Synthetic data generation with Dataflow data generator flex template
Prathap Kumar Parvathareddy
Staff Data Engineer
Generating synthetic data at a very high queries per second (QPS) is a challenging task that forces developers to build and launch multiple instances of a complex multi-threaded application. Having learned that this is a very common need which helps IT teams to validate system resilience during evaluations and migrations to new platforms, we decided to build a pipeline that eliminates the heavy lifting and makes synthetic data generation easier.
We are excited to announce the launch of a new Dataflow Flex template called Streaming Data Generator that is capable of publishing unlimited high-volume JSON messages to a Google Cloud Pub/Sub topic. In this blog post, we will briefly discuss the use cases and how to use the template.
Flex Templates
Before diving into the details of the Streaming Data Generator template’s functionality, let’s explore Dataflow templates at a very high level:
The primary goal of Dataflow templates is to package Dataflow pipelines in the form of reusable artifacts that can be run in various channels (UI / CLI / REST API) and be used by different teams. In the initial version of templates (called traditional templates), pipelines were staged on Google Cloud Storage and could be launched from the Google Cloud Console, the gcloud command-line tool or other cloud-native Google Cloud services such as Cloud Scheduler or Cloud Functions.
However, traditional templates have certain limitations:
Lack of support for Dynamic DAGs
Many I/Os don’t implement ValueProvider Interface, which is essential to supporting runtime parameters
Flex templates overcome these limitations. Flex templates package Dataflow pipeline code, including application dependencies, as Docker images and stage the images in Google Container Registry (GCR). Metadata specification files referencing the GCR image path and parameters details will be created and stored in Google Cloud Storage. Users can invoke a pipeline through a variety of channels (UI, gcloud, REST) by referring to the spec file. Behind the scenes, the Flex template launcher service runs Docker containers with parameters supplied by the user.

Streaming Data Generator Overview
The Streaming Data Generator template can be used to publish fake JSON messages based on a user-provided schema at a specified rate (measured in messages per second) to a Google Cloud Pub/Sub topic. The JSON Data Generator library used by the pipeline supports various faker functions that can be associated with a schema field. The pipeline supports configuration parameters to specify message schema, specify the number of messages published per second (i.e., QPS), enable auto scaling, and more. Pipeline steps are shown below:

The primary use case of the pipeline is to benchmark the consumption rate of Streaming pipelines and evaluate the resources (number of workers/machine types) required to meet the desired performance.
Launching the Pipeline
The pipeline can be launched either from the cloud console , gcloud command-line tool or REST API.
To launch from Cloud Console:
1. Go to the Dataflow page in the Cloud Console.
2. Click “Create Job From Template.”

3. Select “Streaming Data Generator” from the Dataflow template drop-down menu.
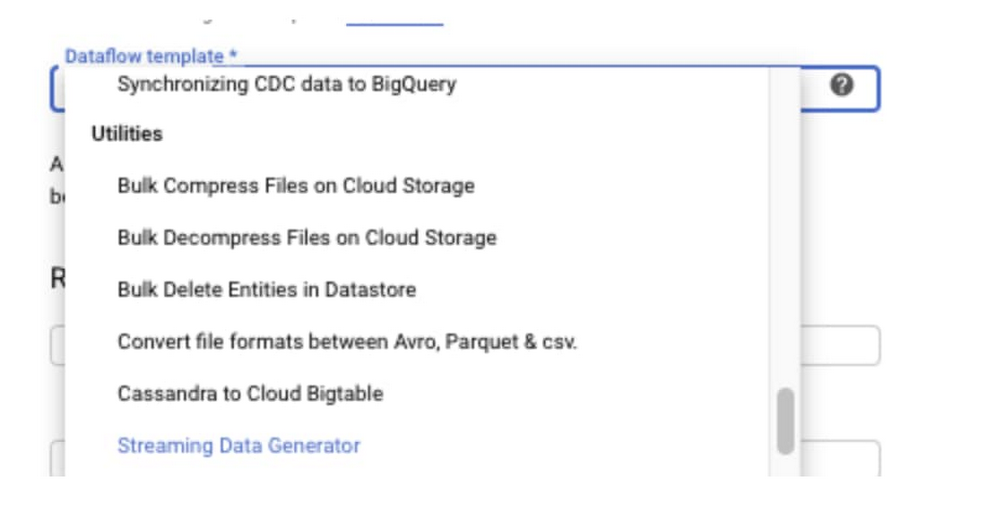
4. Enter the job name.
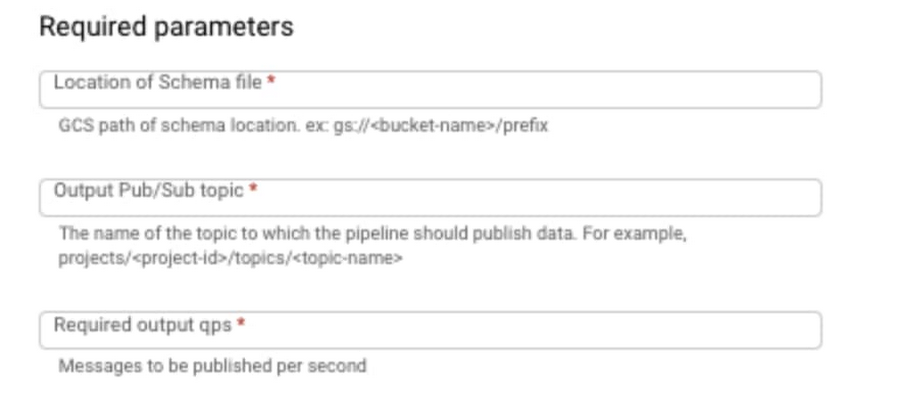
5. Enter required parameters as shown below:
6. Enter optional parameters such as autoscalingAlgorithm and maxNumWorkers, if required.
7. Click “Run Job.”
To launch using the gcloud command-line tool, enter the following:
To launch using REST API:
Next Steps
We hope the template combined with Dataflow’s serverless nature will enhance your productivity and make synthetic data generation much simpler. To learn more, you can read the documentation, check out the code or get started by running a template on Google Cloud. In addition to Utility templates, the Dataflow team provides a wide variety of Batch and Streaming templates for point-to-point data transfers covering popular data sources and destinations.

