How Volkswagen and Google Cloud are using machine learning to design more energy-efficient cars
Ahmad Ayad & Henrik Bohlke
Data Scientists, Volkswagen
Dr. Michael Menzel
ML Specialist Customer Engineer, Google Cloud
Volkswagen strives to design beautiful, performant, and energy efficient vehicles. This entails an iterative process where designers go through many design drafts, evaluating each, integrating the feedback, and refining.
For example, a vehicle’s drag coefficient—its resistance to air—is one of the most important factors of energy efficiency. Thus, getting estimates of the drag coefficient for several designs helps the designers experiment and converge toward more energy-efficient solutions. The cheaper and faster this feedback loop is, the more it enables the designers.
Unfortunately, estimating drag coefficient is an expensive and time-consuming operation that involves either a physical wind tunnel or a computationally intensive simulation. This can be a bottleneck in the feedback cycle.
For this reason, Volkswagen and Google Cloud decided to collaborate on a joint research project to investigate using machine learning (ML) to get fast and inexpensive estimates of the drag coefficient. In this post, we’ll explore the challenges and approaches undertaken in this project.
The core principles of the project were simple. First, we needed to collect a dataset of existing car designs and their respective drag coefficients. Then, we needed to create a representation of the various cars that would be suitable for ML. The next step was to train a deep learning model to predict the drag coefficient, and then, finally, we would use that model to efficiently estimate drag for any new design.
Representing three-dimensional car designs
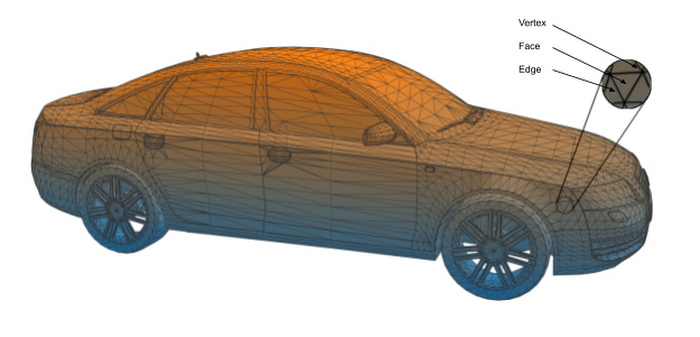
Design software recreates a physical object as a three-dimensional triangle mesh made up of three types of objects—faces, edges, and vertices. Figure 1, below, shows such a mesh for an Audi S6. Faces are flat surfaces, such as the window in a car door. An edge is where two faces meet (e.g., the side of the door), and a vertex is where two or more edges meet, such as the corner of the door.
Car bodies, however, come in all shapes and sizes. A Volkswagen Golf economy model is very different from a Tiguan SUV, and a single vehicle can have both large smooth surfaces as well as areas with delicately designed features. Consequently, there can be a huge variety from one polygonal mesh to the next.
ML models need consistent representation in order to form robust generalized rules. With such a dramatic variance between each polygonal mesh, the models would be compromised and the results could have huge margins of error.
We needed to find a way to create simple meshes that capture the shape of the car but are still suited for ML models.
Representing a car with digital shrink wrapping
Rather than building a representation of each car from the ground up, we applied a “shrink wrapping” method for the 3D meshes. The principle is very similar to vacuum-sealing a cucumber (Figure 2). The cucumber is placed in a plastic bag and the air is then gradually removed until the bag fits tightly around it, capturing its shape.
Our approach works similarly: we start with a base mesh, a simple shape that corresponds to the plastic bag, and we deform it until it captures the shape of the target mesh. For our purposes, the base mesh is a simplified representation of a car and the target mesh is the particular car we are designing for at that moment. Such meshes can be defined, managed, and presented to ML models for training using the Tensorflow Graphics and trimesh libraries.

Our “shrink wrapping” method mainly works by iteratively minimizing a measure of distance (e.g., chamfer distance) between the two meshes. Additionally we can regularize our mesh to preserve certain qualities, like smoothness, in the resulting mesh. This iterative optimization is analogous to the vacuum pump, gradually shrinking and fitting the vertices of the mesh as closely as possible to the complex shape of the car. With shrink-wrapping, we are able to produce cleaner meshes that are more suitable to our estimation task. An example of such a procedure is shown in Figure 3.

How to train a model
Shrink-wrapping the 3D car designs was an important first step, but the work was far from over. Our next challenge was to build and test the machine learning algorithms.
We wanted our algorithms to estimate the drag coefficient as accurately and quickly as possible each time it looked at a new design. To do so, we had to train the ML models on existing data.
From publicly available datasets, we calculated the drag coefficients for 800 different car meshes, which we trained the models on. Then, we evaluated the trained models on a further 100 meshes, seeing how accurate their estimates were on new data.
As we worked through this training, we refined our approach. Initially, we tested models based on convolutional neural networks – similar to PointNet – that observed only the vertices, i.e., the fixed points in each mesh. But when we tested mesh-convolutional models – similar to FeastNet – we found a slightly different focus improved the accuracy of the estimates. Rather than focusing on vertices alone, these models looked at a mesh of vertices and how they relate to each other. These models placed each vertex in a richer context, leading to more accurate estimates when air-flow hit particularly subtle design features.
Working in parallel and at scale
To collaborate across time zones and two organizations, we’ve used the Google Cloud Vertex AI platform.
Vertex AI Workbench serves as a central hub to interact with other services and infrastructure on the Vertex AI platform. It enables quick experiments and preparation of training packages for resource-intensive ML model training jobs, all in a Python notebook environment for immediate execution of code. The notebook environments allow code-based interaction with other services on Google Cloud and ML tools such as Vertex AI Training and Vertex AI Pipelines.
The process of training a new model is a seamless one. First, a dataset is prepared and stored in Google Cloud Storage, usually with the help of Tensorflow Datasets. Then, for every ML model we want to test, we package and store the training code as a container image with Google Cloud Build and Container Registry. This ensures that every job is fully documented, including the provided parameters, training code package, logs from the training task, and resulting artifacts such as metrics and model files.
From there, we submit the model to the Vertex AI Training service, which provides easy access to large scale infrastructure and hardware accelerators, such as GPUs and TPUs, by simply defining resource needs when submitting a job. By using Vertex AI Training’s hyperparameter tuning feature, we can run experiments in parallel with multiple neural networks to find the right one for our purposes.
With Vertex AI Tensorboard, we can capture metrics and visualize the results of our experiments. These are readily available to anyone in the team, wherever they are in the world, for a wider discussion.
The first milestone
This joint research effort between Volkswagen and Google has produced promising results with the help of the Vertex AI platform. In this first milestone, the team was able to successfully bring recent AI research results a step closer to practical application for car design. This first iteration of the algorithm can produce a drag coefficient estimate with an average error of just 4%, within a second.
An average error of 4%, while not quite as accurate as a physical wind tunnel test, can be used to narrow a large selection of design candidates to a small shortlist. And given how quickly the estimates appear, we have made a substantial improvement on the existing methods that take days or weeks. With the algorithm that we have developed, designers can run more efficiency tests, submit more candidates, and iterate towards richer, more effective designs in just a small fraction of the time previously required.
Going forward, faster and more accurate estimates could even enable more automated searching for efficient designs, which would help both engineers and designers to hone in on the areas of the vehicle body where they could have the most impact. An important next step will be integrating the results into 3D design software to let designers benefit from the output and provide feedback.
As we continue, our focus is on improving the accuracy of the models. Firstly, we will build a larger, better quality dataset. Secondly, we will improve our shrink-wrapping algorithm to capture more details. Finally, we will enhance our existing models by experimenting with Vertex AI Neural Architecture Search to explore and experiment with different neural architecture options.
Moreover, we believe that our results for drag coefficient estimation is only a starting point for further exploration. There could potentially be numerous use cases in the space of physical simulations and assessments where cost and time savings could be achieved through ML-based estimators.
Acknowledgements
This work wouldn’t have been possible without the contributions from Volkswagen Data:Lab, Google Research, and Google Cloud. Thanks to Ahmed Ayyad, Dr. Andrii Kleshchonok, Dr. Daniel Weimer, Gülce Cesur, Henrik Bohlke, Andreas Müller from Volkswagen, Ameesh Makadia, Ph.D., and Carlos Esteves, Ph.D., from Google Research, and Daniel Holgate, Holger Speh, and Dr. Michael Menzel from Google Cloud.



