Splunk にデータをストリーミングする Dataflow テンプレートのご紹介
Google Cloud Japan Team
※この投稿は米国時間 2020 年 4 月 18 日に、Google Cloud blog に投稿されたものの抄訳です。
Google Cloud では、お客様が抱える問題を解決し、それぞれの状況に合わせてご支援を提供することに尽力しています。数多くの企業がオンプレミスとクラウドの両方の環境の管理に Splunk のサードパーティ モニタリング ソリューションを使用しています。これを使用したユースケースには、IT 運用、セキュリティ、アプリケーション開発、ビジネス分析などが挙げられます。
このブログ投稿では、最近リリースされた Pub/Sub to Splunk Dataflow テンプレートを使用して、Google Cloud のデータを Splunk Cloud または Splunk Enterprise のインスタンスにネイティブに push するストリーミング パイプラインを設定する方法をご紹介します。この Dataflow テンプレートを使用すると、データを Pub/Sub から Splunk にエクスポートできます。つまり、Pub/Sub トピックに配信可能なあらゆるメッセージが Splunk に転送できるというわけです。転送の対象には、Cloud Logging(旧称 Stackdriver Logging)からのログ、IoT デバイスからのメッセージ、Cloud Security Command Center からのセキュリティ検出結果などのイベントが含まれます。このテンプレートを活用することで、お客様は GCP から提供される有益なデータの多様な種類、速度、量に対応できます。Spotify 社のセキュリティ エンジニアである Andy Gu 氏は、次のように述べています。「Google Cloud の Pub/Sub to Splunk Dataflow テンプレートのおかげで、Spotify Security チームは多種多様なログタイプを Splunk に取り込めるようになりました。その結果、Google の Pub/Sub モデルと Splunk のクエリ機能の両方を活用し、検出と応答のインフラストラクチャを簡素化して毎日 800 万件を超えるイベントを処理しています。」
これから説明する詳細なチュートリアルでは、Cloud Logging の送信元ログシンクの構成から最終的な Splunk の送信先である Splunk HTTP Event Collector(HEC)エンドポイントまでを包括的にカバーした全体の設定について取り上げます。
データのストリーミングとデータのポーリング
Splunk ユーザーはもともと、データ コレクターとして Google Cloud Platform の Splunk アドオンを使用して Google Cloud からログを pull するためのオプションを使用できます。具体的には、このアドオンはログシンクのエクスポートとして構成されている Pub/Sub トピックからログを定期的に pull する Splunk のモジュラー入力を実行するものです。このソリューションは確実にうまく機能するものの、以下のような考慮すべきデメリットもあります。
ログ容量を増やして高可用性とスケールアウトを実現するには、より運用が複雑な 1 つ以上のデータ コレクター(別名 Splunk Heavy Forwarder)を管理する必要がある。
Google Cloud への外部リソース アクセス権限が必要となり、サブスクリプションを作成して Pub/Sub トピックからデータを pull するための権限を上述のデータ コレクターに付与しなければならない。
「データ コレクターの仲介デバイスの管理が不要で、Splunk HTTP(S) エンドポイント(Splunk HEC)にログを直接ストリーミングする、よりクラウド ネイティブなアプローチが必要である」という声がお客様から寄せられていました。そのご要望にお応えしたのが、マネージド Cloud Dataflow サービスです。Dataflow ジョブは Pub/Sub トピックから自動的にログを pull し、ペイロードを解析して Splunk HEC のイベント形式に変換します。変換されたデータは、その後 Splunk HEC に転送されます。この設定を効率よく進めるために、Google では、指数バックオフでの再試行(ネットワーク障害の復元力、または Splunk がダウンした場合のため)、バッチ処理イベントや並列処理リクエスト(スループットを高めるため)などの組み込み機能を備えた Pub/Sub to Splunk Dataflow テンプレートをリリースしました。以下では、その詳細について説明します。
Splunk へのロギング エクスポートを設定する
エンドツーエンドのロギング エクスポートは以下のとおりです。
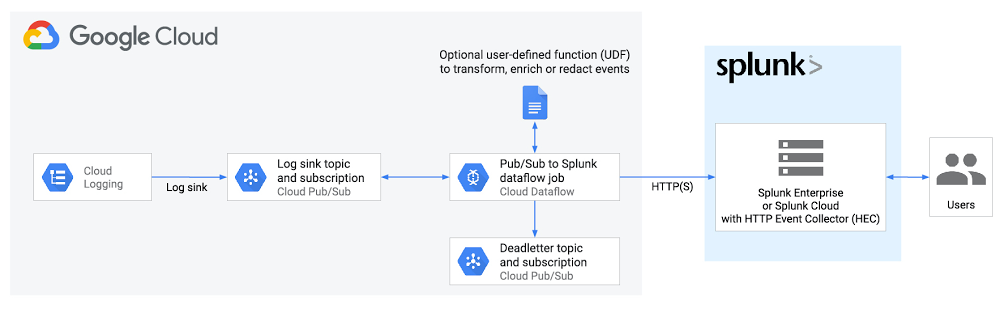
以下の手順について確認していきます。
Pub/Sub トピックとサブスクリプションを設定する
ログシンクを設定する
Pub/Sub トピックに IAM ポリシーを設定する
Splunk HEC エンドポイントを設定する
Pub/Sub を設定して Splunk Dataflow テンプレートにデプロイする
Pub/Sub トピックとサブスクリプションを設定する
まず、エクスポートされたログを受け取る Pub/Sub トピックと、Dataflow ジョブが後でログを pull する Pub/Sub サブスクリプションを設定します。この設定は、Cloud Console を使用しても、CLI で gcloud を使用しても行えます。gcloud を使用した例は次のようになります。
注: 先にサブスクリプションを作成してから Cloud Logging シンクを設定することが重要です。こうすることで、サブスクリプションを作成する前にトピックに追加されたデータが失われるのを回避できます。
Cloud Logging シンクを設定する
前の手順で作成した Pub/Sub トピックを送信先としてログシンクを作成します。この操作もログビューアまたは CLI の gcloud logging で行えます。たとえば、現在の Google Cloud プロジェクトのログをすべて取得するには、次のコードを使用します([MY_PROJECT] を置き換えます)。
注: デプロイする Dataflow パイプライン自体が Splunk に push されるログを Cloud Monitoring で生成し、さらなるログを生成して指数サイクルを作り出します。そのため、上記のログフィルタは「pubsub2splunk」(後ほど使用する Dataflow ジョブの任意の名前)というジョブからのログを明示的に除外します。このサイクルを回避するもう 1 つの方法は、ロギング エクスポートを別の専用「ロギング」プロジェクトで設定することです。一般的には、これがベスト プラクティスといえるでしょう。
上記の log-filter パラメータ値として使用されるリソースまたはサービス固有のログについては、サンプルクエリをご覧ください。同様に、権限を持っている場合、Google Cloud 組織のすべてのプロジェクトまたはフォルダからログをエクスポートする「gcloud logging sink」コマンドの例については、集約エクスポートをご覧ください。たとえば、すべてのプロジェクトのクラウド監査ログを 1 つの Pub/Sub トピックにエクスポートし、後で Splunk に転送するように選択することもできます。
この最後のコマンドの出力は次のようになります。
返されたサービス アカウント [LOG_SINK_SERVICE_ACCOUNT] をメモしておきます。
通常、末尾は @gcp-sa-logging.iam.gserviceaccount.com です。
Pub/Sub トピックに IAM ポリシーを設定する
シンクのエクスポートを機能させるには、返されたシンクのサービス アカウントに Cloud IAM ロールを付与する必要があります。これにより、Pub/Sub トピックへのログの公開権限が与えられます。
Cloud Console を使用してログシンクを作成した場合、エクスポート先を所有していれば、新しいサービス アカウントにエクスポート先への書き込み権限が自動的に付与されます。この場合、Pub/Sub トピックの my-logs です。
Splunk HEC エンドポイントを設定する
まだ Splunk HEC エンドポイントがない場合は、Splunk HEC の構成方法に関する Splunk のドキュメントをご覧ください。マネージド Splunk Cloud サービスと Splunk Enterprise インスタンスのどちらを選んでもかまいません。新しく作成された HEC トークンは後ほど使用しますのでメモしておきます。
注: 高可用性の確保と大量のトラフィックによるスケーリングについては、HTTP(S) ロードバランサの前にある複数の HEC ノードに負荷を分散してスケールする方法に関する Splunk のドキュメントをご覧ください。
Pub/Sub to Splunk Dataflow テンプレートを実行する
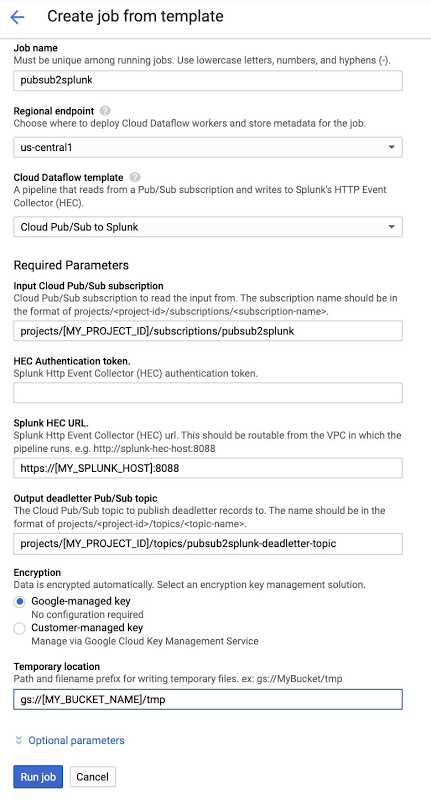
UI、gcloud、または REST API 呼び出しを使用して、Pub/Sub から Splunk へのパイプラインを実行できます(詳細についてはこちらをご覧ください)。以下は、「Cloud Pub/Sub to Splunk」テンプレートを選択した後にコンソールで入力されたフォームの例です。ジョブ名「pubsub2splunk」は前述のログフィルタで使用されている名前と同じで、この特定の Dataflow ジョブからログを除外します。[オプション パラメータ] をクリックすると、フォームが展開されてより多くのパラメータが表示されます。イベントを変換(次のセクションで説明)するためのユーザー定義関数(UDF)を追加したり、並列リクエストの数やリクエストごとのバッチ処理イベントの数を構成したりするなどのパイプラインのカスタマイズが可能です。スケーリングやサイジングに関連するパラメータの詳細については、以下のベスト プラクティスをご覧ください。パラメータ設定が完了したら [ジョブを実行] をクリックして、継続的なストリーミング パイプラインをデプロイします。
イベントを変換する UDF 関数を追加する(オプション)
前述のように、Splunk への送信前に、イベントを変換する JavaScript UDF 関数を指定することもできます。他のフィールドでイベントデータを拡充する場合、フィールド値を正規化または匿名化する場合、イベント単位で index、source、sourcetype などのイベント メタデータを動的に設定する場合などに特に役立ちます。
以下に示すのは JavaScript UDF 関数の例です。送信元の Pub/Sub サブスクリプション(ここでは pubsub2splunk)を追跡する新しいフィールド inputSubscription を追加します。また、プログラムにより、着信ログエントリの logName の値をイベントの source に設定し、着信ログエントリに応じてペイロードまたはリソースの種類をイベントの sourcetype に設定します。UDF を使用するには、前のステップで [ジョブを実行] をクリックする前に、UDF を Cloud Storage バケットにアップロードしてテンプレート パラメータで指定する必要があります。上記のサンプルコードを my-udf.js という名前の新しいファイルにコピーし、次のコードを使用して Cloud Storage バケットにアップロードします([MY_BUCKET] を置き換えます)。
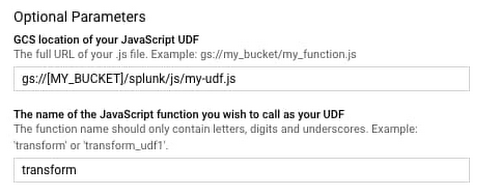
Dataflow コンソールのテンプレート フォームに戻り、[オプション パラメータ] をクリック
して展開し、次のように 2 つの UDF パラメータを指定します。
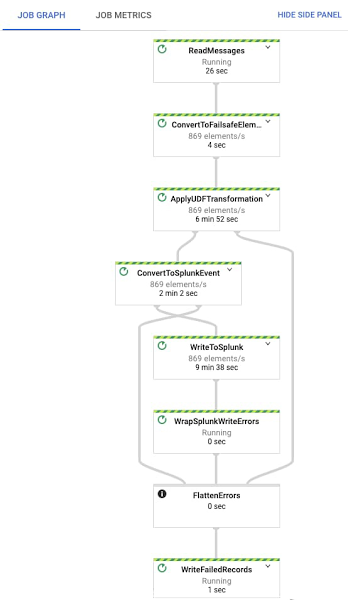
[ジョブを実行] をクリックすると、パイプラインは数分以内に Splunk へのイベントのストリーミングを開始します。Dataflow ジョブをクリックして [ジョブグラフ] タブを選択すると、正確なオペレーションを視覚的に確認できます。以下のように表示されます。Google Cloud でのテスト プロジェクトでは、UDF 関数(ApplyUDFTransformation ステップ)を適用して要素を Splunk HEC イベント形式(ConvertToSplunkEvent ステップ)に変換した後、Dataflow ステップ WriteToSplunk が 1 秒あたり 1,000 要素よりわずかに少ない要素を Splunk HEC に送信します。 パイプラインで発生する問題を確実に把握できるように、Cloud Monitoring アラートを設定することをおすすめします。これを使用すると、入力 Pub/Sub サブスクリプション内の最も古い「確認応答されていない」または未処理のメッセージが 10 分を超えた場合にアラートを起動できます。この指標のグラフにアクセスする簡単な方法については、Pub/Sub の Cloud Console UI の Pub/Sub サブスクリプションの詳細ページをご覧ください。
Splunk でログを表示する
すべての GCP ログやイベントを、Splunk Enterprise または Splunk Cloud の検索インターフェースから検索できるようになりました。Splunk HEC トークンの構成時には、設定したインデックスを必ず使用してください(ここではインデックス「test」を使用しました)。以下は、モニタリング対象リソースのタイプごとのイベント数を可視化する基本的な検索の例です。
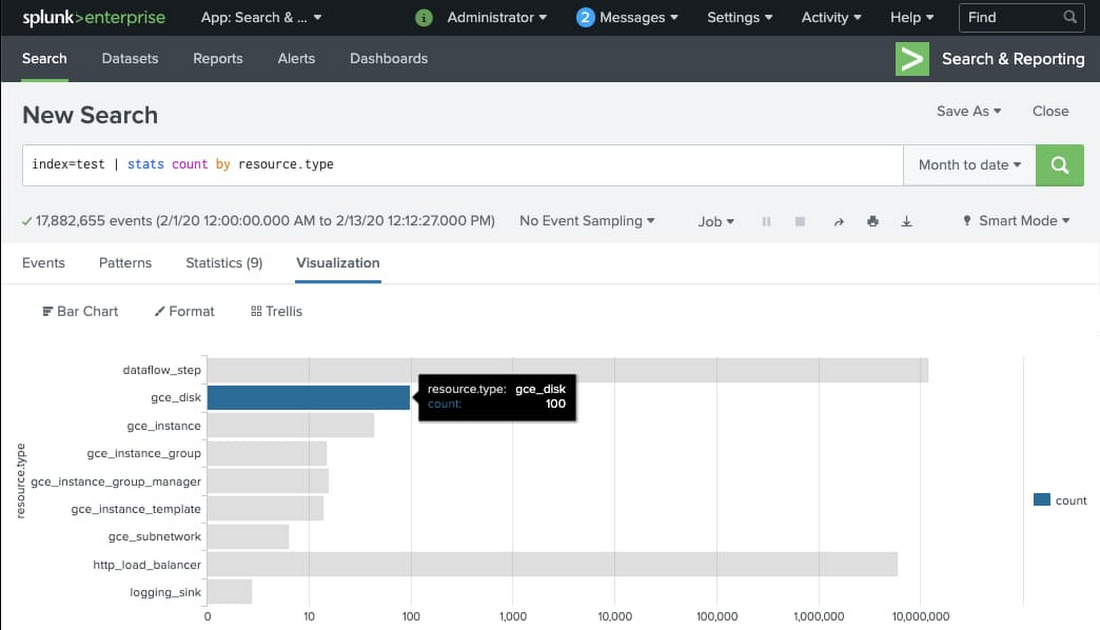
Splunk Dataflow テンプレートの使用のヒント
Splunk イベント メタデータの入力
Splunk HEC では、Splunk のデータのフィルタリングと可視化に使用できるいくつかのメタデータ フィールドでイベントデータを拡張できます。前述のように、Pub/Sub から Splunk Dataflow へのパイプラインでは、JavaScript で記述されたオプションの UDF 関数を使って、これらのメタデータ フィールドを設定することが可能です。
イベントデータを追加のメタデータで拡張するために、ユーザー指定の UDF は、イベント ペイロードで「_metadata」キーによってタグ付けされた JSON オブジェクトをネストできます。この _metadata オブジェクトには、パイプラインによって自動的に抽出、入力される Splunk メタデータのサポート対象のフィールド(以下の表を参照)を含めることができます。パイプラインは、Splunk に送信されたイベントデータから「_metadata」フィールドを削除することもできます。これは、イベント ペイロードとイベント メタデータ間のデータの重複を避けるためです。
現時点では、次のメタデータ フィールドが抽出に対応しています
(詳細については、Splunk HEC メタデータをご覧ください)。
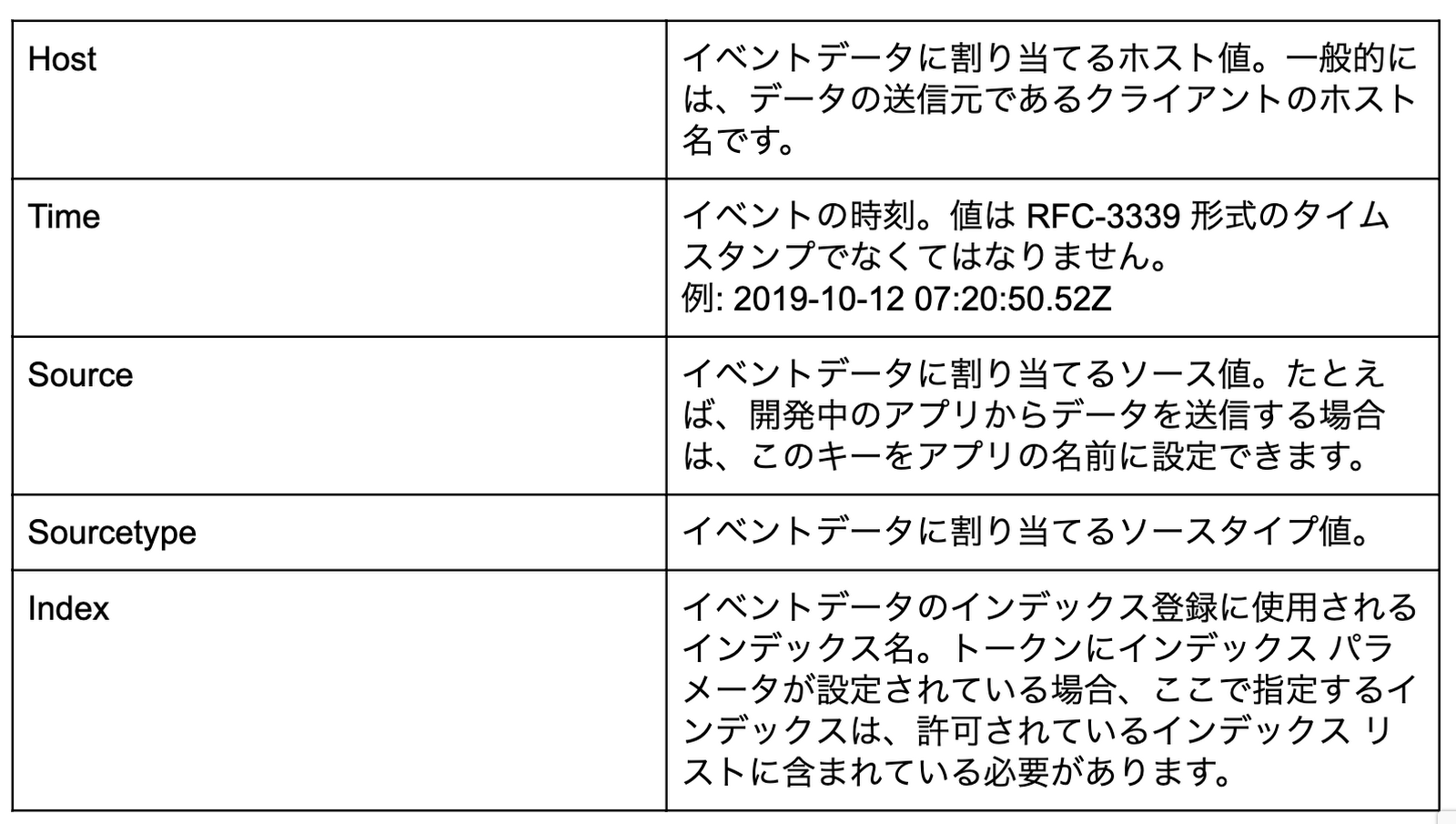
注: 「Time」行では、データ ペイロードに「timestamp」という名前のフィールドがある場合、パイプラインがイベントデータからの時刻メタデータの抽出を試みます。これは、Cloud Logging の LogEntry ペイロード形式からの時刻値の抽出を簡単にするためです。「_metadata」オブジェクトに表示される時刻値は、「timestamp」フィールドから抽出された値を常にオーバーライドするので注意してください。
バッチ処理による Splunk HEC への書き込み
Pub/Sub から Splunk へのパイプラインでは、複数のイベントをまとめて 1 つのリクエストにすることができます。こうすることでスループットが改善し、Splunk HEC エンドポイントへの書き込みリクエストの数を減らせます。バッチ処理のデフォルト設定は 1(バッチ処理なし)です。この値は、batchCount に 1 よりも大きな値を指定することで変更できます。
スループットとレイテンシのバランスに関する注意事項: バッチ処理で問題になるのは、バッチ処理で Splunk に転送される前にメモリ内のキューに格納される個々のメッセージのわずかなレイテンシです。パイプラインは、イベントが Splunk に push される前にパイプラインに留まる時間の上限(2 秒)を適用しようとします。これは、ユーザーが非常に高い batchCount を提供した場合に、そのレイテンシを最小限に抑え、イベントがパイプラインで長時間待機するのを防ぐためです。個々のイベントに追加のレイテンシが容認されないユースケースでは、バッチ処理を無効にする必要があります(デフォルト設定)。
書き込み並列処理の増加
Pub/Sub から Splunk へのパイプラインでは、Splunk HEC エンドポイントに対して行われる並列リクエストの数を増やすことができます。デフォルト設定は 1(並列処理なし)です。この値は、並列処理に 1 よりも大きな値を指定することで変更できます。並列処理の増加により Splunk HEC エンドポイントに送信されるリクエストの数が増加し、HEC ダウンストリームのスケーリングが必要になる場合があるので注意してください。
SSL 証明書の検証
Splunk HEC エンドポイントで SSL が有効(推奨)であるものの自己署名証明書を使用している場合には、証明書の検証を無効にできます。デフォルト設定では、SSL 証明書の検証が行われます。この値は、disableCertificateValidation の設定を true にすることで変更できます。
自動スケーリングと並列処理
並列処理の設定に加え、Pub/Sub から Splunk へのパイプラインでは最大 20 ワーカー(デフォルト)での自動スケーリングを有効にします。gcloud CLI からパイプラインを実行する場合、ユーザーは UI または --max-workers フラグを使用してこの値をオーバーライドできます。並列リクエスト数(並列処理)は、最大ワーカー数を超えないようにすることをおすすめします。
次のステップ
最新の参考資料についてユーザー ドキュメントを参照し、Pub/Sub to Splunk Dataflow テンプレートの使用を開始してみましょう。フィードバックや機能のリクエストがありましたら、ぜひお知らせください。関連する GitHub リポジトリで直接問題を作成する、Cloud Console から直接サポートケースを作成する、Stack Overflow フォーラムで質問することなどが可能です。
GCP で Splunk Enterprise を使用するには、数分で Google Cloud にクラスタをデプロイできるオープンソースの Terraform スクリプトをお試しください。デフォルトでは、新しくデプロイされた Splunk Enterprise インデクサ クラスタは複数のゾーンに分散されます。これは、事前構成されていて、Splunk TCP と HEC の両方の入力を介してデータを取り込めるよう準備されています。Terraform 出力は Dataflow ジョブの作成時にすぐに使用できる HEC トークンを返します。一般的なデプロイメントのガイドラインについては、GCP での Splunk Enterprise のデプロイをご覧ください。
-By ソリューション アーキテクト Roy Arsan、戦略的クラウド エンジニア Sameer Abhyankar


