Vertex AI の Streaming Ingestion でリアルタイム AI を実現
Google Cloud Japan Team
※この投稿は米国時間 2022 年 9 月 21 日に、Google Cloud blog に投稿されたものの抄訳です。
不正行為の検出、広告のターゲット設定、レコメンデーション エンジンをはじめ、数多くの機械学習(ML)のユースケースには、ほぼリアルタイムの予測が必要です。こうした予測のパフォーマンスは、最新データへのアクセスに大きく依存しており、数秒の遅れでも少なからぬ影響につながります。とはいえ、高スループットの更新と低レイテンシのデータ取得に必要なインフラストラクチャを準備するのは容易ではありません。
今月から、Vertex AI Matching Engine と Feature Store はリアルタイムのストリーミング取り込み機能、Streaming Ingestion の Preview 版を提供開始します。Matching Engine はベクトル検索用のフルマネージド ベクトル データベースであり、Streaming Ingestion の利用によりインデックス内のアイテムの継続的な更新と検索結果への即時の反映が可能となります。また Feature Store の Streaming Ingestion を使用すると、最新の特徴量をリアルタイムに取り込み、つねに最新の特徴量を低遅延での推論やバッチ学習等に提供できます。
一例として、Digits は Vertex AI Matching Engine の Streaming Ingestion を利用して、自社プロダクトである Boost の強化に役立てています。Boost は会計データの品質管理の作業を自動化し、会計士の生産性を高めるツールです。「Vertex AI Matching Engine の Streaming Ingestion のおかげで、Digits Boost の各機能と分析サービスをリアルタイムに提供可能となりました。Matching Engine が登場する前、取引データは 24 時間単位の定期バッチで分類処理されていました。Streaming Ingestion の導入により、ほぼリアルタイムの増分インデックス更新(既存のインデックスに対する特徴ベクトルの挿入、更新、削除など)が可能になり、分類処理を大幅に高速化できました。今では、より多くの取引データをより迅速に処理でき、即座にお客様にフィードバックを提供可能になりました」(Digits の機械学習エンジニア、Hannes Hapke 氏)
以下では、レコメンデーション、コンテンツのパーソナライズ、サイバーセキュリティのモニタリングなど、Strearming Ingestion が実現する様々なリアルタイム AI のユースケースについて説明します。

Streaming Ingestion でリアルタイム AI を実現
いま、より多くの企業が「データの新鮮さ」のビジネスにもたらすメリットに注目し、「リアルタイム AI」を実装するケースが増えています。次に例を示します。
リアルタイムのレコメンデーションとマーケットプレイス: メルカリでは、既存の Matching Engine ベースの商品レコメンデーションに対して Streaming Ingestion によるリアルタイム機能の追加を検討しています。これにより実現されるリアルタイム マーケットプレイスでは、ユーザーが特定の興味に基づいて商品をブラウジングしている際に、販売者が新しい商品を追加すると即座に検索結果に反映されます。あたかも市場で買い物をしていると新しい野菜や果物が運ばれてくるようなエクスペリエンスが実現します。また Matching Engine のフィルタリング機能を組み合わせることで、「オンライン / オフライン」や「在庫あり / 在庫なし」などのタグに基づいてアイテムを検索結果に含めるかどうかを指定できます。

パーソナライズされたコンテンツの大規模なストリーミング: テキストや画像、ドキュメント等のコンテンツのストリームを扱うサービスでは、それらの特徴ベクトルを集める PubSub チャネルを設計して、個々のユーザーの興味や関心に合わせて最適なコンテンツを配信できます。Matching Engine はスケーラブルなベクトル検索サービスであるため、毎秒何 10 万ものクエリを処理可能です。コンテンツ ストリーミング用に数 100 万規模のオンラインユーザーをサポートし、動的に変化するさまざまなトピックの配信基盤を構築できます。Matching Engine のフィルタリング機能を使用すると、各オブジェクトに「不適切な表現」や「スパム」などのタグを割り当てて、配信すべきコンテンツをリアルタイムに判断することもできます。また Feature Store は、コンテンツの特徴ベクトルをほぼリアルタイムで保存、提供するリポジトリとして使用できます。
モニタリング: 上述の仕組みは、IT インフラストラクチャ、IoT デバイス、製造業の生産ライン、セキュリティ システムなどの商用ユースケースからのイベントやシグナルをモニタリングするためにも使用できます。たとえば、何 100 万個ものセンサーやデバイスからシグナルを特徴ベクトルとして抽出し、Feature Store に保存できます。さらに Matching Engine を使用すると、例えば「欠陥の可能性がある上位 100 個のデバイスリスト」や「外れ値のある上位 100 個のセンサー イベント」といったリストをほぼリアルタイムで継続的に更新できます。
セキュリティ脅威 / スパムの検出: セキュリティ脅威やスパム行為のパターンによるシグナルをモニタリングしているケースでは、数 100 万のモニタリング ポイントについてのセキュリティリスクやスパムの可能性を Matching Engine で瞬時に検出できます。一方、バッチ処理に基づくセキュリティ脅威の識別は大きな遅延を伴うため、脆弱性への対処に時間がかかってしまいます。リアルタイム データなら、企業ネットワーク、ウェブサービス、オンライン ゲーム等で発生する脅威やスパムを、より迅速に検出できます。
ストリーミング ユースケースの実装
このようなユースケースを実装する方法について詳しく見てみましょう。
小売業向けのリアルタイムのレコメンデーション
メルカリは、 Streaming Ingestion のための特徴抽出パイプラインを構築、評価しています。
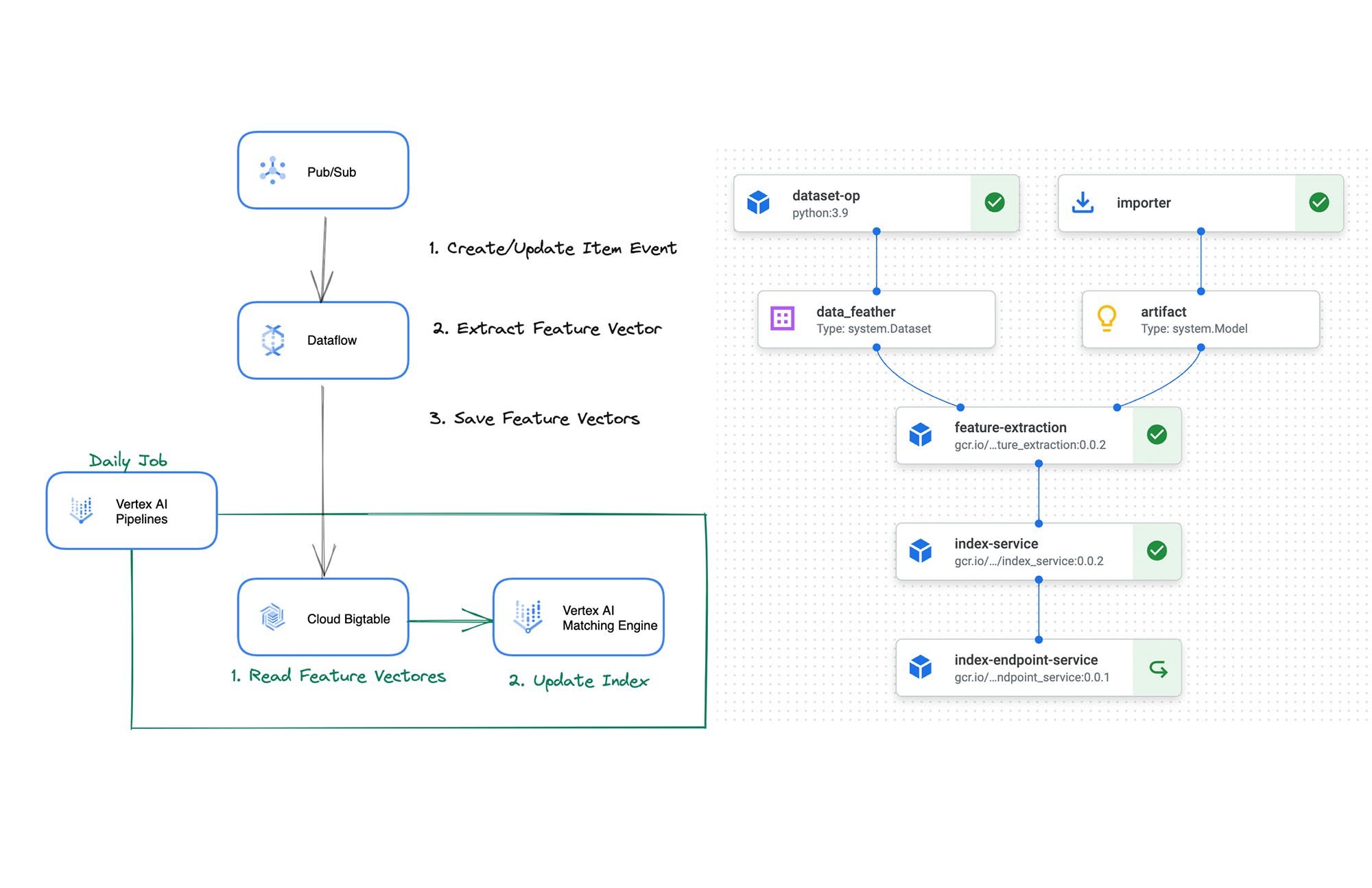
このパイプラインは Vertex AI Pipelines で定義されており、Cloud Scheduler と Cloud Functions によって定期的に呼び出されて以下の処理を開始します。
アイテムデータの取得: パイプラインは、更新されたアイテムデータを BigQuery から取得するためにクエリを発行する。
特徴ベクトルの抽出: パイプラインは、word2vec モデルでデータに対して予測を行い、特徴ベクトルを抽出する。
インデックスの更新: パイプラインは、Matching Engine API を呼び出し、特徴ベクトルをベクトル インデックスに追加する。ベクトルは Cloud Bigtable にも保存される(今後 Feature Store にも置き換え可能)。
「これまで Matching Engine Streaming Ingestion を評価してきましたが、インデックス更新の遅延の低さを初めて目にしたときは信じられませんでした。この機能の一般提供が開始されたらすぐに本番環境サービスへの導入を検討したいと考えています」(株式会社ソウゾウのソフトウェア エンジニア、野上和加奈氏)
このアーキテクチャは、商品のレコメンデーションをリアルタイムで更新する必要がある様々な小売業に適用できます。
広告ターゲティング
広告のレコメンデーション システムでは、最新データとのリアルタイム マッチングにより多大なメリットが得られます。Vertex AI がリアルタイムの広告ターゲティングシステムの構築にどのように役立つかを見てみましょう。
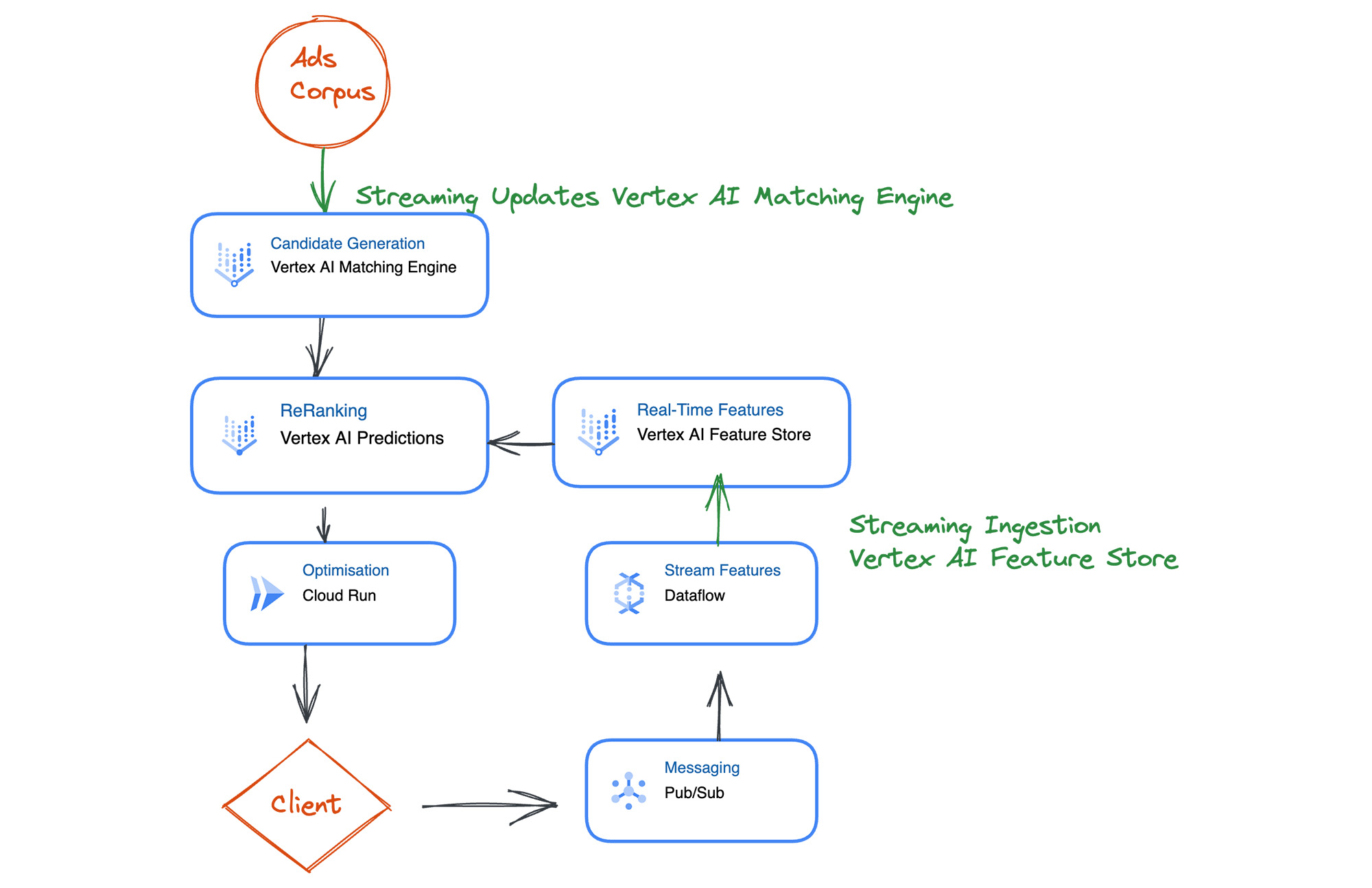
広告レコメンデーションを行うには、まず、広告コーパスから一連の候補を生成します。適切な候補をミリ秒単位で生成し、最新状態に保たなくてはならないため、この処理には困難が伴います。このとき Vertex AI Matching Engine を使用すれば、ミリ秒単位の低遅延のベクトル検索を毎秒数 10 万回の規模で実行し、適切な候補を選択できます。また Streaming Ingestion によりインデックスを継続的に更新できるため、つねに最新の広告が候補に含まれる状態を維持できます。
また得られた候補について、さらに ML モデルによる再ランキングを実施し、広告候補の適切な順序を決定します。ここで Feature Store の Streaming Ingestion を利用することで、最新の特徴量を継続的に収集しながらオンライン サービングによりミリ秒単位で特徴量を取り出せ、再ランキングのための高速な推論を支援します。
再ランキングの後は、最新のビジネス ロジックを適用するなどの仕上げの最適化を適用できます。Cloud Functions や Cloud Run を使用してこの最適化手順を実装できます。
次のステップ
いかがでしたか。Streaming Ingestion はすでにドキュメントが公開されており、簡単に試すことができます。たとえば、Matching Engine で REST API を使用してインデックスを作成する場合、indexUpdateMethod 属性に STREAM_UPDATE を指定します。
インデックスのデプロイ後、次の形式で特徴ベクトルのインデックスを更新または再構築できます。データポイント ID がインデックスに登録済みの場合はデータポイントが更新され、未登録の場合は新しいデータポイントが挿入されます。
データポイントの挿入 / 更新を高スループットかつ低遅延で処理できます。新しいデータポイントの値は、数秒または数ミリ秒以内に新しいクエリに適用されます(この遅延はさまざまな条件によって変化します)。
Streaming Ingestion は強力でありながら、とても使いやすい機能となっています。独自のストリーミング データ パイプラインを構築して運用することなくリアルタイムのインデックス作成と保存が可能で、リアルタイムの応答性によりビジネスに大きな価値をもたらします。
Matching Engine と Feature Store の概念やユースケースについて詳しくは、次のブログ投稿をご覧ください。
- Google Cloud デベロッパー アドボケイト Erwin Huizenga
- Google Cloud デベロッパー アドボケイト Kaz Sato



