Volkswagen と Google Cloud、機械学習を利用して高エネルギー効率の自動車の設計を実現
Google Cloud Japan Team
※この投稿は米国時間 2022 年 9 月 28 日に、Google Cloud blog に投稿されたものの抄訳です。
Volkswagen は、美しく高性能でエネルギー効率の高い自動車のデザインに日々取り組んでいます。設計者は何度もデザイン案を作成して評価し、フィードバックを統合し、さらに洗練させるというプロセスを繰り返します。
たとえば、自動車の空気抵抗は、エネルギー効率を考えるうえで最も重要な要素の一つです。設計者は複数のデザインの抵抗係数を推定して実験を行い、よりエネルギー効率の高い解決策を導き出します。このフィードバックのループが低コストで高速であればあるほど、設計者の能力を発揮できます。
しかし、抵抗係数の推定には物理的な風洞実験や計算量の多いシミュレーションが必要で、高コストで時間のかかる作業であるという問題があります。これは、フィードバック サイクルのボトルネックになりうる問題です。
Volkswagen と Google Cloud は、この問題を解消すべく、機械学習(ML)を使用して、高速かつ低コストで抵抗係数を推定することを検討する共同研究プロジェクトを立ち上げました。今回の投稿では、このプロジェクトで直面した課題と実施したアプローチを紹介します。
プロジェクトの基本方針はシンプルでした。まず、既存の自動車のデザインとそれぞれの抵抗係数のデータセットを集めます。そして、さまざまな自動車の、機械学習に適したモデリングを作成します。次に、抵抗係数を予測するディープ ラーニング モデルを学習させ、最終的にそのモデルを使って、どんな新しいデザインでも抵抗を効率的に推定できるようにします。
自動車のデザインを 3 次元で表現する
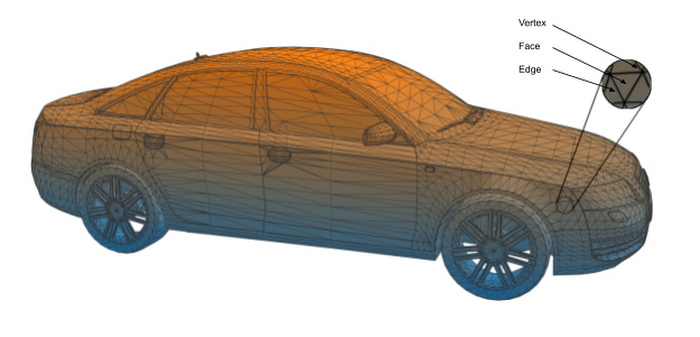
設計ソフトウェアは、物理的な物体を「面」「辺」「頂点」の 3 種類のオブジェクトで構成される 3 次元の三角形メッシュとして再現します。下の図 1 は、Audi S6 のメッシュを示したものです。「面」とは、自動車のドアの窓のような平らな面のことです。「辺」とは 2 つの面が接する部分(ドアの側面など)、頂点は 2 つ以上の辺が接する部分(ドアのコーナーなど)のことです。
とはいえ、自動車のボディはさまざまな形をしています。Volkswagen Golf の場合、エコノミー モデルと SUV の Tiguan では形が大きく異なります。また、1 台の自動車に大きく滑らかな面と繊細なデザインが施された形相の両方が存在します。そのため、ポリゴン メッシュの種類は非常に多くなります。
機械学習モデルは、しっかりと一般化されたルールを形成するために、一貫したモデリングが必要です。ポリゴン メッシュのばらつきが大きいと、モデルに欠陥が生じ、結果的に大きな誤差が生じる可能性があります。
ですから、自動車の形状を捉えつつ、機械学習モデルに適したシンプルなメッシュを作成する方法が必要でした。
デジタル シュリンク ラッピングで自動車をモデリングする
私たちは、各自動車のモデリングを一から作り上げるのではなく、3D メッシュに「シュリンク ラッピング(包装)」という手法を利用しました。この原理はキュウリの真空パックとよく似ています。キュウリをビニール袋に入れ、徐々に空気を抜いていくと、袋がキュウリを包み込むように形を変えていきます。
Google Cloud のアプローチも同様で、ビニール袋に相当する単純な形状のベースメッシュから始めて、ターゲット メッシュの形状になるまで変形させます。ベースメッシュは自動車を簡略化したもので、ターゲット メッシュはその時点でデザインしている特定の自動車のことです。このようなメッシュは、Tensorflow Graphics と trimesh ライブラリを用いた定義、管理、そして学習用の機械学習モデルに渡すことが可能です。
私たちの「シュリンク ラッピング」手法は、主に 2 つのメッシュ間の距離の尺度(面取り距離)を繰り返し最小化することで実現します。メッシュを標準化して、結果のメッシュの滑らかさなど特定の品質を保持することも可能です。この反復最適化は、つまりは真空ポンプであり、メッシュの頂点を徐々に縮め、自動車の複雑な形状にできるだけフィットさせるというものです。シュリンク ラッピングにより、よりきれいな、Google Cloud の推定タスクに適したメッシュを生成できます。このような手順の一例を図 2 に示します。

モデルの学習方法
自動車の 3D デザインについては、シュリンク ラッピングが重要な第一歩でしたが、他にも行うべき作業があります。次の課題は、機械学習アルゴリズムの構築とテストでした。
私たちは、新しいデザインを見るたびに、アルゴリズムでできるだけ正確かつ迅速に抵抗係数を推定できるようにしたいと考えていました。そのためには、既存のデータで機械学習モデルを学習させる必要がありました。
そこで私たちは、一般公開されているデータセットから、800 種類の自動車メッシュの抵抗係数を計算し、そのうえでモデルを学習させました。次に、トレーニング済みモデルをさらに 100 メッシュで評価し、新しいデータに対してどの程度の精度で推定できるかを確認しました。
このトレーニングに取り組みながら、私たちはアプローチに磨きをかけていきました。当初は、各メッシュの頂点、すなわち固定点のみを観測する、PointNet と同様の畳み込みニューラル ネットワークに基づくモデルをテストしていました。しかし、FeastNet と同様のメッシュ畳み込みモデルを検証したところ、着目点を少し変えるだけで推定精度が向上することがわかりました。このモデルでは、頂点だけに注目するのではなく、メッシュ状になった頂点と、頂点がどのように関係しているかを見ています。各頂点がより情報量の多いコンテキストで配置され、特に微妙なデザインの形相に対する気流を、より正確に推定できるようになりました。
並列処理とスケールアップ
私たちは、時差や組織を超えてコラボレーションするために、Google Cloud Vertex AI プラットフォームを活用しました。
Vertex AI Workbench は、Vertex AI プラットフォーム上の他のサービスやインフラストラクチャとインタラクションするための中心的なハブとして機能します。リソースが必要な機械学習モデルのトレーニング ジョブに使用するトレーニング パッケージのテストや準備が可能で、Python ノートブック環境ですぐにコードを実行することができます。ノートブック環境では、Google Cloud 上の他のサービスや Vertex AI Training、Vertex AI Pipelines などの機械学習ツールと、コードベースのやり取りが可能です。
新しいモデルのトレーニングは、シームレスなプロセスで行われます。まず、データセットを用意し、Google Cloud Storage に保存します。通常は、Tensorflow Datasets を使用します。そして、テストしたい機械学習モデルごとに、Google Cloud Build と Container Registry を使って、トレーニング コードをコンテナ イメージとしてパッケージ化し、保存します。これにより、すべてのジョブが、提供されたパラメータ、トレーニング コード パッケージ、トレーニング タスクのログ、指標やモデルファイルなどの結果の成果物を含めて、完全にドキュメント化されます。
そこから、Vertex AI Training サービスにモデルを投入します。このサービスは、ジョブ投入時にリソースの必要性を定義するだけで、大規模インフラストラクチャや GPU や TPU などのハードウェア アクセラレータに簡単にアクセスできるサービスです。Vertex AI Training のハイパーパラメータ チューニング機能を使えば、複数のニューラル ネットワークで並行して実験を行い、目的に合ったものを見つけることができます。
Vertex AI Tensorboard を使えば、指標を取得し、実験結果を可視化できます。チームの誰もが、世界のどこからでもすぐにこの結果を利用して、より広範な議論を行うことができます。
最初のマイルストーン
Volkswagen と Google の共同研究は、Vertex AI プラットフォームの力を活かして、有望な結果を生み出しています。この最初のマイルストーンでは、私たちは最近の AI 研究の成果を、自動車のデザインという実用化に一歩近づけることに成功しました。このアルゴリズムは、最初の反復処理で平均誤差わずか 4% の抵抗係数の推定値を 1 秒以内に生成できます。
平均 4% の誤差は、物理的な風洞試験ほど正確ではありません。しかし、多数のデザイン候補を小さく絞り込むことは可能です。また、推定がすぐに出るというのは、数日、数週間かかる既存の方法よりも大きな進歩です。私たちが開発したアルゴリズムにより、設計者はより多くの効率テストを実行し、より多くの候補を出し、より優れた、効果的なデザインに向けた反復処理を行えるようになりました。従来と比較して、それにかかる時間はほんのわずかです。
今後、より早くより正確な推定が実現すれば、効率的なデザインを自動で探し出すことが可能になり、エンジニアと設計者双方が車体の中で最も影響のある部分に集中できるようになると思われます。次のステップとして重要なのは、この結果を 3 次元設計ソフトウェアに組み込んで、設計者がその成果を活用し、フィードバックできるようにすることです。
今後は、モデルの精度を高めることにフォーカスします。まず、より大規模で質の高いデータセットを構築し、次に、シュリンク ラッピング アルゴリズムを改良して、より詳細な情報を取得できるようにします。最後に Vertex AI Neural Architecture Search を使って、さまざまなニューラル アーキテクチャのオプションを探索・テストして、既存のモデルを強化します。
私たちは、今回の抵抗係数の推定結果は、さらなる探求の出発点に過ぎず、物理シミュレーションや評価の分野では、機械学習ベース推定によって費用や時間を削減できるユースケースが多数存在する可能性がある、と考えています。
謝辞
この研究は、Volkswagen Data:Lab、Google Research、Google Cloud の貢献のもとに実現しました。Volkswagen の Ahmed Ayyad 氏、Andrii Kleshchonok 博士、Daniel Weimer 博士、Gülce Cesur 氏、Henrik Bohlke 氏、Andreas Müller 氏、Google Research の Ameesh Makadia 博士、Carlos Esteves 博士、Google Cloud の Daniel Holgate, Holger Speh、Michael Menzel 博士に感謝いたします。
- Volkswagen、データ サイエンティスト Ahmad Ayad 氏、Henrik Bohlke 氏
- Google Cloud、ML スペシャリスト カスタマー エンジニア Michael Menzel 博士