データ エージェントと BigQuery プラットフォームの機能強化によって AI 構築を加速させる
Gerrit Kazmaier
VP & GM of Data Analytics, Google Cloud
Yasmeen Ahmad
Managing Director, Data Cloud, Google Cloud
※この投稿は米国時間 2024 年 10 月 10 日に、Google Cloud blog に投稿されたものの抄訳です。
AI によるイノベーションを推進するうえで、データの持つ役割は明白です。しかし、今日のデータの多くは構造化されておらず、管理もされていないため、データへのアクセス性が AI 導入の妨げとなる可能性があります。Google が目標としているのは、データをアクセス可能にすること、データをアクションにつなげられるようにすること、そして、データを企業が変革を成し遂げるための礎にすることです。本日 Google は、オープン スタンダードに基づくデータクラウドによってこれを実現可能にする新しい機能を提供します。このデータクラウドは、データを AI にリアルタイムで接続し、会話型データ エージェントによって生成 AI の限界を押し広げます。
リアルタイムでデータと連携するオープン エコシステム
今年 Google は、BigQuery をデータ ユースケースと AI ユースケース向けの単一のプラットフォームに統合し、そこにあらゆる形式や種類のデータ、複数のエンジン、ガバナンス、ML、ビジネス インテリジェンスを組み込む計画を発表しました。オープン フォーマットを扱うお客様をサポートするため、Apache Iceberg のマネージド エクスペリエンスの一般提供を開始したことを発表いたします。マルチモーダル データを容易に準備できるように、ドキュメント、音声、画像、動画などのさまざまな形式のデータを処理するための機能が追加されています。
Volkswagen は BigQuery を使用して、車両のオーナーズ マニュアル、顧客からのよくある質問、ヘルプセンターの記事、Volkswagen の公式 YouTube 動画などの複数のデータソースをグラウンディングに使用した AI モデルを構築しています。
「私たちは、Volkswagen のすべてのお客様のオーナー エクスペリエンスを向上させ、当社の車への愛着を育む新しいテクノロジーや機能を導入することに尽力しています。AI は、Volkswagen のオーナー様が愛車への理解を深め、疑問に対する答えをすばやく簡単に得るためのユーティリティ ツールとして浮上しています。」 - Volkswagen Group of America、CIO(最高情報責任者)、Abdallah Shanti 氏
新たなデータ取り込み方法をサポートするため、Flink および Kafka 向けの新しいマネージド サービスを発表します。これらのサービスは、リアルタイム ワークロードの取り込み、構成、チューニング、スケーリング、モニタリング、アップグレードに役立ちます。プレビュー版の BigQuery ワークフローを使用することで、データ エンジニアは統合プラットフォーム内でデータ パイプラインを構築し、それらを手動で、API を介して、またはスケジュールに従って実行できます。
最近のもう一つのイノベーションである BigQuery の継続的クエリは、リアルタイムのデータ分析だけにとどまらず、そこから得られた情報をリアルタイムでアクティベートできるようにします。従来、「リアルタイム」とは数分、あるいは数時間前のデータを分析することを意味していました。しかし、データの取り込みと分析の状況は急速に進化しています。生成されるデータ量、顧客エンゲージメント、意思決定、AI を活用した自動化が急増したことにより、意思決定を下すまでの猶予は大幅に短くなりました。分析情報の要求からアクティベーションまではシームレスでなければならず、もはや数分や数時間ではなく数秒単位でそれを可能にする必要があります。さらに、Analytics Hub データ マーケットプレイスも拡張され、リアルタイムのデータ共有が可能になりました(プレビュー版)。
お客様がログデータから有意義な分析情報を抽出できるようにするため、BigQuery パイプ構文を発表いたします。この機能は、ログを管理、分析し、そこから価値を引き出す方法を改善するよう設計されており、データチームはログデータの半構造化された性質に合わせて設計された SQL を使用して、より簡便な手法でデータ変換に取り組むことができます。
すべてのデータを AI に接続する
現在 BigQuery をご利用のお客様は、エンベディングを大規模に生成および検索することで、セマンティック最近傍探索、エンティティ解決、セマンティック検索、類似性検出、RAG、レコメンデーションなどの幅広いユースケースに対応できます。Vertex AI とのインテグレーションにより、テキスト、画像、動画、マルチモーダル データに加え、構造化データに対しても簡単にエンベディングを生成できます。一般提供が開始された LangChain と BigQuery のインテグレーションは、データの前処理、エンベディングの生成と保存、ベクトル検索の実行をより一層容易にする道を開きます。
ベクトル検索機能を強化するため、Google は ScaNN による大規模なクエリの検索を導入しています(プレビュー版)。これは、Google 検索や YouTube などの人気のある Google サービスで活用されているものと同じテクノロジーです。ScaNN インデックスは、最先端のクエリ パフォーマンスを維持しながら 10 億を超えるベクトルをサポートすることができ、あらゆる企業のために高スケールのワークロードを可能にします。
また、BigQuery DataFrames を使用すれば、使い慣れた Python API によってデータを簡単に処理できます。これには、ML モデルのトレーニングやシステムテストの代用となる合成データの生成が含まれます。この種の AI 実験を加速させるため、Google は BigQuery での合成データの生成に関して Gretel AI と提携しています。そのため、実際のデータによく似ているものの、機密情報が含まれないデータを使用できます。
きめ細かいガバナンスでデータを統合する
すでに何万もの組織が、BigQuery とその統合 AI 機能を使ってデータクラウドを運用しています。しかし、データドリブンな AI の時代においては、新しいデータタイプや増え続ける多様なワークロードを管理する必要があります。
たとえば Box Inc. は、数十億のファイルを処理し、世界中で数百万のユーザーにサービスを提供していますが、BigQuery とそのサーバーレス アーキテクチャのおかげで、苦もなく 1 秒間に数十万件のイベントを処理し、ペタバイト規模のストレージを管理しています。BigQuery を使用することにより、同社はきめ細かいアクセス制御を通じてセキュリティを強化し、機密データ フィールドを確実に特定、分類、保護できるようになりました。
データアクセスと AI のユースケースが増加するにつれて、データ マネジメントとガバナンスが最優先の課題となっています。データと AI アセットを統一された方法で探索できるようにするため、BigQuery の統合カタログの一般提供が開始されました。これにより、データソース、AI モデル、BI アセットを含むデータ資産全体からメタデータを自動的に収集して取り込み、インデックス付けできます。また、その種類や場所を問わず、すべてのデータアセットを簡単に探索してクエリできるように、BigQuery カタログ セマンティック検索も導入されました(プレビュー版)。自然言語で質問すると、BigQuery が質問の意図を理解して最も関連性の高い結果を返すため、探している答えがより簡単に見つかります。
Google は、お客様のユースケースとワークフローをサポートするため、さらに多くのサードパーティ データソースにアクセスできるよう継続的に取り組んでいます。たとえば、Equifax は最近 Google Cloud とのパートナーシップを拡大し、BigQuery を基盤とするデータ交換を使用して、ローンデータ、信用動向、商業マーケティング データなどの差別化された匿名のデータアセットを安全に提供しています。
「Equifax では、データが多いほどよりスマートな意思決定が可能になると考えています。差別化されたデータを Google Cloud で提供することにより、お客様は情報に基づく予測的な意思決定を行えるようになります。また、お客様が選んだ任意のチャネルでご要望に応えることにより、意思決定のスピードとアジリティも高まります。」 - Equifax、米国情報ソリューション担当プレジデント、Todd Horvath 氏
複数の実行エンジンからデータにアクセスできるようにするには、新しい BigQuery メタストアを使用します。来月からプレビュー版で提供されるこの機能を使用すると、構造化オブジェクト テーブルと非構造化オブジェクト テーブルの両方を含む単一のデータコピーに対して複数のエンジンを実行できるようになり、単一のビューからポリシーとパフォーマンスの管理やワークロード オーケストレーションを行うことができます。
また、Looker を使用した BI ユースケースにおいて、BigQuery の新しいガバナンス機能を使用することもできます。これを使用すれば、Looker に接続してメタデータを取り込むタスクにおいてフルマネージドなセルフサービス エクスペリエンスが得られます。独自のコネクタを設定、維持、運用する必要はありません。その代わりに、Looker インスタンスのカタログ メタデータを使用し、Looker ダッシュボード、データ探索、ディメンションを取得できます。
最後に、ビジネスの継続性を確保するため、BigQuery に障害復旧機能が追加されました。これにより、ビジネスクリティカルなワークロードに対して、サービスレベル契約(SLA)に基づくフェイルオーバーと冗長なコンピューティング容量が提供されます。これらの機能はデータに限定されるものではなく、BigQuery による分析ワークロードのフェイルオーバーもサポートされています。
Gemini による会話型データ エージェント
今や世界中の組織が、LLM を基盤とするデータ エージェントを構築し、それを社内タスクや顧客対応タスクの遂行、データアクセスの推進、新しいインサイトの獲得、行動の促進に活かしたいと考えています。その手助けとして、Google は新しい会話型 API セットの開発に取り組んでいます。これらの API を使用すると、独自のデータ エージェントを作成してセルフサービス方式のデータアクセスを向上させ、データを収益化して市場で自社製品を差別化できます。
会話分析
実際、私たちはこれらの API を利用して、Gemini in Looker で会話分析エクスペリエンスを構築しました。Looker のエンタープライズ規模のセマンティック レイヤで使用可能なビジネス ロジック モデルと組み合わせることで、これは AI のグラウンディングに使われるデータの信頼できる唯一の情報源となり、組織全体で一貫した指標を提供します。これにより、使い慣れた Google 検索のようなエクスペリエンスを使用して、自然言語でデータを探索できます。
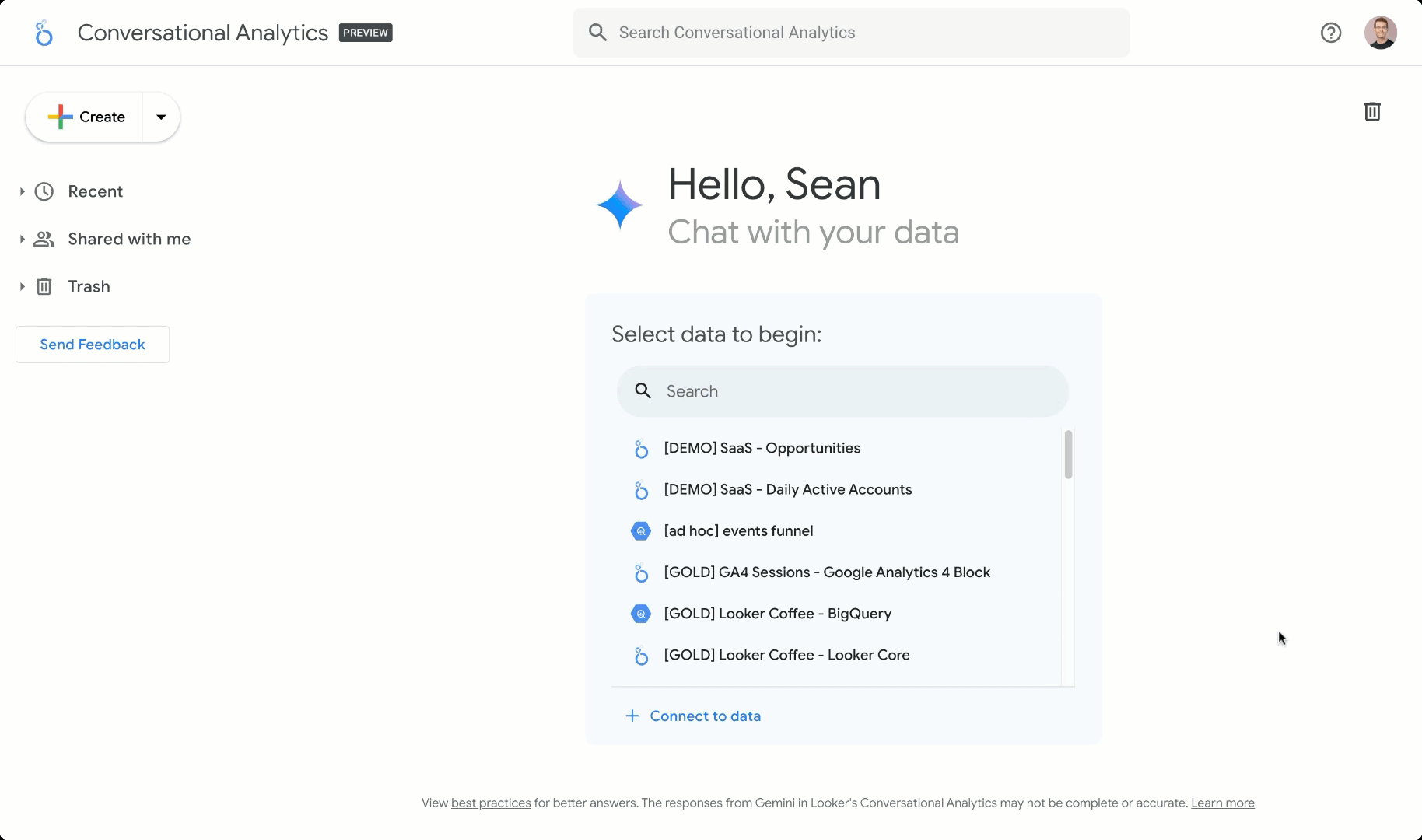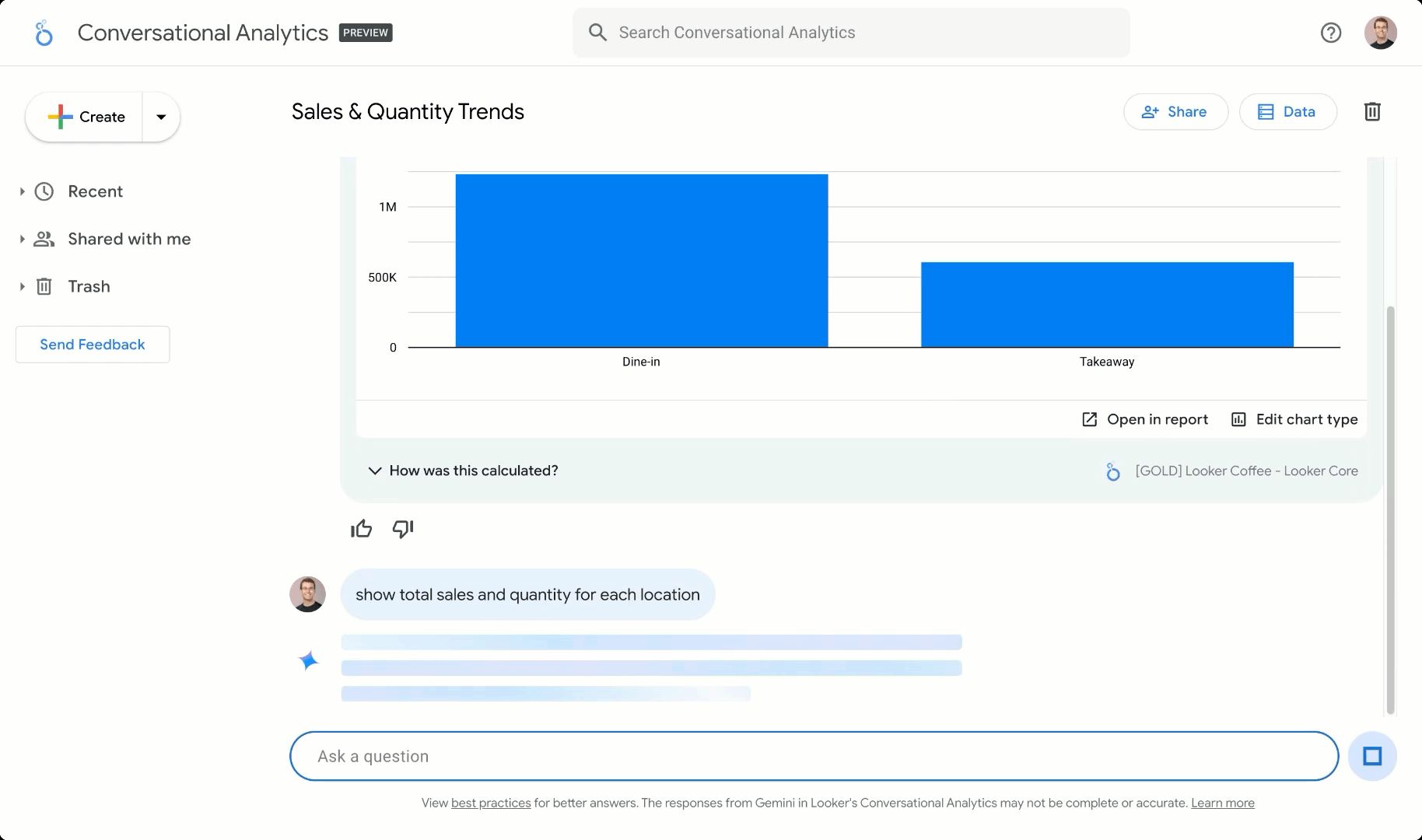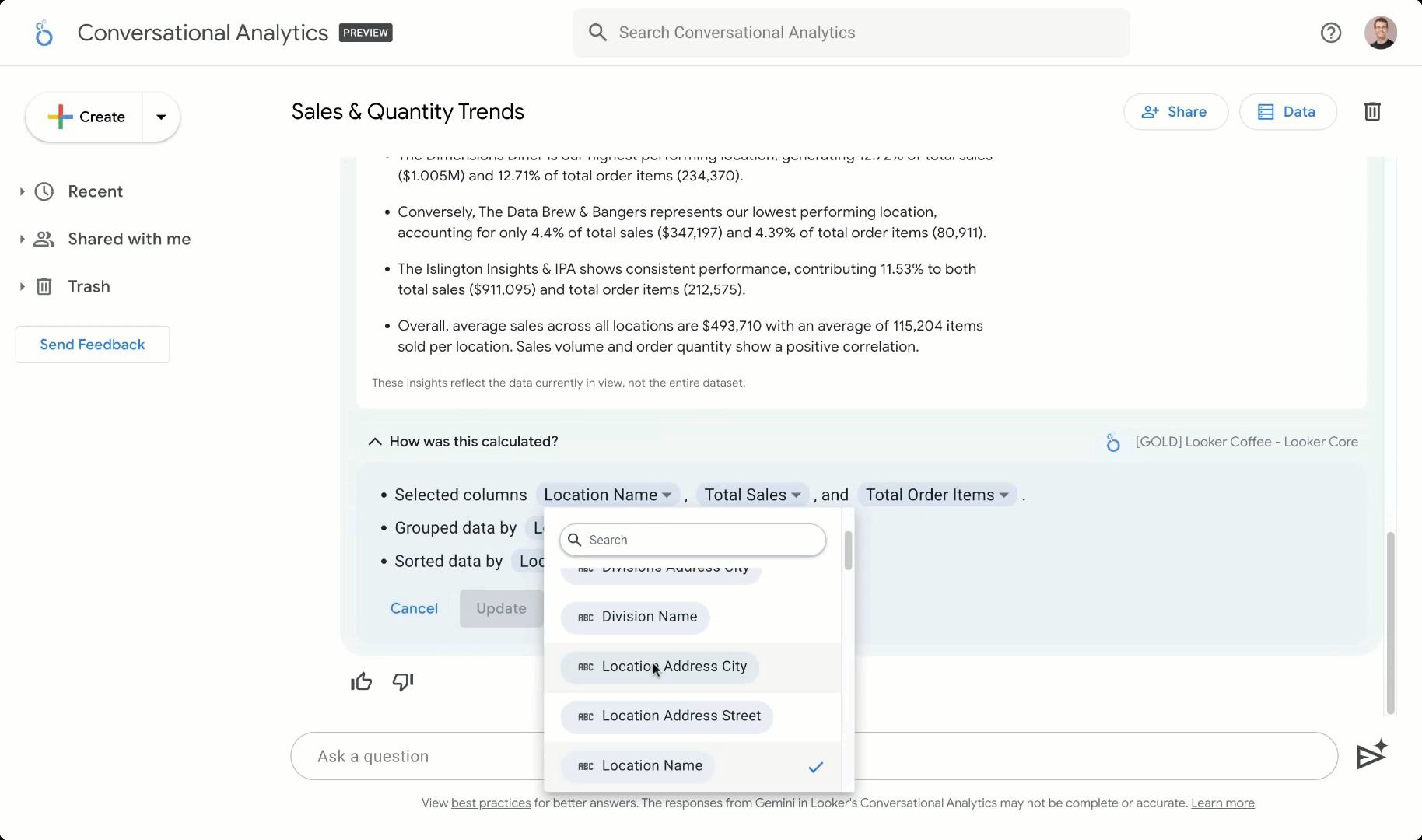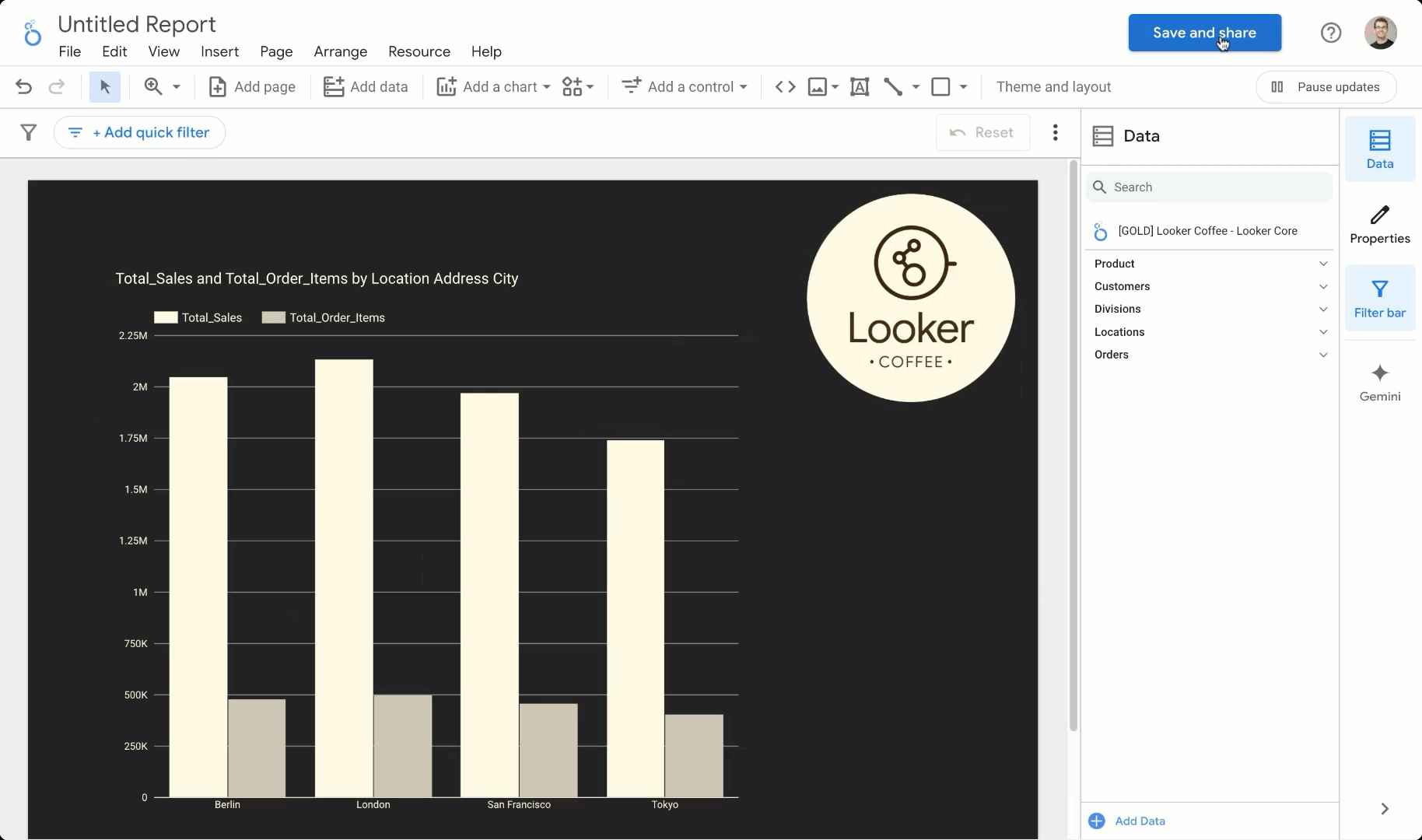
データ エージェントは LookML のセマンティック データ モデルを基に構築できるため、管理する指標やデータモデル間のセマンティック関係を定義できます。これらのモデルにはデータの記述が含まれているだけではありません。作成した LookML モデルをクエリしてデータに直接アクセスすることもできます。
内部的には、データ エージェントはデータの動的なナレッジグラフによって動作します。BigQuery を中核とするこの動的ナレッジグラフは、単純なセマンティクスを超えて、使用パターン、メタデータ、過去の傾向などを織り交ぜながらデータ、アクティビティ、関係性のネットワークを構築します。
最後に付け加えておくと、Gemini in BigQuery はすでに一般提供されており、データ移行、データ準備、コード支援、データ インサイトによってデータチームの生産性向上に貢献しています。今や、ビジネスチームや分析チームを含む企業のどの部門でも、データと対話して瞬時にインサイトを得ることができるため、データドリブンな意思決定の文化を社内に浸透させることができます。データ インサイトに関する新機能は、分析情報を即時に提供するすぐに実行可能なクエリによって当て推量の必要性を低減します。また、AI を活用したデータ準備機能は、BigQuery Studio でデータ パイプラインを構築するための自然言語インターフェースを提供します。
今こそ、すべてのデータを AI に接続するときです。データ移行プログラムを利用してデータを BigQuery に取り込むことから始めましょう。BigQuery プラットフォームの最新のイノベーションについて知りたい場合は、こちらのプロダクト ロードマップ ウェブキャストをご覧ください。これらのデータ分析のイノベーションをお客様のビジネスにどのようにお役立ていただけるか、皆様の事例を伺うのを楽しみにしています。
-Google Cloud、データ分析担当バイス プレジデント兼ゼネラル マネージャー、Gerrit Kazmaier
-データ分析担当マネージング ディレクター、Yasmeen Ahmad
