BigQuery と Variant Transforms による Mayo Clinic のデータ プラットフォームの強化
Google Cloud Japan Team
※この投稿は米国時間 2020 年 8 月 14 日に、Google Cloud blog に投稿されたものの抄訳です。
ゲノムデータは、Google のお客様や Mayo Clinic のような戦略的パートナーが扱うデータの中で、最も複雑かつ重要なデータに属します。多くの場合、患者の診断や新しい治療法の発見のために、ゲノム バリアント データが扱われます。このデータは、特定のサンプルと参照ゲノムの相違点をまとめたものです。各サンプルのバリアントは通常 Variant Call Format ファイル(VCF)として保存されますが、このデータに対して分析と機械学習を実施する場合、ファイルは適切な手法とは言えません。2018 年、Google は Variant Transforms をリリースしました。このツールにより、VCF データを BigQuery に簡単に読み込んで、こうしたユースケースに対応できます。
それ以降、Google は Variant Transforms の改良に懸命に取り組んできました。たとえば、ファイルベースのツールの利用を希望するお客様向けに BigQuery から VCF を再度取り出す機能などを追加しました。今回は、BigQuery の新機能を使用してクエリ実行の費用を大幅に削減する Variant Transforms の新しいスキーマについてご紹介します。
- シャーディング: Variant Transforms は出力を複数のテーブルにシャーディングします。各テーブルには、ゲノムの特定の領域、この場合は染色体全体のバリアントが含まれます。各染色体のバリアントをそれぞれのテーブルに保存することで、いずれかの染色体のわずかなゲノム領域のみを分析する場合に、全染色体に対してクエリを実行するための費用を費やさずに済みます。各テーブルをよりコンパクトに、管理しやすくすることに加えて、シャーディングは整数範囲パーティショニングの前提条件となっています。
- 整数範囲パーティショニング: パーティション分割テーブルとは、パーティションと呼ばれるセグメントに分割された特殊なテーブルであり、これによってデータの管理とクエリを効率的に行えるようになります。大きいテーブルを小さいパーティションに分割することでクエリのパフォーマンスを向上させることができるほか、クエリで読み取られるバイト数を減らすことで費用も抑えられます。Variant Transforms は整数パーティション分割テーブルを使用して必要なバリアントに対してのみクエリを実行します。
- クラスタリングとは、テーブルのスキーマの 1 つまたは複数の列のコンテンツに基づいてテーブルを自動的に整理する手法のことです。クラスタ化列は、関連するデータを同じクラスタ内に配置するために使用されます。BigQuery はクラスタ化列の値に基づいてデータを並べ替え、BigQuery ストレージ内の複数のブロックにデータを整理します。パーティショニングに加えてクラスタリングも使用すると、大きなバリアント テーブルで非常に効果的です。なぜなら、各パーティション内のバリアントを効率的に整理し、並べ替えることができるためです。
最終的に、典型的な遺伝子のすべてのバリアントを検出するためのクエリにかかる費用が、以前と比べて 5 分の 1~40 分の 1 になりました。短いゲノム領域にわたるクエリの場合、関連費用を最大で 200 分の 1 に抑えることができます。1
Mayo Clinic での Variant Transforms の活用
こうしたパフォーマンスは、Mayo Clinic のようなパートナーに大きな力を与えています。2019 年、Mayo Clinic は Google Cloud 上に新しい Omics Data Platform(ODP)を構築しました。Variant Transforms と Google Cloud Healthcare API および Google Cloud Life Sciences API を併用し、Mayo Clinic の患者向けに次世代の患者分析情報をもたらしました。Mayo Clinic は、バリアント データを生成し、履歴データすべての読み込みも行うパイプラインに ODP を統合しました。
「Mayo Clinic は、すべてのバリアントに意味を見いだすことに関心を寄せています。このバリアントは病原性か、それとも良性か?このバリアントは大きな影響を及ぼす可能性があるか?このバリアントは患者の薬物代謝に影響を与えるか?といった具合に」と、Mayo Clinic で IT テクニカル スペシャリストを務める Mike Mundy 氏は述べています。同氏は ODP の導入を担当されています。「バリアントのアノテーションには多数のソースがあり、それらは新しい情報で常に更新されています。」Mayo Clinic の ODP にもアノテーションのソースの管理機能があり、アノテーション データは BigQuery に読み込まれます。バリアント データとアノテーション データは別々に維持されるため、最新の情報を含む動的なバリアントのアノテーションも実現できます。
ODP は Google Cloud を基盤とするマイクロサービス アーキテクチャを使用して導入されます。その際、アカウントと権限の管理には Cloud IAM が使用され、データレイクには Cloud Storage、データ ウェアハウスには BigQuery が使用されます。ODP のセキュリティ モデルでは、調査の対象データと患者の臨床データが別々に保存されます。調査研究または臨床シークエンシング プロジェクトごとに独自の Google Cloud プロジェクトを設定し、きめ細かいアクセス制御を行います。ODP には、ODP のマイクロサービスを使用して、バリアント データに対するクエリ実行と動的なアノテーションの実行を行うためのユーザー インターフェースを提供する Omics Data Console も含まれています。
Variant Transforms の性能の検証
新しいスキーマのパフォーマンスをテストするために、ある固定長のゲノム領域のすべてのバリアントを検出するクエリを記述し、1,000~1,000,000 塩基対の複数の領域長を検証しました。ランダムな開始点から各クエリを 10 回実行し、中央値の費用(課金されるバイト数)を記録しました。このプロセスを大きな染色体と小さな染色体の 2 つで繰り返し、新しいスキーマの効率性に対する染色体サイズの影響を検証しました。以下は 1,000 人ゲノム データセットに対する新しいスキーマのパフォーマンスを処理量(MB)で示したものです(値が小さいほど優れています)。
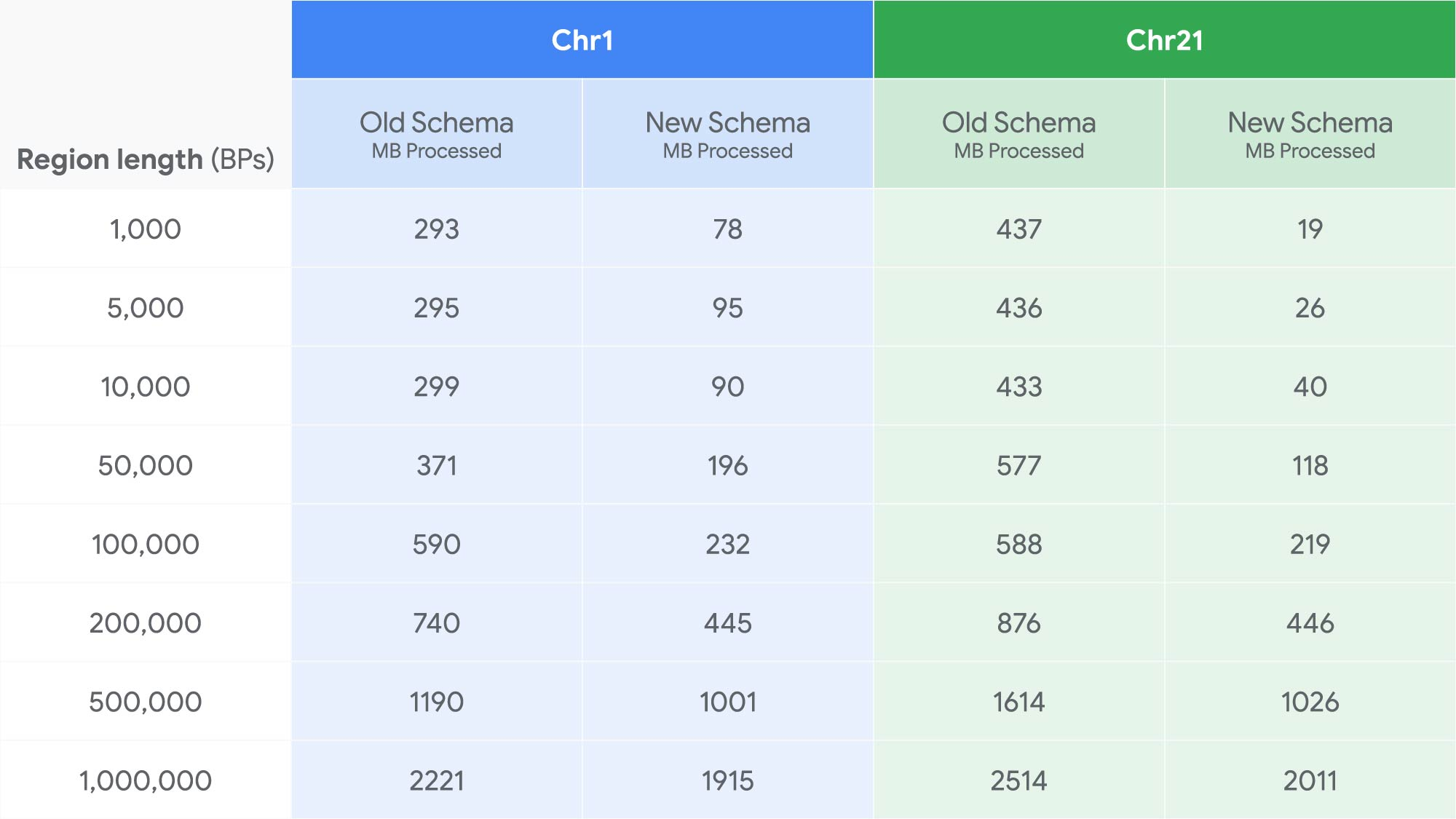
また、以下は gnomADv3 データセットに対する新しいスキーマのパフォーマンスを処理量(MB)で示したものです(値が小さいほど優れています)。
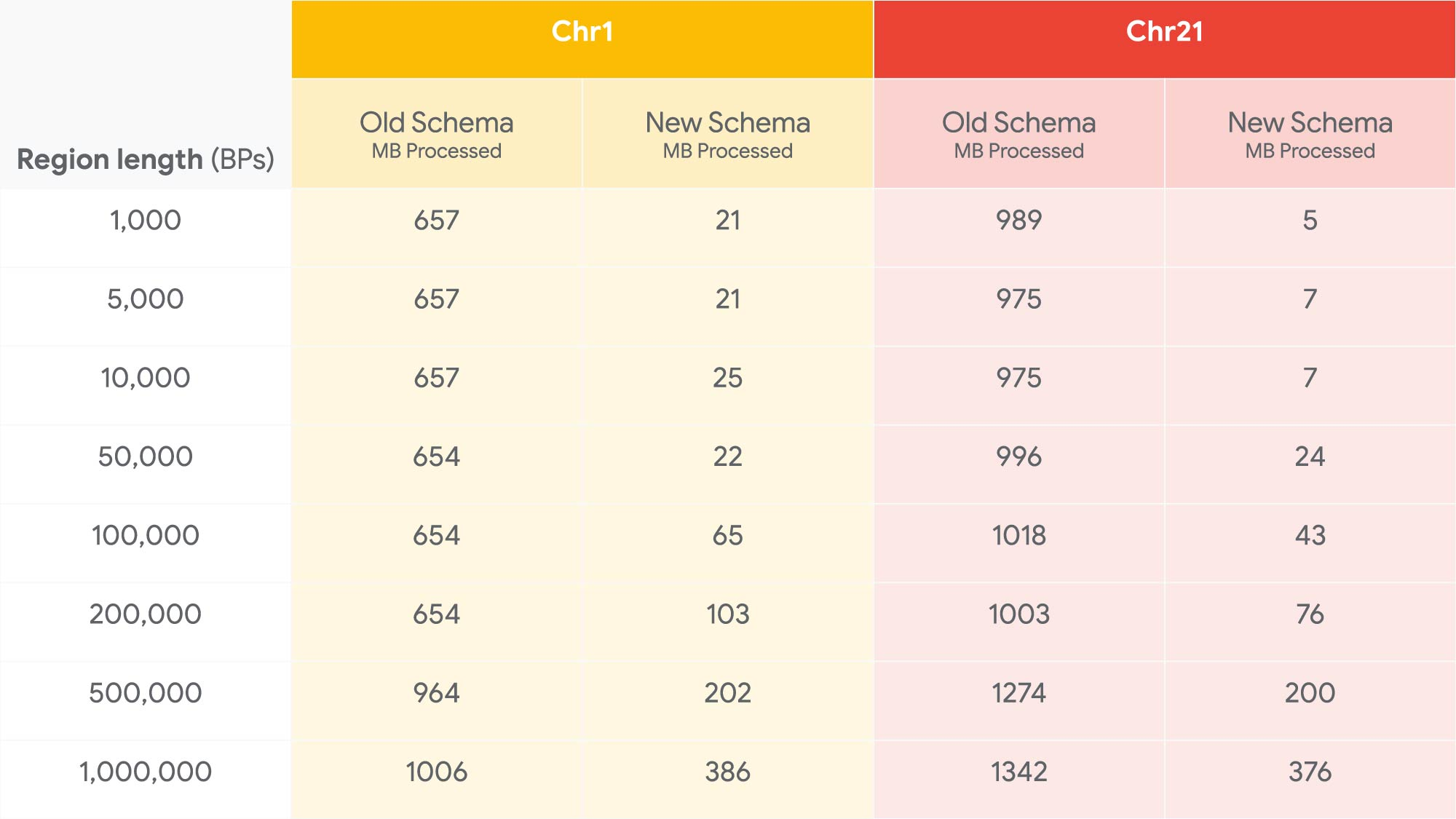
典型的な遺伝子のおおよその長さは 50,000 塩基対に満たないため、gnomADv3 で 1 つの遺伝子のすべてのバリアントを検出するためのクエリの実行費用は約 25 MB となります。つまり、BigQuery の 1 TB の無料サービスを利用すれば、約 42,000 の類似したクエリを毎月無料で実行できることになります。
Mayo Clinic はシークエンシングを数十万人の患者に拡大しているため、既存のソリューションに替えて Google Cloud と Variant Transforms を利用することで、3 年間で 150 万ドルを節約できたと見積もっています。Variant Transforms の新バージョンはチームの能力をさらに高め、精密医療の実現に貢献するでしょう。
Mayo Clinic と Variant Transforms の詳細をご覧ください。
1. この投稿の「Variant Transforms の性能の検証」セクションで説明されているテストに基づきます。Variant Transforms のパフォーマンス改善の状況は環境によって異なります。パフォーマンスは、シャーディングされた出力テーブルのサイズ、バリアントの密度、繰り返される呼び出しの存在(遺伝子型が決定されている統合入力の場合)など、多数の要因の影響を受けます。
Jonathan Sheffi, Senior Product Manager, Life Sciences, Google Cloud
Saman Vaisipour, Software Engineer, Life Sciences, Google Cloud



