Google Cloud Next におけるデータ分析に関するまとめ
Google Cloud Japan Team
※この投稿は米国時間 2021 年 10 月 26 日に、Google Cloud blog に投稿されたものの抄訳です。
Google Next 2021 の熱気冷めやらぬ 10 月 23 日(先週の土曜日)は、私が Google に入社して 4 周年を迎えた日でした。
2017 年に私が入社したとき、私たちには BigQuery をあらゆる組織のデータドリブンなデジタル トランスフォーメーションを推進するインテリジェントなデータ ウェアハウスにするという夢がありました。
今年の Next で注目された点として、Google Cloud CEO の Thomas Kurian の基調講演に WalMart の CTO である Suresh Kumar 氏が登場し、同社がどのようにしてデータに「BigQuery 治療」を施したかについて語りました。

今 Next 2021 を総括しながら過去 4 年間の私たちの実り多い道のりに思いを巡らすと、Twitter、Walmart、Home Depot、Snap、PayPal などの世界に名だたる革新的な企業と仕事をする機会を得たことを誇りに思います。
Next で発表されたことの多くは、お客様に最高の分析エクスペリエンスを提供するために私たちが長年にわたって根気強く努力を続けてきた結果です。
お客様はなぜデータのために Google を選ぶのでしょうか?その理由の一つは、Google の戦略とお客様の戦略がしっかりと一致しており、Google がお客様の要求するスピードで絶え間なくイノベーションを提供しているためだと考えます。
一元化されたスマート アナリティクス プラットフォーム
この 4 年間、私たちは業界をリードする一元化されたスマート アナリティクス プラットフォームを構築することに注力してきました。BigQuery はこのビジョンの中心にあり、Google の他のすべてのサービスとシームレスに統合されています。お客様は BigQuery を使用して、BigQuery Storage、Google Cloud Storage、AWS S3、Azure Blobstore や、BigTable、Spanner、Cloud SQL などの各種データベースに保存されたデータをクエリすることができます。また、Spark、Dataflow、Vertex AI などのエンジンを BigQuery と組み合わせて使用することも可能です。BigQuery はすべてのメタデータを Data Catalog と自動的に同期します。これにより、ユーザーはデータ損失防止(DLP)サービスを実行して機密データを識別し、タグを付けることができます。さらに、これらのタグを使用してアクセス ポリシーを作成することもできます。
Google サービスに加えて、Google パートナー プロダクトもすべて BigQuery とシームレスに統合されています。Next 21 では、データの取り込み(Fivetran、Informatica、Confluent)、データの準備(Trifacta、DBT)、データ ガバナンス(Colibra)、データ サイエンス(Databricks、Dataiku)、BI(Tableau、PowerBI、Qlik など)を扱っている主要パートナーが注目を集めました。
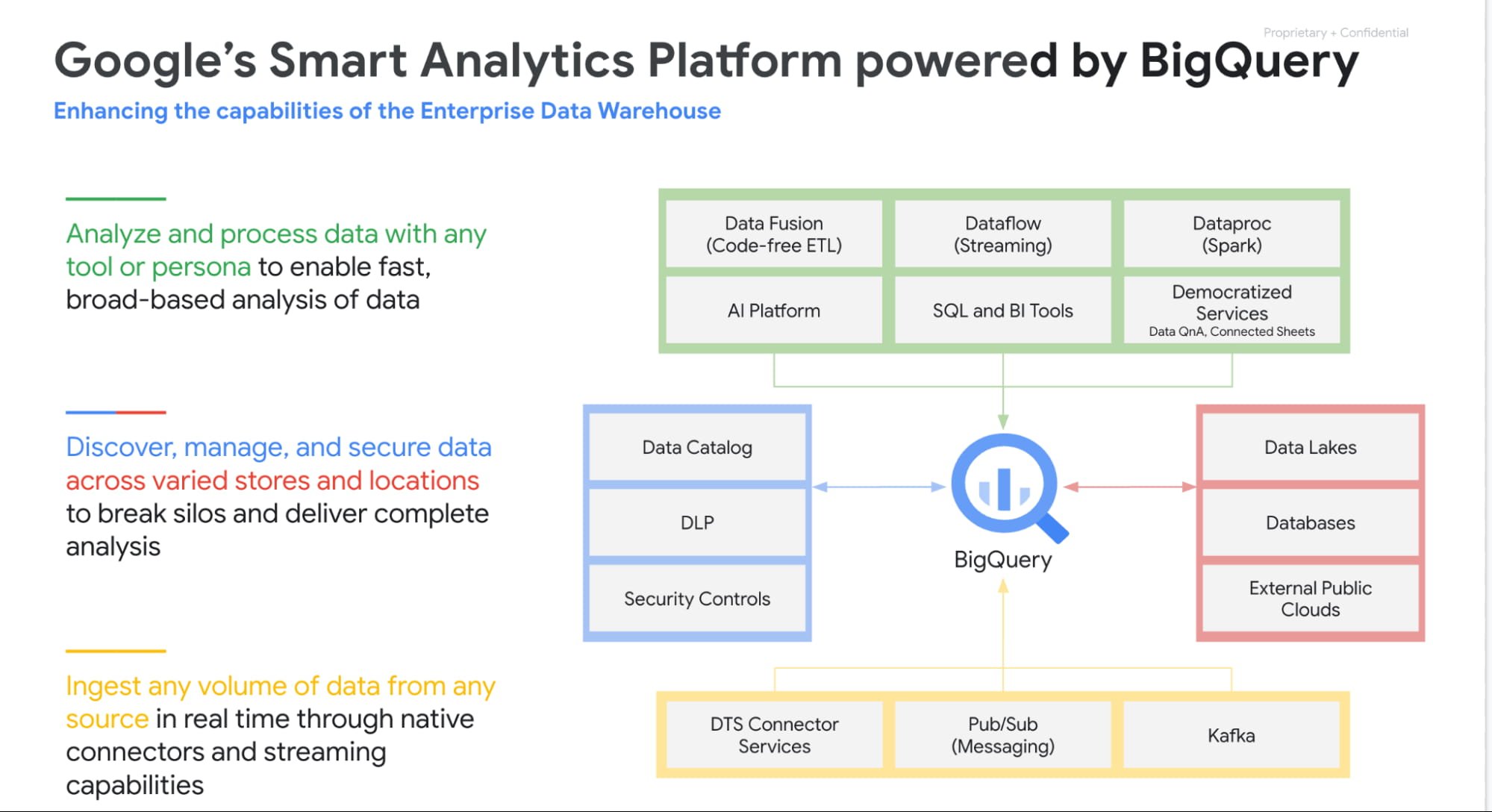
BigQuery による世界規模の分析
BigQuery は優れたプラットフォームであり、過去 11 年にわたってさまざまな側面でイノベーションを提供し続けています。スケーラビリティは常に BigQuery の大きな差別化要因です。多くのお客様が BigQuery で 100 ペタバイトを超えるデータを扱っており、最大規模のお客様のデータ量は今やエクサバイトに達しようとしています。また、このように BigQuery を大規模に利用している場合、クエリの対象行数は数兆行に及びます。
しかし、Google にとってスケールとは、単に大量のデータを保存または処理することではありません。スケールは、Google が世界中のすべての組織にリーチするための手段でもあります。これこそが、BigQuery サンドボックスがリリースされた理由です。BigQuery サンドボックスを利用すると、クレジット カードなしで BigQuery を試すことができます。これにより、数万人規模のお客様にリーチすることが可能になりました。さらに、BigQuery を簡単に使い始められるように、Firebase、Google 広告、Google アナリティクス 360 などのさまざまな Google ツールとのインテグレーションも構築されています。
最後に、BigQuery を採用しやすいように、料金プランはクエリ単位の課金、定額サブスクリプションの購入、秒単位の容量の購入からお選びいただけるようになりました。自動スケーリング機能により、定額サブスクリプションの割引と Flex Slots のスロットによる自動スケーリングを組み合わせてコストを最適化できます。

データ アナリストをデータ サイエンティストに変えるインテリジェントなデータ ウェアハウス
BigQuery ML は、Google が過去数年間に市場投入した最大のイノベーションの一つです。Google は、機械学習を民主化することですべてのデータ アナリストをデータ サイエンティストにするというビジョンを描いています。ML プラットフォームに関する時間の 80% はデータの移動、準備、変換に費やされています。これは大きなデータ ガバナンスの問題も引き起こしており、今日ではすべてのデータ サイエンティストが貴重なデータを複製しています。Google のアプローチは非常にシンプルでした。それは次のような問いかけから始まりました。「データを ML エンジンに渡すのではなく、ML をデータの元に持っていったらどうなるだろうか?」
BigQuery ML はこのようにして誕生しました。そこでは、2 行の SQL コードを記述するだけで ML モデルを作成できます。
この 4 年間に Google は、回帰、行列分解、異常検出、時系列、XGboost、DNN などの多くのモデルをリリースしました。お客様はこれらのモデルを使用して、セグメンテーション、おすすめの提案、時系列予測、荷物配達見積もりなどの複雑なビジネス問題を簡単に解決しています。このサービスは人気が高く、今では Google の上位顧客の 80% 以上が BigQuery ML を使用しています。ML / AI の平均採用率が 30% という低い水準にあることを考えると、80% はかなり良い結果です。

BQML と Vertex AI のより緊密なインテグレーションも発表されました。モデルの説明可能性は、個々の特徴が予測結果にどの程度貢献したかを把握することで ML の予測分類モデルや回帰モデルの結果を説明する機能を提供します。また、ユーザーが Vertex で BigQuery ML モデルを管理、比較、デプロイし、Vertex Pipelines を利用して BigQuery ML モデルのトレーニングや予測を行うこともできます。
BigQuery によるリアルタイムのストリーミング分析
お客様の期待は変化しており、今では誰もがあらゆるものを瞬時に手に入れたいと望んでいます。Gartner によると、2024 年末までに企業の 75% は AI を試験運用から本番運用に移行させ、その結果ストリーミング データとストリーミング分析のインフラストラクチャは 5 倍増加します。
BigQuery のストレージ エンジンはリアルタイム ストリーミング向けに最適化されています。BigQuery は数千万件のイベントのリアルタイムのストリーミング取り込みをサポートしており、クエリ パフォーマンスへの影響はありません。さらに、ストリーミング データに加えてマテリアライズド ビューと BI Engine(一般提供が開始されました)も使用できます。BigQuery は常に最新のデータを迅速に提供することを保証します。マテリアライズド ビューと BI Engine は、Google のシステムによって自動的に更新されます。
多くのお客様は、PubSub サービスを使用してリアルタイムのイベントを収集し、Dataflow を通じてそれらのイベントを処理してから BigQuery に取り込んでいます。これはストリーミング ETL と呼ばれるデータ取り込みパターンで、非常によく使われています。昨年発表された PubSub Lite は 90% 低料金で、DIY Kafka デプロイメントよりも TCO が低くなります。
さらに Dataflow Prime も発表されました。これは次世代の Dataflow プラットフォームです。ビッグデータ処理プラットフォームはこれまで、ワークロードの最適化に際して水平スケーリングのみに焦点を合わせていました。しかし、Google はストリーミング AI のような新しいパターンやユースケースを見出しました。ストリーミング AI では、データを準備するいくつかのステップをパイプラインに組み込むことができ、GPU ベースのモデルを実行する必要があります。お客様はさまざまなサイズやシェイプのマシンを使用してこれらのパイプラインをできる限り最適に実行することを要求します。これはまさに Dataflow Prime が実現することです。Dataflow Prime は垂直自動スケーリングを提供し、お客様のパイプラインにリソースを適切にフィットさせます。これにより、パイプラインの費用は大幅に低下すると考えられます。
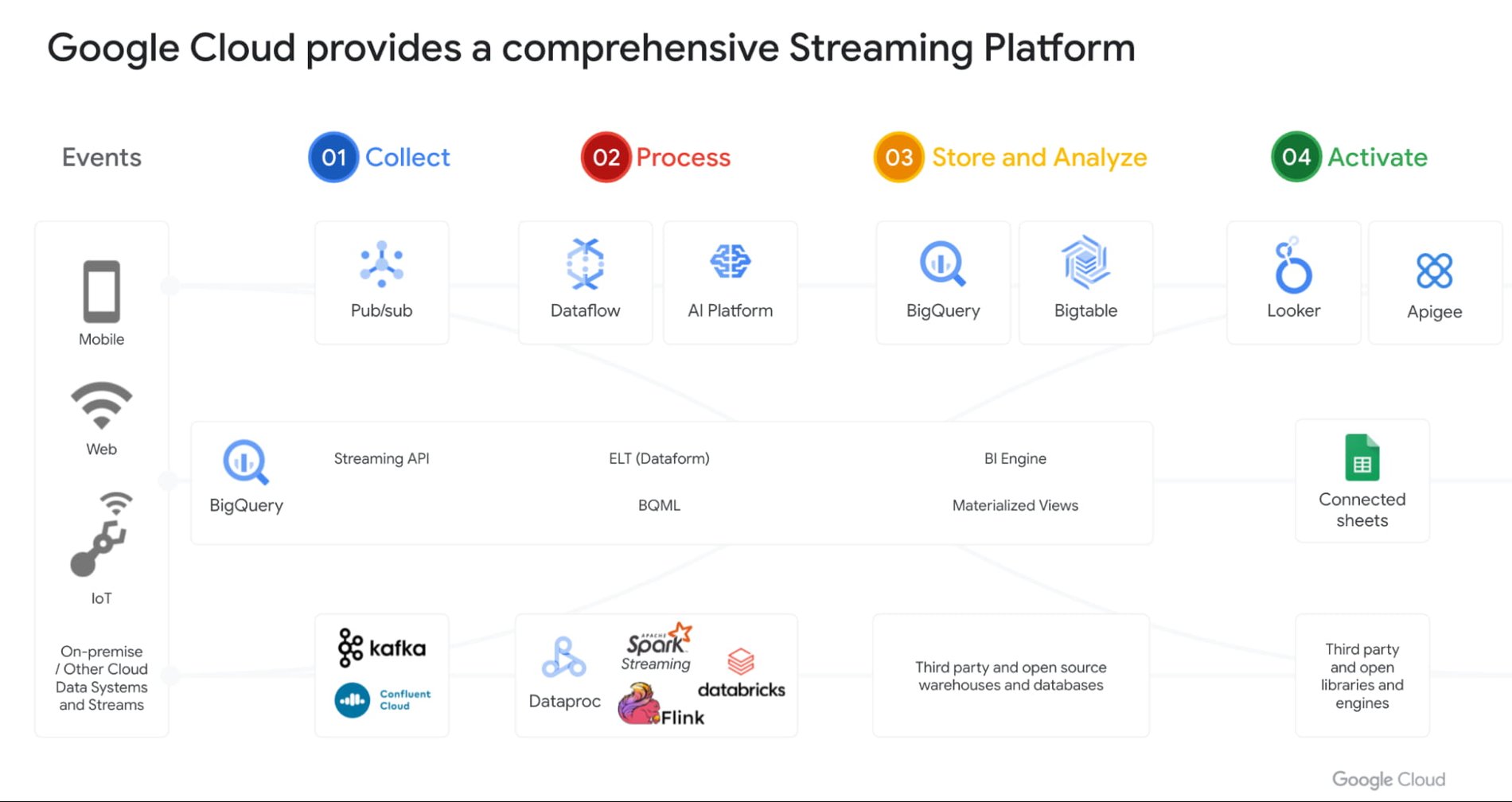
Datastream(Alooma の技術を基に構築された変更データ キャプチャ サービス)は、お客様の最後の主要な問題空間を解決しました。このサービスは、MySQL、Postgres、Oracle などのオペレーショナル データベースに加えられた変更を自動的に検出し、それらを BigQuery と同期します。
最も重要なのは、これらすべてのプロダクトが一連のテンプレートを通じて互いにシームレスに連携するということです。私たちは来年 1 年かけてこれをより一層シームレスにすることを目標としています。
BigQuery によるオープンなデータ分析
Google はこれまでも、オープンソース イニシアチブの力を信じてきました。Google のお客様は、Spark、Flink、Presto、Airflow などのさまざまなオープンソース ソリューションを好んで使用しています。Dataproc と Composer を使用すれば、これらの各種オープンソース フレームワークを GCP で実行し、Google のスケール、スピード、セキュリティを活用できます。Dataproc は優れたサービスで、オンプレミスの Hadoop 環境からの移行を大幅に簡素化します。しかし、お客様はジョブに専念したいのであって、クラスタの管理に時間を取られたくはありません。
そのため、Dataproc Serverless Spark(一般提供)サービスが Next 2021 でリリースされました。この新しいサービスは、Google が新たに取り組み始めた「データをシンプルにする」という主要な設計原則の一つに準拠しています。
BigQuery と同じように、クエリを簡単に実行できます。Google Cloud 上の Spark により、ジョブの実行も簡単です。これについてうまくまとめた記事が ZDNet に掲載されています。この記事をお読みいただくことをおすすめします。
Google のお客様の多くは Kubernetes に移行しており、Kubernetes を Spark 用のプラットフォームとして使用することを望んでいます。まもなく発表される Spark on GKE サービスは、Spark ワークロードを既存の Kubernetes クラスタにデプロイできるようにします。
しかし、私が最も魅力を感じているのは、Spark を BigQuery ストレージで直接実行できることです。BigQuery ストレージは、高度に最適化された分析用ストレージです。Spark を BigQuery ストレージで直接実行することは、BigQuery ML の場合と同じようにコンピューティングをデータの元に持ち込むことであり、データをコンピューティングに移動する必要がなくなります。
ログ分析を強化する BigSearch
Google は BigQuery に検索の力をもたらします。お客様はすでに大量のログデータを BigQuery に取り込んでログデータの分析を行っています。以前から、ネイティブ JSON と検索のサポートを強化するよう求める声がお客様から寄せられていました。Next 21 で、これら両方の機能がまもなく提供されることが発表されました。

高速なクロスカラム検索は、構造化データ、半構造化データ、非構造化データの効率的なインデックス付けを提供します。ユーザー フレンドリーな SQL 関数により、テーブル内のすべてのテキストをスキャンしなくてもデータポイントを迅速に見つけることができ、データがどの列に存在するかを知ることさえできます。
これはネイティブ JSON と緊密に統合されているため、BigQuery のパフォーマンスとストレージが JSON に最適化され、構造化されていないデータ構造、または絶えず変化するデータ構造を検索できるようになります。
マルチクラウドおよびクロスクラウド分析
マルチクラウドの導入に関する調査結果は明白で、2021 年には 92% の企業がマルチクラウド戦略を行っていると報告しています。Google は常にさまざまな選択肢をお客様に提供し、お客様の現状に即してその要求に応えることを信条としています。お客様のデータが複数のクラウドに分散して存在する現在、BigQuery のような便利なツールを他のクラウドでも利用したいというニーズが生じるのは必然でした。
さらに、お客様が求めているのは明らかにクロスクラウド分析であり、異なるクラウドで実行できるだけのマルチクラウド ソリューションではありませんでした。要するに、すべてのデータを単一の画面に表示する、データがどこに存在するかを気にせずにデータ分析を行う、下り(外向き)の費用を避ける、異なるクラウド上のデータセットを横断してクロスクラウド分析を行うことが必要になります。

Google は BigQuery Omni でこのビジョンを実現しました。これは複数のパブリック クラウドに保存されているデータを分析する新しい手段です。競合製品とは異なり、BigQuery Omni は異なるクラウドにまたがるサイロを生み出しません。BigQuery は単一のコントロール プレーンを提供し、アナリストはそこから自身がアクセス可能なすべてのクラウド上のすべてのデータを見ることができます。アナリストはクエリを記述するだけでよく、クエリの送信先は AWS、Azure、GCP の中から自動的に判別され、そのクラウドでローカルにクエリが実行されます。したがって、下り(外向き)の費用は発生しません。
AWS と Azure 向けの BQ Omni の一般提供が Google Next 21 で発表されました。私はこのビジョンを実現させたチームを本当に誇りに思います。Vidya のセッションを視聴し、Johnson and Johnson がどのようにしてマルチクラウドの世界でイノベーションを遂げたかをご覧ください。
BigQuery と Earth Engine による地理空間分析
私たちは Google 地理空間チームと協力し、長年にわたって BigQuery 内で GIS 機能を提供しています。Next において、Earth Engine と BigQuery、Google Cloud の ML 技術、および Google Maps Platform とのインテグレーションが発表されました。
このインテグレーションから、持続可能な調達、エネルギーの節約、ビジネスリスクの把握を可能にするために、どのようなシナリオやユースケースが生まれるかを想像してみてください。
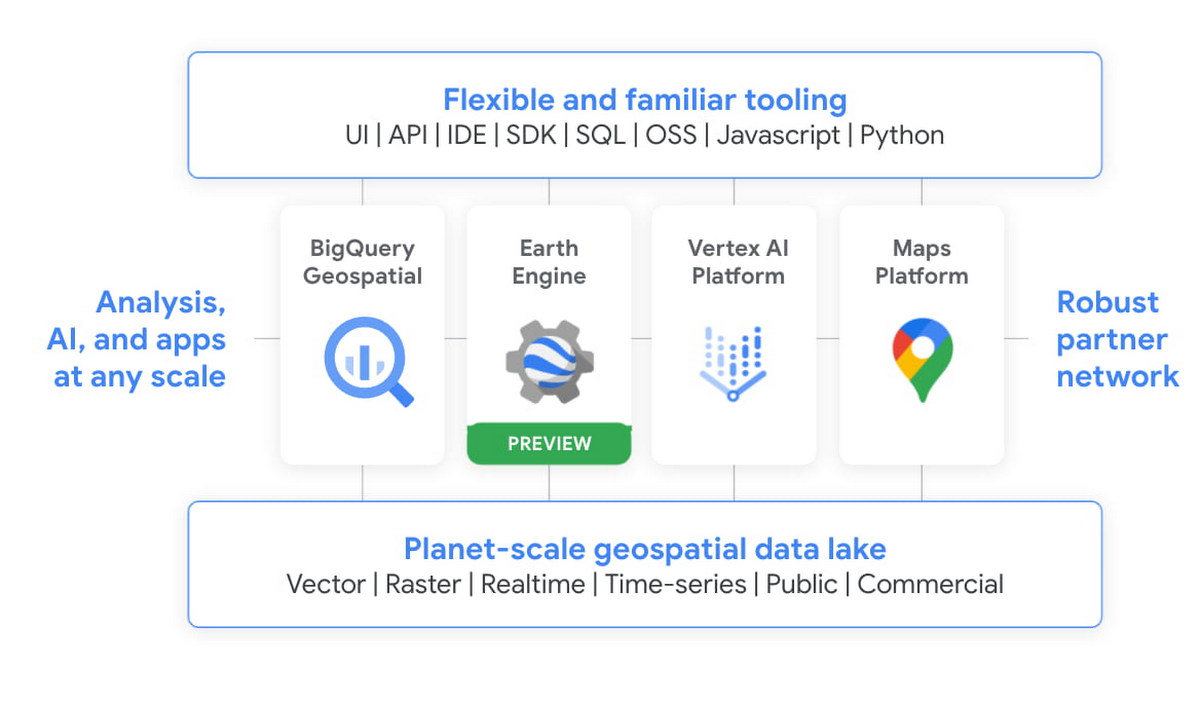
このように Google と Google Cloud の強みを結び付けることで、データを利用した持続可能な未来の構築が容易になります。
データ交換および共有プラットフォームとしての BigQuery
BigQuery は共有プラットフォームになることを目指して構築されています。現在、3,000 を超える組織が 250 ペタバイトを超えるデータを組織全体で共有しています。Google はまた、150 を超える一般公開データセットを各種ユースケースで使用できるようにもしています。これに加えて、Google トレンドのような独自のデータセットも BigQuery から利用できます。これにより、組織はリアルタイムのトレンドを把握し、ビジネス上の問題に適用できます。

Analytics Hub のプレビューが発表されたのは大きな喜びです。Analytics Hub は、プライベートおよびパブリックの分析エクスチェンジを構築する機能を組織に提供します。これには、データ、分析情報、ML モデル、可視化が含まれます。これは、業界をリードする BigQuery のセキュリティ機能を基盤として構築されています。

データサイロの解消
データは組織内のさまざまなシステムに分散しているため、簡単にデータサイロを解消して誰もがすべてのデータにアクセスできるようにすることが不可欠です。また、私が特に注目しているのは、Informatica との協力による移行ファクトリーの構築や、1,000 を超える(そしてさらに増え続けている)共通の顧客を持つ Trifacta や FiveTran のような企業とのデータ移行やインテリジェントなデータ ラングリングに関する共同の取り組みです。さらに、お客様を支援するネイティブ Google サービスの提供もおろそかにしてはなりません。
Google は 2018 年に Cask を買収し、Data Fusion でセルフサービスのデータ統合サービスをリリースしました。今では、Fusion でドラッグ&ドロップするだけで複雑なパイプラインを作成できます。今年は SAP データの活用に注力し、SAP 用のさまざまなコネクタやアクセラレータをリリースしてこれを達成しました。
GCP Next では、BigQuery Migration Service のプレビューも発表されました。Google のお客様の多くは以前のデータ ウェアハウスやデータレイクを BigQuery に移行しています。BigQuery Migration Service は、そのようなお客様のために移行を簡素化するエンドツーエンドのツールを提供します。
そして本日、さらに多くのお客様が BigQuery への移行を容易に行えるように、CompilerWorks の買収が発表されました。CompilerWorks の Transpiler は、実世界での SQL 移行を容易にするために一から設計されており、移行に要する時間を短縮します。10 を超えるレガシー エンタープライズ データ ウェアハウスからの移行をサポートしているこのテクノロジーは、数か月以内に BigQuery Migration Service の一部として利用可能になる予定です。
BigQuery によるデータの民主化
この 4 年間、私たちは BigQuery のデータから実用的な分析情報を簡単に引き出せるように努力を重ねてきました。最も優先されたのは、これを可能にするとともに Google ネイティブの機能も備えた優れたツールを提供できる強力なパートナー エコシステムを提供することでした。
2019 年に紹介され、今年初めにプレビュー版が公開されて Microsoft PowerBI や Tableau のようなツールと肩を並べる BI Engine が一般提供となり、すべてのお客様が利用できるようになりました。
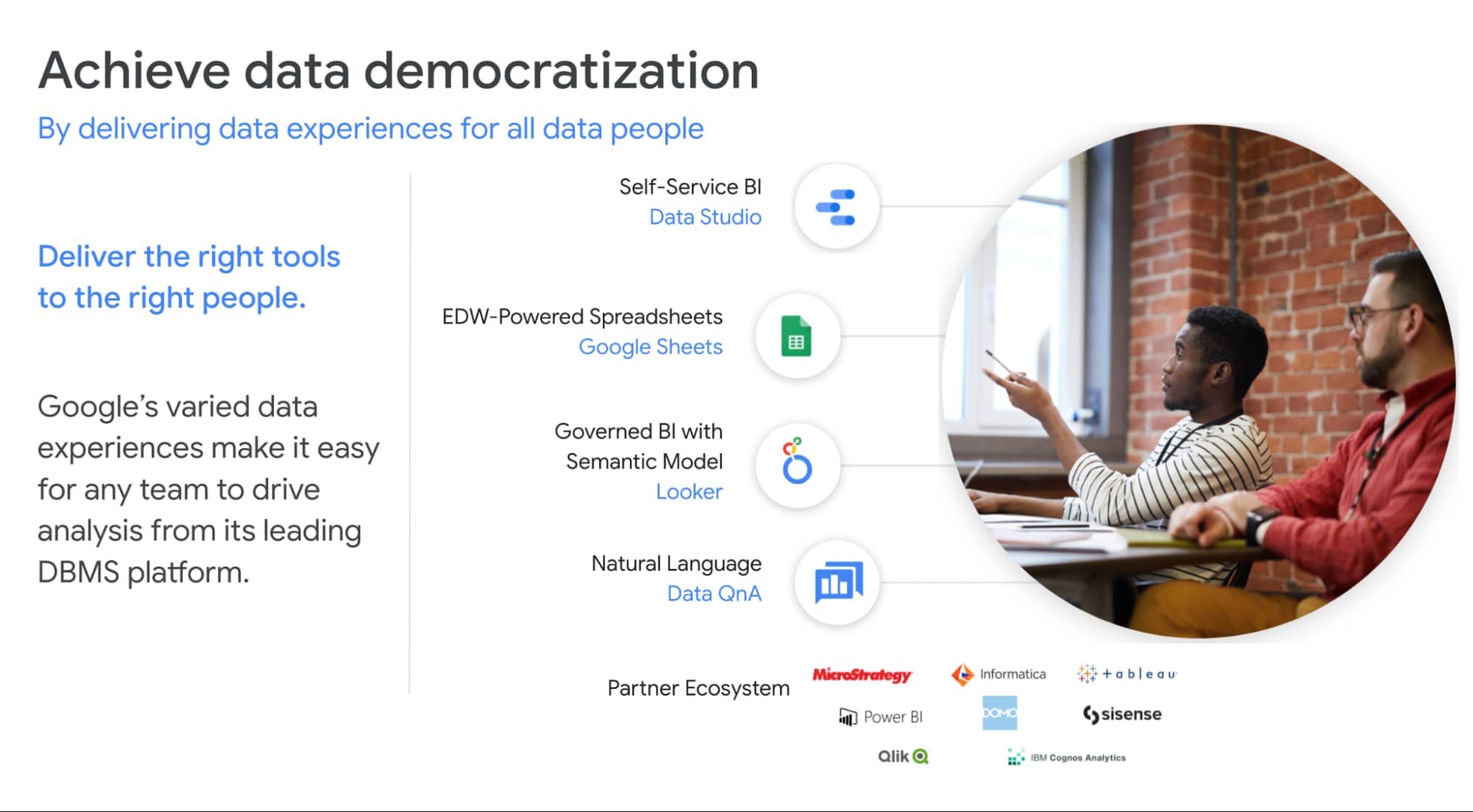
BigQuery + データポータルはピーナッツ バターとジェリーのようなものです。両者の組み合わせは実に良い働きをします。最初にリリースされたのはデータポータルが組み込まれた BI Engine で、これがすべてのユーザーに拡大されました。データポータルを使用している BigQuery ユーザーは 40% を超えます。BI Engine がきわめて高い効果を発揮したことから、次にこれを BigQuery API の不可欠な要素とし、すべての社内ツールとパートナー BI ツール向けにリリースしました。
Next 2021 で BI Engine の一般提供が発表されましたが、データポータルはすでに 2 年前から一般提供されています。データポータル チームは最近 Google Cloud に復帰し、パートナーシップはより一層強固になりました。データポータルをまだ使用したことがない場合は、その内容についてご確認いただき、こちらから今すぐ無料で試用することをおすすめします。
BigQuery 用のコネクテッド シートは、私がよく使う組み合わせの一つです。これを利用すれば、組織内のすべてのビジネス ユーザーが標準的な Google スプレッドシートを使用するのと同じ簡便さで数十億のレコードを分析できます。私は個人的にコネクテッド シートを毎日使用してすべてのプロダクト データを分析しています。
Google は、統制された BI ソリューションによってセマンティック モデリング レイヤをお客様に提供するというビジョンを実現するために、2020 年 2 月に Looker を買収しました。Looker は、BigQuery ML を含む BigQuery と緊密に統合されています。Google と Tableau の最新のパートナーシップにより、Tableau のユーザーはまもなく Looker のセマンティック モデルを利用できるようになります。これにより、データへのアクセスを民主化しながら、新たなレベルのデータ ガバナンスを手にすることができます。
最後に、私はいつの日か Google アシスタントをエンタープライズ データで利用できるようにしたいという夢を持っています。これは Data QnA のビジョンです。これについてはまだ着手したばかりであり、実現に向けて今後も努力を続けていきます。
プラットフォームを一元化するインテリジェントなデータ ファブリック
私たちの市場を形成しているもう一つの重要なトレンドは、データメッシュです。私は今年初めに、Starburst からこの話題について説明するよう依頼を受けました。Google ではこのコンセプトに何年も取り組んでいます。私たちはすべてのデータを 1 か所に整然と整理するのが望ましいと考えていますが、お客様の現実がそうなってはいないことも認識しています(これについて興味がある方は、この話題について私と Fivetran の George Fraser 氏、a16z の Martin Casado 氏、Databricks の Ali Ghodsi 氏がディスカッションした記事をご覧ください)。
この分野に携わってきた歳月で私がお客様から学んだ重要なことは、お客様が本当に必要としているのはデータカタログでも一連のデータ品質ツールやガバナンス ツールでもなく、インテリジェントなデータ ファブリックであるということです。そのために Google が開発したのが Dataplex です。このプロダクトも Next で一般提供が発表されました。
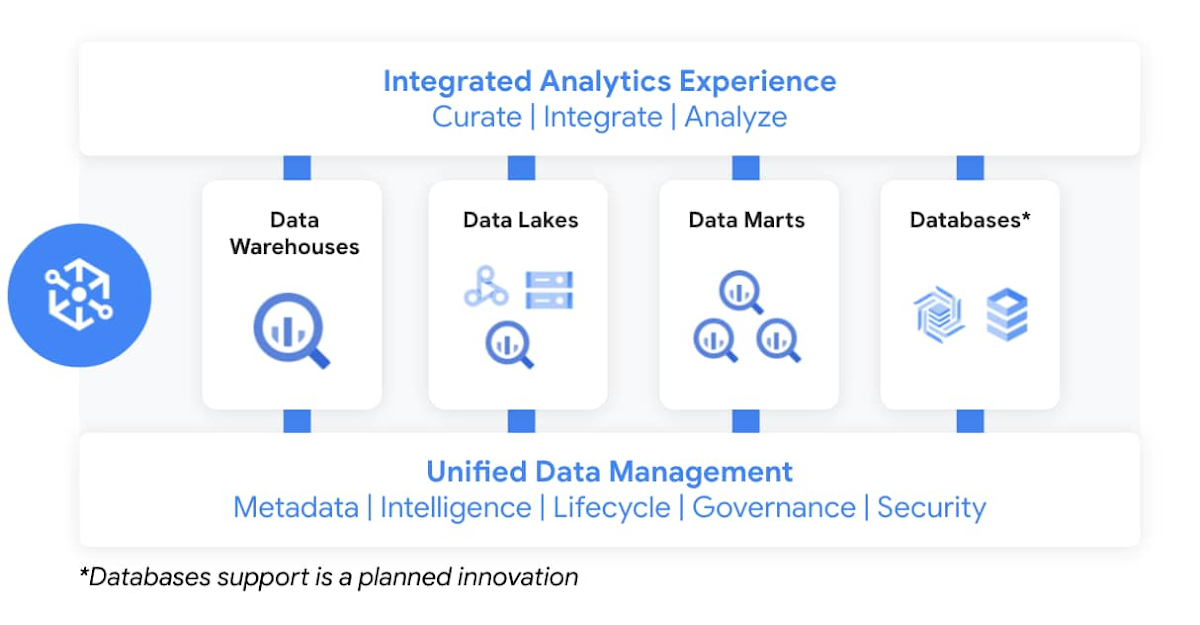
Dataplex を使用すると、データレイク、データ ウェアハウス、データマートの垣根を越えてデータを一元的に管理、モニタリング、統制し、さまざまな分析ツールやデータ サイエンス ツールからデータに確実にアクセスできます。これにより、データの移動や複製を行わずに、自社のビジネスにとって意味のある形でデータを整理および管理できます。その結果生じるレイク、データゾーン、アセットなどの論理構造は、基になるストレージ システムを抽象化し、データアクセス、セキュリティ、ライフサイクル管理などを取り巻くポリシーを定めるための基礎となります。Prajakta Damle のセッションを視聴し、Deutsche Bank が分散データ全体に広がる一元化されたデータメッシュについてどのように考えているかをご覧ください。
最後に
Google の勢いはアナリストにも認められています。今年を振り返ってみると、Google の幅広いデータ分析ポートフォリオ全体にわたって私のチームや私自身を支えてくれたお客様やパートナーの皆様には感謝してもしきれません。3 月には、Google BigQuery が The Forrester Wave™: Cloud Data Warehouse、Q1 2021 においてリーダーに位置付けられました。さらに 6 月には、Dataflow が The Forrester Wave™: Streaming Analytics、Q2 2021 レポートでリーダーに位置付けられました。
お客様がなぜ他のハイパースケーラーやクラウド データ ウェアハウジングではなく Google を選ぶのか、その理由を体感したい場合は、最近公開されたデータ ジャーニー シリーズをご覧いただくことをおすすめします。そこでは、Google Cloud を利用してクラウドにモダナイズしようとしている組織の事例を紹介しています。

Google Cloud データ分析ポートフォリオは今や業界を牽引する存在であり、自分がその一翼を担っていることが私の仕事に対する原動力となっています。お客様やパートナーの方々と会えない日々は寂しく、以前のように対面でお話しできなかったことは率直に残念ですが(写真はパンデミック前最後の対面講演における私の様子です)、今回の Google Next は格別なものでした。ぜひプロダクト イノベーションの世界に飛び込み、そのテーマを深く考えてみてください。
次回の Google Next は対面で開催できることを願っております。
- プロダクト管理シニア ディレクター Sudhir Hasbe



