Vertex Feature Store で特徴量管理の MLOps はこう変わる
Google Cloud Japan Team
※この投稿は米国時間 2021 年 7 月 21 日に、Google Cloud blog に投稿されたものの抄訳です。
データ サイエンティストが費やす時間の 7 割以上はデータとの格闘に充てられている、という声をお客様からよく伺います。具体的には、生のデータを機械学習(ML)モデルのための高品質な特徴量データに変換する特徴量エンジニアリングや、それを本番環境に確実にデプロイする工程に時間が費やされています。しかしながら、このプロセスが非効率で融通が利かない場合が多々あります。
ML の特徴量を取り扱う上で、よく直面する 3 つの重要な課題があります。
共有と再利用が難しい
本番環境で求められる高信頼・低遅延の特徴量サービングの実装が難しい
トレーニング時とサービング時で特徴量に意図しないスキュー(ずれ)が生じる
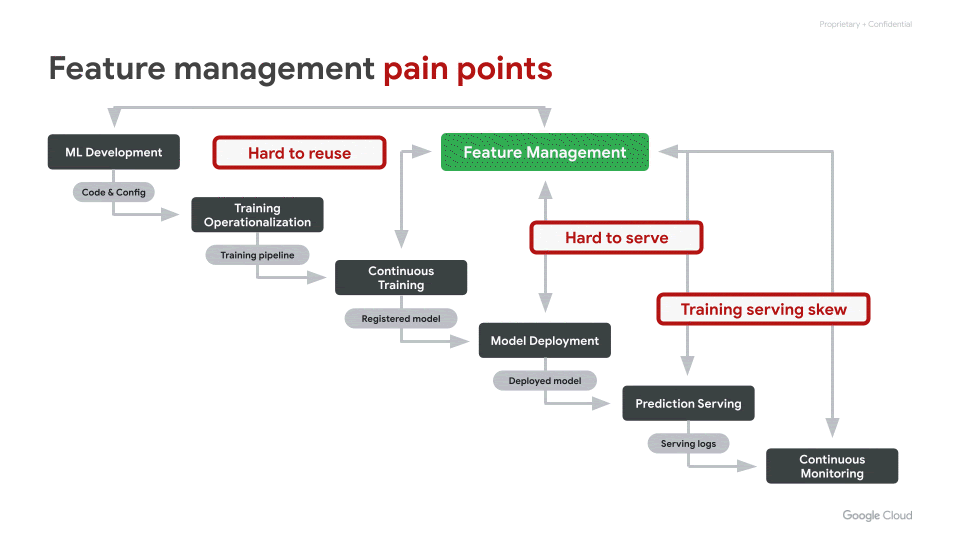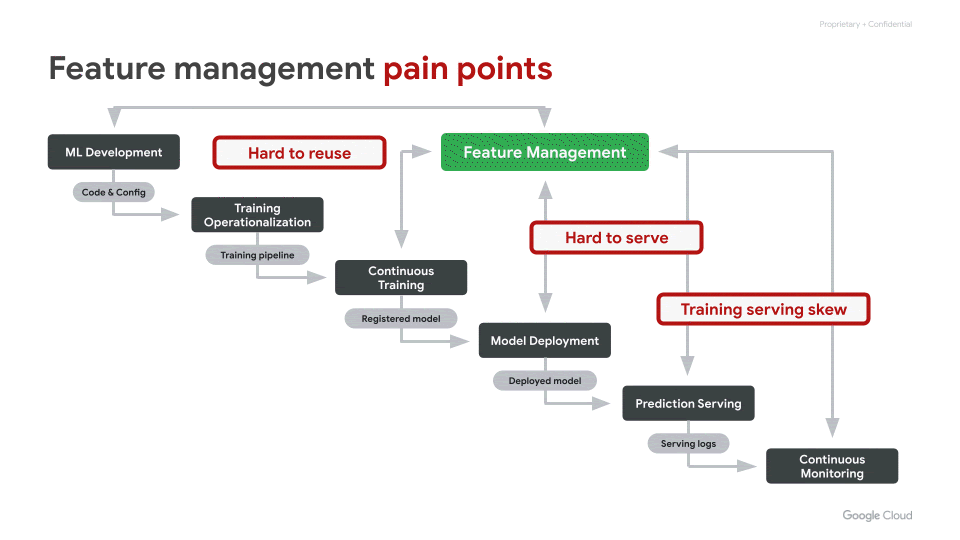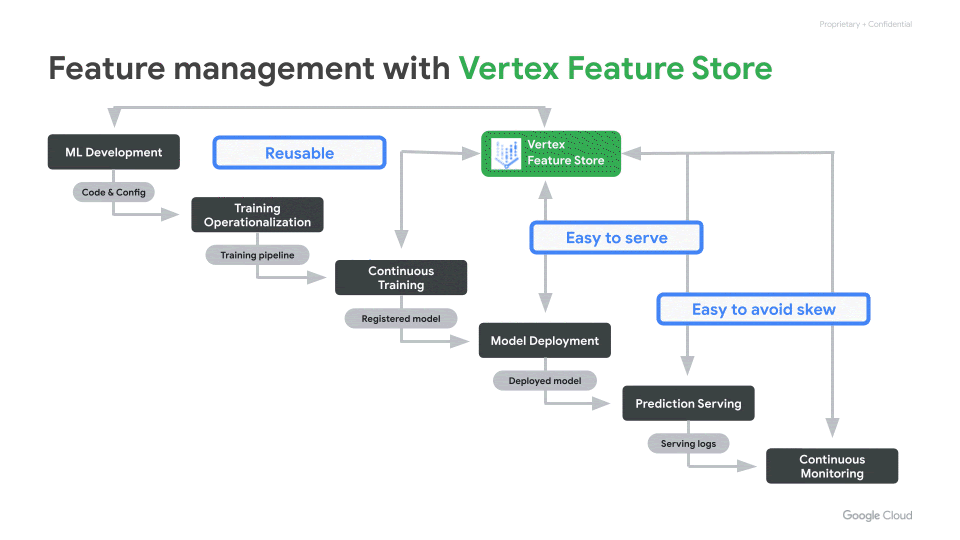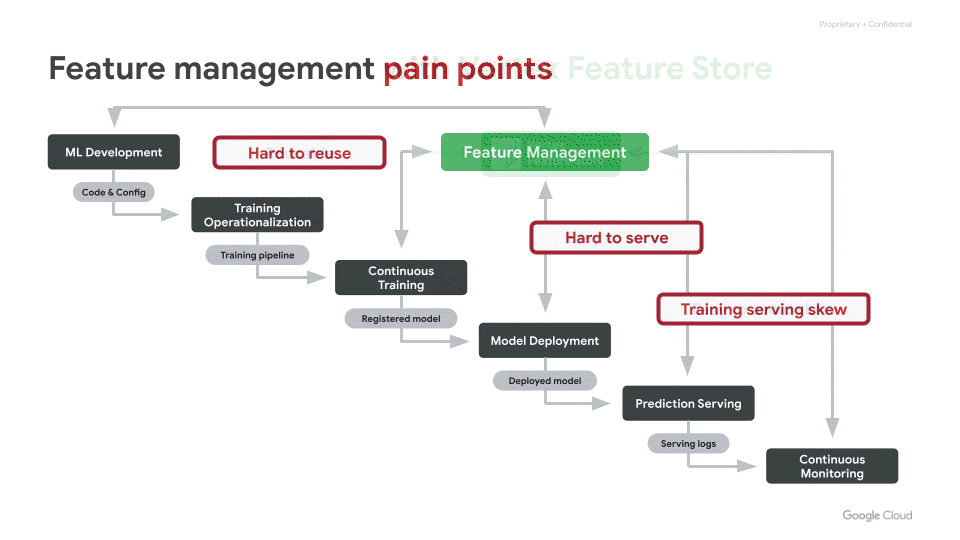
このブログ投稿では、最近リリースされた Vertex Feature Store を利用することで、上述の課題にどのように対処できるのかを説明します。Vertex Feature Store は、ML の特徴量の管理と整理を容易にすることで、企業が AI / ML アプリケーションを構築およびデプロイするのに要する時間を短縮します。組織内の異なるチーム間で特徴量を大規模に共有、検索しサービングに利用するためのフルマネージド統合ソリューションです。
簡単で使いやすい特徴量管理サービス
以下の概要図に示されているように、Vertex Feature Store の内部は、ストレージ システムとコンポーネントの組み合わせで構成されています。これらの複雑な下位層を抽象化したシンプルな API とSDK を備えたマネージド ソリューションを提供します。

主な API は次のとおりです。
計算済みの特徴量を取り込むための Batch Import API(近日中に Streaming Import API の提供も開始される予定です)。ユーザーがこの API を介して特徴量を取り込むと、データはオフライン ストアとオンライン ストアの両方に確実に書き込まれます。オフライン ストアでは特徴量が長期間にわたって保持されるため、後でトレーニングのために取得できます。オンライン ストアには、オンライン予測の最新の特徴量が含まれます。
オンライン ストアから最新の特徴量を低レイテンシで提供する Online Serving API。この API は、クライアント アプリケーションが特徴量を取得して、オンライン予測を実行するために使用されます。
モデルのトレーニングやバッチ予測の実行のために、オフライン ストアからデータを取得する Batch Serving API。この API は、トレーニングに適した特徴量を取得するために、「Point-in-time 検索」を実行します。この機能については、本稿の後半で詳しくご説明します。
それでは、Feature Store が上で述べた 3 つの課題にどのように対処するのかを詳しく見ていきましょう。
特徴の検索、共有、再利用を簡単にする
冗長さの低減: 企業の規模が大きいと、機械学習のユースケースが異なる場合でも、モデルへの入力として同じの特徴量が使用されるのケースが多々あります。Feature Store がない場合、たとえ同じ特徴量であっても、各チームは特徴量エンジニアリングのためのパイプラインをそれぞれ独自に開発して運用する必要に迫られます。これは生産性を低下させる冗長な作業です。
特徴量エンジニアリングの効用を最大限に引き出す: 洗練された高品質な特徴量を作成するには、高い創造性と努力が必要です。質の高い特徴量があれば、さまざまな用途で高い効果を発揮できます。その価値十分に活用できないと、企業にとっては機会損失となります。特徴量を異なるチーム間で簡単に共有し、検索したり再利用できるようにすることが重要です。
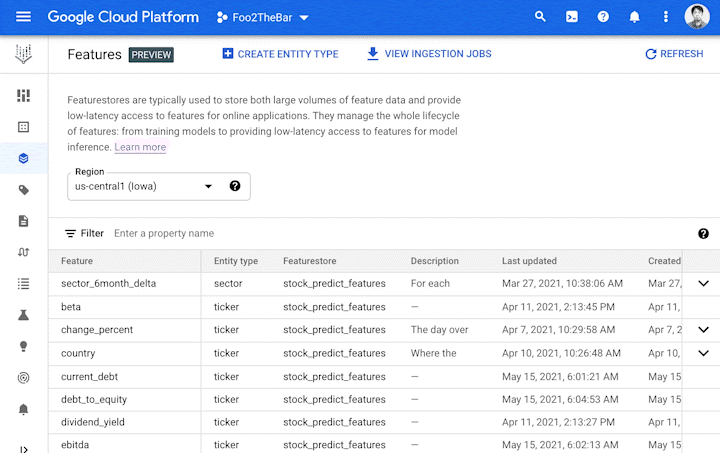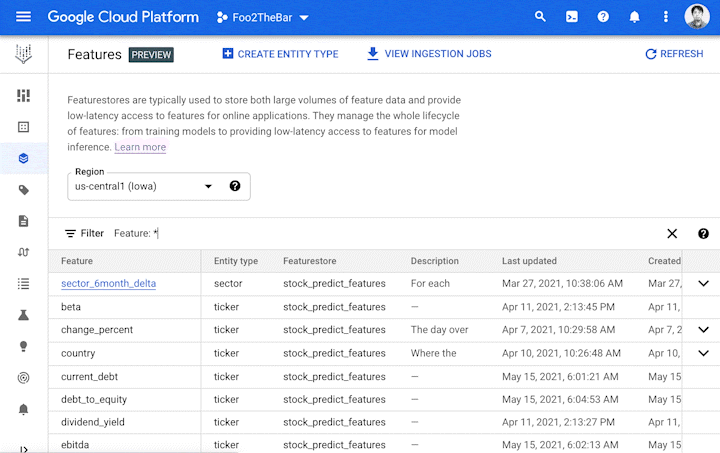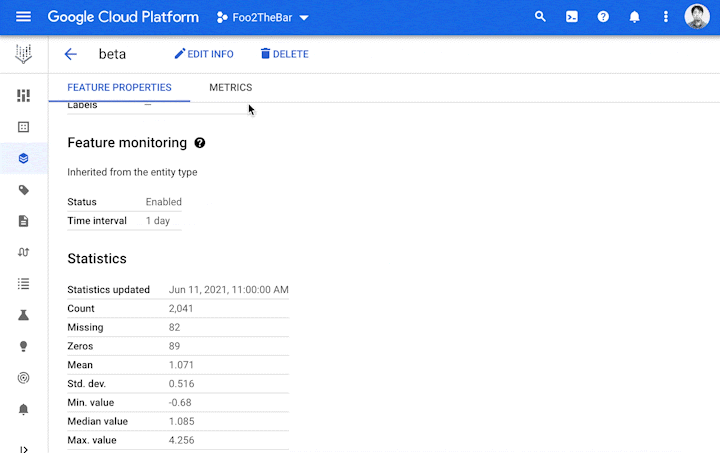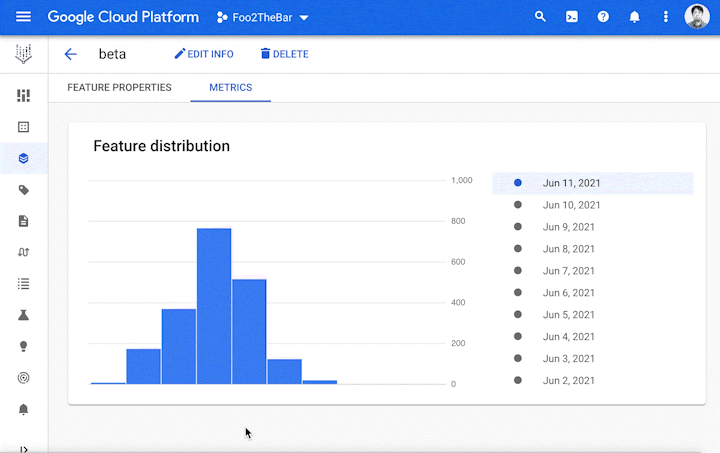
Vertex Feature Store は、企業全体で共有される特徴量のリポジトリとして機能し、既存の特徴量を検索するための分かりやすい UI と API を備えます。また、特徴量のグループに対して適切な権限を設定し、特徴量へのアクセス制御も可能です。
ここで重要となるのが、「信頼性の高い特徴量をどうやって見つけるか」という点です。そこで Vertex Feature Store では特徴量の品質情報を共有するための指標を提供します。たとえば、特徴量の分布、更新頻度、他のチームによる参照の頻度を示す指標などで検索が可能です。
本番環境での特徴量のサービングを容易に
ML モデルによる予測を低レイテンシでリアルタイムに提供できるオンライン サービング環境を用意することで、ML活用の幅がぐんと広がります。Vertex Prediction サービスの利用により、ML モデルを 高い可用性と信頼性を備えた HTTP または RPC エンドポイントとして大規模かつ簡単にデプロイできます。ただし、こうしたオンライン サービング環境では、モデルをデプロイするだけでなく、モデルに入力する特徴量を低レイテンシで取得する必要があります。
多くの企業では、新しい特徴量の作成はデータ サイエンティストが担当し、そのサービング環境の構築は運用チームやエンジニアリング チームが担当するという役割分担が行われています。このためデータ サイエンティストは、自分が作った特徴量を本番環境でデプロイする際に他のチームに依存することになります。しかしこの依存関係は、望ましくないボトルネックの原因となります。データ サイエンティストは、特徴量のライフサイクル全体を管理したいと考えるものです。新しい特徴量をすばやく作成してデプロイできる自由とアジリティを求めるでしょう。
Vertex Feature Store は、特徴量のオンライン サービングをスケーラブルかつ低レイテンシで行うための、使いやすいフルマネージド ソリューションを提供することで、データ サイエンティストにこの自由とアジリティを提供します。Import API を使用するだけで新しい特徴量を Feature Store に取り込むことができ、取り込み後すぐにオンライン サービングが可能になります。
Training-serving skew を軽減する
実際の ML アプリケーションでは、オフラインのテストではうまく機能していたモデルでも、本番環境にデプロイすると期待通りに機能しないという状況に陥ることがあります。この状況は Training-serving skew と呼ばれます。ML モデルの Training-serving skew 発生にはさまざまな原因がありますが、その多くはつまるところ、トレーニング時にモデルに提供される特徴量と、予測時に提供される特徴量との間のスキュー(ずれ)です。
Google には、 Training-serving skew を避けるため、「サービング環境と同じやり方でトレーニングする」という経験則があります。

Training-serving skew を軽減するためのルール
(機械学習のルールより)
トレーニング時の特徴量とサービング時の特徴量の不一致は、おもに次の 3 つの問題によって生じます。
A. トレーニング用とサービング用の特徴量を生成するためのコードや実装方法が異なる。異なる実装が存在する場合、意図しない偏りが入り込んでしまう可能性があります。
B. モデルがトレーニングされてから最終的に本番環境で使用されるまでに元データが変化する。これはデータドリフトと呼ばれ、運用期間の長いモデルでしばしば発生します。
C. モデルとアルゴリズム間にフィードバック ループが生じる。データリークやターゲットリークとも呼ばれます。この現象の詳細については、次の 2 つのリンクをご確認ください。
a. https://www.kaggle.com/dansbecker/data-leakage
では、Vertex Feature Store がこれら 3 つの問題にどのように対処しているのかを見ていきましょう。
特徴量が Vertex Feature Store に一度取り込まれると、トレーニングとサービングの両方に再利用されます。これにより、(A)の発生を回避できます。特徴量は全体を通して 1 回しか計算されないため、異なる実装による値の不一致を回避できます。
(B)については、Feature Store に取り込まれた特徴量の分布を常に監視することで、特徴量がドリフトし始めるタイミングや、時間経過に伴う分布変化のタイミングをユーザーが把握できます。
(C)については、トレーニングにおける特徴量の「Point-in-time 検索」により対処します。これについては、以下で詳しく説明します。基本的には、ラベルのタイムスタンプ以前に得られた特徴量のみを用いてトレーニングすることで、データリークに対処します。先に挙げたデータリークに関するリンクで説明されているように、トレーニングに用いるラベルが作られたタイムスタンプより後に生成された情報は、トレーニングに利用するべきではありません。結局、それは事実上、未来の「のぞき見」になってしまうからです。
データリークを防ぐ Point-in-time 検索
ML モデルのトレーニングでは、予測の例を含むトレーニング データセットを用います。このデータは、特徴量とラベルを含むデータで構成されています。たとえば、あるデータが住宅を表し、その市場価値が知りたいとします。その特徴量には、立地条件、築年数、付近の住宅の実売価格などが含まれるでしょう。ラベルは、その住宅は最終的に $100,000 で販売されます、といった予測の答えになりす。
個々のラベルは特定の時点での観測情報となるため、観測が行われた時点での対応する特徴量(特定の住宅が販売されたときの周辺にある住宅の価格など)を取得する必要があります。こうしてラベルと特徴量収集を続けていくと、そうした特徴量の内容は変化していきます。この変化によるデータリークを防ぐため、モデルのトレーニング時に Feature Store からデータを取得する際には、Point-in-time 検索を実行し、各ラベルが観測された時点に対応する特徴量を取得します。注目すべき点は、トレーニング データセットに数千万件のラベルがある場合でも、Feature Store がこれらの Point-in-time 検索を高速に実行できることです。
次の例では、ラベル L1 と L2 に対する 2 つのトレーニング で用いる特徴量を取得します。2 つのラベルは、それぞれ T1 と T2 の時点で観測されます。それらの時刻に特徴量の状態を凍結させたと考えてください。こうして、T1 時点での Point-in-time 検索では、Vertex Feature Store により T1 時点までの特徴量 1、特徴量 2、特徴量 3 の最新の特徴量が返され、T1 より後の値はリークしません。特徴量は時間の経過とともに変化し、それによってラベルも変化します。したがって、T2 の時点では、その時点での異なる特徴量が Vertex Feature Store から返されます。

AI / ML 開発にはずみをつける Feature Store
豊富な特徴量を集約したリポジトリを構築することで、企業における ML アプリケーションの構築とデプロイにかかる時間と費用を大幅に削減でき、優れた「はずみ車」の効果を生み出します。Vertex Feature Store の利用により、データ サイエンティストは一から作業を始める必要がなく、以前のアプリケーション用に作成された特徴量を検索して再利用することで、新しい ML アプリケーションをより迅速に構築できます。さらに、Vertex Feature Store は、新たに作成された各特徴量の費用対効果を最大化して企業全体に利益をもたらし、後続のアプリケーション開発をさらに高速化することで、好循環を生み出すはずみ車としての価値を発揮します。
まずはプロダクト ドキュメントのチュートリアルとスタートガイド サンプルに沿って、この効果を体感してください。
-Cloud AI Platform プロダクト マネージャー Anand Iyer
-Google Cloud デベロッパー アドボケイト Kaz Sato



