BigQuery による半構造化データのネイティブ サポートのプレビュー版を発表
Google Cloud Japan Team
※この投稿は米国時間 2022 年 1 月 7 日に、Google Cloud blog に投稿されたものの抄訳です。
本日は、BigQuery での半構造化データの保存と分析をサポートする機能、BigQuery ネイティブ JSON データ型の公開プレビュー版を発表いたします。
この新しい JSON ストレージ タイプと JSON の高度な機能(JSON ドット表記のサポート、適応可能なデータ型の変更、新しい JSON 関数など)によって、BigQuery で半構造化データをネイティブ形式で直感的に使用し、クエリできるようになりました。
この機能のプレビュー版には、こちらからご登録いただけます。
データの変更に伴う課題
データ パイプラインを構築するには、さまざまな決定が必要です。たとえば、「データをどこから取り込むか」、「アプリケーションでのデータのロードはバッチジョブとリアルタイムのストリーミング取り込みのどちらとして行う必要があるか」、「テーブルはどのような構造にすべきか」などを決定する必要があります。こうした決定の多くは、データ パイプラインを構築する前に行うのが一般的です。つまり、データ パイプライン構築後に行われるテーブルやデータ型の変更は、残念ながら複雑でコストのかかるプロセスになる可能性があります。
従来、これらのイベントを処理するには、変更処理のための複雑な自動化を構築するか、データの取り込みを一時停止して手動で介入できるようにするか、計画外のデータをキャッチオール文字列フィールドに書き込んでおいて、後処理で解析する必要がありました。
このようなアプローチはどれも、コスト増と複雑化の原因となり、データドリブンなインサイトを生み出す能力を低下させます。
ネイティブ JSON の活用
JSON は、スキーマを必要としないため、半構造化データを可能にする形式として広く使用されています。これにより、固定のスキーマやデータ型に常に準拠しているとは限らないデータを保存およびクエリする柔軟性が追加されます。BigQuery では、半構造化データを JSON データ型として取り込むことにより、各 JSON フィールドを個別にエンコードして処理できます。その後で、ドット表記を使用して JSON データ内のフィールドの値を個別にクエリできます。これにより、JSON クエリが使いやすくなります。この新しい JSON 機能は、データブロック全体を処理する必要がある文字列フィールドから JSON 要素を抽出する以前の方法と比べて、コスト効率も優れています。
BigQuery のネイティブ JSON サポートのおかげで、お客様は将来データを変更するときのことを心配せずに、BigQuery にデータを書き込めるようになりました。モバイルゲームと e コマースのサービス プロバイダである DeNA のようなお客様は、価値創出までの時間を短縮できるため、この新機能を活用することに価値を見出しています。
「アジリティは当社の成功の鍵です。ネイティブ JSON 機能により、データモデルの変更をより迅速に処理し、データからインサイトを引き出すためのリードタイムを短縮できると確信しています。」—長谷川了示氏、データ エンジニア、株式会社ディー・エヌ・エー
JSON の実用例
多くの場合、何かを学習するための最善の方法は実際にやってみることです。ネイティブ JSON の実用例を見てみましょう。取り込みパイプラインが 2 つあるとします。1 つは一括取り込みを実行し、もう 1 つはリアルタイム ストリーミング取り込みを実行します。いずれのパイプラインもアプリケーション ログイン イベントを BigQuery に取り込んで、さらに分析します。ネイティブ JSON 機能を活用することで、アップストリーム データの進化と変更内容をアプリケーションに取り入れることができます。
CSV としての JSON の一括取り込み
JSON 型は現在、CSV 形式のファイルの一括読み込みのジョブを介してサポートされています。ここでは例として、json_example.batch_events という新しいテーブルを作成し、以下の bq コマンドを使用して、この正しくエスケープされた login_events.csv ファイルを BigQuery に取り込むことにします。batch_events テーブルには、構造化された列と、半構造化フィールドに新しい JSON 型を使用する labels フィールドの両方があります。この例では、イベント作成時刻、イベント ID、イベント名などの一部のアプリケーション値が高度に構造化されたままになるため、このテーブルを構造化データと半構造化データの両方を保存するものとして定義します。
このブログの後半では、新しい JSON 関数を使用してクエリを実行する方法を説明しますが、まず、JSON 型を使用して半構造化リアルタイム イベントを BigQuery にストリーミングする方法についても説明しておきます。
リアルタイム ストリーミング用の JSON イベント
次に、先ほどと同じ半構造化アプリケーションのログイン イベントを BigQuery にストリーミングする方法の例を見ていきましょう。まず、構造化列と半構造化列の同じ組み合わせを利用する json_example.streaming_events という新しいテーブルを作成します。ただし、bq コマンドラインを使用する代わりに、SQL データ定義言語(DDL)ステートメントを実行してこのテーブルを作成します。
BigQuery は、BigQuery Storage Write API と以前のストリーミング API という 2 つの形式のリアルタイム取り込みをサポートしています。Storage Write API は、gRPC を介して BigQuery にデータを書き込むための統合データ取り込み API として機能するもので、1 回限りの配信セマンティクス、ストリームレベルのトランザクション、複数ワーカーのサポートなどの高度な機能を提供し、通常は以前のストリーミング API よりも推奨されます。ただし、以前のストリーミング API は一部のお客様の間で引き続き使用されているため、Storage Write API を介した JSON データの取り込みと、以前の insertAll ストリーミング API を介した JSON データの取り込みの両方の例を見ていくことにします。
Storage Write API を介する JSON
Storage Write API を介してデータを取り込むには、プロトコル バッファとしてデータをストリーミングします。プロトコル バッファの使用法について簡単に復習するには、こちらのチュートリアルをご確認ください。
まず、proto2 の .proto ファイルを使用して json_example.streaming_events テーブルに書き込むためのメッセージ形式を定義します。こちらからファイルをコピーした後で、Linux 環境内で次のコマンドを実行し、プロトコル バッファ定義を更新できます。
次に、このサンプル Python コードを使用して、構造化データと半構造化データの両方を streaming_events テーブルにストリーミングします。このコードは、以下の例のように、proto2 シリアル化バイトを serialzed_rows 繰り返しフィールドに追加することにより、行データのストリーミングをバッチ処理します。特に注目すべきは、テーブル内で JSON として定義された labels フィールドです。
実行が完了すると、Storage Write API から数行がテーブルに取り込まれていることがわかります。

以前の insertAll ストリーミング API を介した JSON
最後に、以前の insertAll API を使用して、同じ streaming_events テーブルへのストリーミング データを調べてみましょう。insertAll API アプローチでは、ローカル ファイル内に保存されている一連の JSON イベントを、先ほどと同じ streaming_events テーブルにリアルタイムで取り込みます。イベントは以下のように構造化され、ラベル フィールドは高度に可変的で半構造化されます。

次に、ローカル JSON イベント ファイルからデータを読み取り、それを BigQuery にストリーミングする次の Python コードを実行します。
JSON イベントが BigQuery に正常に取り込まれ(一括取り込み、Storage Write API、または以前のストリーミング API、あるいはその 3 つすべてを使用)、BigQuery で半構造化データをクエリする準備が整いました。
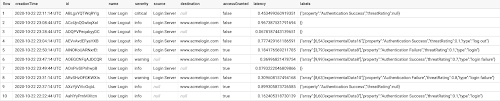
新しい JSON データのクエリ
ネイティブ JSON 型の導入に伴い、ネイティブ形式でデータを簡単かつ効率的にクエリするための新しい JSON 関数も導入されています。
たとえば、取り込んだイベントのうち、ログイン認証が失敗したイベントの数を取得するには、ドット表記を使用して JSON 値の labels.property フィールドでフィルタします。
ラベル内の threatRating フィールドを浮動小数点数としてネイティブにキャストすることによって、データセット内のログイン失敗に起因するイベント脅威を平均化し、集計を実行することもできます。
既存のテーブルがある場合のネイティブ JSON
既存のテーブルがある場合に、すべてのデータを書き換えなくてもネイティブ JSON 型を利用することが可能です。
BigQuery では、newJSONField という名前の新しい JSON 列を既存のテーブルに追加する次のような DDL ステートメントを使用して、既存のテーブル スキーマを変更するなどの操作を簡単に行えます。
ここでは、既存のデータ(おそらく文字列として保存されている既存の JSON データ)を newJSON フィールドに変換するか、純粋に新しいデータをこの列に取り込むことによって、newJSON 列の利用方法を決定できます。
既存のデータを JSON に変換するには、文字列を JSON 型に変換する PARSE_JSON 関数、または任意のデータ型を JSON 型に変換する TO_JSON 関数を、UPDATE DML ステートメントで使用します。以下にそれぞれの関数を使用した例を示します。
文字列を JSON に変換する場合:
こちらの例のように、ネストされた繰り返し STRUCT として保存されている既存のデータを JSON に変換する場合:
BigQuery でネイティブ JSON を使い始める方法
データの形式やサイズは多種多様であり、進化を止めることはありません。データとその将来の進化をサポートする BigQuery ネイティブ JSON 型のプレビュー版に登録するには、こちらのフォームにご記入ください。
- Nick Orlove、Google Cloud カスタマー エンジニア
- Francis Lan、Google Cloud ソフトウェア エンジニア


