あらゆるデータの瞬時アクセスを実現する Google のベクトル検索技術
Kaz Sato
Developer Advocate, Cloud AI
Tomoyuki Chikanaga
Chief Architect, Groovenauts
※この投稿は米国時間 2021 年 12 月 14 日に、Google Cloud blog に投稿されたものの抄訳です。
先日、Google Cloud のパートナー会社の グルーヴノーツ が、 MatchIt Fast のライブデモを公開しました。MatchIt Fast は、Wikimedia や the GDELT project などにある大規模公開データの中から、選択したサンプルに類似した画像やテキストを数ミリ秒で見つけ出すことができます。

このデモはどなたでも試せます。Image Similarity search に進み、クエリ候補に表示されている画像を選択するか、自分が所有する画像をアップロードしてみてください。上の動画のように、Wikimedia にある 200 万枚の画像の中から類似した上位 25 枚の画像が瞬時に表示されます。アルゴリズムが高速であるため、キャッシュはまったく使用されていません。
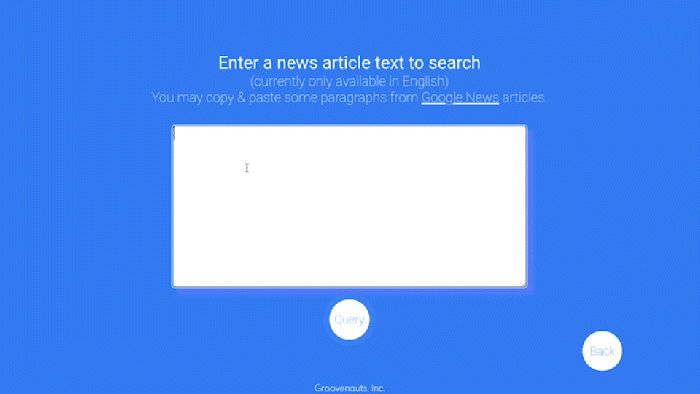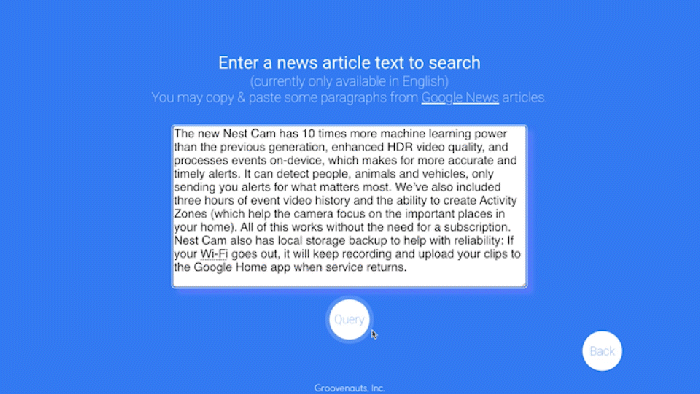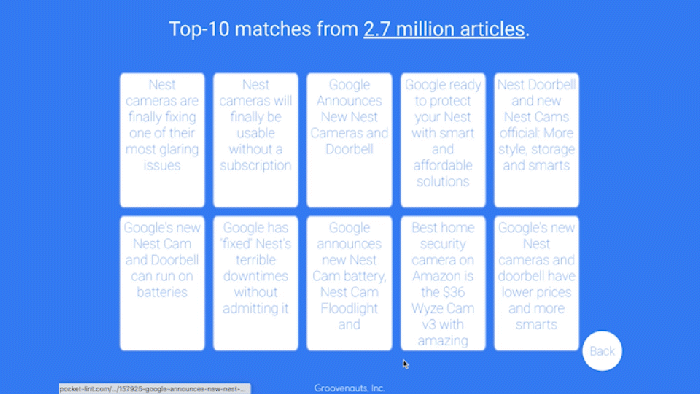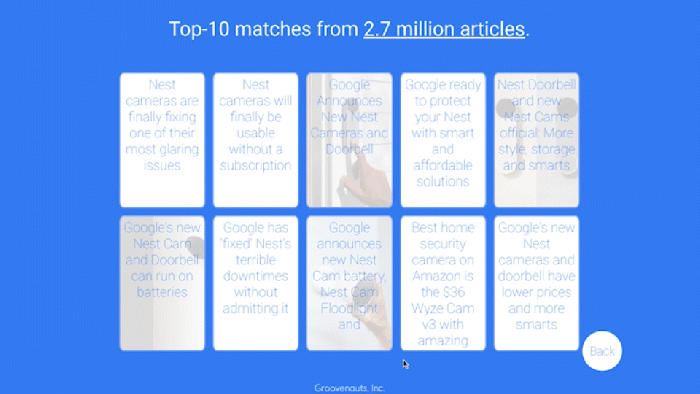
同様に、このデモでは類似したニュース記事(英文)の探索を行うことも可能です。好きなニュース記事をコピー&ペーストするだけで、the GDELT project にある 270 万の記事の中から類似した記事を 1 秒以内に取得できます。
ベクトル検索:Google 検索、YouTube、 Google Play などを支える技術
これほど速い検索をどのようにして実現しているのでしょうか? その秘密は、Vertex AI Matching Engine のベクトル検索機能にあります。Vertex AI Matching Engine は、Google Image Search、YouTube、Google Play などで世界中の Google ユーザーに何十億ものレコメンデーションや情報検索を提供しているものと同じベクトル検索のバックエンドを利用しています。この技術は、Google のコアサービスの最も重要なコンポーネントの一つです。ディープニューラルネットワーク(DNN)の発展にともない、Google に限らずコンテンツ検索や情報検索に依存する多くの一般的なウェブサービスに不可欠なコンポーネントになりつつあります。
では、従来のキーワードベースの検索とベクトル検索の違いは何でしょうか? 従来、ITシステムの情報検索基盤はリレーショナル データベースと全文検索エンジンでした。これらの技術では、例えばコンテンツ(画像やテキスト)の一部やエンティティ(商品、ユーザ、IoT デバイスなど)に対して”movie”、”music”、”actor”などのようなタグやカテゴリーキーワードを付与し、それらのレコードをデータベースに保存します。そうすることで、それらのタグやキーワードで検索できるようにしています。
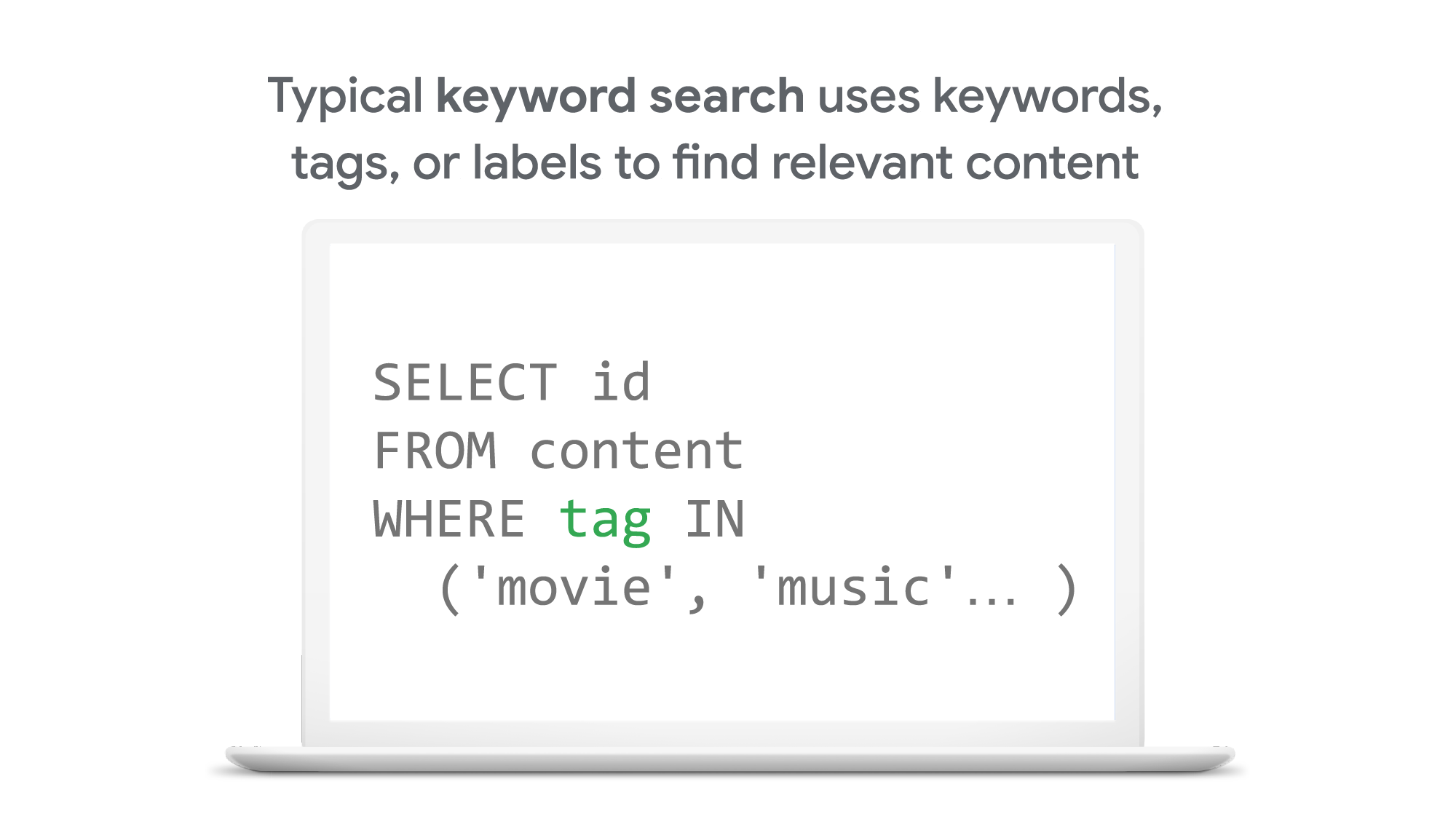
これに対し、ベクトル検索ではコンテンツの表現と検索にベクトル(数値の羅列)を使用します。数値の組み合わせによって、特定のトピックとの類似性を定義します。例えば、ある画像(またはその他のコンテンツ)に映画に関する内容が 10 %、音楽が 2 %、俳優が 30 %含まれていた時、シンプルにそれを表すと[0.1, 0.02, 0.3]というベクトルを定義できます(このあとで説明するように、実際のベクトルはもっと複雑なベクトル空間を持っています)。このように作られたベクトル同士の距離や類似性を比較することで、似たコンテンツを見つけることができます。Google のサービスは、このベクトル検索の技術を使用することで、世界中の多様なユーザにとって価値のあるコンテンツを数ミリ秒で見つけ出しているのです。

キーワード検索では、各コンテンツに紐付けられる属性として、映画かどうか、音楽かどうかなど、イチゼロで指定することになります。これはコンテンツの実際の”意味”を表現しているわけではありません。そのため、例えば”films”というキーワードで検索した場合、同じ意味を持つ”movies”がタグ付けされたコンテンツも本来検索対象に含めて欲しいところですが、キーワード検索ではヒットしません。キーワード検索でこれを改善したい場合、”films”と”movies”の2つの用語を明示的に結びつける辞書をデータベースや検索エンジンで持つ必要があります。コンテンツの実際の”意味”を十分に表せる表現力がありません。
ベクトル検索では、微妙なニュアンスや意味に基づき、コンテンツをより洗練された方法で見つけ出せます。キーワード検索のように各要素が独立しているわけではなく、ベクトル全体でコンテンツの意味が表現されるので、”films”、”movies”、”cinema”をまとめたコンテンツの意味を表現することができます。また、ベクトルはこれらの属性値の組み合わせに傾向や特徴が表れ、新しいカテゴリーとして捉えることもできます。つまり、これまでサービス提供者が知らなかった、あるいは定義されていなかったカテゴリーを表現する柔軟性を備えています。例えば、ASMR やスライムなど、おもに子供に人気のあるコンテンツの新しいカテゴリーは、大人やマーケティング担当者が事前に予測することは非常に難しくうえ、膨大なデータベースを遡って手動で新しいラベルに更新することは、非常に時間がかかりす。一方、ベクトルはこれまでにないカテゴリーをも瞬時に捉え表現できます。

ベクトル検索がビジネスを変える
ベクトル検索は画像やテキストといったコンテンツだけに利用可能な技術ではありません。ベクトル表現を定義できるあらゆるビジネスデータの情報検索に適用できます。いくつか例を挙げてみましょう。
類似ユーザーの発見:ユーザのアクティビティや購買履歴、その他のユーザ属性を組み合わせてベクトルを定義することで、指定したユーザーに類似した傾向を持つユーザを見つけ出せます。例えば、似たような商品を購入しているユーザー、ボットと疑われるユーザー、デジタルマーケティングの対象としたい優良顧客ユーザーなどを見つけられます。
類似した製品やアイテムを見つける:商品説明、価格、販売場所などの製品の特徴から生成されたベクトルを使うことで、特徴の類似した製品を見つけ、様々な顧客の質問に答えられます。例えば、「この製品に似ていて、同じユースケースで使える他の製品はありますか?」、「この地域で過去24時間に売れた製品は?」などの検索に有用なツールとなり得ます。
欠陥のある IoT デバイスの発見:欠陥のある機器の特徴を信号から捉え、そのベクトルで検索することで、同じように欠陥の可能性がある機器を瞬時に見つけ出し、事前のメンテナンスを行えます。
広告レコメンド:ここの広告とユーザーに対して適宜作成されたベクトルにより、ユーザーにとって最も関連性が高く適切な広告を数ミリ秒という速さで見つけることができます。
セキュリティの脅威を発見:Web サービスやネットワーク機器に対するコンピュータウイルスのバイナリやマルウェアの振る舞いパターンのシグネチャをベクトル化することで、セキュリティ上の脅威を発見できます。
ここまで紹介してきたもの以外にも、ベクトル検索は、今後数年のうちにあらゆる業界で何千もの多様な用途に適用され、リレーショナル データベースと同じくらい重要な技術になるでしょう。
ここまで聞くと、ベクトル検索は非常に強力な技術に聞こえます。しかし、この技術を実際のビジネスのユースケースに適用する上での大きな課題は何でしょうか? 実は2つあります。
ビジネスのユースケースに適したベクトルの作成
高速でスケーラブルなベクトル検索サービスの構築
Embeddings:ビジネスユースケースに適したベクトル
最初の課題は、ビジネス上のユースケースに適した、有用なベクトルを作ることです。この点では、深層学習の技術が威力を発揮します。Matchlt Fast のデモでは、画像からのベクトル抽出には事前学習された MobileNet v2 model を、テキストには Universal Sentence Encoder(USE)をそのまま使用しています。これらのモデルに生データを入力することで、データの「意味」の空間にマッピングされたベクトルである”embeddings(埋め込み表現)”を抽出できます。MobileNet ではパターンやテクスチャが似ている画像同士を embedding 空間の近くにマッピングし、USE ではトピックが似ているテキストを近くにマッピングします。
例えば、注意深く設計され、学習された機械学習モデルを使えば、映画を以下のような embedding 空間にマッピングできます。
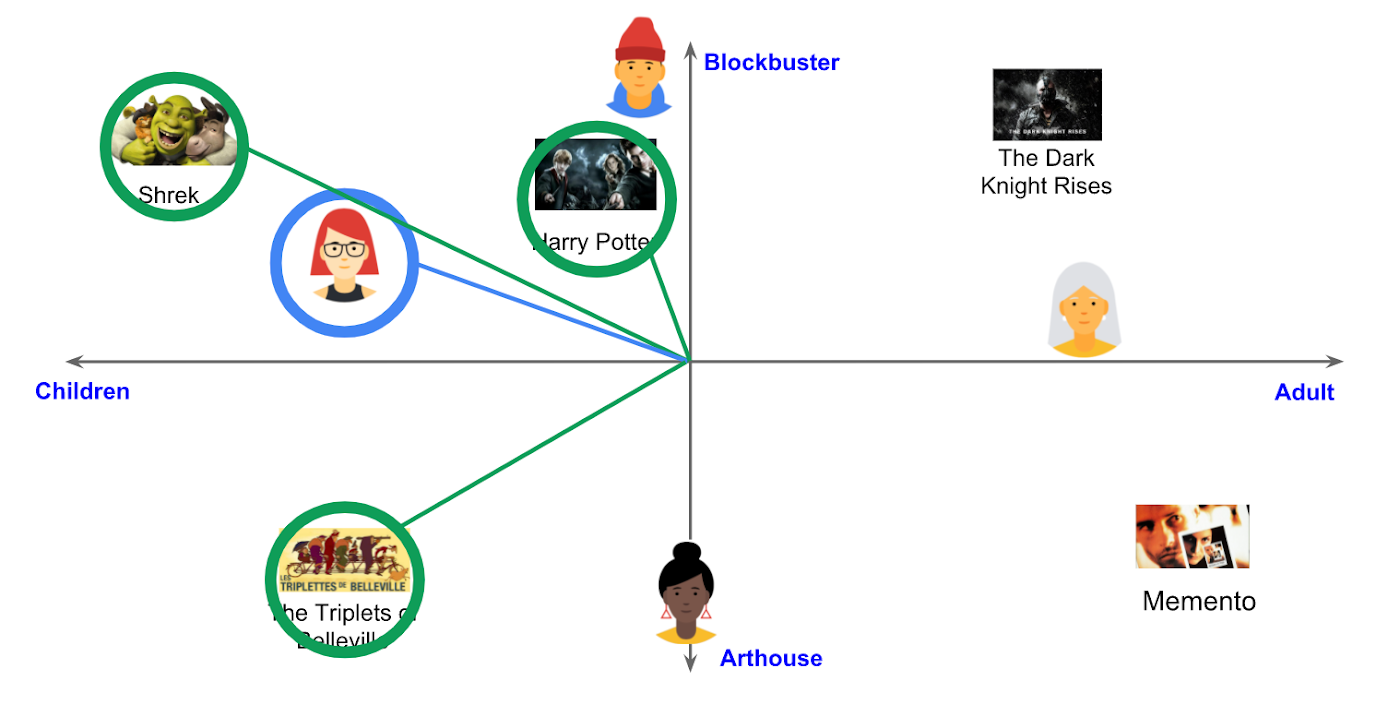
映画レコメンドのための 2 次元 embedding 空間の例
(Recommendation Systems, Google MLCC)ここで示した embedding 空間では、ユーザーは「その映画は子供向けか大人向けか」、「ブロックバスター映画かアート系映画か」という 2 つの次元に基づいて、おすすめの映画を見つけられます。もちろん、これは非常に単純な例ですが、他のケースでもビジネス要件にあった同様の embedding 空間があれば、モデルから抽出されたベクトルが表現するインサイトにより、推薦サービスや情報検索サービスでより優れたUXを提供できます。
Embedding の作成方法については、Machine Learning Crash Course on Recommendation Systems が参考になります。また、ビジネスデータからより良い embedding を抽出する方法については、この記事の後半で紹介します。
高速でスケーラブルなベクトル検索サービスの構築
ビジネスデータから有用なベクトル(embedding)を抽出できたなら、あとは類似するベクトルを検索するだけです。これは簡単そうに聞こえますが、実際にはそうではありません。ナイーブな手法によるベクトル検索を BigQuery で実装した場合の動作を見てみましょう。

この動画から分かるとおり、100 万個のアイテムの中から類似したアイテムを見つけ出すのに約 20 秒かかっています。Matchlt Fast のデモと比較するとかなり見劣りします。BigQuery は業界で最も高速なデータウェアハウスサービスの一つですが、なぜベクトル検索にこれほどの時間がかかるのでしょうか?
これは 2 つ目の課題である「高速でスケーラブルなベクトル検索エンジン」を構築することの難しさを示しています。ベクトル同士の類似性を計算する指標としては、L2 距離(ユークリッド距離)、コサイン類似度、内積が広く使われています。
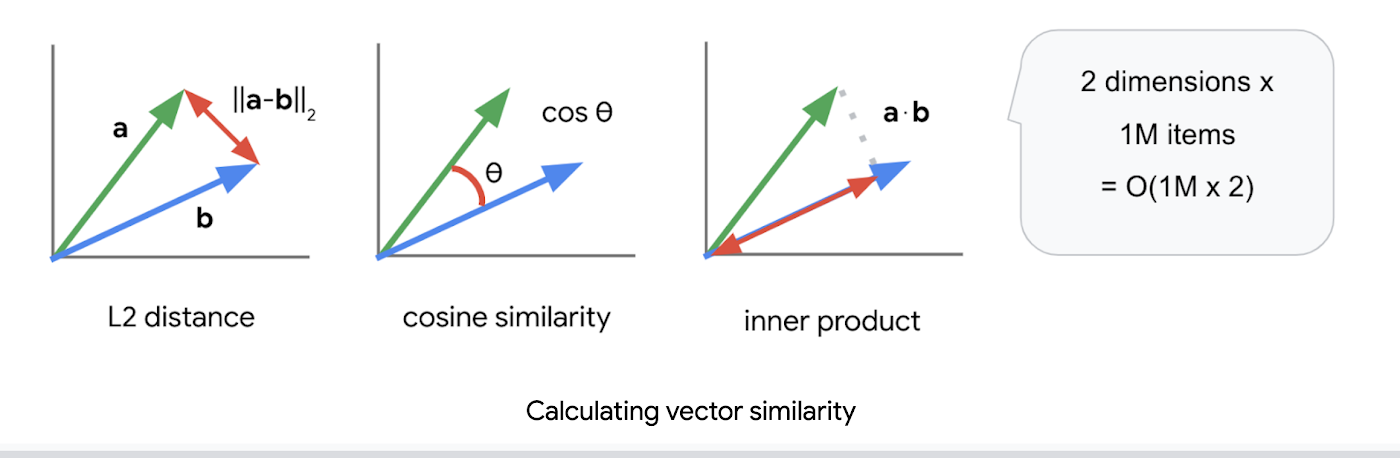
いずれの指標も一般的な方法で実装すると、ベクトルの総数を N、次元数を K とした時にO (NK)の計算量が必要になります。例えば、1024 次元のベクトルと検索対象のベクトル 1 M(100 万)個を比較した場合、計算回数は 1024 x 100 M = 1.02B(10億回)に比例したオーダーになります。これが 1 回の検索で全てのベクトルを調べるのに必要な計算量であり、上記 BigQuery のデモが時間がかかる理由でもあります。
ベクトルを 1 つ 1 つ比較する代わりに、近似最近傍探索(ANN)を使うことで検索時間を短縮できます。多くの ANN アルゴリズムでは、ベクトル空間を複数のグループに分割し、各グループを表す「コードワード」を定義して、そのコードワードを使って検索するベクトル量子化(VQ)が用いられています。この VQ は、検索速度を飛躍的に向上させる技術であり、リレーショナル データベースや全文検索エンジンにインデックスが不可欠であるのと同様に、多くの ANN アルゴリズムに欠かせない技術となっています。
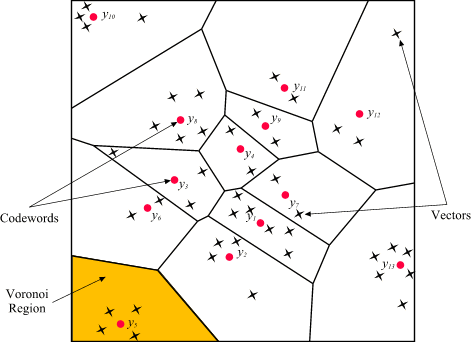
上図から分かるように、空間内のグループの数が増えると検索速度が低下し、精度が向上します。このトレードオフを改善すること、つまり、より短い遅延でより高い精度を得ることが、ANN アルゴリズムの重要な課題でした。
昨年、Google Research は、この課題に対して最先端の結果を実現する新しい手法「ScaNN」を発表しました。ScaNN では、「異方性ベクトル量子化」という新しい VQ アルゴリズムを導入しました。
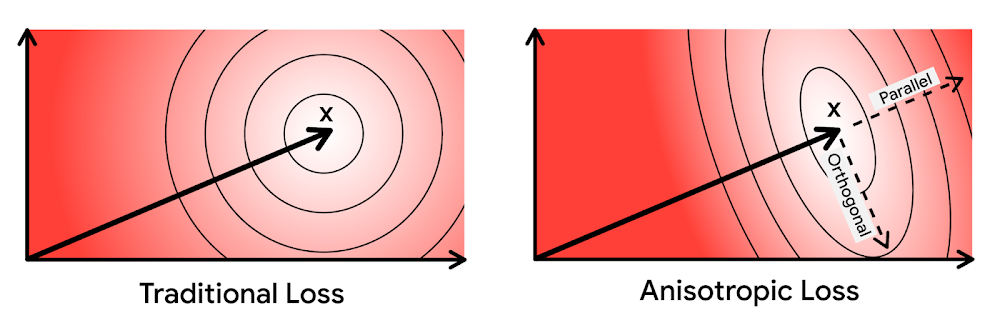
異方性ベクトル量子化では、新しい損失関数を使用して、1 つのグループでより遠くのデータポイント(つまり、より高い内積)を取り込むための最適なグループ化のための VQ のモデルを学習します。この新しいアイデアにより、以下のベンチマーク結果(紫色の線)のとおり、より低い遅延でより高い精度を得られます。
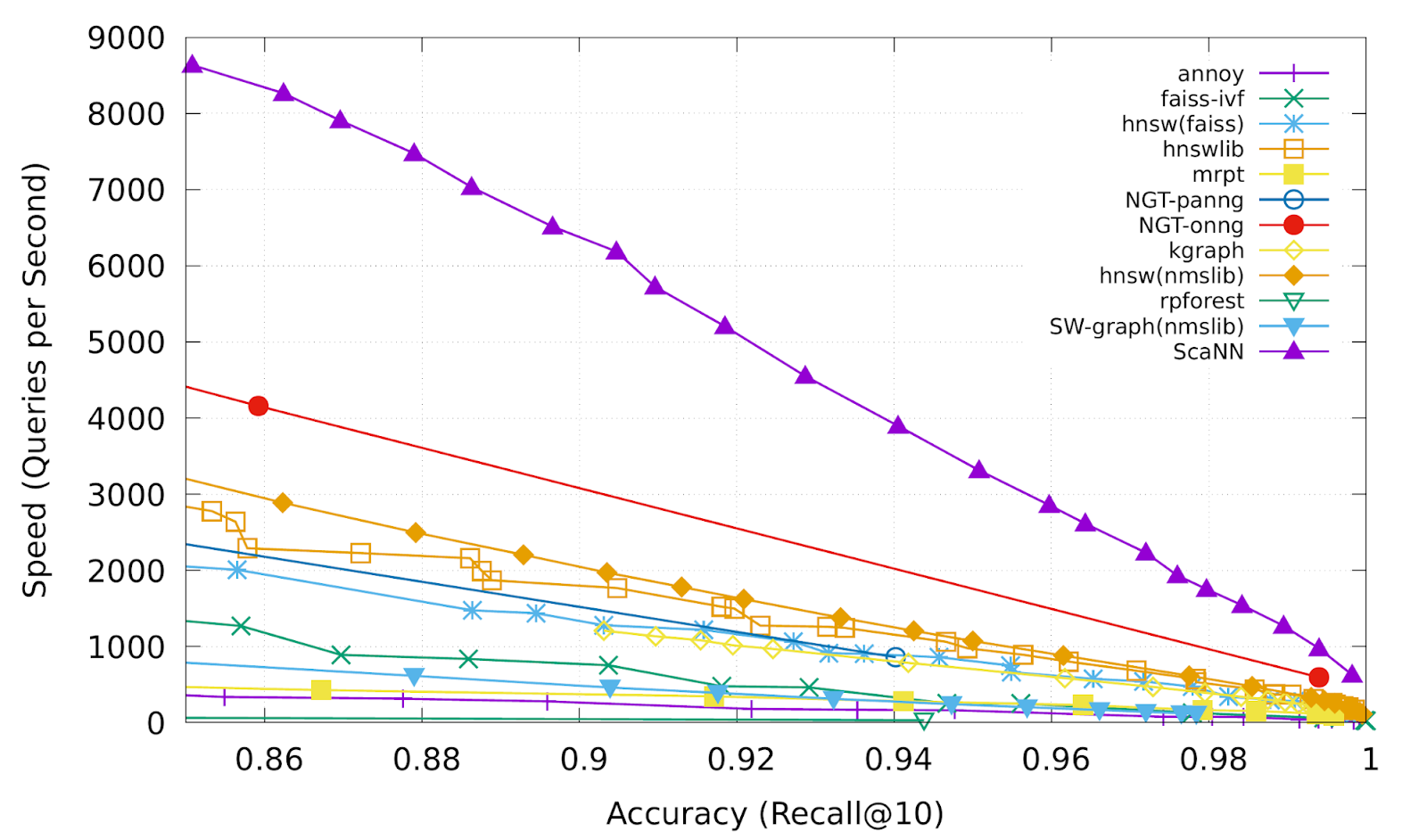
この速度と精度が、Google 画像検索、YouTube、Google Play などのユーザ体験を生み出す「魔法のスパイス」の正体です。Google の ANN 技術は、ユーザーが膨大なウェブコンテンツの中から価値ある情報を数ミリ秒で見つけ出すことを可能にしているのです。
Vertex AI Matching Engine をどう使うか
そして今回、Google の各種サービスと同じベクトル検索技術を、お客様のビジネスにも活用できるようになりました。Vertex AI Matching Engine は、Googleのサービスと同じ ScaNN ベースのバックエンドを共有し、高速でスケーラブルなベクトル検索を実現する製品です。先日プレビュー版を終えて一般提供が開始され、本番環境での利用が可能となりました。ScaNN に加えて、Matching Engine は商用製品として以下の追加機能を提供しています。
スケーラビリティと可用性:オープンソース版のScaNN は、実験や検証目的には適していますが、自力で本番運用する際には多くの課題が生じることが予想されます。例えば、スケーラビリティ、可用性、メンテナンス性の観点が考えられます。Matching Engine では、Google サービスの本番バックエンドで動作するScaNN を使用しており、大規模なワーカープールによるオートスケーリングとオートフェイルオーバーを実現しています。1 秒間に数万件のリクエストを受け付けることができ、90 %のリクエストに対して 95〜98 % の再現率と 10ms 以下のレスポンスタイムを提供します。
フルマネージド:検索サービスの構築やメンテナンスを気にする必要はありません。ベクトルを使用してインデックスを作成または更新するだけで、本番環境に対応した ANN サービスが展開されます。インデックスの再構築や最適化などのメンテナンス作業も必要ありません。
フィルタリング:Matching Engine には、ベクトル毎に指定したタグをもとに検索結果を絞り込むことができるフィルタリング機能があります。例えば、ファッションアイテムのベクトルに「国」と「在庫」のタグを設定し、「(US OR Canada) AND Stocked」や「not Japan AND Stocked」などのフィルターを指定し、検索範囲を絞った上で探索を行うこともできます。
では、Matchlt Fast のデモで使われたコードを参考に、Matching Engine の使い方を見てみましょう。
Embedding を生成する
検索を開始する前に、以下のように各データの embedding を生成する必要があります。
上記の例は、MobileNet v2 モデルで生成された、ある一つの画像に対する 1280 次元の embedding です。Matchlt Fast デモでは、以下のコードで 200 万枚の画像の embedding を生成しています。
各フィールドの詳細な説明はこちらのドキュメントに記載されていますが、ここではいくつかの重要なフィールドを紹介します。
contentsDeltaUrl: embeddingを保存した場所
dimensions: embeddingの次元数
approximateNeighborsCount: 近似最近傍探索で取得する近傍数のデフォルト値
distanceMeasureType: embedding 間の類似性をどのように測定するか。L1、L2、cosine、dot product のいずれかを指定できます。embedding の類似性を測定する手法の選定方法については、こちらを参照してください。
Matching Engine でインデックスを作成するには、以下の gloud コマンドを実行します(引用元)。このとき、metadata-file オプションには上記で定義した JSON ファイル名を指定します。
検索の実行
ここまでで、Matching Engine で検索を実行する準備が整いました。このデモでは、それぞれの検索リクエストを以下の順序で処理します。
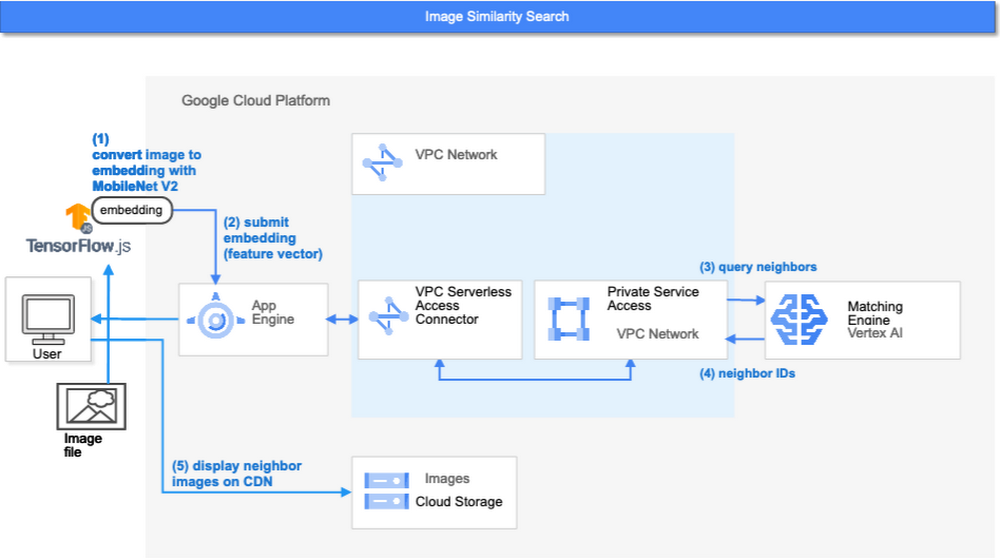
まず、web UI は画像(ユーザーが選択またはアップロードしたもの)を取得し、ブラウザ内で実行されている TensorFlow.js の MobileNet v2 モデルを使用して embedding にエンコードします。ちなみに、このようなクライアント側でのエンコーディングはネットワークトラフィックを削減するユニークな手法です。多くのケースでは、Vertex AI Prediction のようなサーバ側の推論サービスによりコンテンツを embedding にエンコードしたり、Vertex AI Feature Store などのリポジトリにある事前生成された embedding を取得したりします。
App Engineでは、embedding を受け取り、Matching Engine にクエリを送信します。なお、Matching Engine へのクエリの送信には、Cloud Run、Compute Engine、Kubernetes Engineなどのような Google Cloud にある他のアプリケーション実行環境も利用できます。用途に応じて最適なものを選択してください。
Matching Engine が検索処理を実行します。App Engine と Matching Engine の接続には VPC プライベートネットワークを使用することで低遅延を実現しています。
Matching Engine は、インデックス内の類似したベクトルの ID を返します。
ステップ3は以下のコードで実装されています。
Matching Engine へのリクエストは、上記コードにあるように gRPC を介して送信されます。リクエストオブジェクトを取得した後、インデックスの ID を指定し、クエリのembedding ベクトルを付与して、上位何件を検索するかを指定します。最後に Match 関数を呼び出してリクエストを送信しています。応答は数ミリ秒以内に返ってきます。
Next steps:様々なユースケースや検索品質向上のためにできること
先に述べたように、本番環境でベクトル検索を適用する際の大きな課題は以下の2点です。
ビジネスのユースケースに適したベクトルの作成
高速でスケーラブルなベクトル検索サービスの構築
ここまでの例から、Vertex AI Matching Engine が2つ目の課題を解決していることがお分かりいただけたかと思います。では、1つ目の課題はどうでしょうか。Matching Engine はベクトル検索サービスであり、ベクトルを作成する部分については含まれていません。
Matchlt Fast のデモでは、画像やコンテンツから embedding を抽出する手段としてシンプルな方法を使用しています。具体的には、既存の事前学習済みモデル(MobileNet v2 や Universal Sentence Encoder)を使用しています。これらのモデルは簡単に使い始めることができますが、ビジネスやユーザーエクスペリエンスの要件に基づいて、他のユースケースやより良い検索品質のための embedding を生成するために、他の選択肢も検討できます。
例えば、製品レコメンドのための embedding は、どのようにして生成すればよいでしょうか。Machine Learning Crash Course の Recommendation Systems のセクションでは、協調フィルタリングと DNN モデル(two-tower model)を使ってレコメンド用のembedding を生成する方法を学ぶのに良い教材を用意しています。また、TensorFlow Recommenders は、特に two-tower モデルや高度なトピックについて、有用なガイドやチュートリアルを提供しています。Matching Engine との連携については、Train embeddings by using the Two-tower built-in algorithm も参考になります。
もう一つの興味深い手法は、Swivel モデルです。Swivel は、製品の共起行列から embedding を生成する手法です。例えば購買履歴のような構造データの場合、製品の共起行列は、embedding を生成したい全ての製品について、製品 A、B の両方を含む購買履歴を数えることで計算できます。さらに詳しく知りたい方は、Matching Engine でモデルを使用する方法について紹介したこちらのチュートリアルをご覧ください。
より良い検索品質を実現するための方法を探すのであれば、分類だけでなく、embedding 空間におけるエンティティ間の距離を考慮する、距離学習(metric learning)を検討してみてください。
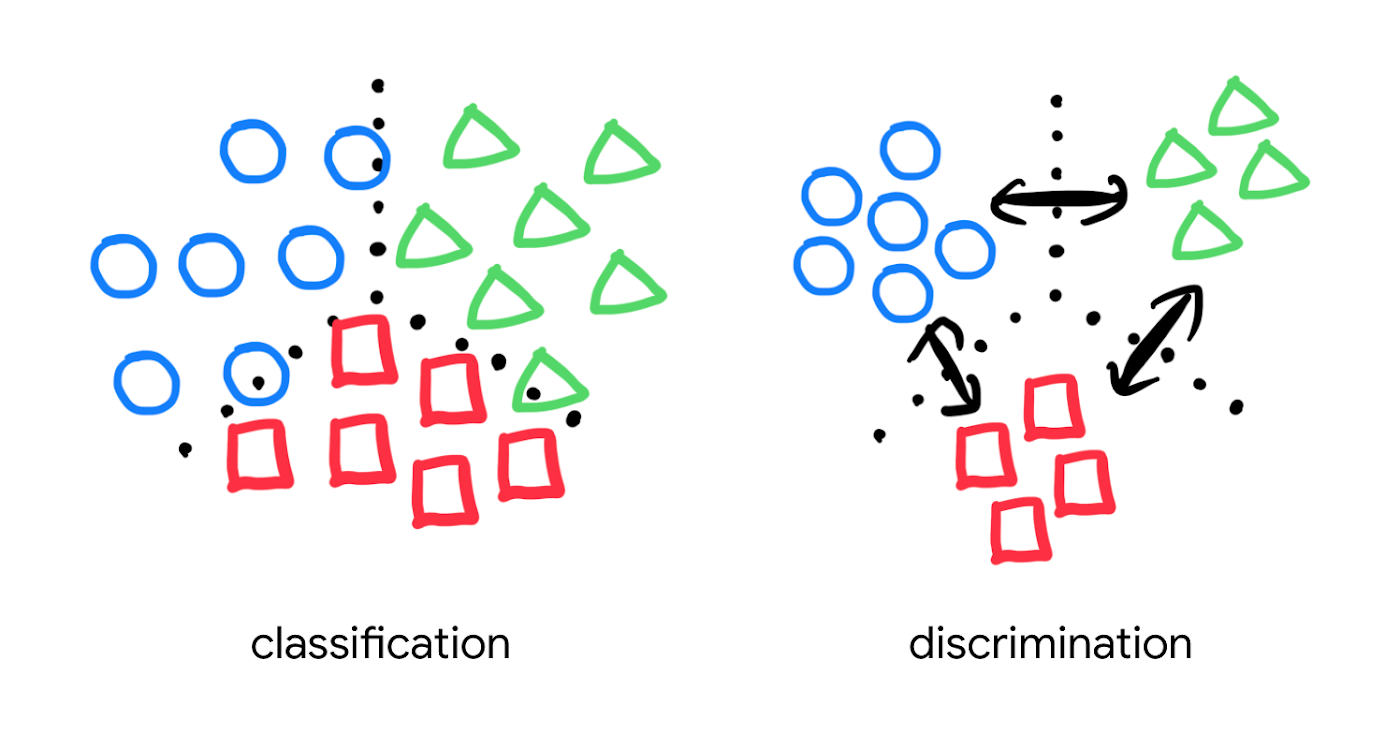
距離学習では、エンティティ間の距離指標を用いて識別のためのモデルを学習します。
MobileNet v2 などの一般的な事前学習済みモデルは、画像中のそれぞれのオブジェクトを分類することはできますが、一定の距離指標でオブジェクト間の距離を測れるようには明示的に学習されていません。しかし距離学習では、オブジェクト同士の距離(上図の黒い矢印)を含めて学習することが可能です。そのため、距離学習は様々なビジネスユースケースに最適化された embedding 空間を設計することで、検索品質の向上が期待できます。この距離学習を Matching Engine と組み合わせて使うには、TensorFlow Similarity が選択肢の一つになります。

Tensorflow Similarity projector による Oxford-IIIT Pet データセットの可視化
いかがでしょうか? 今日、私たちは、従来のキーワードベースの検索技術から新しいベクトル検索への移行を始めたばかりです。今後 5 年から 10 年の間に、業界やコミュニティでさらに多くのベストプラクティスやツールが開発されるでしょう。これらのツールやベストプラクティスは、次のような多くの疑問に答えてくれることでしょう。
・特定のビジネスユースケースのために、独自の embedding 空間をどのように設計するか?
・検索品質をどのように測定するのか?
・ベクトル検索のデバッグとトラブルシューティングはどのように行うのか?
・より高度な要件を満たすために、既存の検索エンジンとのハイブリッド構成をどのように設計するか?
・などなど
この技術を実際のサービスに導入する上で、多くの新しい課題とチャンスが待ち受けています。 Matching Engine のベクトル検索を活用した、より良いユーザーエクスペリエンスの提供と新たなビジネスチャンスの獲得に向けて、今こそベストなタイミングです。
謝辞
この記事に対して貴重なフィードバックをいただいた Anand Iyer 氏、Phillip Sun 氏、Jeremy Wortz 氏に感謝いたします。
- Tomoyuki Chikanaga, Chief Architect, Groovenauts



