プリエンプティブル VM と GPU による ML ワークフローのコスト削減

Google Cloud Japan Team
※この投稿は米国時間 2019 年 11 月 2 日に、Google Cloud blog に投稿されたものの抄訳です。
ビジネス プロセスへの機械学習(ML)の導入は以前より簡単になり、メリットも大きくなっていますが、ML ジョブの実行にはコストがかかることがあります。たとえば、トレーニングや調整を定期的に(たいていは毎日)実行するよう計画している場合や、大規模なハイパーパラメータ調整テストを定期的に実行している場合は、コストが大きくなります。しかしこうした作業の実行は、多くの場合、決まった時間内に終了する必要はありません。サービス時間と可用性の要件がそれほど厳しくない場合は、GPU を備えたプリエンプティブル VM はコストを大幅に下げるための有効な手段となり得ます。
この記事では、Kubeflow Pipelines ジョブを実行する際に、GPU をプロビジョニングしたプリエンプティブル VM を使用する方法についてご説明します。また、Stackdriver Monitoring を使用して、現在と過去のパイプライン オペレーションのログを確認する方法についても解説します。
プリエンプティブル VM は持続時間が最大で 24 時間の Compute Engine VM インスタンスで、可用性は保証されていません。そのため標準的な Compute Engine VM よりも、低い価格が設定されています。Google Kubernetes Engine(GKE)では、プリエンプティブル VM を使用するクラスタやノードプールを簡単に設定できます。こうしたノードプールでは、プリエンプティブル インスタンスに GPU を接続した設定が可能です。プリエンプティブル インスタンスは GPU を有効にした標準のノードと同じように動作しますが、GPU を実行できるのはインスタンスの持続中のみになります。
Kubeflow は Kubernetes 上での機械学習ワークフローのデプロイメントを容易にし、移植性とスケーラビリティを向上させることを目的としたオープンソース プロジェクトです。Kubeflow Pipelines は、Docker コンテナベースの移植可能でスケーラブルな機械学習ワークフローを構築しデプロイするためのプラットフォームです。
GKE で Kubeflow を実行する場合、プリエンプティブル ノードに 1 つ以上のパイプライン ステップが実装された Kubeflow Pipelines を簡単に定義して実行できるため、ジョブの実行コストを抑えられます。プリエンプティブル VM の使用時に適切な結果を得るために、プリエンプティブルなステップは、べき等性(1 つのステップを複数回実行しても同じ結果になる性質)を有する作業か、チェックポイントが設定された作業(中断されたところからのステップ再開を可能にする)として構成しておく必要があります。
たとえば、Google Cloud Storage ディレクトリのコピーは、ソース ディレクトリが変わらないと想定した場合、中断して再開しても同じ結果になります。機械学習モデルをトレーニングするオペレーション(TensorFlow トレーニングの実行など)は、通常、定期的にチェックポイントを作成するよう設定されます。つまり、トレーニングがプリエンプションによって中断されても、ステップを再開したときに前回の場所から作業を再開できます。大部分の ML フレームワークではチェックポイント作成を容易にサポートできます。そのため Kubeflow Pipelines にモデル トレーニングのステップが含まれる場合は、GPU を有効にしたプリエンプティブルなノードで実行できる最適な候補となります。
パイプラインを実行中にクラスタノードがプリエンプトされると、そのノードで実行中のポッドも終了します。GCP の Stackdriver Logging を使用すると、このような終了したポッドからのログを簡単に表示して、詳細情報を確認できます。
ここからは、Kubeflow Pipelines でのプリエンプティブル VM の使用方法と、Stackdriver を使用してパイプライン ステップを検査する方法について解説します。
GKE クラスタへのプリエンプティブル GPU ノードプールの設定
下に示すようなコマンドを実行することで、プリエンプティブル GPU を有効にしたノードプールをクラスタに設定できます。ご使用の要件に合わせてコマンドのクラスタ名とゾーンを変更し、アクセラレータのタイプとカウントを調整してください。また、下記に示すように、現在のワークロードに基づき自動スケーリングを行うよう、ノードプールを定義できます(注: このコマンドを実行する前に、GPU 割り当てを増やさなければならない場合があります)。
また、Cloud Console を使用してノードプールを設定することも可能です。
プリエンプティブル GKE ノードを使用する Kubeflow パイプラインの定義
Kubeflow パイプラインを定義する際は、以下のようなオペレーションを適宜変更して、任意のステップがプリエンプティブル ノードで実行されるように指定できます。
詳細についてはドキュメントをご覧ください。ノードプールの作成時に上記のコマンドで node taint を変更した場合は、同じ node toleration を use_preemptible_nodepool() 呼び出しに受け渡します。
また、ノードがプリエンプトされた場合に、ステップを複数回再試行できるようにしておく必要があります。これは以下のコマンドを使用して実行できます。このコマンドでは再試行を 5 回に指定しています。また、以下のアノテーションでは利用可能な GPU が 4 つあるノードでオペレーションを実行するよう指定しています。
例: プリエンプティブル ノードによるモデル トレーニングのコスト削減
具体例を見てみましょう。こちらのコードラボの Kubeflow パイプラインはプリエンプティブル ステップを使用するのに適した候補です。このパイプラインは GitHub の問題のデータで Tensor2Tensor モデルをトレーニングし、問題の本文から問題のタイトルを予測できるようにします。また、トレーニングしたモデルを稼動用にデプロイしてから、モデルから予測を行うためのウェブアプリをデプロイします。このパイプラインは、十分なパフォーマンスを確保するために GPU を必要とする TensorFlow モデル アーキテクチャを使用し、構成によっては長時間の実行が可能です。
トレーニングにプリエンプティブル VM を使用するよう、このパイプラインを変更すれば有用であると私たちは考えました(オリジナルのパイプラインの定義はこちら)。そのためにまず、パイプラインをリファクタリングし、Google Cloud Storage(下記のコードの GCS)のコピー アクションと、モデル トレーニング アクティビティを分離する必要がありました。このパイプラインのオリジナル バージョンでは、最初の TensorFlow チェックポイントのコピーが、トレーニングのコンポーネント アクションの一部として実行されました。精度を確保するために、これをリファクタリングする必要がありました。トレーニングがプリエンプトされ再開する必要がある場合に、再度コピーして現在のチェックポイント ファイルが上書きされてしまうことを回避するためです。
また、2 つの Google Cloud Storage のコピーと TensorFlow トレーニング パイプライン ステップについて、パイプラインの定義の一部として定義するのではなく、再利用可能なコンポーネント仕様を作成しました。再利用可能なコンポーネントとは、あらかじめ実装されたスタンドアロンのコンポーネントで、任意のパイプラインにステップとして簡単に追加でき、パイプラインの定義を簡略化します。コンポーネント仕様によって、入出力の静的な型チェックを簡単に追加できます。このようなコンポーネントの定義ファイルについては、こちらとこちらをご覧ください。
以下は、新しいパイプラインの定義の関連する部分です。
このケースでは URL からロードしたコンポーネント定義を使用して、copydata と train のステップを定義しました(ここには示されていませんが、Github ベースのコンポーネントの URL には特定の Git commit ハッシュを含めて、コンポーネントのバージョン管理をサポートすることが可能です。こちらの例をご覧ください)。
トレーニング オペレーションには、GPU を有効にしたプリエンプティブル ノード上で実行し、5 回再試行するよう、アノテーションを追加しました。長時間のトレーニング ジョブの場合は、再試行の回数を増やしてください。パイプラインの定義の詳細は、こちらをご覧ください。
(追記: コピーステップにプリエンプティブル VM を使用しても、問題なく動作したと考えられます。中断されても結果が変わることなく再試行できるからです)。
実際のプリエンプティブル パイプライン
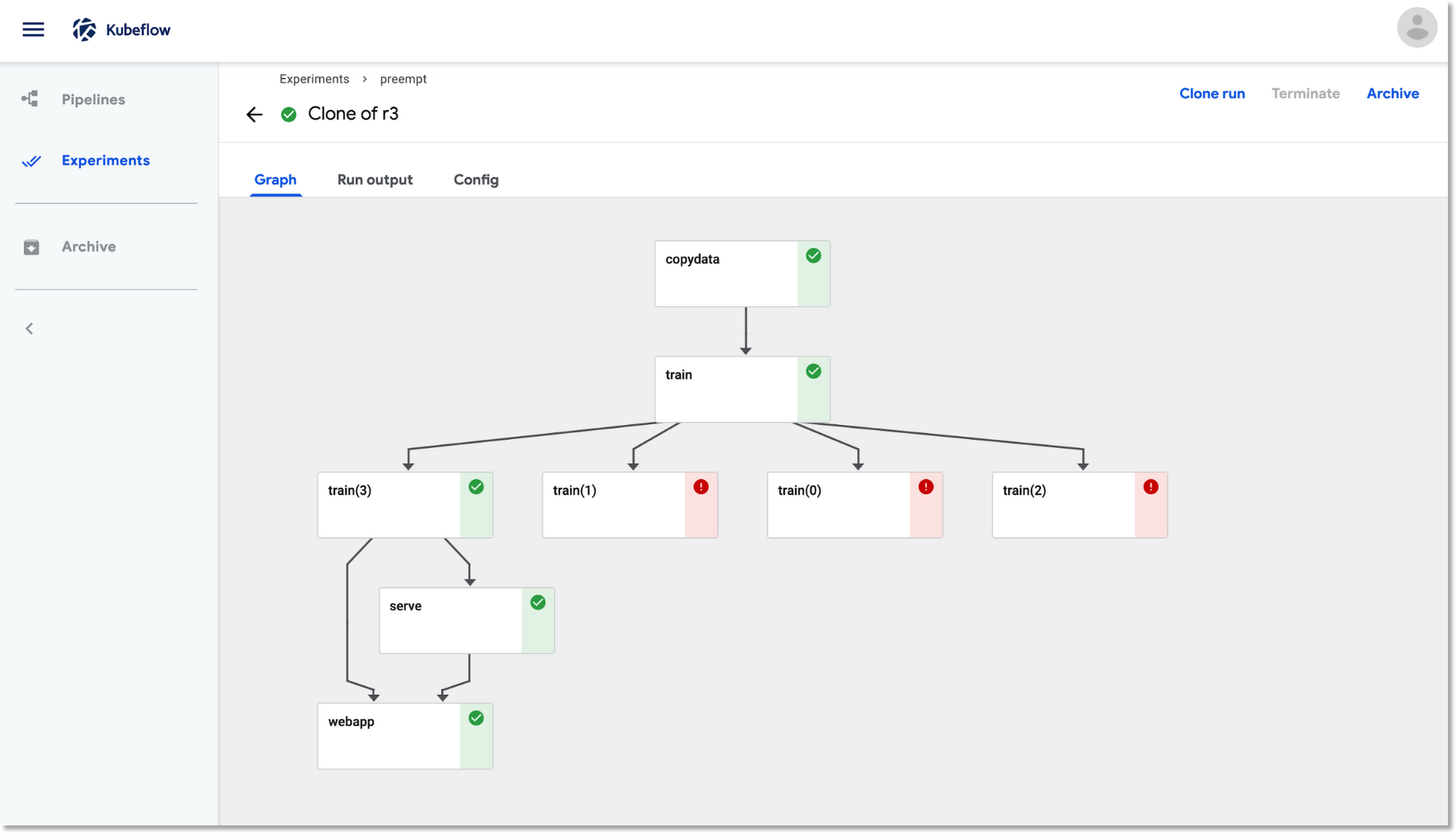
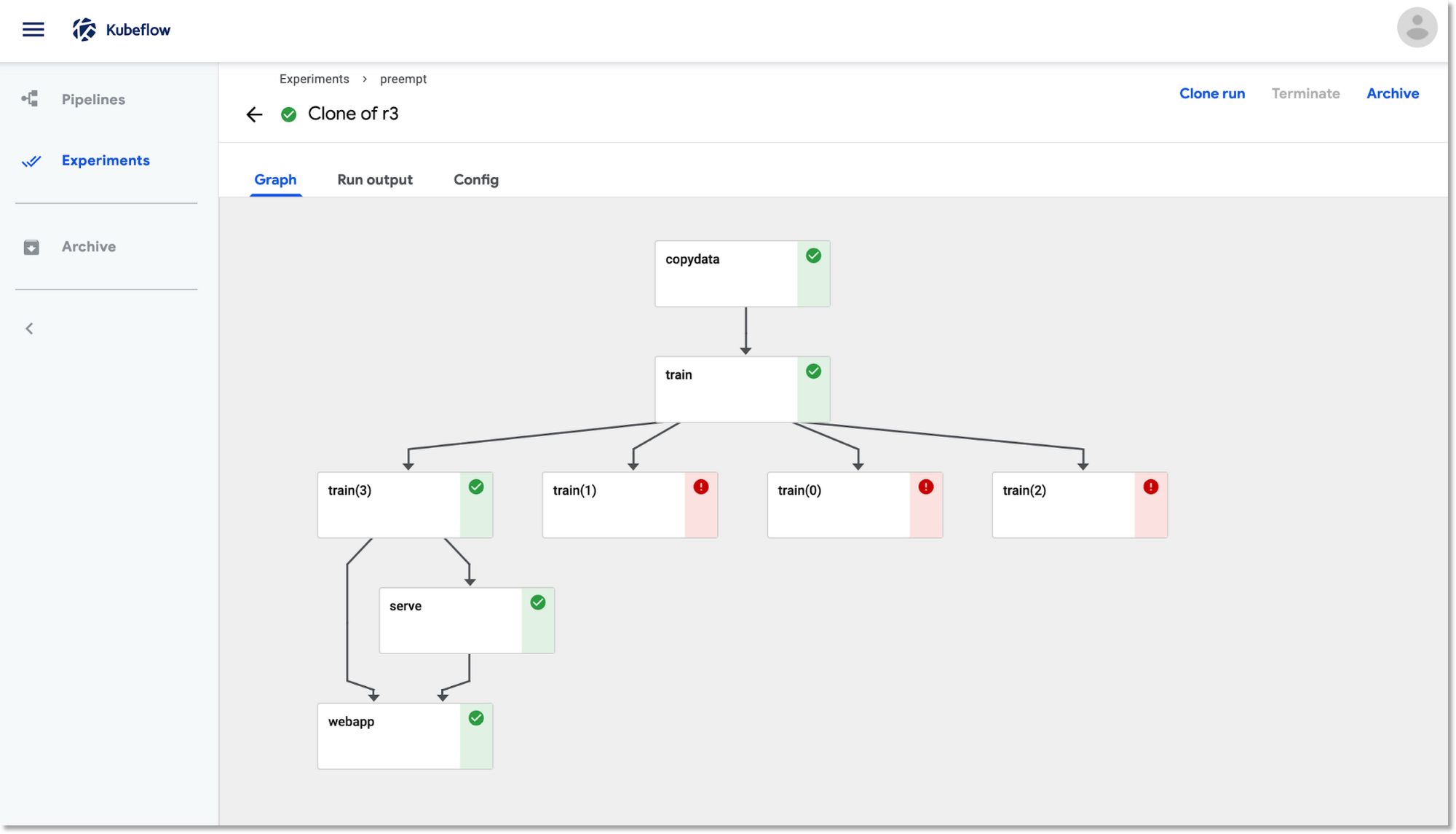
上記のパイプラインの実行時には、トレーニング ステップがプリエンプトされて再開することがあります。その際、Kubeflow Pipelines ダッシュボード UI の表示は以下のようになります。
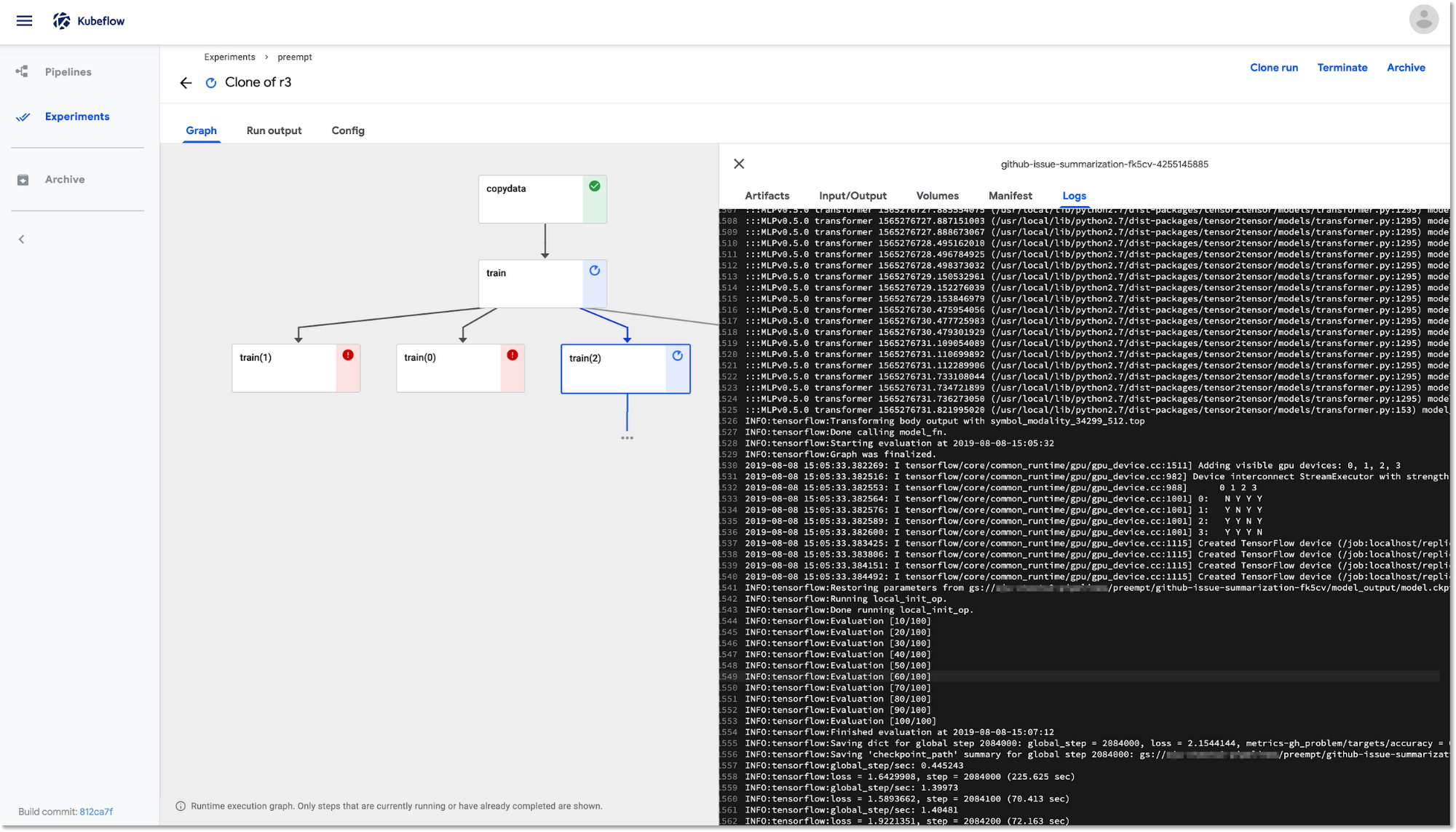
再開したトレーニング ステップは、最後に保存されたチェックポイントを使用して、中断したところから作業を再開します。このスクリーンショットでは、実行中のトレーニング ポッド、 train(2)のログを確認するために、パイプラインの UI を使用しています。
Stackdriver を使用して、ノードのプリエンプションによって終了したポッドのログを確認できます。
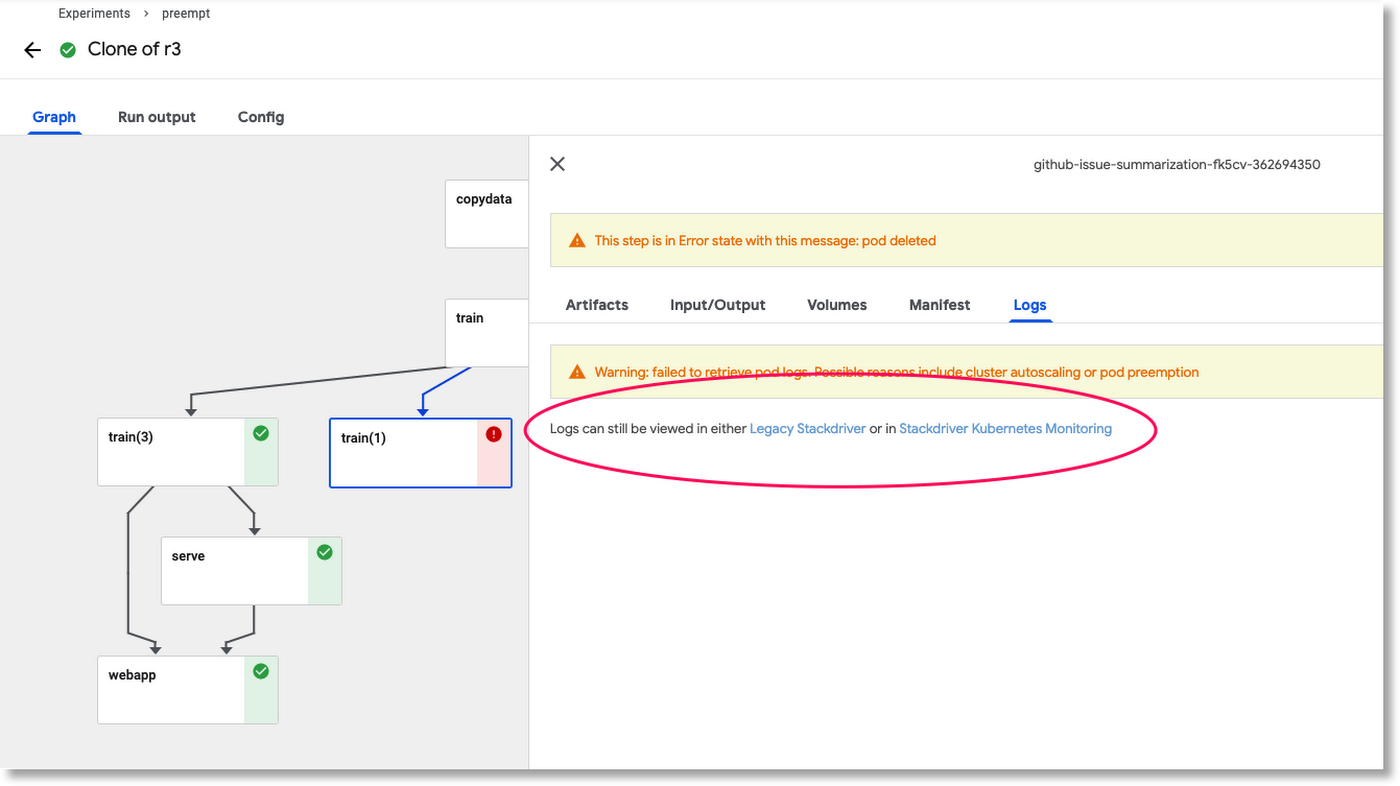
Stackdriver のリンクをクリックすると、ウィンドウが開いて Cloud Console に Stackdriver ログビューアが表示され、そのポッドの出力を選択するフィルタを設定できます。
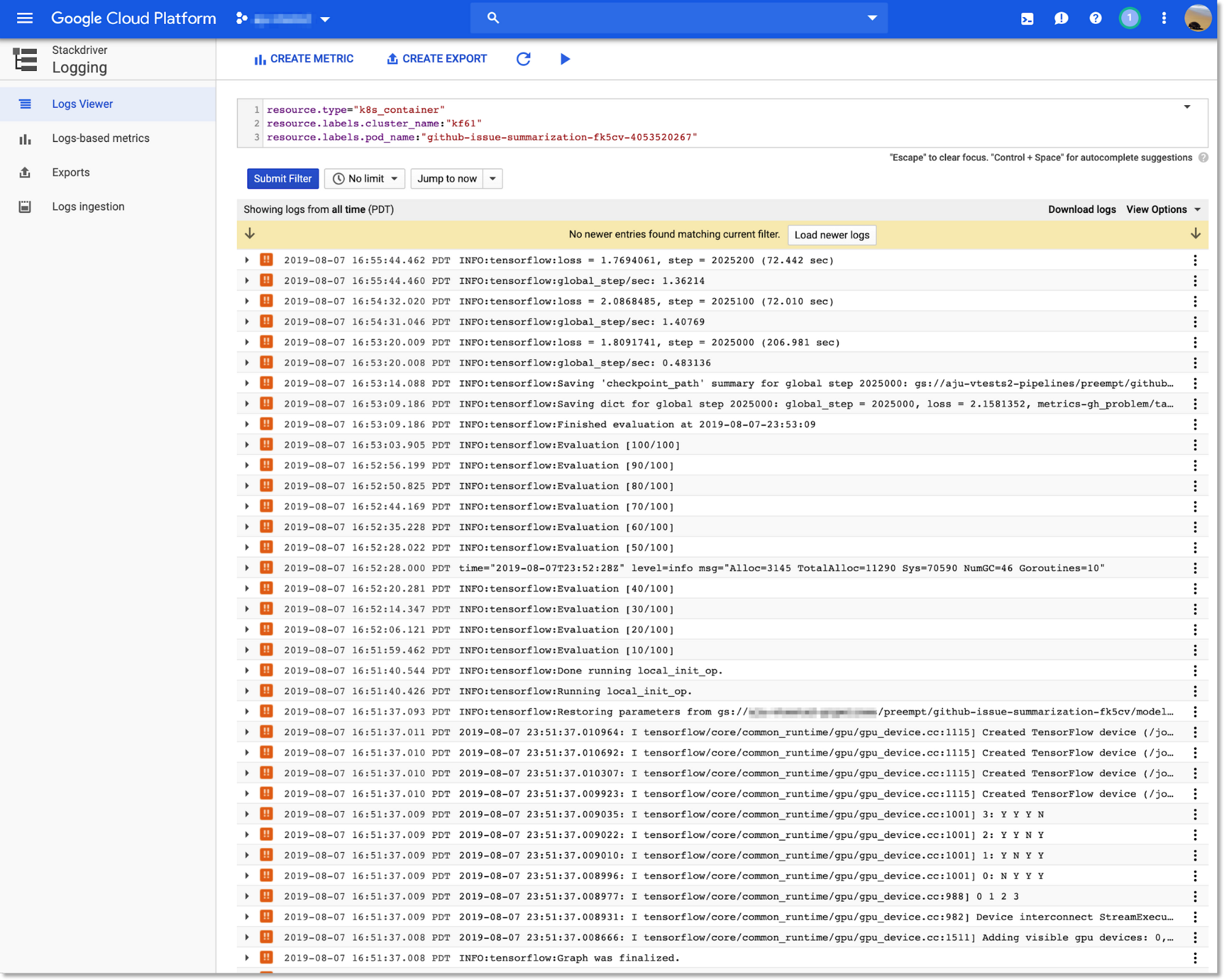
下の図ではこの後、3 回のプリエンプションと再試行の後でトレーニングの実行が完了し、パイプラインの残りの部分が実行されます。
次のステップ
この記事では、Kubeflow Pipelines ジョブに低価格のプリエンプティブル VM を使用することで、コストを削減する方法について詳しく解説しました。前述のように、プリエンプティブル VM は、定期的に実行するモデル トレーニングや、完了時期に余裕がある調整ジョブに最適です。また、大規模な HP 調整の原因分析にも適しています。特定のパイプラインでプリエンプティブル VM を使用したい場合、関連するパイプライン ステップにアノテーションを追加するだけで済みます。例に示したように、アイドル インスタンスへの課金が発生しないようにノードプールの自動スケーリングを定義することも可能です。
Kubeflow Pipelines を含む、Kubeflow の詳細情報と、Kubeflow の無料トライアルについては、Kubeflow のドキュメントと事例リポジトリをご覧ください。最近の Kubeflow コミュニティの会合で発表された Kubeflow 0.6 リリースの新機能についてもご確認ください。
「軽量」な Kubeflow Pipelines デプロイツールを使用すると、GCP プロジェクト レベルの管理者でなくても Kubeflow Pipelines を既存のクラスタにデプロイできます。こちらもぜひお試しください(CloudSQL と Google Cloud Storage の設定に関する詳細はこちらをご覧ください)。
次回の記事では、Kubeflow クラスタの外から Kubeflow Pipelines をリモートでデプロイするための各種の方法についてご説明します。
- by スタッフ デベロッパー アドボケイト、Amy Unruhm



