BigQuery 向けにデータリネージ システムを構築
Google Cloud Japan Team
※この投稿は米国時間 2021 年 2 月 10 日に、Google Cloud blog に投稿されたものの抄訳です。
組織内でデータを民主化することは、社員が新しい知見を得て、組織の成長を促すために不可欠です。その前提で、ビッグデータ環境においてデータ ウェアハウス内のデータの所出や流れを追跡できるようにすること(トレーサビリティ)は、非常に重要な意味をもちます。トレーサビリティの情報はデータリネージと呼ばれ、それを追跡、管理、確認できるような環境を整えることで、データエラーの追跡や、フォレンジック分析、データの依存関係の特定を簡単に行うことができるようになります。
データリネージは、ビジネスデータを保護するためにも欠かせません。たとえば、組織ではデータ ガバナンスの手順が定められ、個人情報(PII)などの機密データの流れを完全に追跡できるようにすることが求められています。特に重要視されているのは、メタデータが顧客のクラウド組織(またはプロジェクト)の外に出ないようにすることです。
Data Catalog は、ビジネス メタデータと各種データアセットの関連を指定するための機能豊富なインターフェースを提供するサービスです。関連付けの対象となるデータアセットは、Google Cloud 内の BigQuery、Cloud Storage、Pub/Sub から、Google Cloud 外のオンプレミスのデータセンターやデータベースまで、広範囲にわたります。Data Catalog で運用およびビジネス メタデータとデータアセットの関連付けを行うには、構造化タグを使用します。ユーザーが構造化タグを指定し、このタグを使って、ビジネスや運用に関する複雑なメタデータ(エンティティ スキーマなど)を管理したり、データリネージを系統立てたりすることが可能になります。
データリネージの一般的な用途
データリネージはさまざまな用途に利用され、これらの用途には共通する部分も、異なる部分もあります。また、用途ごとに必要なリネージ情報の細かさも異なります。たとえば、テーブルやデータセットなど、データアセット間の関係性が知りたいときもあれば、テーブルごとに列レベルのデータリネージが必要な場合もあります。そのほかにも、テーブル内の特定の行のデータを追跡するといった用途があります(行レベルのリネージと呼ばれます)。
ここでは、最も一般的な「列レベル」に着目し、以下の各用途のためにデータリネージを自動化するという具体的なアーキテクチャについてご説明します。
因果関係、依存関係の分析
大規模な企業では、古いデータアセットを廃止して置き換えるなど、データアセットのスキーマを変更しなければならないことがよくあります。こうした計画的な変更においてデータリネージを用いれば、互換性に支障をきたすような変更に注意を払ったり、影響が及ぶテーブルや BI ダッシュボードを特定したりすることが可能になります。
データの漏洩、引き出し
セルフサービス型の分析環境では、偶発的にデータが引き出されるリスクがあり、そのような事態が発生した場合、企業の信用低下を招きかねません。データリネージは、このような予想外のデータの動きを特定するために役立ちます。たとえば、外向きのデータ送信が特定のプロジェクトや場所に対してのみ行われるように制限して、一部の許可されたユーザーしかアクセスできないようにすることができます。
誤データのデバッグ、データ品質の修正
データ品質が低下する原因には、元データの不足や誤りのほか、データ パイプラインでの誤ったデータ変換があります。そんなときにリネージグラフを遡れば、データ変換時の問題を調べたり、元データまで辿って原因を見極めたりすることができます。
データ パイプラインの検証
コンプライアンスの規定により、承認済みデータソースのみに由来する正式なデータアセットを用意し、データパイプラインを正しく使用することが義務付けられている場合、たとえばアナリストが分析用に作成したテーブルや、PII データが含まれるテーブルを用いることは許されません。このような場合、データリネージを使えば、データ パイプラインがガバナンスの要件に沿っているかどうかを検証、証明することができます。
データ サイエンティストのインストロペクション
データ サイエンティストはさまざまな目的のもと、データリネージ グラフを詳しく観察し、データにどのような用途があるかを十分に把握することが求められます。データリネージ グラフを辿り、データの変換について調べることで、データアセットがどのように構築されているか、ML モデルにどう活用できるか、ビジネスにどのように役立てることができるかに関する重要な知見を得ることができます。
リネージの抽出システム
BigQuery のような SQL データ ウェアハウスには、パッシブなデータリネージ システムが適しています。リネージ抽出プロセスでは、まず SQL クエリを用いて、ターゲット エンティティの生成に使用されたソース エンティティを特定します。クエリを解析する際は、そのクエリのソース エンティティのスキーマ情報を Schema Provider から取得する必要があります。続けて Grammar Provider を使用して、出力列とソース列の関係と、出力カラムに適用された関数 / 変換リストを特定します。リネージを取得する手順は以下のとおりです。
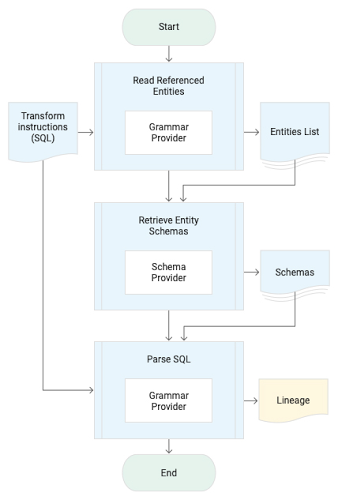
ソース、ターゲット、変換情報の組み合わせに基づくリネージ データモデルを通じて、リネージが抽出、記録されます。
BigQuery のサーバーレス データ ウェアハウスでは、クラウドネイティブのリネージ ソリューションとして Pub/Sub からリアルタイムで提供される BigQuery 監査ログが使用されます。Dataflow の抽出パイプラインでは、ZetaSQL のグラマー エンジンを使ってクエリの SQL を解析し、BigQuery API から取得したテーブル スキーマを使用して、生成されたリネージを BigQuery テーブル内に保持し、Data Catalog 内にタグとして保存するという一連の処理が行われます。このリネージ テーブルに対してクエリをかけることで、データ ウェアハウス内のデータフローを完全に特定することができます。このアーキテクチャは次のようになります。
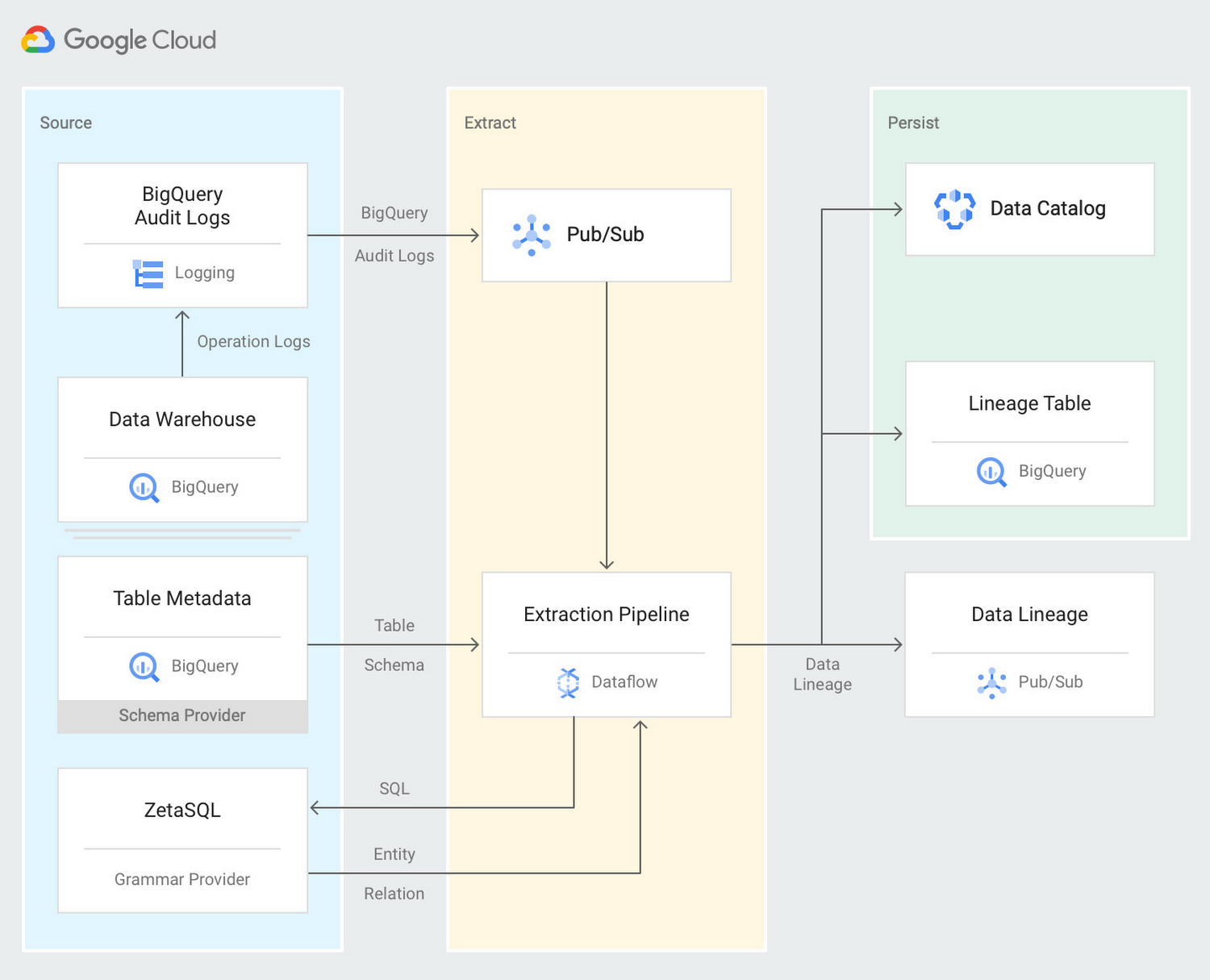
データリネージを実際に使ってみる
説明は以上です。実際に BigQuery データリネージ システムをデプロイしてみたいという方は、bigquery-data-lineage GitHub リポジトリのクローンを作成してみてください。あるいはさらに踏み込んで、リネージ シグナルに基づいて、生成されたテーブルにデータ アクセス ポリシーを動的にプロパゲートさせてみてはいかがでしょうか。
- ソリューション アーキテクト Anant Damle




{kind=link}
{kind=link}