BigQuery の高度なテキスト アナライザと前処理関数
Google Cloud Japan Team
※この投稿は米国時間 2023 年 11 月 11 日に、Google Cloud blog に投稿されたものの抄訳です。
BigQuery は、顧客情報や事業運営に関する情報を含め、大量の非構造化テキストデータと構造化テキストデータを保存します。BigQuery の検索機能と ML 機能を通じて、こうしたテキスト データセットから価値あるビジネス分析情報を抽出する優れた分析ツールが提供されています。
テキストの前処理は、生の自然言語や非構造化テキストを機械で扱いやすい形式に変換するため、テキスト分析や情報検索パイプラインの重要なステップであり、全文検索インデックス登録や ML パイプラインなど、多くのテキストベース オペレーションの前提条件となっています。テキスト検索インデックスの有効性は多くの場合、選択したトークン化アルゴリズムの品質に大きく影響されます。同様に、ML モデルのパフォーマンスは、前処理された入力の品質に大きく依存します。
Google は本日、BigQuery での一連のテキスト分析と前処理関数および機能の公開プレビュー版を発表します。こうした新機能は、プリミティブ文字列関数に加えてテキスト処理の不可欠な要素となり、BigQuery での検索と ML のユーザー エクスペリエンスをさらに向上させます。
アナライザでテキスト検索を強化する
不正行為の調査のシナリオ
架空の不正行為の調査と予防を行うシナリオを考えてみましょう。調査では、報告されたトランザクションに関連する疑わしいアクティビティを特定するために、ビジネス ログ データを検索することが役に立ちます。このプロセスには、日常的な業務で生成されたログテーブルから、関連する顧客情報を含むエントリを検索することが含まれます。
以下の情報が対象になります。
- 顧客 ID
- アクセス IP アドレス
- メールアドレス
- クレジット カード番号の下 4 桁
新しく追加された効果的な PATTERN_ANALYZER とその構成可能性により、上記の特定の情報を検索する際に役立つ検索インデックスを作成できます。
検索インデックス構成の作成
検索インデックスで PATTERN_ANALYZER を使用すると、指定した RE2 正規表現に一致する情報を抽出してインデックス登録できます。この場合、正規表現は次のような形式になります(パターン全体をまとめてキャプチャするため、キャプチャしないグループを「?:」で表している点に注意してください)。
(?:<customer_uuid>)|(?:<ip_address>)|(?:<email_address>)|(?:<credit_card_4_digits_number>)
上記の各コンポーネントに考えられる正規表現の例は次のとおりです。
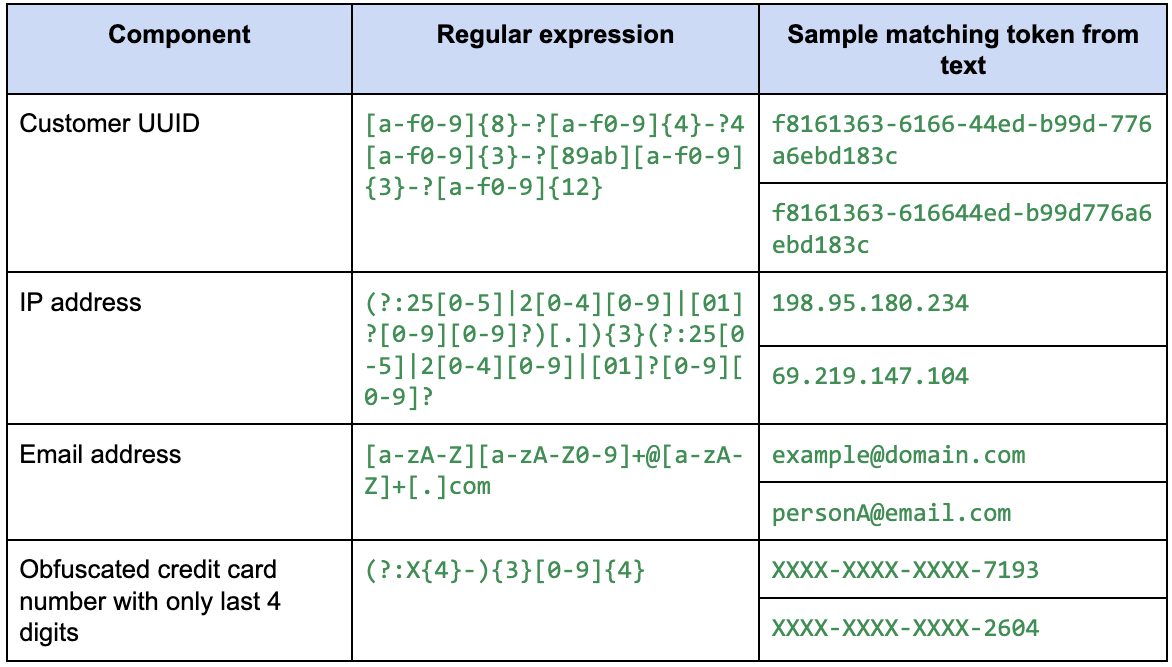
以上をまとめると、正規表現は次のようになります。
(?:[a-f0-9]{8}-?[a-f0-9]{4}-?4[a-f0-9]{3}-?[89ab][a-f0-9]{3}-?[a-f0-9]{12})|(?:(?:25[0-5]|2[0-4][0-9]|[01]?[0-9][0-9]?)[.]){3}(?:25[0-5]|2[0-4][0-9]|[01]?[0-9][0-9]?)|(?:[a-zA-Z][a-zA-Z0-9]+@[a-zA-Z]+[.]com)|(?:(?:X{4}-){3}[0-9]{4})
次に、キャプチャしたトークンにさらに手を加えて、検索インデックスの有効性と検索のユーザビリティを向上させることができます。
- テキストを小文字に変換して、大文字と小文字を区別しない検索ができるようにする
- 信頼性の高いシステム ロボットやテストのメールアドレスなど、既知のメールアドレスを削除する
- localhost のような、固定または既知の IP アドレスを削除する
これを行うには、アナライザのトークン フィルタ オプションを使用できます。

さまざまな構成でテストする
時間も費用もかかりがちな検索インデックスの作成プロセスに入る前に、新しく追加された TEXT_ANALYZE 関数を使用して、さまざまな構成でテストし、意図したとおりに機能するものを見つけましょう。以下に、構成をテストするクエリの例を示します。
この例では同じアナライザ オプションを使用するため、CUSTOM_OPTIONS という変数を宣言し、複数のクエリで再利用できるようにします。
注: この例では、説明のためにストップワードのリストを 2 つに分けています。実際に、リストを一つにまとめると検索を迅速に行うことができます。
例 1: UUID と IP アドレスの両方を含むテキスト
結果:

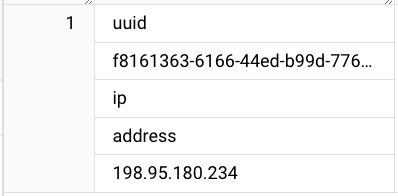
例 2: 複数のメールアドレスと難読化されたクレジット カード番号を含むテキスト
結果:

ユースケースに適した構成が見つかるまで反復処理を続けることができます。調査するうえで重要な情報に加えて、通常の単語もインデックスに追加するとします。そのようにすると、通常の単語の検索でも検索インデックスを利用できます。そのためには、次の正規表現をパターンの末尾に追加します。
\b\w+\b
正規パターンは次のようになります。
(?:[a-f0-9]{8}-?[a-f0-9]{4}-?4[a-f0-9]{3}-?[89ab][a-f0-9]{3}-?[a-f0-9]{12})|(?:(?:25[0-5]|2[0-4][0-9]|[01]?[0-9][0-9]?)[.]){3}(?:25[0-5]|2[0-4][0-9]|[01]?[0-9][0-9]?)|(?:[a-zA-Z][a-zA-Z0-9]+@[a-zA-Z]+[.]com)|(?:(?:X{4}-){3}[0-9]{4})|(?:\b\w+\b)
通常の単語をインデックス登録するようになったので、インデックスに不要なエントリが混じらないよう、一般的な英単語を削除することも有効です。そのためには、アナライザ オプションで stop_words リストを指定します。
{"stop_words": ["a", "an", "and", "are", "is", "the"]}
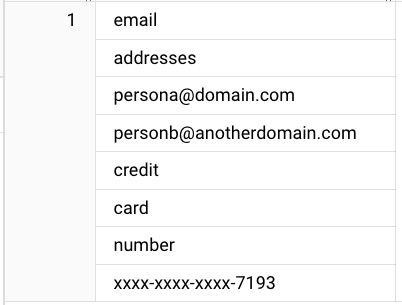
TEXT_ANALYZE 関数を使用した最新の構成と検証を以下に示します(SQL ステートメントではバックスラッシュ「\」をエスケープする必要がある点に注意してください)。
結果:
結果:
検索インデックスの作成
テストが完了し、適切な構成が見つかったら、検索インデックスを作成できます。
検索インデックスの使用
SEARCH 関数は、検索データと入力検索クエリの両方に(指定した構成で)アナライザを適用し、検索クエリのトークンが検索データのトークンのサブセットである場合に TRUE を返す、という仕組みでした。
SEARCH 関数はインデックスなしでも機能しますが、関数とインデックスが同じアナライザ構成を共有する場合、パフォーマンスを向上させるために検索インデックスを活用できます。SEARCH 関数の analyzer 引数と analyzer_options 引数を以下のように設定します。
IP アドレス、顧客 UUID、その他の通常の(ストップワードではない)単語もインデックス登録されるため、これらの検索も同様に検索インデックスで改善できます。
この例から、新しい PATTERN_ANALYZER は、不正行為を調査するシナリオに効果的な検索インデックスを作成できる効果的なツールであることがわかります。テキスト アナライザとそのオプションは、さまざまなユースケースに柔軟に対応できるように設計されています。検索インデックスを適切に構成することで、こちらのブログ投稿で紹介したように、クエリ パフォーマンスを大幅に改善できます。
テキスト アナライザと BigQuery ML
テキストの前処理関数も 2 つ発表します。ML.TF_IDF と ML.BAG_OF_WORDS です。他の前処理関数と同様に、この 2 つの新しい関数を TRANSFORM 句で使用して、データの前処理を行う ML モデルを作成できます。この 2 つの関数をテキスト アナライザで使用する方法を以下の例で示します。
テキスト アナライザの ML のユースケースでは、ベクトル化の前に、すべてのテキスト トークンを抽出して Unicode 正規化を行うことを重視します。そのためには、上記の関数と新しく導入された TEXT_ANALYZE 関数を組み合わせます。
BigQuery ではテキストのベクトル化に事前トレーニング済みの ML モデルを使用できますが、前述の統計ベースの関数は、簡潔さ、解釈可能性、低い計算要件が特長です。さらに、微調整のために分野固有の広範なデータを利用できない新しい分野を扱う際、統計ベースの手法は多くの場合、事前トレーニング済みのモデルベースの手法より優れています。
この例では、ニュースを技術、ビジネス、政治、スポーツ、エンターテインメントという 5 つのカテゴリに分類する ML モデルの構築方法を紹介します。BBC ニュースの公開データセット(BigQuery の bigquery-public-data.bbc_news でホストされています)を使用して、次の手順を実施します。
- ニュースを生の文字列としてトークン化し、英語のストップワードを削除します。
- BigQuery ML で、トークン化したデータとカスタムのベクトル化関数を使用して分類モデルをトレーニングします。
- 新しいテストデータに対して予測を行い、ニュースをカテゴリに分類します。
TEXT_ANALYZE による生テキストの前処理
分類器を構築する最初のステップとして、生のニュース テキストをトークン化し、そのトークンを前処理します。多くの場合、デフォルトの LOG_ANALYZER とその区切り文字のデフォルト リストで十分なため、さらに構成する必要はありません。
また、テキストデータには Unicode テキストが含まれていることがあるため、ICU 正規化が有用な前処理ステップとなります。
{ "normalizer": { "mode": "ICU_NORMALIZE" } }
次に、トークンリストから一般的な英語のストップワードを除外します。
{"stop_words": ["is", "are", "the", "and", "of", "be", "to"]}
まとめると、TEXT_ANALYZE を使用して元データを前処理し、トレーニング モデルの入力としてテーブルに実体化します。
トークン化された行の例を見て、トークン化の結果を把握しましょう。
Result:
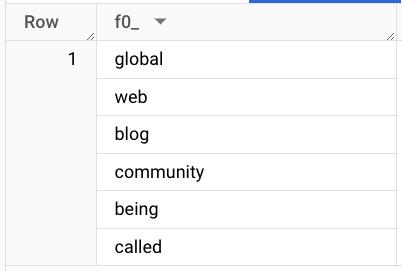
TRANSFORM 句を使用したモデル トレーニング
これで、トークン化されたデータを使用して分類器をトレーニングできるようになりました。この例では、ランダム フォレスト分類器を TRANSFORM 句とともに使用します(ベクトル化関数として ML.BAG_OF_WORDS を使用)。
トレーニング後、作成したモデルのパフォーマンスが良好であることがわかります。

モデルを推論に使用する
最終的に、トレーニング データ以外のスポーツ記事の抜粋を使用してモデルをテストできます。なお、前処理にはまったく同じ TEXT_ANALYZE オプションを使用する必要があります。
結果:
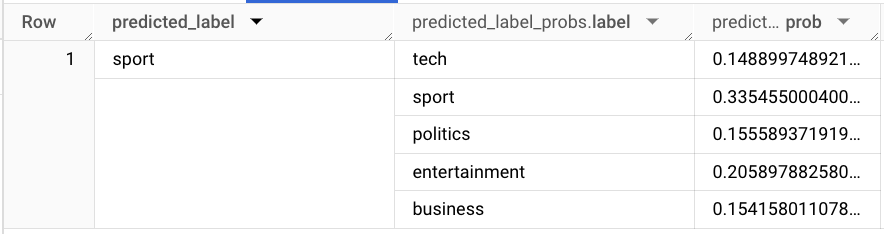
この例は、TEXT_ANALYZE と BigQuery ML のベクトル化関数がデータの前処理と ML モデルの作成に最適なツールであることを示しています。BigQuery ML を使用した感情分析に関する以前のブログ投稿で紹介した複数のステップと比較して、大幅に改善されています。
まとめ
テキスト分析ツールセットに加わった新機能は、既存の機能の価値を向上させ、柔軟性、能力、データの分析力を高めるものです。カスタムのテキスト分析をさまざまな方法で行えるため、Google のツールセットがさらに包括的でユーザー フレンドリーなものになります。
新機能を試して、テキストの前処理と分析のワークフローをどのように強化できるのかをご自身で確かめてみてください。こうした新機能が、お客様のデータの詳しい分析に役立てば幸いです。お客様のニーズに応えられるよう、今後もテキスト分析ツールの開発と改善に取り組んでまいります。
- BigQuery 検索担当ソフトウェア エンジニア HP Truong

