Pre-built Cloud Dataflow templates: KISS for data movement
Anand Iyer
Group Product Manager, Google Cloud
Yunqing Zhou
Cloud Dataflow Software Engineer
Most tools that process data begin by moving data. Often this data movement is, simply put, boring: move data from from source A to destination B, with very minimal per-datum processing, so no joins, no group-bys, no aggregations. Accordingly, we decided to provide a solution that keeps the simple things simple. (In line with the perpetually guiding KISS principle.)
Having learned the need for simplicity from our own experiences and those of our customers, today we’re releasing an expanded set of pre-implemented Dataflow templates for point-to-point data movement. Simply select a template from the UI, provide a few basic parameters, and launch your data movement job. If you need to apply simple per-element filters or transforms, just embed some JavaScript, and you’re good to go.
Once you submit the Dataflow job, we take care of the rest: Dataflow is a fully managed serverless solution, so as a user, you incur no operational burden. No clusters to worry about, no scaling parameters to set. After a few clicks in a simple web interface your data is moved. As simple as that!
Typical usage patterns
These templates are commonly used for simple ingestion of data. However, they are also convenient for other use cases, such as to:- Periodically backup data for archival, e.g. from Cloud Pub/Sub, Cloud Spanner, or Cloud Datastore to Cloud Storage.
- Replicate or mirror data, e.g. from an online database (Cloud Datastore) to analytic systems like BigQuery.
- Take a snapshot for development, testing, or debugging purposes.
- Perform common bulk operations such as compress/decompress files on Google Cloud Storage.
An example: launch a Cloud Pub/Sub to a BigQuery pipeline
Problem statement and initial setupCompany A is collecting telemetry data from its mobile apps via Cloud Pub/Sub and would also like to use BigQuery to analyze its user activity in real time. Basically, the customer needs a pipeline to stream data from Cloud Pub/Sub to BigQuery continuously.
Launch the pipeline
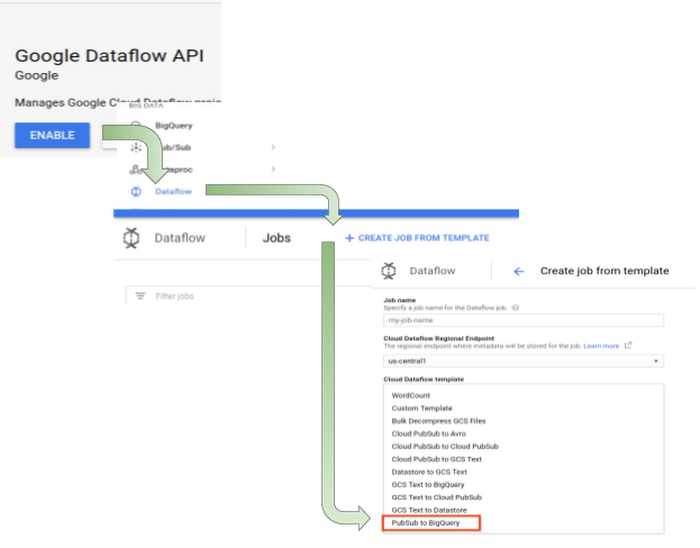
You can easily test out this pipeline using the Google-provided Dataflow template “Pub/Sub to BigQuery” by following these steps:
- Create the destination table which matches the input JSON messages from BigQuery UI.
- Activate Dataflow API.
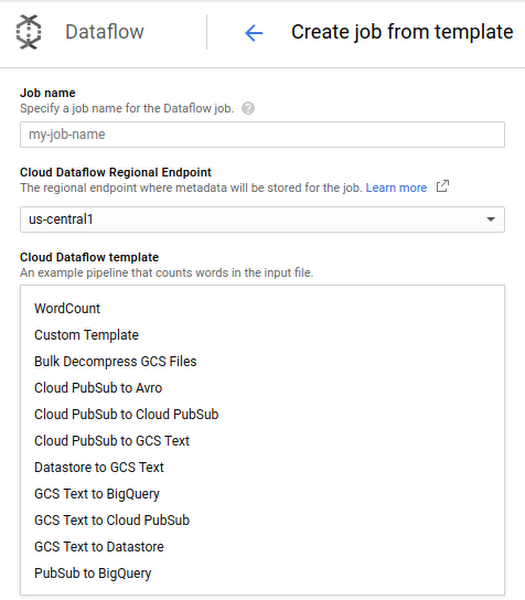
- Select “Create job from template” from Dataflow tab.
- Select Pub/Sub to BigQuery from the dropdown list.
- Complete the form and click “Run”.
Pick your template from the Dataflow UI:
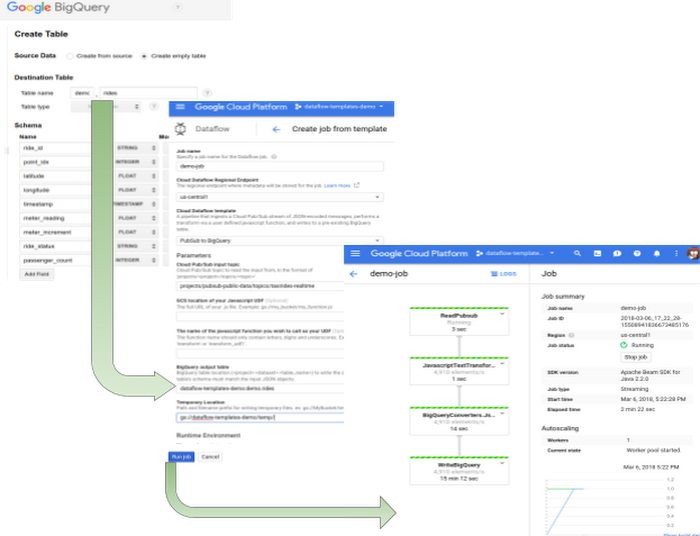
Fill in parameters, click ‘Run’ and view your job in the ‘Dataflow Monitoring Interface’
Transforming records by using UDFs
Sometimes incoming JSON records need to be transformed before they can be ingested into the final destination. Google provided templates enable this by allowing the user to specify a simple javascript snippet, as follows:
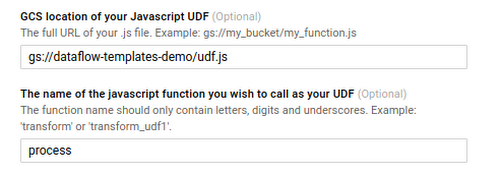
- Create a JavaScript file containing the transformation logic and save it on Google Cloud Storage. For example:
- Repeat the job launching process described in the last section. Specify udf information in the form like below and you’re ready to go:
Integrating with your own system
Besides launching jobs from the Cloud Console UI, a REST API is also available for easy integration with other systems. Here’s an example for launching the same job as above:
Please review the documentation for more details.
Open-source for easy customization
While building these templates, we received several requests to make the template code open-source. As a result, we’ve made these templates available on GitHub as examples of how to write a production-quality Beam template.The templates in this repository are the same ones we have made available in the Google Cloud Console. They represent best practices for template authoring and for interaction with data sources. We also encourage users to fork this repository for their own uses; many of these templates provide a good starting point for more advanced data movement use cases. We look forward to seeing what you create!



