Kickstart your organization’s ML application development flywheel with the Vertex Feature Store
Anand Iyer
Group Product Manager, Google Cloud
Kaz Sato
Developer Advocate, Cloud AI
Try Google Cloud
Start building on Google Cloud with $300 in free credits and 20+ always free products.
Free trialWe often hear from our customers that over 70% of the time spent by Data Scientists goes into wrangling data. More specifically, the time is spent in feature engineering -- the transformation of raw data into high quality input signals for machine learning (ML) models -- and in reliably deploying these ML features in production. However, today, this process is often inefficient and brittle.
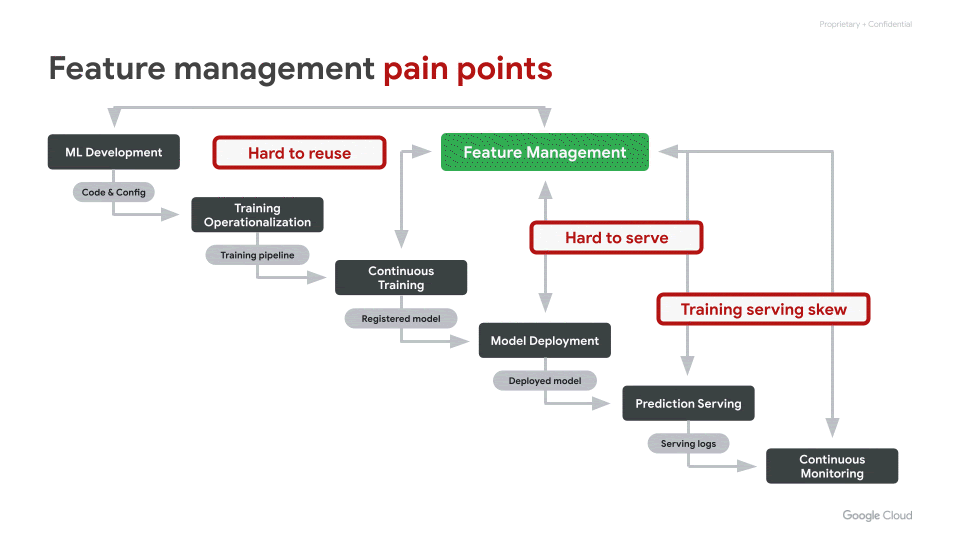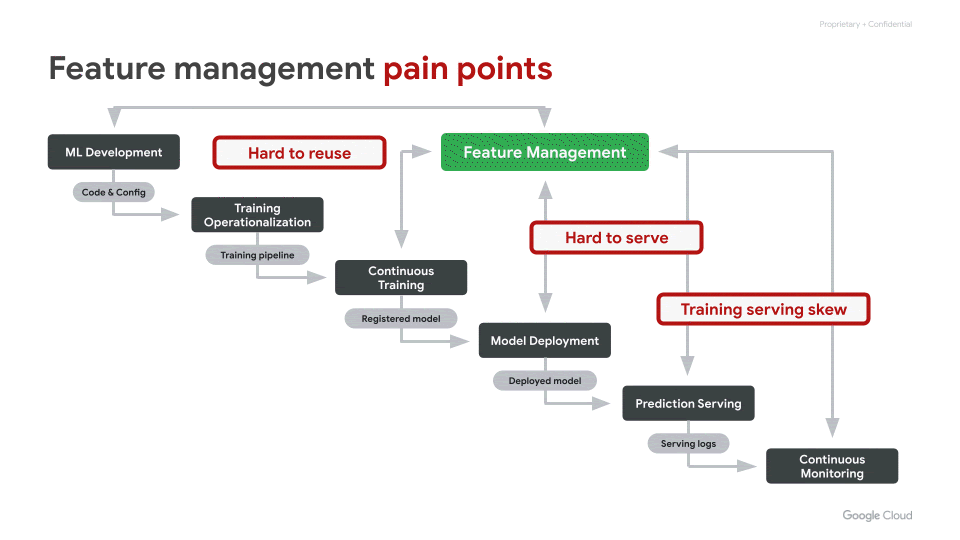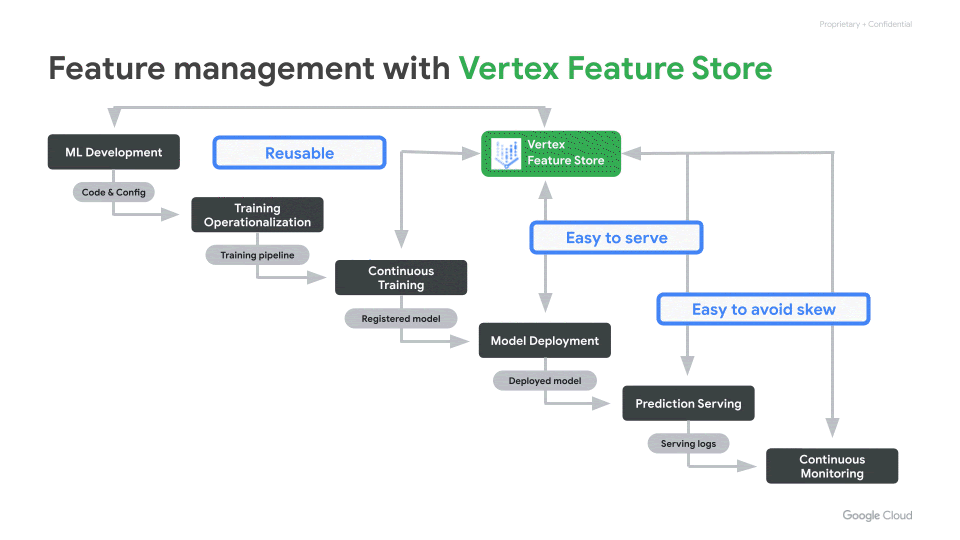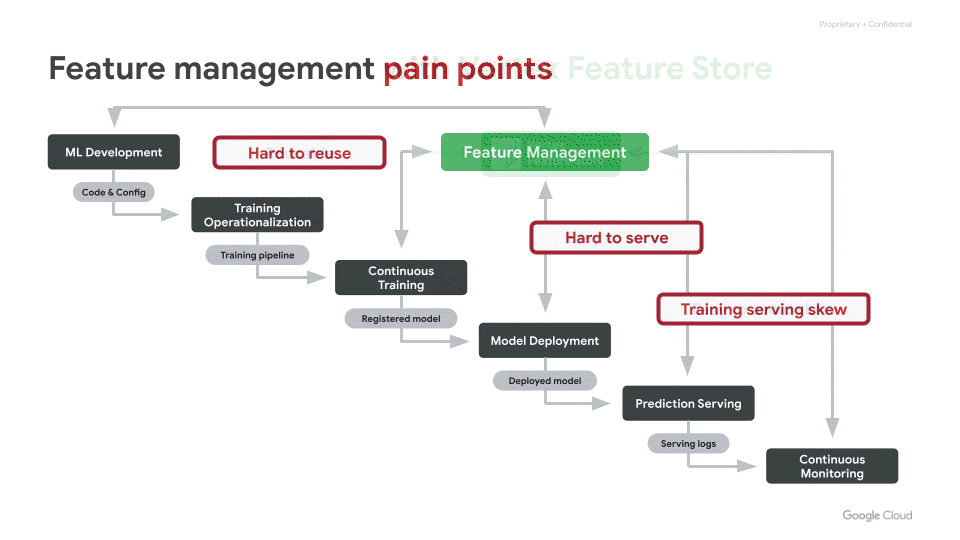
There are three key challenges with regards to ML features that come up often:
- Hard to share and reuse
- Hard to serve in production, reliably with low latency
- Inadvertent skew in feature values between training and serving
In this blog post, we explain how the recently launched Vertex Feature Store helps address the above challenges. It helps enterprises reduce the time to build and deploy AI/ML applications by making it easy to manage and organize ML features. It is a fully managed and unified solution to share, discover, and serve ML features at scale, across different teams within an organization.
Vertex Feature Store solves the feature management problems
Simple and easy to use
As illustrated in the overview diagram below, Vertex Feature Store uses a combination of storage systems and components under the hood. However, our goal is to abstract away the underlying complexity and deliver a managed solution that exposes a few simple APIs and corresponding SDKs.

High level animated illustration of the Feature Store
The key APIs are:
- Batch Import API to ingest computed feature values. We will soon be launching a Streaming Import API as well. When a user ingests feature values via an ingestion API, the data is reliably written both to an offline store and to an online store. The offline store will retain feature values for a long duration of time, so that they can later be retrieved for training. The online store will contain the latest feature values for online predictions.
- Online Serving API to serve the latest feature values from the online store, with low latency. This API will be used by client applications to fetch feature values to perform online predictions.
- Batch Serving API to fetch data from the offline store, for training a model or for performing batch predictions. To fetch the appropriate feature values for training, the Batch Serving API performs “point-in-time lookups”, which are described in more detail below.
Now lets do a deeper dive into how the Feature Store addresses the three challenges mentioned above.
Making it easy to discover, share, and re-use features
Reducing redundancy: Within a broader organization, it is common for different machine learning use cases to have some identical features as inputs to their models. In the absence of a feature store, each team invariably does the work of authoring and maintaining their own feature engineering pipelines, even for the identical features. This is redundant work, reducing productivity, that can be avoided.
Maximizing the impact of feature engineering efforts: Coming up with sophisticated high quality features entails non-trivial creativity and effort. A high quality feature can often add value across many diverse use cases. However, when the feature goes underutilized, it is a lost opportunity for the organization. Hence, it is important to make it easy for different teams to share and re-use their ML features.
Vertex Feature Store can serve as a shared feature repository for the entire organization. It provides an intuitive UI and APIs to search and discover existing features. Access to the features can also be controlled by setting appropriate permissions over groups of features.
Discovery without trust is not very useful. Hence, Vertex Feature Store provides metrics that convey information about the quality of the features, such as: What is the distribution of the feature values? How often are a particular feature’s values updated? How widely is the feature consumed by other teams?
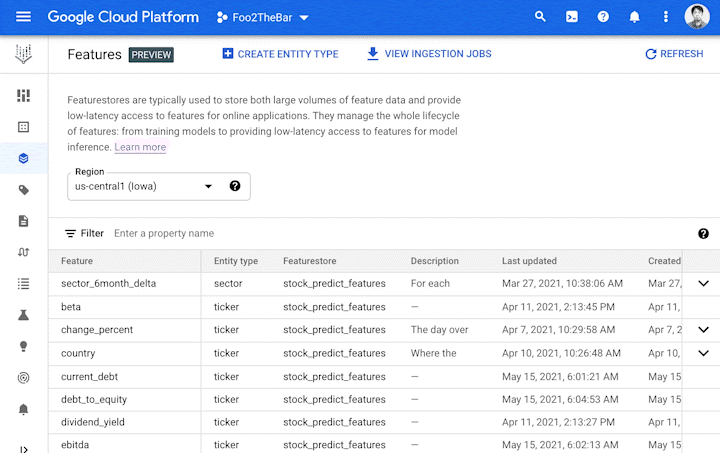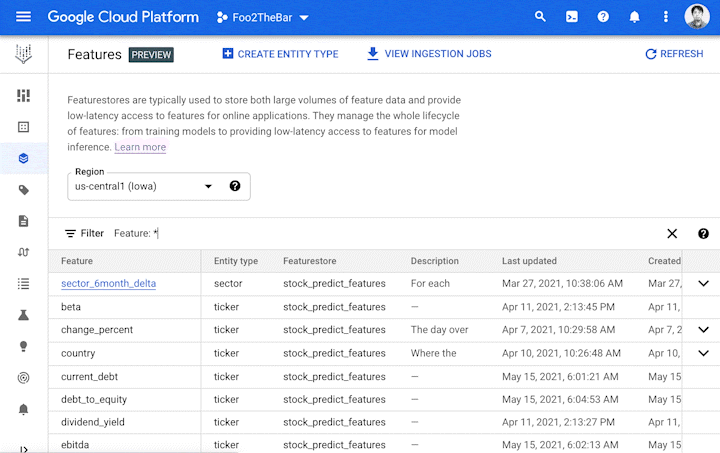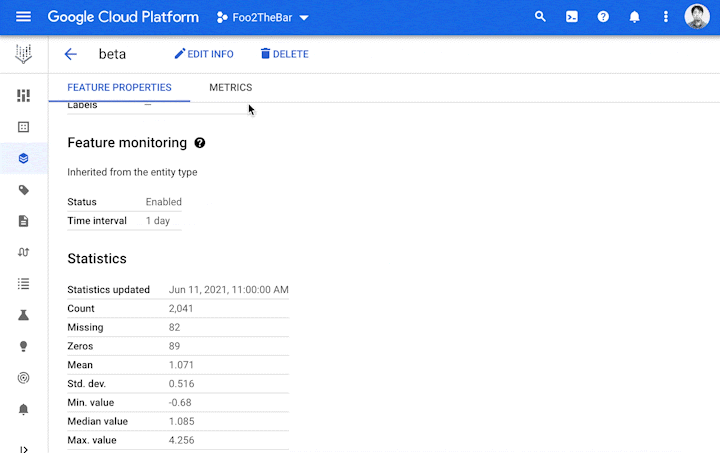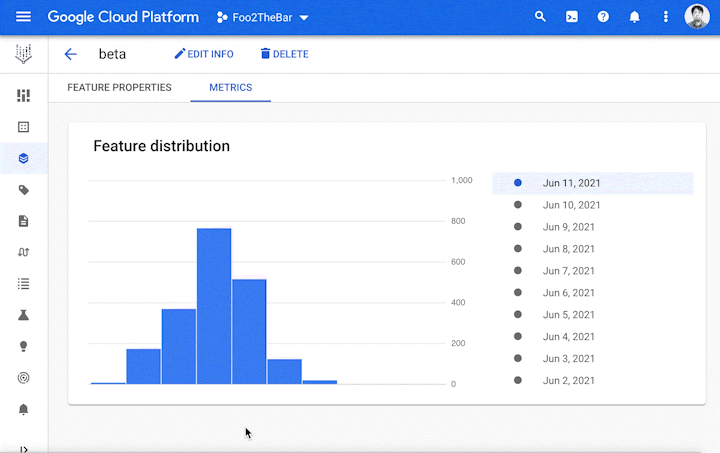
Feature monitoring on the Feature Store console
Making it easy to serve ML features in production
Many compelling machine learning use cases deploy their models for online serving, so that predictions can be served in real-time with low latency. The Vertex Prediction service makes it easy to deploy a model as an HTTP or RPC endpoint, at scale, with high availability and reliability. However, in addition to deploying the model, the features required by the model as inputs need to be served online.
Today, in most organizations there is a disconnect: it is the Data Scientist that creates new ML features, but the serving of ML features is handled by Ops or Engineering teams. This makes Data Scientists dependent on other teams to deploy their features in production. This dependence causes an undesirable bottleneck. Data Scientists would prefer to be in control of the full ML feature lifecycle. They want the freedom and agility to create and deploy new features quickly.
Vertex Feature Store gives Data Scientists autonomy by providing a fully-managed and easy to use solution for scalable, low-latency online feature serving. Simply use the Ingestion APIs to ingest new feature values to a feature store. Once ingested, they are ready for online serving.
Mitigating training-serving skew
In real world machine learning applications, one can run into a situation where a model performs very well on offline test data, but fails to perform as expected when deployed in production. This is often called Training-Serving Skew. While there can be many nuanced causes of model training-serving skew, often it boils down to skew between the features provided to the model during training and the features provided while making predictions.
At Google, there is a rule of thumb to avoid training-serving skew: you train like you serve.
A rule for mitigating training-serving skew
(from Rules of Machine Learning)
Discrepancies between the features provided to the model during training and serving are predominantly caused by the following three issues:
A. Different code paths for generating features for training and serving. If there are different code paths, inadvertently some deviations can creep in
B. A change in the raw data between when the model was trained and when it is subsequently used in production. This is called data drift and often impacts long-running models.
C. A feedback loop between your model and your algorithm, also called data leakage or target leakage. Please read the following two links for a good description of this phenomenon:
a. https://www.kaggle.com/dansbecker/data-leakage
Let’s see how Vertex Feature Store addresses the aforementioned three causes of feature skew:
- The feature store addresses (A) by ensuring that a feature value is ingested once into Vertex Feature Store, and then re-used for both training and serving. Since the feature value is only computed once, it avoids discrepancy due to duplicate code paths.
- (B) is addressed by constantly monitoring the distributions of feature values ingested into the feature store, so that users can identify when the feature values start to drift and change over time.
- (C) is addressed by what we call “point-in-time lookups” of features for training. This is described in more detail below. Essentially, this addresses data-leakage by ensuring that feature values provided for training were computed prior to the timestamp of the corresponding labeled training instance. The labelled instances used for training a model correspond to events that occurred at a specific time. As described by the data leakage links above, information generated after the label event should not be incorporated into the corresponding features. After all, that would effectively constitute “peeking” into the future:
Point-in-time lookups to fetch training data
For model training, you need a training data set that contains examples of your prediction task. These examples consist of instances that include their features and labels. For example, an instance might be a home and you want to determine its market value. Its features might include its location, age, and the prices of nearby homes that were sold. A label is an answer for the prediction task, such as the home eventually sold for $100K.
Because each label is an observation at a specific point in time, you need to fetch feature values that correspond to that point in time when the observation was made, like what were the prices of nearby homes when a particular home was sold. As labels and feature values are collected over time, those feature values change. Hence, when you fetch data from a feature store for model training, it performs point-in-time lookups to fetch the feature values corresponding to the time of each label. What is noteworthy is that the Feature Store performs these point-in-time lookups efficiently, even when the training dataset has tens of millions of labels.
In the following example, we want to retrieve feature values for two training instances with labels L1 and L2. The two labels are observed at time T1 and T2, respectively. Imagine freezing the state of the feature values at those timestamps. Hence, for the point-in-time lookup at T1, Vertex Feature Store returns the latest feature values up to time T1 for Feature 1, Feature 2, and Feature 3 and does not leak any values past T1. As time progresses, the feature values change and, consequently, so does the label. So, at T2, Vertex Feature Store returns different feature values for that point in time.

Point-in-time Lookup for preventing the data leak
A virtuous flywheel for faster AI/ML application development
A rich feature repository can kick start a virtuous flywheel effect that can significantly reduce the time and cost of building and deploying ML applications. With Vertex Feature Store, Data Scientists don’t need to start from scratch, rather they can build each ML application faster by discovering and reusing features created for prior applications. Moreover, Vertex Feature Store ensures maximum return on investment for each newly crafted feature, ensuring that it benefits the entire organization and further speeds up subsequent applications, leading to a virtuous flywheel effect.
Kick start your AI/ML flywheel by following the tutorials and getting started samples in the product documentation.




