作可能なパイプライン ジョブを設計できます。
- Data loss prevention API - 必要に応じて機密データを難読化できます。
- Dataproc Serverless - 元のソースデータを最初に取り込んでクリーンアップし、変換するために使用されます。広範なファイルやプロセスと統合可能であるため、Spark が選ばれました。
- Dataflow - データが取り込まれた後で行われる、すべての BigQuery 以外のプロセスで使用されるメイン処理エンジンです。コーディング不要でデプロイでき、要件の変更に応じて更新できます。
- Dataform / dbt - BigQuery 内でデータを直接操作するための SQL ネイティブのパイプラインを生成するために使用されます。
- BigQuery - Pythian は、BigQuery と GCS を使用して、お客様用のレイクハウスおよびデータメッシュ アーキテクチャを実装します。
- BigQuery Studio - データの取り込み、準備、分析、探索、可視化を行うための包括的な機能のセットを提供しており、データ関連のタスクをすべて単一の環境で実行できます。
- Looker - ユーザーはデータを分析、可視化し、データから得た分析情報に基づいて行動できます。Pythian の EDP ソリューションの一部として、ビルド済みの Looker ダッシュボードを追加設定なしでデプロイでき、ユースケースに固有のカスタム ダッシュボードを実装することも可能です。
結果
EDP は直ちに価値をもたらすことができ、お客様は主要なユースケースを 8 週間以内に実装して、アーキテクチャの準備状況を検証できました。
EDP のメタデータ処理パターンにより、パイプラインを迅速に開発してデプロイ可能なため、ビジネス アナリストがオーナーシップを持つことで IT サポートへの依存を減らすことができました。
パフォーマンス テストで EDP の効率性が示され、20 億を超える行を持つ 250 GB のデータをわずか 30 分で処理できるため、将来の実装への信頼が増しました。
手の届くデータ プラットフォーム
セキュアかつスケーラブルで、費用対効果の高いデータ プラットフォームの基礎を確立し、エンタープライズのニーズを満たすことが、手の届く範囲で実現できるようになりました。そして、実現までの期間をこのようなイニシアチブがこれまで要してきた数か月、数年ではなく、数週間に短縮できます。
Pythian の EDP Quickstart アセットは、業界に認知されているベスト プラクティスを中心に十分なテストのもとで設計されています。これを利用することにより、プラットフォームを短期間でセットアップして、データの豊富な価値を引き出し、エンタープライズ全体にスケールして、データを利用して分析情報、予測、成果を獲得できます。
Google Cloud を、Pythian のような高度な技能を持つサービス パートナーと組み合わせることで、組織とデータとの間にある障壁を取り除き、具体的で測定可能な価値を実現できます。Google は、データクラウドの構築を求めているあらゆる規模の企業のためにデータとソフトウェアを結合し、現在は想像もできないような水準まで企業を押し上げます。
Pythian について、および Pythian の Google Cloud 用の Pythian エンタープライズ データ プラットフォーム クイックスタートを使用してデータ プラットフォームを使い始める方法について詳しくは、このサービスの概要を参照し、Pythian にお問い合わせください。
- Pythian、ソリューション アーキテクト Scott McCormick 氏
- Google Cloud、パートナー エンジニア Sebastian Senen-Gonzalez


