Dataproc Hub を導入して Apache Spark と AI Platform Notebooks の能力を活用する
Google Cloud Japan Team
※この投稿は米国時間 2020 年 5 月 29 日に、Google Cloud blog に投稿されたものの抄訳です。
Apache Spark は、大量のデータを探索し、機械学習(ML)に関連した付随タスクを大規模に実行することが必要な企業で幅広く利用されています。データ サイエンティストは多くの場合、それらの大規模なデータセットを Jupyter Notebook などのツールで掘り下げることが不可欠です。Jupyter Notebook は、Spark によるスケーラブルな処理システムへのプラグインとして利用でき、常用の ML ライブラリへのアクセスも可能にします。新たにリリースされる Dataproc Hub を利用すると、インタラクティブ データの大規模なリサーチと ML を同一のノートブック環境(Dataproc または AI Platform)から安全かつ一元的に実行できます。
Google Cloud では、以下のプロダクトでノートブックにアクセスできます。
Dataproc: Google Cloud のマネージド サービスの 1 つで、Spark と Hadoop のジョブに加え、Hadoop の広範なエコシステムに含まれるその他のオープンソース ソフトウェアを実行します。また、ノートブックがオプション コンポーネントとして提供されているほか、コンポーネント ゲートウェイ経由で安全にアクセスできます。詳しくは、Jupyter Notebook のプロセスをご覧ください。
AI Platform Notebooks: Deep Learning Compute Engine インスタンス上で実行される JupyterLab 環境向け Google Cloud マネージド サービスで、Google の反転プロキシによって提供される安全な URL を介してアクセスできます。
どちらのプロダクトも先進的な機能を利用してノートブックをセットアップできますが、これまでは以下の制限がありました。
データ サイエンティストは、Spark と常用の ML ライブラリのどちらか一方を選択するか、相応の時間を費やして環境を設定しなければなりませんでした。この作業は煩雑になる場合があり、反復作業が生じることも少なくありませんでした。その時間を使って、もっと興味深いデータを探索できたかもしれません。
管理者がユーザーにすぐ利用できる環境を提供することは可能でしたが、特定のユーザーや特定のユーザー グループ向けのマネージド環境をカスタマイズする手段がほとんどありませんでした。結果として、好ましくないコストや、セキュリティ管理上のオーバーヘッドが生じることもありました。
データ サイエンティストから要望として寄せられていたのは、同一のノートブックから、インタラクティブな Spark タスクを大規模に実行すると同時に、ML ライブラリにもアクセスできる柔軟性でした。さらに、セットアップのオーバーヘッドを最小限に抑えることも求められていました。
管理者の要望は、費用とセキュリティに関する自社の制約をプラットフォームで遵守しながら、大きな規模でインタラクティブにデータセットを探索するための手立てをデータ サイエンティストに提供したいというものでした。
Google が今回リリースする Dataproc Hub は、そうしたニーズに応えるプロダクトです。Dataproc Hub の基盤は、Google Cloud のコアプロダクト(Cloud Storage、AI Platform Notebooks、Dataproc)とオープンソース ソフトウェア(JupyterHub、Jupyter、JupyterLab)です。
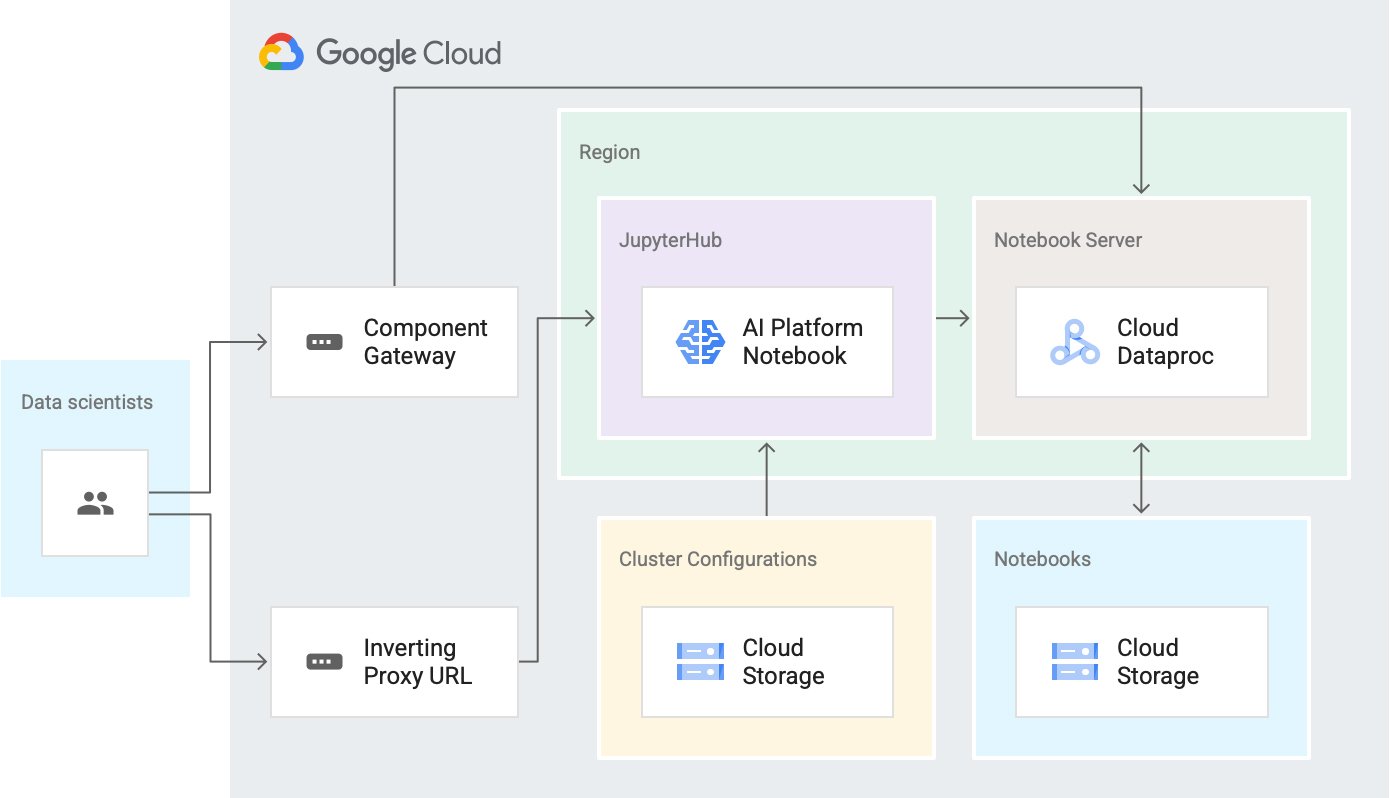
Dataproc Hub では、前述のテクノロジーを組み合わせて以下を実現しています。
事前に定義された Spark ベースの環境を、データ サイエンティストが必要になった時点ですぐに選択できるようにしました。データ サイエンティストは、考えうる構成や必要な操作をすべて把握しておく必要がなくなります。今回のリリースで実現するシンプルな手順と、以下をはじめとする Dataproc のこれまでのメリットの両方をデータ サイエンティストが活用できます。
アジリティ: リソースを待機させることなく数秒で起動できるエフェメラルな(存続時間が短いか、ジョブ限定であることが通例)クラスタによって実現します。
スケーラビリティ: 自動スケーリング ポリシーで管理します。データ サイエンティストは、同一のノートブックからサンプルデータのリサーチとテストを大規模に実施できるようになります。
耐久性: Dataproc クラスタの外部にある Cloud Storage が基盤となっているため、貴重な処理結果を失うリスクを最小限に抑えられます。
標準化された環境の管理を円滑に実施できます。管理者とデータ サイエンティストのどちらも、本番環境に移行する作業が容易になります。今回のリリースによるセキュリティおよび一貫性の強化と、以下をはじめとする Dataproc のこれまでのメリットの両方を管理者が活用できます。
Dataproc Hub を使ってみる
デフォルトのセットアップで Dataproc Hub をすぐに導入する手順は、次のとおりです。
1. Dataproc の UI に移動します。
2. 左側のパネルにある [ノートブック] メニューをクリックします。
3. [新しいインスタンス] をクリックします。
4. [スマート アナリティクス フレームワーク] メニューの [Dataproc Hub] を選択します。

6. インスタンスの作成処理が完了したら、[JupyterLab を開く] をクリックします。

8. Dataproc Hub インスタンスの作成対象となったデータ サイエンティストのグループに、URL を通知します。この安全なエンドポイントにデータ サイエンティストがアクセスすると、データ サイエンティストの ID が確認されます。確認された ID に基づいて、各ユーザー固有のシングル ユーザー環境が提供されます。
事前定義の構成
管理者は、データ サイエンティスト用にカスタマイズ オプションを追加できます。たとえば、管理者によって用意された構成のリストから、データ サイエンティストが事前定義の作業環境を選択できます。クラスタ構成の実体は、管理者が次のステップで定義する宣言型の YAML ファイルです。
- 手動でリファレンス クラスタを作成し、その構成を次のコマンドでエクスポートします。gcloud beta dataproc clusters export CLUSTER
- Dataproc Hub インターフェースの実行元インスタンスの ID でアクセスできる Cloud Storage バケットに、YAML 構成ファイルを保存します。
- 作成するすべての構成について、このステップを繰り返します。
- Dataproc Hub インスタンスの作成時に、関連する YAML ファイルのすべての Cloud Storage URI を使用して、環境変数を設定します。
注: 管理者が構成を提供した場合、データ サイエンティストが Dataproc Hub エンドポイントに初めてアクセスすると、上のステップ 6 で言及した構成用のフォームが表示されます。ノートブック環境がその URL で実行されている場合は、データ サイエンティストが各自のノートブックに直接リダイレクトされます。
Dataproc Hub のセットアップと使用については、Dataproc Hub のドキュメントをご覧ください。
セキュリティの概要
Cloud Identity and Access Management(Cloud IAM)はほとんどの Google Cloud プロダクトの中心となるコンポーネントであり、セキュリティ上重要な 2 つの機能を提供します。
- ID: アクションを実行しようとしているユーザーの身元を明らかにします。
- アクセス: 当該の ID によるアクションの実行を許可するかどうかを指定します。
Dataproc Hub の現行バージョンでは、生成されるすべてのクラスタで、カスタマイズ可能な同一のサービス アカウントが使用されます。アカウントを設定する手順は以下のとおりです。
管理者が、生成されるすべての Dataproc クラスタの共通 ID として機能するサービス アカウントを提供します。アカウントを設定しない場合は、Dataproc クラスタのデフォルト サービス アカウントが使用されます。
ユーザーが Dataproc 上でノートブック環境を生成すると、当該の ID を使用してクラスタが起動します。Dataproc Hub がクラスタの生成元であるため、当該のサービス アカウントに roles/iam.serviceAccountUser ロールは必要ありません。
ツールの最適化
特定の環境で便利に使用できるその他のツールについては、以下を参照してください。
- クラスタの起動時間を可能な限り短縮するには、Dataproc カスタム イメージを使用します。このステップは、Cloud Builder のコミュニティで提供されているイメージを使用して自動化できます。その後、クラスタ構成の YAML ファイルでイメージ参照を提供します。
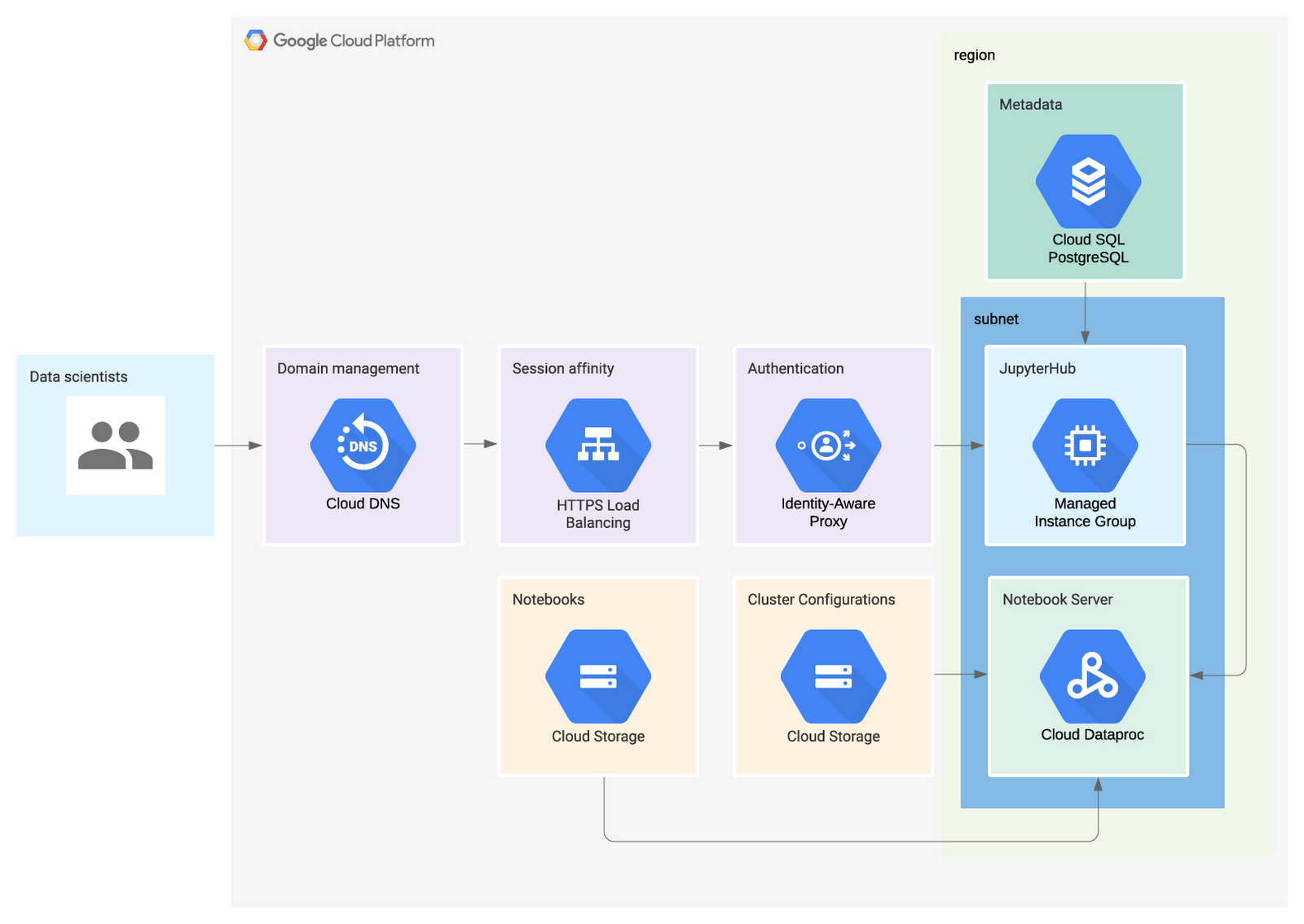
- Dataproc Hub の GitHub リポジトリを使用して Dataproc Hub を拡張します。このオプションでは、独自の Dataproc Hub のセットアップをマネージド インスタンス グループ上で実行します。AI Platform Notebooks でホストされているバージョンと似ていますが、カスタム DNS、Identity-Aware Proxy、フロントエンドの高可用性、内部エンドポイントのセットアップ オプションなど、追加のカスタマイズ機能が提供されます。
- AI Platform Notebooks 上の Dataproc Hub とマネージド インスタンス グループ上の拡張バージョンはいずれも、オープンソース化された同一の Dataproc Spawner を共有し、JupyterHub が基盤となっています。データ サイエンティストにさらなるオプションを提供するには、Dataproc Hub を拡張する際、これらのツールを構成してオプションを追加します。
- Dataproc Hub を拡張する場合は、Terraform を使って以下のアーキテクチャをセットアップする例が GitHub レポジトリにありますのでご覧ください。
次のステップ
- Dataproc 上でノートブック サーバーを生成する方法を習得するため、Dataproc Spawner についての理解を深める。
- Dataproc Hub のデプロイ方法と要件に応じたカスタマイズ方法を習得するため、GitHub で Dataproc Hub のサンプルコードについての理解を深める。
- Dataproc Hub のインスタンスをすばやく起動する方法を習得するため、Dataproc Hub のプロダクト ドキュメントを参照する。
- By ソリューション アーキテクト Matthieu Mayran

{kind=link}
{kind=link}