BigQuery ML を使用した感情分析
Google Cloud Japan Team
BigQuery ML とスパースな特徴を使用した感情分析の実行
※この投稿は米国時間 2023 年 3 月 7 日に、Google Cloud blog に投稿されたものの抄訳です。
はじめに
Google は先日、BigQuery がスパースな特徴に対応し、ユーザーがスパースな特徴を扱うと同時に、効率的に保存、処理できるようになったことを発表しました。この機能により、ユーザーはスパース テンソルを表現し、BigQuery 環境で直接 ML モデルをトレーニングできるようになります。スパース テンソルは、NLP アプリケーションにおけるデータの前処理の一部として TF-IDF のようなエンコード スキームで広く使用されているうえ、コンピュータ ビジョン アプリケーションでは濃い色のピクセルが多い画像の前処理に使用されているため、スパース テンソルを表現できるこの機能は有用です。
テキスト生成や感情分析など、スパースな特徴には多数の活用方法があります。このブログ投稿では、一般公開データセットを使用して ML モデルのトレーニングと推論を行うことにより、BigQuery ML でスパースな特徴を使用して感情分析を行う方法をご紹介します。また、これまで構造化データが使われてきた BigQuery 環境において、非構造化テキストデータをいかに簡単に扱うことができるかもご紹介します。
サンプル IMDb データセットの使用
たとえば、IMDb のウェブサイトにある映画のレビューについて感情分析を行いたいとします。ご自身で確認したい読者のために、BigQuery の一般公開データセットの中から IMDb のレビュー データセットを使用します。では、データセットの最初の 2 行を見てみましょう。
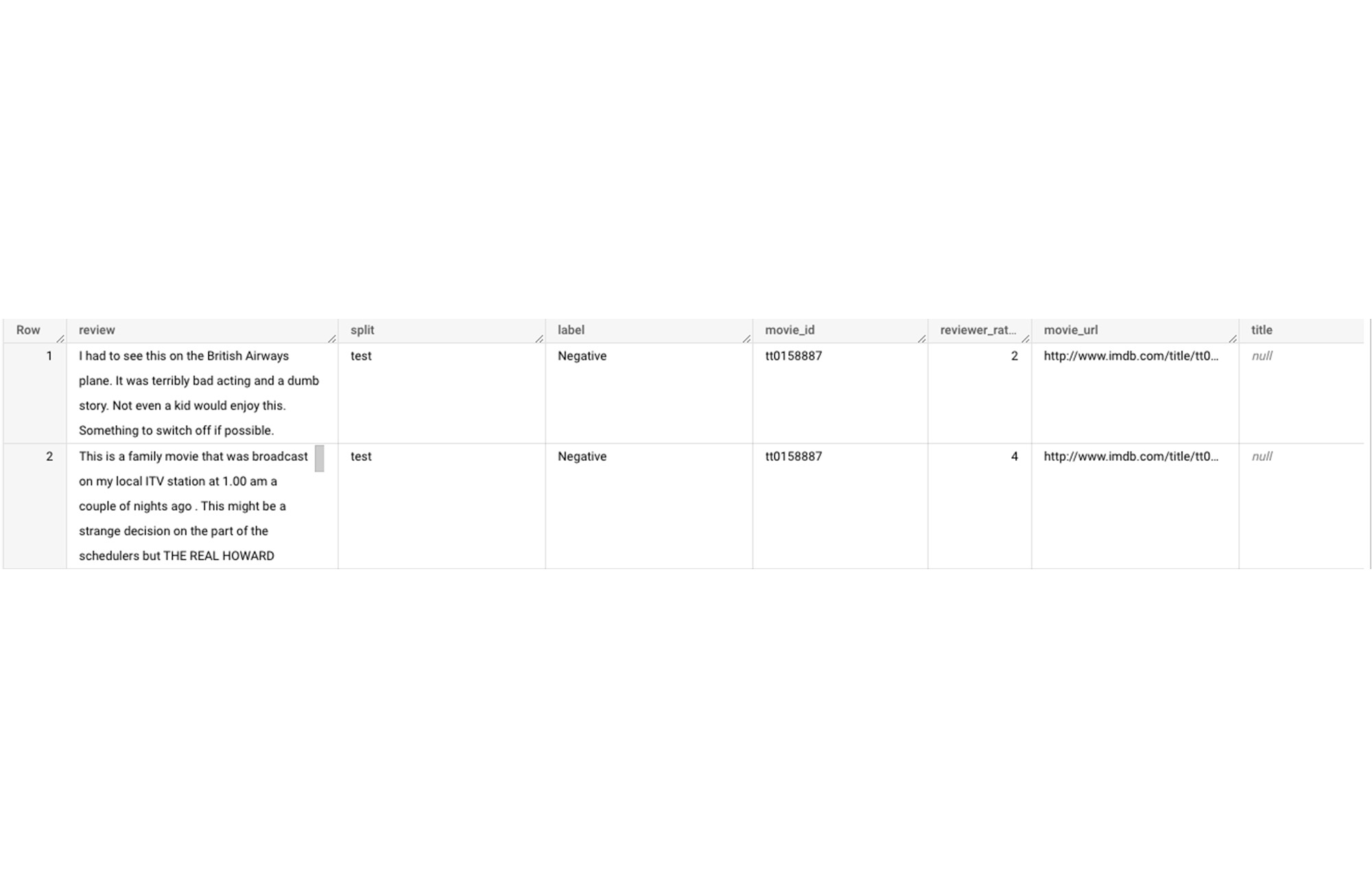
レビュー テーブルには列が 7 つありますが、今回は review 列と label 列のみを使用して感情分析を行います。また、label 列では「Negative」と「Positive」の値のみを考慮します。以下のクエリを使用すると、データセットから必要な情報のみを選択できます。
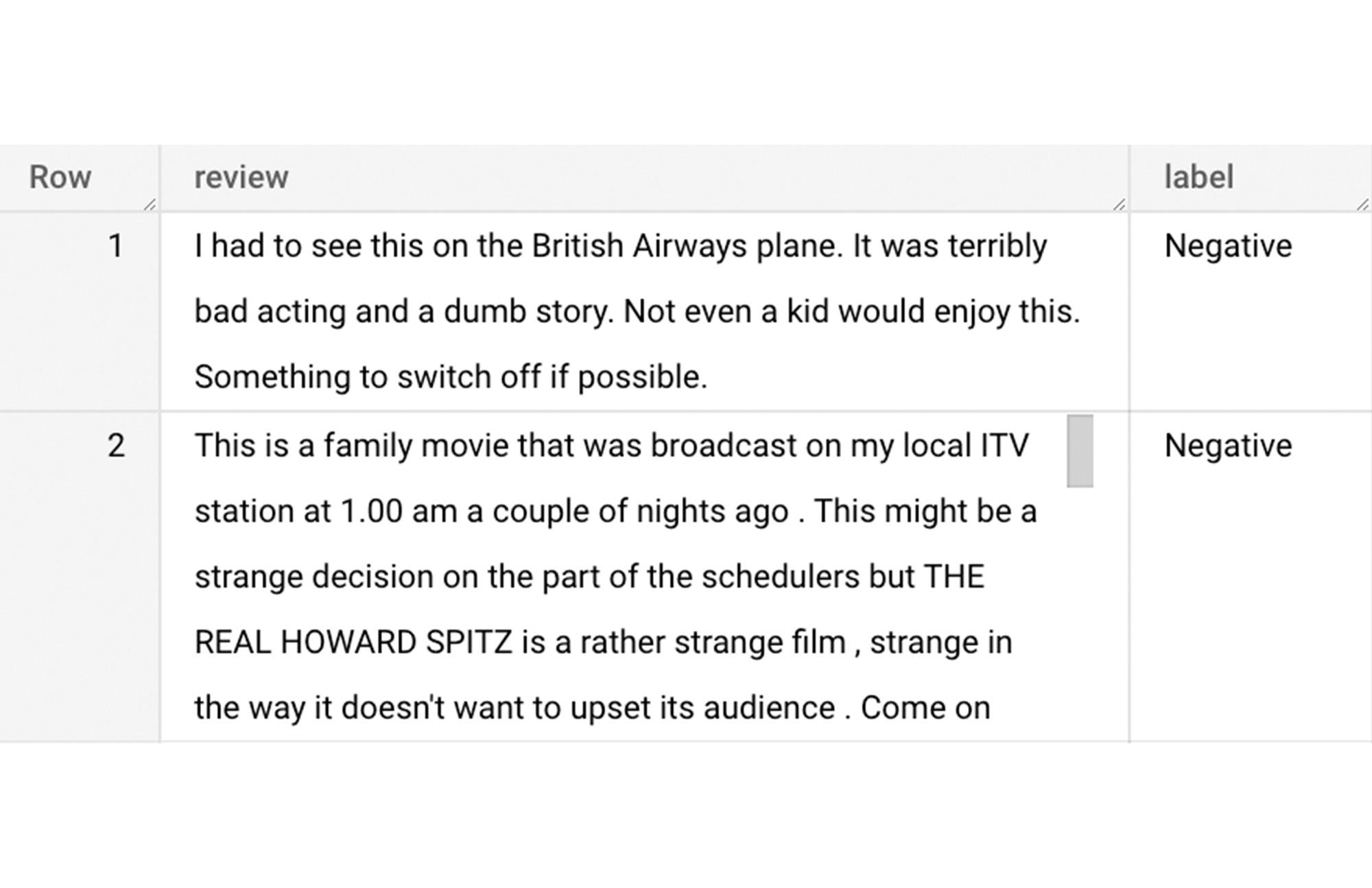
結果の最初の 2 行は以下のようになります。
方法
取得したデータセットに基づき、以下の手順を行います。
review 列を使用して語彙リストを作成する
review 列をスパース テンソルに変換する
ラベル(「Positive」または「Negative」)を予測できるよう、スパース テンソルを使用して分類モデルをトレーニングする
新しいテストデータに対して予測を行い、レビューを「Positive」または「Negative」に分類する
特徴量エンジニアリング
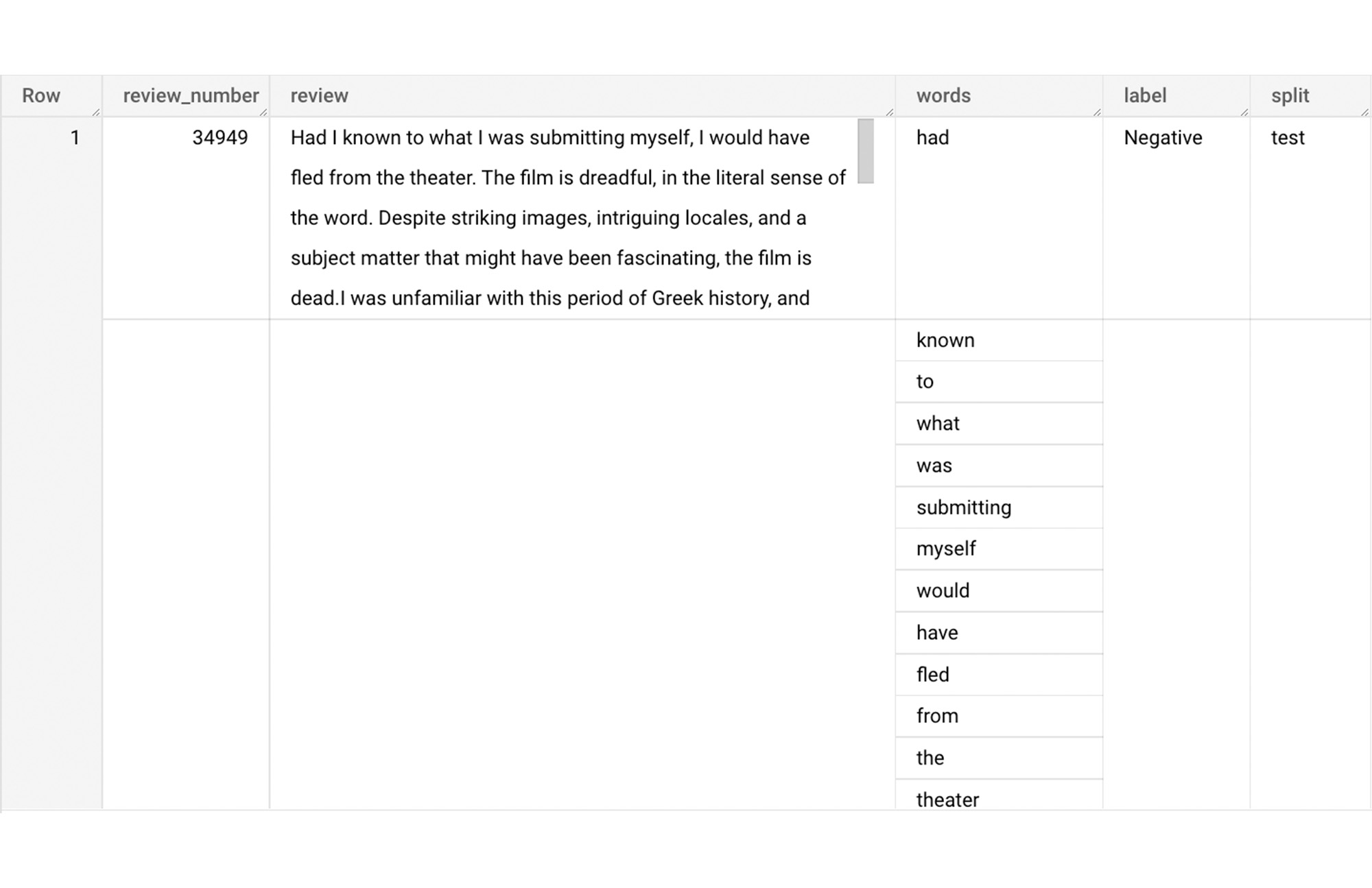
このセクションでは、review 列のテキストを数値特徴に変換し、ML モデルにフィードできるようにします。その方法の一つが bag-of-words アプローチです。レビューの単語を使用して語彙を作成し、その中からよく使われる単語を選択してモデル トレーニング用の数値特徴を構築します。そのためにはまず、各レビューから単語を抽出する必要があります。以下のコードでは、データセットを作成した後、レビューから抽出した単語と行番号を含むテーブルを作成します。
上記のクエリから出力されるテーブルは、以下のようになります。
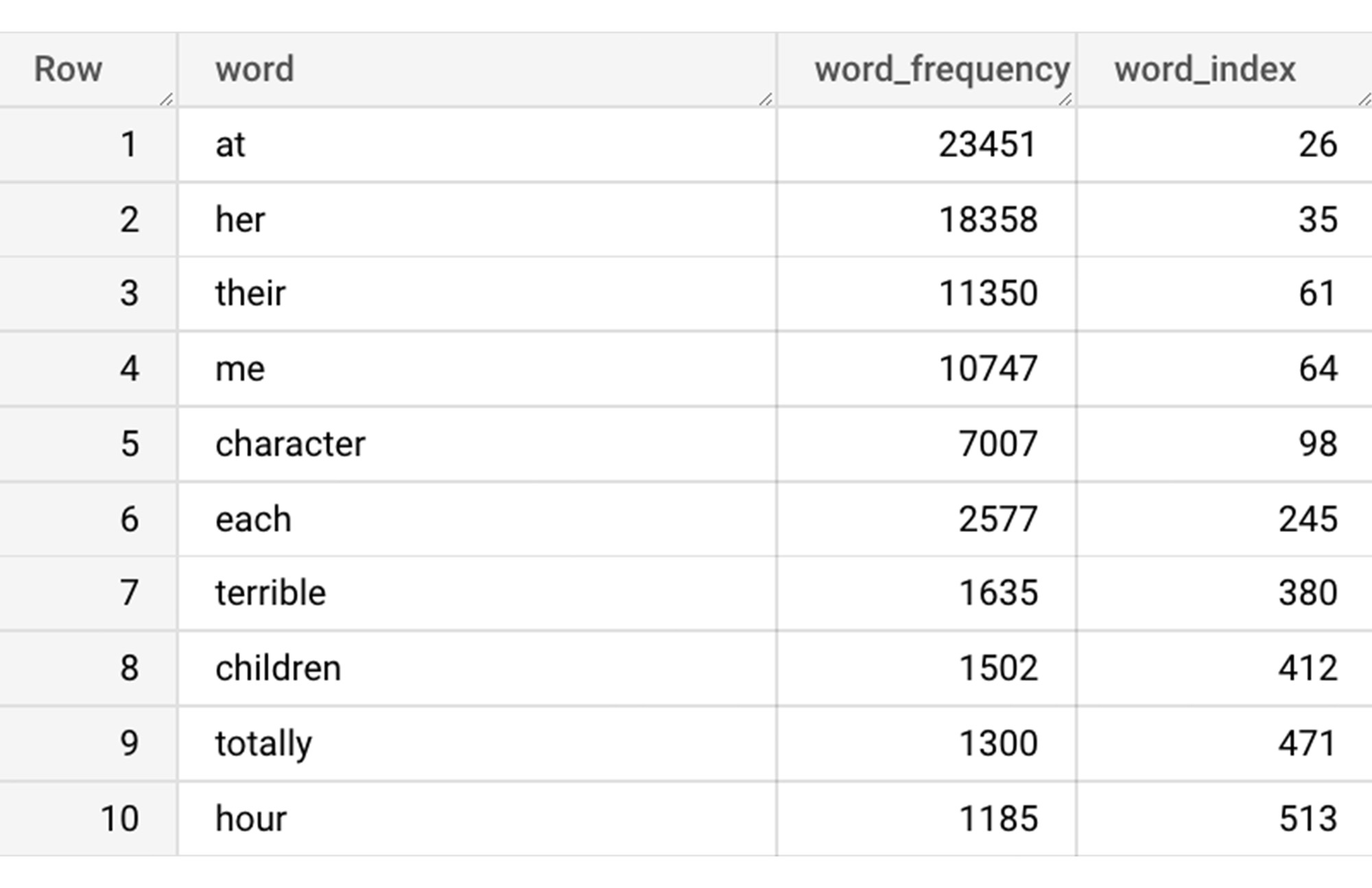
次のステップは、抽出された単語を使用した語彙の作成です。以下のコードでは、レビューの単語の使用頻度とインデックスを含む語彙を作成します。今回は計算時間を短縮するために、上位 20,000 語のみを選択します。
上記のクエリで生成されたテーブルにおける、単語の使用頻度に基づく上位 10 語とそれぞれのインデックスは、以下のようになります。
スパースな特徴の作成
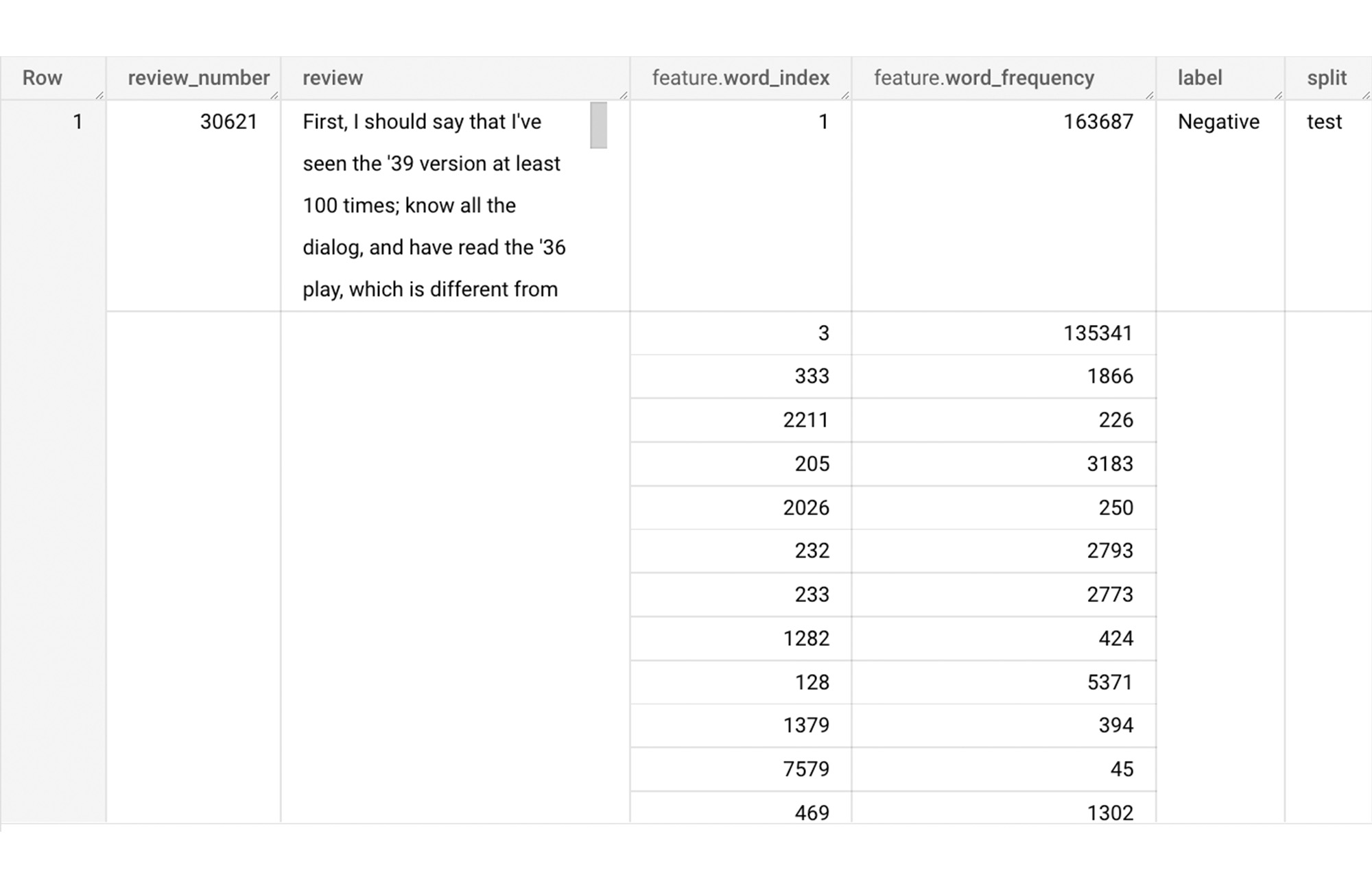
では、新しく追加された特徴を使用して、BigQuery でスパースな特徴を作成しましょう。今回は、各レビューの word_index と word_frequency を集約し、ARRAY[STRUCT<int, numerical>] 型の列を生成します。これにより、各レビューは ARRAY[(word_index, word_frequency)] として表現されます。
クエリを実行すると、「feature」という名前のスパースな特徴が作成されます。この feature 列は ARRAY of STRUCT 列で、word_index 列と word_frequency 列によって構成されます。下の図は、生成されたテーブルを一目でわかるように表示したものです。
BigQuery ML モデルのトレーニング
先ほど、BigQuery でスパースな特徴を持つデータセットを作成しました。そのデータセットを使用して、BigQuery ML で ML モデルをトレーニングする方法を見ていきましょう。以下のクエリでは、review_number、review、feature を使用してロジスティック回帰モデルをトレーニングし、label を予測します。
スパースな特徴を使用して BigQuery ML モデルをトレーニングしたので、モデルを評価し、必要に応じて調整します。
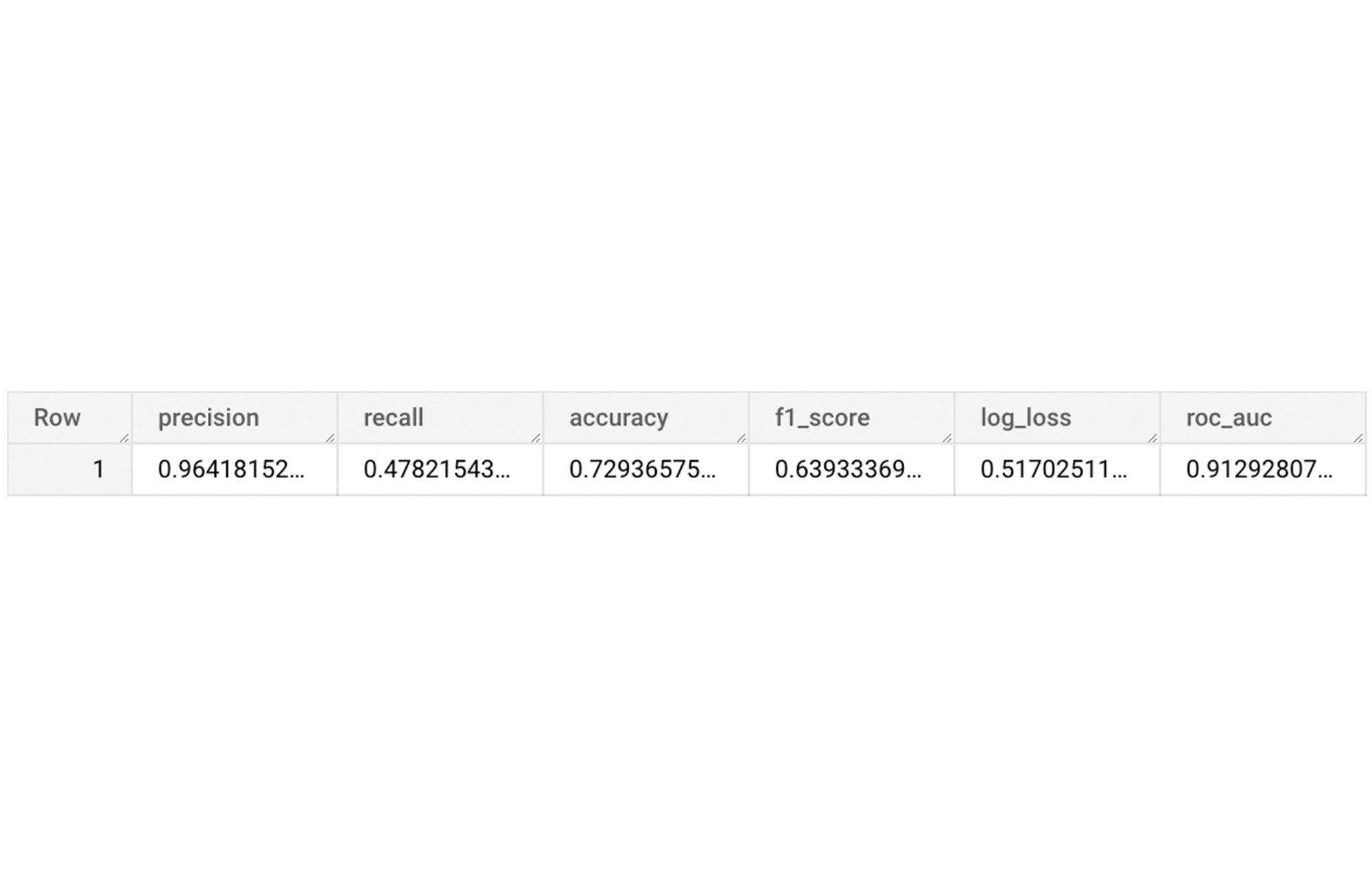
このスコアは最初としてはまずまずのようです。では、テスト用データセットを使用してモデルをテストしてみましょう。
テスト用データセットに対するこのモデルのパフォーマンスは申し分ありません。これで推論に使用できるようになりました。ここで一つ注意しなければならないのは、このモデルは数値特徴でトレーニングされているため、入力には数値特徴しか受け付けないということです。そのため、新しいレビューを推論に使用するには、まず同じ変換手順を行う必要があります。次のステップでは、この変換をユーザー定義のデータセットに適用する方法をご紹介します。
BigQuery ML モデルによる感情予測
後は、ユーザー定義のデータセットを作成してレビューに同じ変換を適用し、ユーザー定義のスパースな特徴を使用してモデルの推論を行うだけです。この処理は、以下のように WITH ステートメントを使用して実行できます。
上記のクエリを実行すると、以下のような結果になります。
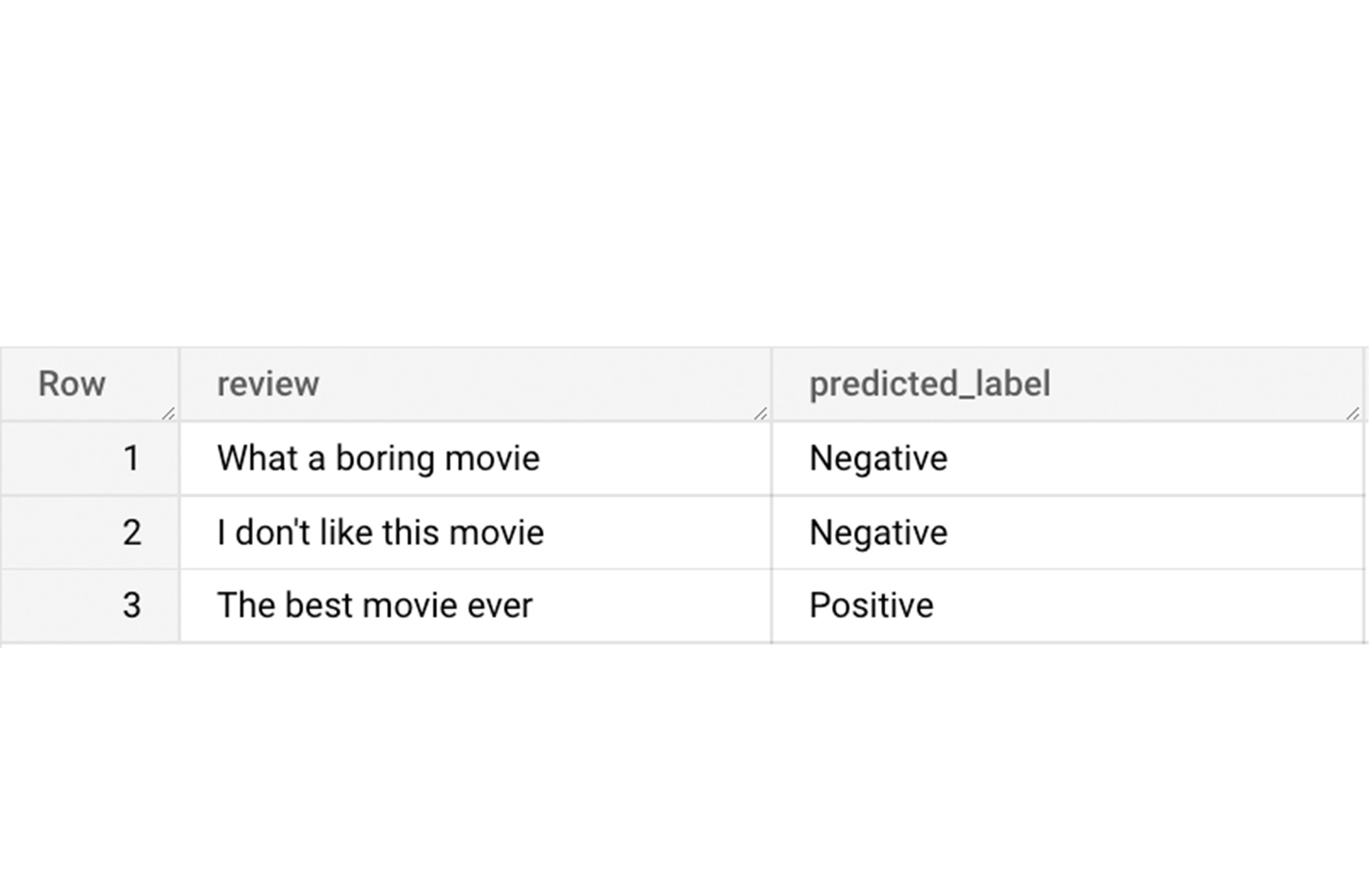
これで完了です。BigQuery 一般公開データセットの IMDb データセットに対し、SQL ステートメントと BigQuery ML のみを使用して感情分析を行いました。BigQuery ML モデルにスパースな特徴を使用できることをご紹介しましたが、今後この機能を活用してどのような素晴らしいプロジェクトが生まれるのか、今から楽しみでなりません。
BigQuery を使い始めたばかりの方は、まずはインタラクティブなチュートリアルをご利用ください。
- Google Cloud ソフトウェア エンジニア Xiaoqiu Huang



