あらゆる Dataflow パイプラインを再利用可能なテンプレートに変換
Google Cloud Japan Team
※この投稿は米国時間 2020 年 10 月 2 日に、Google Cloud blog に投稿されたものの抄訳です。
組織内におけるデータ分析の増大にともない、ビジネスチームには、バッチジョブとストリーミング ジョブを実行し、エンジニアが作成したコードを活用できる機能が必要となります。しかし、既存のコードを再実行するには、多くの場合、開発環境を設定してコードを少し変更する必要がありますが、これはプログラミングのバックグラウンドがない人にとっては大きな課題となります。
この課題を念頭に置き、Google はこのほど、 Dataflow フレックス テンプレートを導入しました。これにより、あらゆる Dataflow パイプラインを、誰でも実行できる再利用可能なテンプレートにより簡単に変換できるようになります。
既存のクラシックテンプレートでも、デベロッパーはテンプレートを介してバッチおよびストリーミング Dataflow パイプラインを共有できるため、開発環境やコードを記述しなくても、誰でもパイプラインを実行できます。ただし、クラシック テンプレートは、いくつかの理由により厳密でした。
まず、デベロッパーがパイプラインを共有可能なテンプレートに変換すると、Dataflow パイプライン実行グラフが永続的に固定されるため、クラシック テンプレートは、デベロッパーが最初に想定した厳密な意味でのタスクを遂行するためにのみ実行されます。たとえば、Cloud Storage や BigQuery などの読み込み元のソースを選択する場合は、テンプレートの作成段階で決定する必要があり、テンプレート実行時にユーザーの選択に基づいて動的に行うことはできませんでした。そのため、デベロッパーは、細かなバリエーション(ソースが Cloud Storage か BigQuery かなど)を含む複数のテンプレートを作成しなければならない場合もありました。
次に、クラシック テンプレートは ValueProvider インターフェースに依存しているため、デベロッパーは限られたオプション リストの中からパイプライン ソースを選択し、シンクする必要があります。ValueProvider を実装すると、デベロッパーは、テンプレートが実際に実行されるたびに変数の読み取りを延期できるようになります。たとえば、デベロッパーはパイプラインが Pub/Sub から読み取ることを知っていても、実行時にユーザーがサブスクリプション名を選択できるよう、延期する場合があります。これはつまり、実際には、外部ストレージおよびメッセージ コネクタのデベロッパーが、Dataflow のクラシック テンプレートで使用される Apache Beam の ValueProvider インターフェースを実装する必要があるということです。
フレックス テンプレートの新しいアーキテクチャは、どちらの制限も効果的に解消するため、今後はフレックス テンプレートの使用をおすすめします。
クラシック テンプレートよりも柔軟性の高いフレックス テンプレートを使用すると、Dataflow ジョブの細かいバリエーションを単一のテンプレートから起動でき、任意のソースまたはシンク I/O の使用が可能になります。(テンプレート作成プロセス中ではなく)テンプレートの実行時に実行グラフが動的に作成されるようになったため、ソースファイル形式やシンクファイル形式の変更など、元の同じテンプレートでさまざまなタスクを実行するために、細かいバリエーションを加えることができます。また、フレックス テンプレートは ValueProvider の依存性を排除するため、どの入力ソース / 出力ソースでも使用できます。
次に、カスタム フレックス テンプレートの作成理由と作成方法をデベロッパー ガイドで説明します。
Dataflow パイプラインの共有が大きな課題となっていた理由
Apache Beam パイプラインは一般に入力データを(ソースから)読み取って変換し(ParDo などの変換を使用)、出力を(シンクに対し)書き込みます。
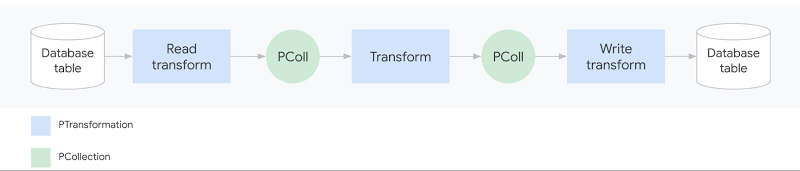
パイプラインは、複数の入力ソース、一連の連鎖変換(DAG のステップ)、複数の出力シンクを使用することで著しく洗練させることができます。作成した Apache Beam パイプラインは、Dataflow、Spark、Flink または Direct Runner(ローカル実行用)などのさまざまなランナーにデプロイして実行できます。テンプレートは、Dataflow ランナーでパイプラインを簡単に再実行できるようにする Dataflow 固有の機能です。
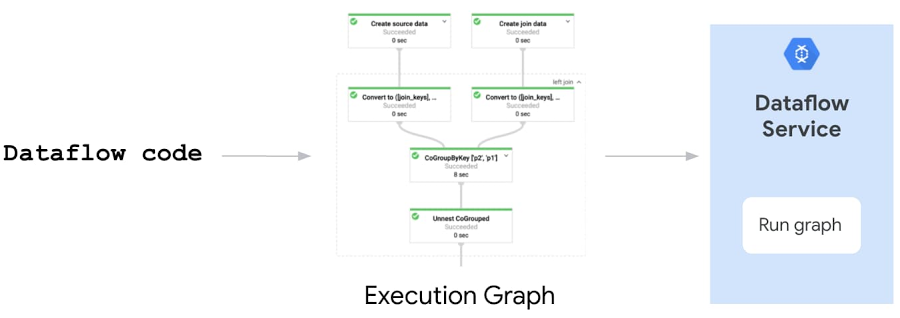
ところで、「パイプラインの実行」とはどういう意味なのでしょうか。Dataflow パイプラインを実行すると、Apache Beam SDK は、コードの局所的な実行、ソースの変換、実行グラフのビルド、シンク、ノード変換を行います。次に、実行グラフ オブジェクトが JSON 形式に変換(シリアル化)され、Dataflow サービスに送信されます。最後に、Dataflow サービスは複数の検証(API、割り当て、IAM チェック)の実行、グラフの最適化、パイプラインを実行するための Dataflow ジョブの作成を行います。
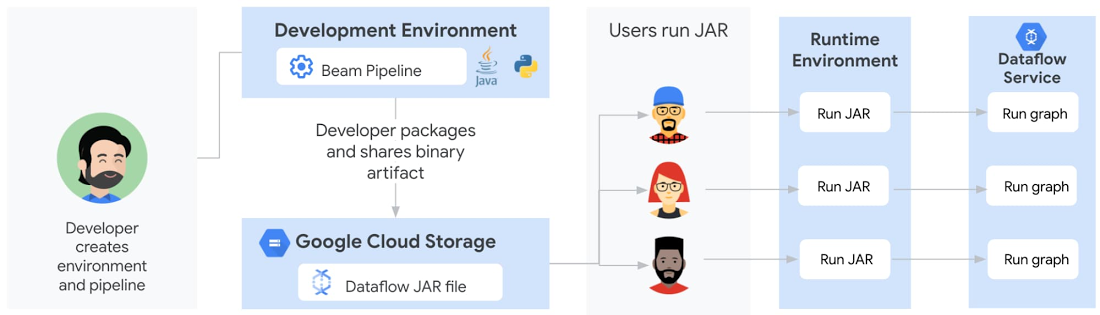
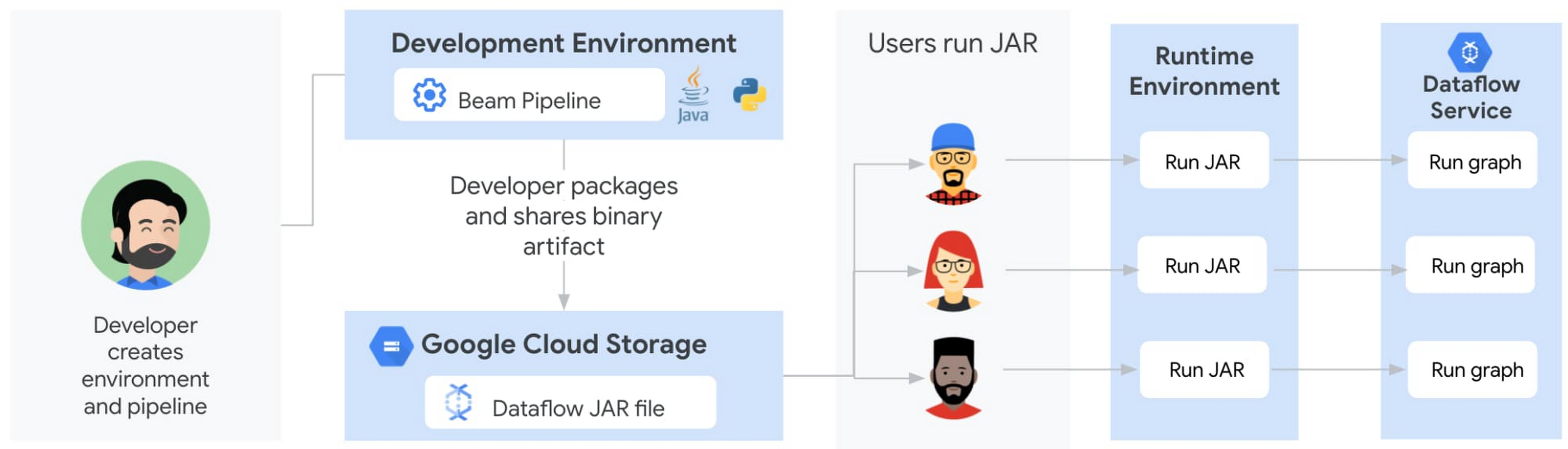
Dataflow テンプレート以前は、デベロッパーが同僚とパイプラインを共有することは困難でした。従来、デベロッパーはまず、開発環境(JDK、Apache Beam SDK、通常 Java または Python にインストールされた Maven または Gradle、通常 Python にインストールされた pip を使用)の作成、コードの記述、バイナリ アーティファクト(依存関係または Python と同等の fat JAR)の構築、Artifactory または Cloud Storage を介したアーティファクトの共有を行うことから始めていました。その後に、ユーザーはローカル ランタイム環境を設定し、バイナリを個々の環境に取り出して実行します。パイプラインが Java で記述されている場合は、ランタイム環境には Java JRE がインストールされている必要があり、パイプラインが Python ベースの場合は、デベロッパーが使用したすべての Python パッケージがインストールされている必要があります。最後に、ユーザーがパイプラインを実行すると、実行グラフが生成されて Dataflow サービスに送信され、クラウド上でパイプラインが実行されます。
これらのステップには、ブレークが起こり得るポイントがいくつかあり、技術的知識を持たないユーザーにとって、ランタイム環境を作成することは容易ではありませんでした。VM(cron を使用)またはサードパーティのスケジューラでパイプラインをスケジュールする場合でも、同様のランタイム環境が存在する必要があり、自動化プロセスを複雑にしていました。
クラシック テンプレートを使用して Dataflow パイプラインを共有
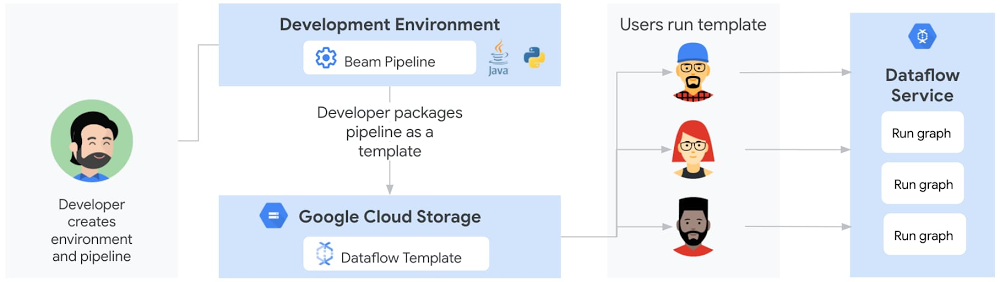
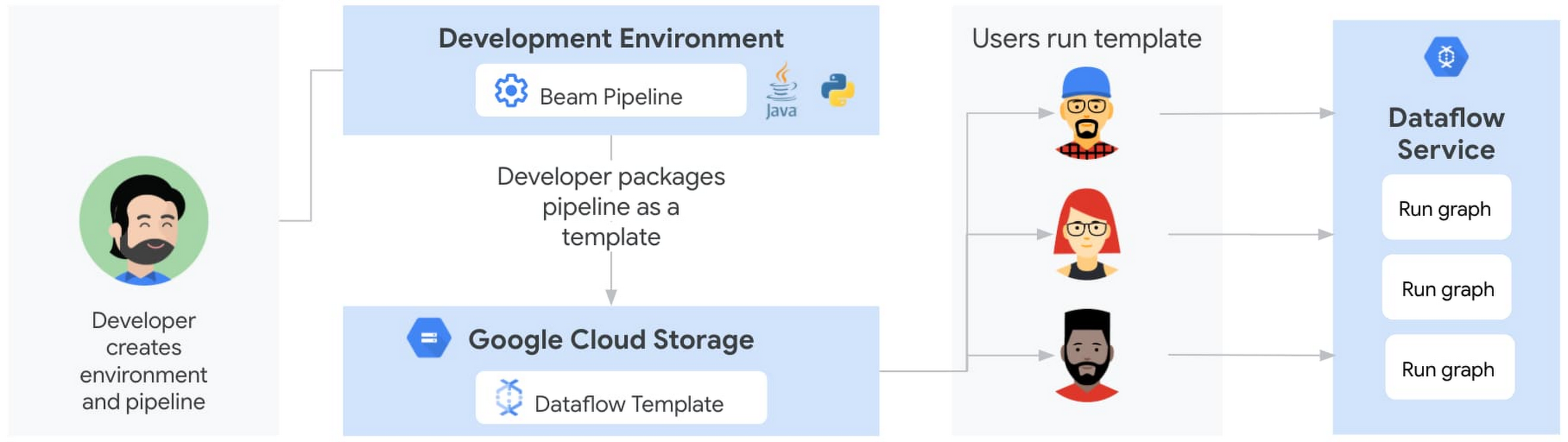
クラシック テンプレートは、Dataflow パイプラインを再実行するためのユーザー エクスペリエンスを大幅に向上させます。デベロッパーが開発環境でパイプライン コードを実行すると、パイプラインが Cloud Storage に保存されている Dataflow テンプレートに変換されるようになります。ステージング済みのテンプレートは、変換された JSON 実行グラフと依存関係(パイプラインとサードパーティのライブラリ)で構成されています。実行グラフは永続的に固定されており、ユーザーは DAG の形状を変更できません。Cloud Storage バケットの権限がユーザーと共有できるよう調整されると、ユーザーは、gcloud コマンド、REST API、または Google Cloud Console の Dataflow UI を介して、必要なパラメータを直接渡しながらパイプラインを呼び出すことができます。ユーザーは、ランタイム環境をビルドして構成する必要がなくなります。また、Cloud Scheduler を使用すると、ランタイム環境を必要とせずに、パイプラインを簡単にトリガーして、定期的なスケジュールで実行することもできます。
フレックス テンプレートを使用した Dataflow パイプラインの共有
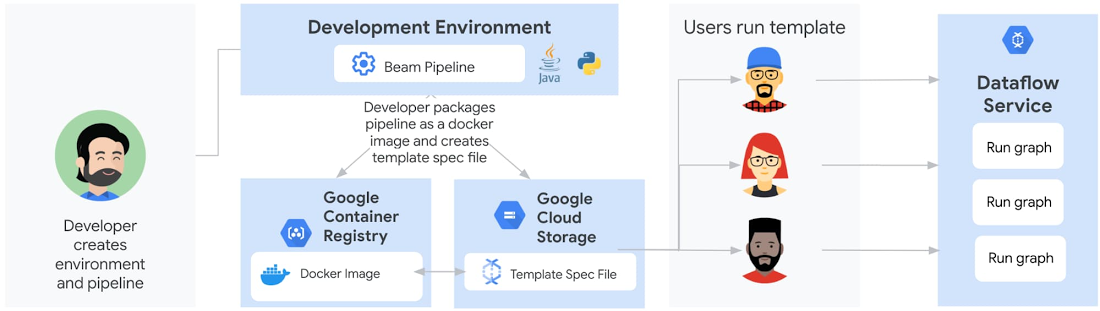
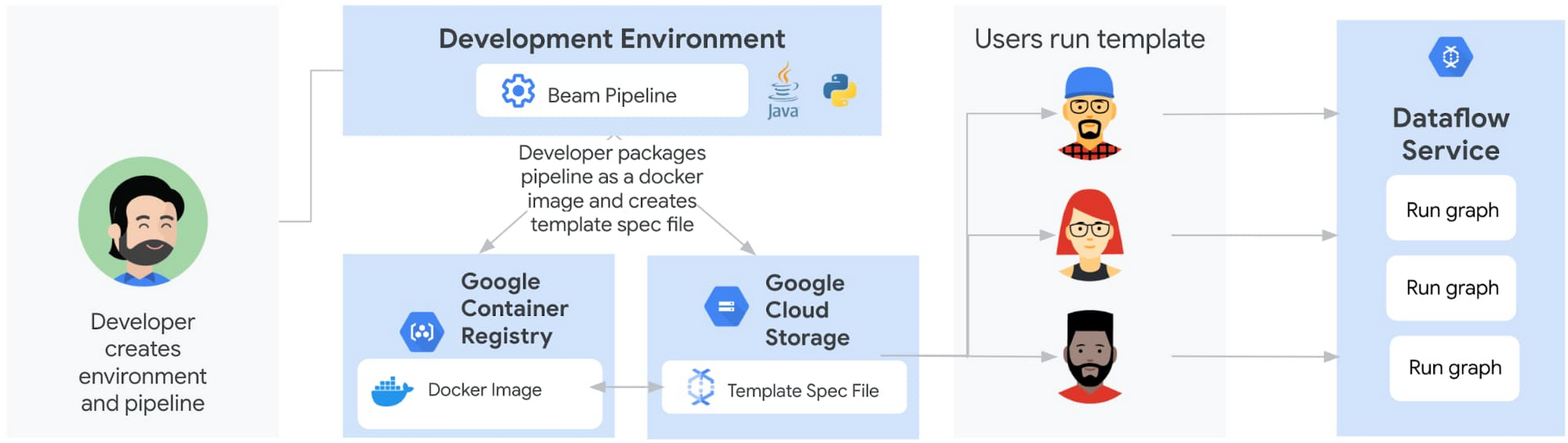
クラシック テンプレートと同様に、フレックス テンプレートを使用したステージングと実行は個別のステップです。ただし、ステージングされる実行可能なパイプライン アーティファクトは異なります。デベロッパーは、Cloud Storage でテンプレート ファイルをステージングするのではなく、Google Container Registry で Docker イメージをステージングできるようになりました。
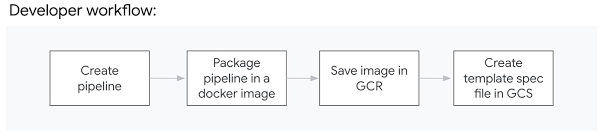
さらに、デベロッパーは、フレックス テンプレートを作成するためにパイプラインを実行する必要はありません。代わりに、デベロッパーは依存関係を含むパイプライン コード / バイナリを Docker イメージにパッケージ化し、Container Registry に保存してから、Cloud Storage に保存されるテンプレート仕様ファイルを作成します。
ステージングされたイメージは、Google が提供するベースイメージを使用してビルドされ、依存関係と環境変数のあるパイプライン アーティファクトが含まれています。
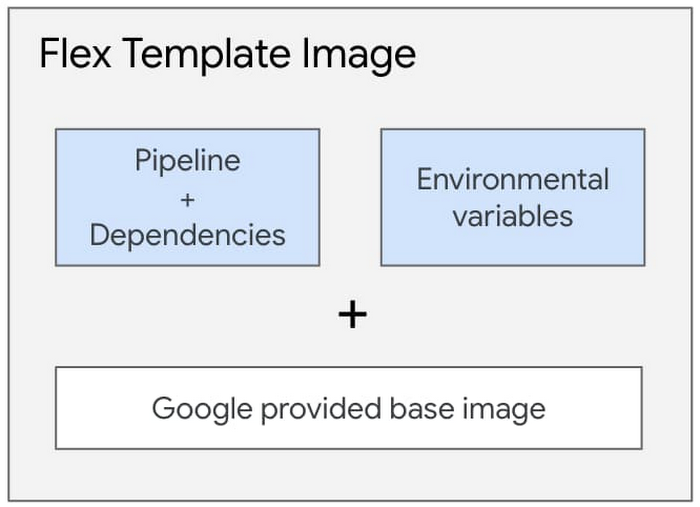
Docker イメージには、JSON シリアル化実行グラフは含まれていません。Java ベースのパイプラインの場合、イメージには JAR ファイルが含まれています。Python パイプラインの場合、イメージには Python コード自体が含まれています。ユーザーが実際にフレックス テンプレートを実行した場合にのみ、グラフ作成フェーズが新しいコンテナ内で開始され、実行グラフはユーザーが実行時に指定したパラメータに基づいて作成されます。これにより、ユーザーから渡される最終的な入力パラメータに基づいて実行グラフを動的に作成できます。
Cloud Storage 内のファイルはフレックス テンプレートではなく、テンプレート仕様ファイルです。この仕様ファイルには、Container Registry イメージの場所、SDK 言語、テンプレートの名前や説明などのメタデータ、テンプレートに必要な必須またはオプションのパラメータなど、ジョブを実行するために必要なすべての情報が含まれています。クラシック テンプレートと同様に、ユーザーが指定した入力パラメータを検証するために、正規表現を使用することもできます。
ユーザーは、gcloud コマンドを使用する、REST API を呼び出す、Cloud Storage に保存されたテンプレート仕様ファイルを参照する Google Cloud Console 内の Dataflow UI を使用して必要なパラメータを指定することで、フレックス テンプレートを実行できます。繰り返し実行されるジョブの自動化またはスケジュール設定は、Cloud Scheduler または Terraform を介して行うことができます(Airflow のサポートは開発中です)。
クラシック テンプレートとフレックス テンプレートの比較
次の表は、クラシック テンプレートとフレックス テンプレートの類似点と相違点をまとめたものです。

最初の Dataflow フレックス テンプレートを作成
Dataflow テンプレートを初めて使用する場合は、最小限の処理でシステム間のデータ移動を行えるように、Google Cloud 提供のテンプレートから始めることをおすすめします。これらは、Google Cloud Console の Dataflow UI から簡単に実行できる、本番環境品質のテンプレートです。
提供されたテンプレートに含まれていないタスクを自動化する場合は、フレックス テンプレートの使用ガイドをご覧ください。このチュートリアルでは、Pub/Sub から JSON エンコードのメッセージを読み取り、Beam SQL でメッセージ データを変換し、その結果を BigQuery テーブルに書き込むストリーミング パイプラインの例を確認できます。
また、Google が提供するテンプレートのソースコードを確認し、ランダムデータの生成、Cloud Storage でのデータ解凍、ツイートの分析、BigQuery に書き込む前のデータの難読化などのデータ拡充タスクの例を確認することもできます。
最後に、フレックス テンプレートをユーザーと共有する準備が整うと、Google Cloud Console UI にカスタム テンプレートを選択するオプションが表示され、次にその保存場所を尋ねられます。
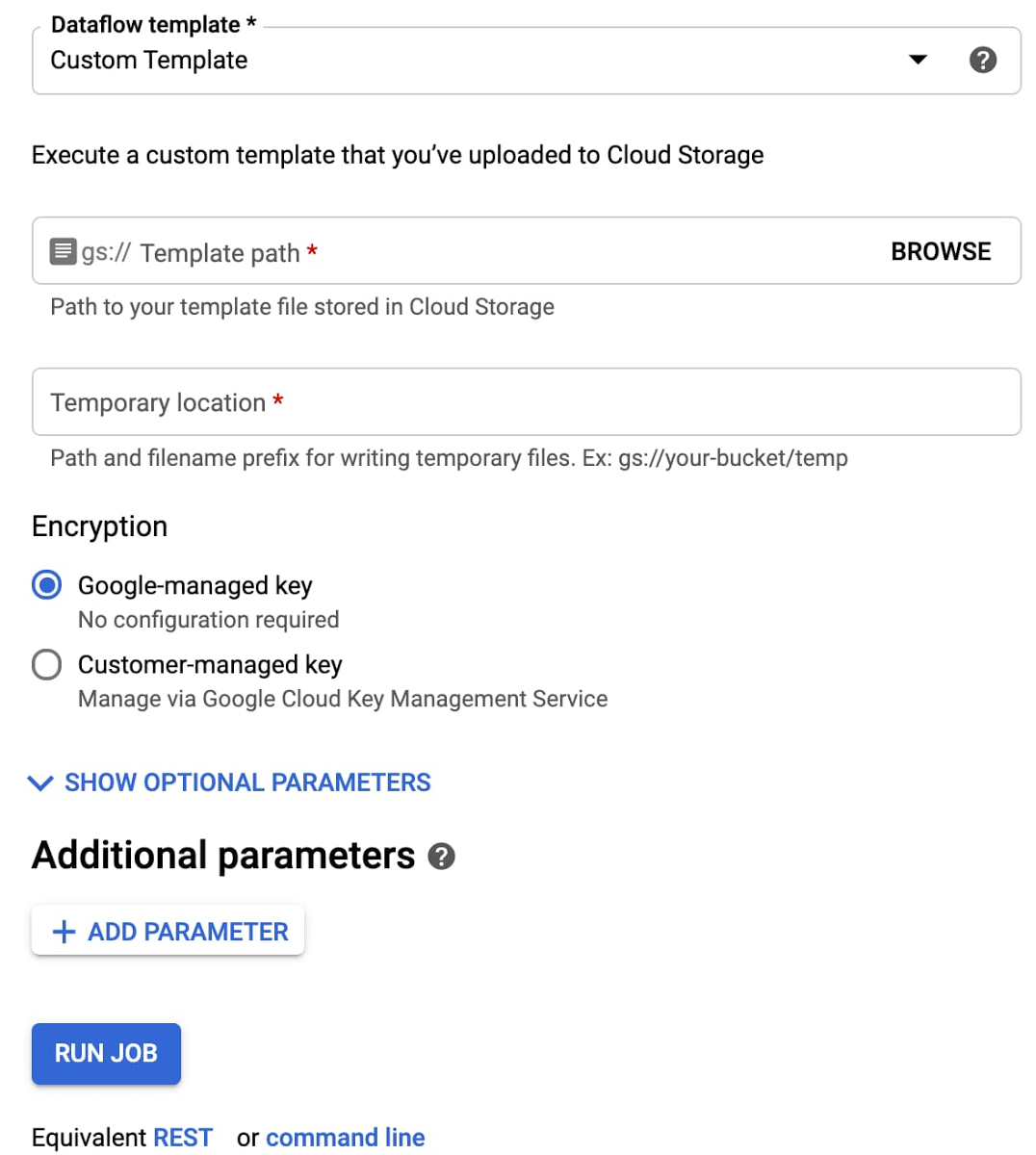
Google Cloud Console でのカスタム テンプレートの作成 (カスタム テンプレートを作成するための Google Cloud Console の Dataflow UI)
Google のサイトで Dataflow についての詳細を確認し、Beam Summit でフレックス テンプレートのプレゼンテーションをご覧ください。
Dataflow フレックス テンプレートの新しいリリースのデザインと開発に寄与してくれた、Mehran Nazir、Sameer Abhyankar、Yunqing Zhou、Arvind Ram Anantharam、Runpeng Chen、Dataflow チームのメンバーに感謝します(順不同)。
- Sameer Farooqui、Prathap Parvathareddy(ともに Cloud Data エンジニア)

{kind=link}
{kind=link}
{kind=link}
{kind=link}