〜AutoMLで実践する〜 ビジネスユーザーのための機械学習入門シリーズ 【第 3 回】 「積ん読」と「体重増」の悩みを AutoML で解決しよう

佐藤一憲
Google Cloud デベロッパーアドボケイト
前回は、AutoML Tables による EC サイトの LTV 分析事例を紹介しました。今回は、同じ AutoML Tables を、より身近な課題の解決に使う方法を紹介します。
その課題とは、筆者自身が抱えていた 2 つの悩みです。ひとつは、スキャンして PDF で保管している書籍の「積ん読」を大量に抱えていたこと。もうひとつは、自宅作業ばかりで増え続けてしまっている体重です。
この 2 つの課題を一挙に解決するソリューションとして筆者が思いついたのが、「PDF 書籍をオーディオブックに変換する」という方法です。読みたかった書籍をオーディオブック化しておけば、ランニングしながら積ん読を解消できます。

これだ!と思った筆者は、年末年始のヒマな時間を利用して「pdf2audiobook」というツールを開発しました。開発期間は学習データ作成を含めて 2 週間ほど、開発コストは 2 万円弱です。以下の動画は、このツールの利用例です。
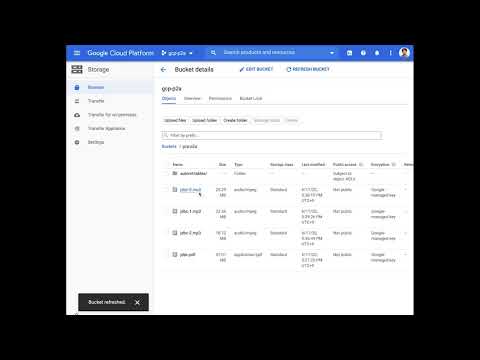
この動画のように、Cloud Storage に用意したフォルダに PDF ファイルをアップロードすると、PDF 書籍の内容が読み上げ音声に変換され、10 〜 15 分ほどで複数の mp3 ファイルとして出力される、という動きです。
実際にこのツールを使い始めてからは、毎日のランニング時に PDF 書籍の未読を消化でき、積ん読は劇的に改善できました。AI 導入による個人的デジタル トランスフォーメーションに成功です。体重の方には目立ったトランスフォーメーションは見られませんでしたが......。
ともあれ、今回はこの pdf2audiobook を Google Cloud の各種サービスと AutoML Tables の組み合わせで短期間・低コストで開発する方法を紹介します。プログラミングと機械学習の初歩的な知識さえあれば、ビジネスユーザーでも Excel マクロを組む感覚で開発が可能です。またここで紹介する手法は PDF からの音声合成だけでなく、例えば見積書や請求書などのビジネス文書から特定部分を切り出すツールとしても応用が可能です。ソースコードはこちらで公開しています。
Cloud Functions でワークフロー実装
pdf2audiobook による PDF ファイルから mp3 ファイルへの変換処理は、以下の流れで進みます。
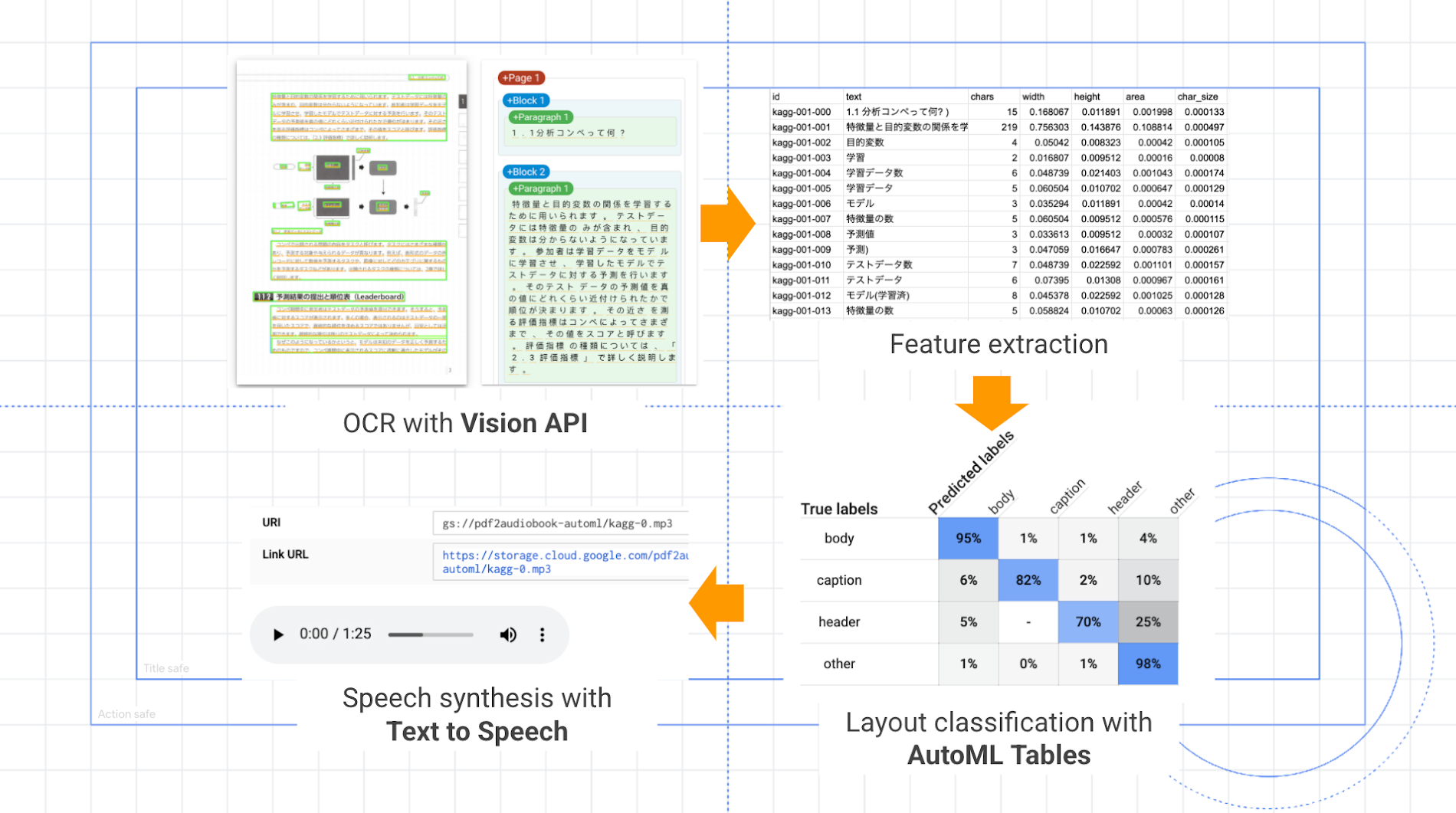
Vision API による PDF からの OCR(文字起こし)
AutoML Tables に入力する特徴量の抽出
AutoML Tables による不要文字列の認識と除去
Text-to-Speech API による 音声ファイル(mp3)生成
このワークフロー全体を記述するために、今回は Cloud Functions を利用しました。

Cloud Functions は、Python や JavaScript、Java 等で記述したコードをサーバレス環境で手軽かつ安価に実行できるサービスで、今回のツールのような簡単なワークフローの実装にはうってつけです。例えば「 Cloud Storage に PDF ファイルがアップロードされたら OCR を開始する」というフローは、以下の Python コードで実装しました。
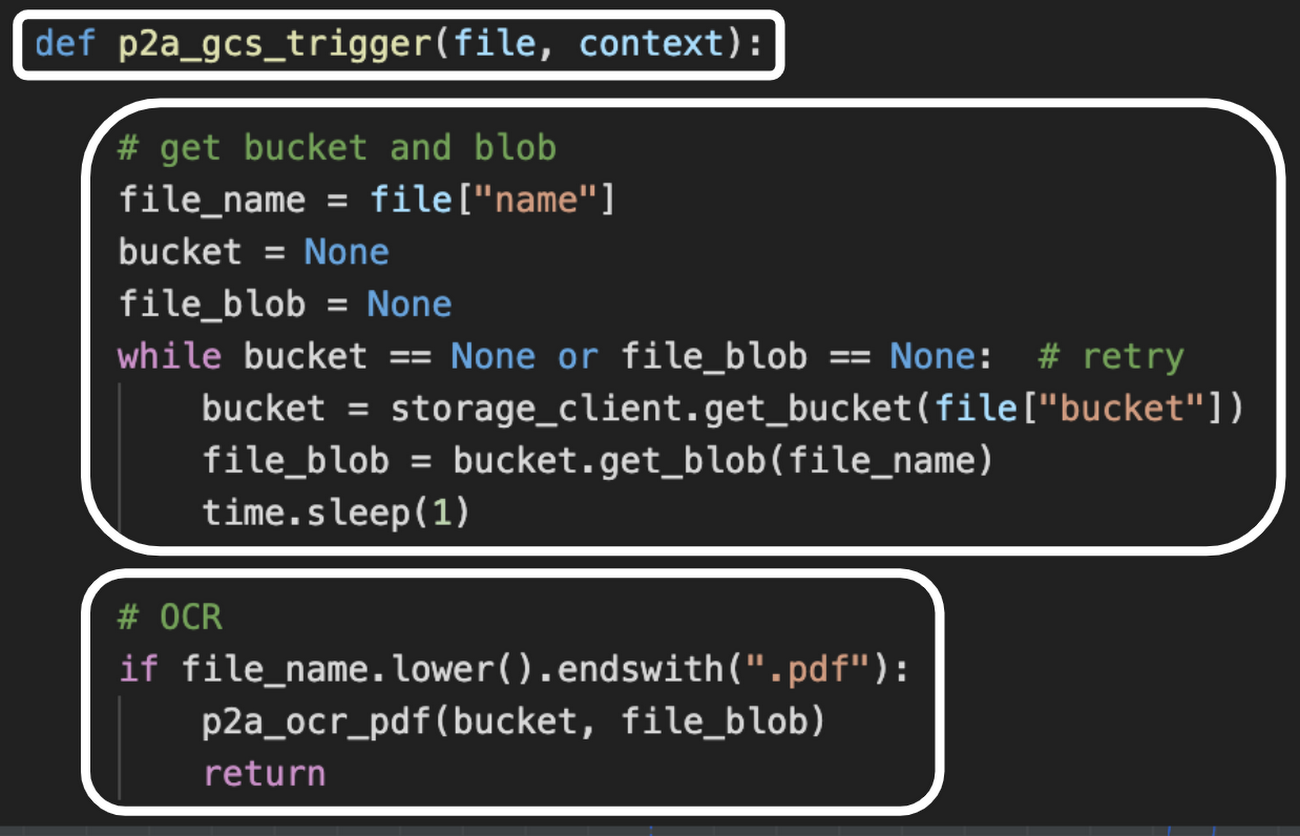
この p2a_gcs_trigger 関数では、1) 引数としてファイル情報を受け取り、2) そのファイル オブジェクトを取得して、3) OCR を実行する関数へ渡します。このように記述したら、以下の gcloud コマンドを実行して Cloud Functions に関数を登録します。

この登録には 1〜2 分ほどの時間がかかります。この例では、実行環境として Python 3.7 を指定し、メモリサイズは 2 GB、タイムアウトは 540 秒に設定しています。登録が完了すると、Cloud Storage の指定したバケットに PDF ファイルをアップロードするたびに p2a_gcs_trigger 関数が実行されます。
pdf2audiobook では、この「Cloud Storage にファイルを保存すると特定の関数が実行される」というトリガー機能を利用して、すべてのワークフローを実行しています。つまり、「PDF ファイル → OCR 済みテキストの JSON ファイル → 特徴量 CSV ファイル → 音声合成用テキストファイル → mp3 ファイル」といった数珠つなぎで処理が進み、また複数のファイルが同時並行で処理されます。
Vision API で文字起こし
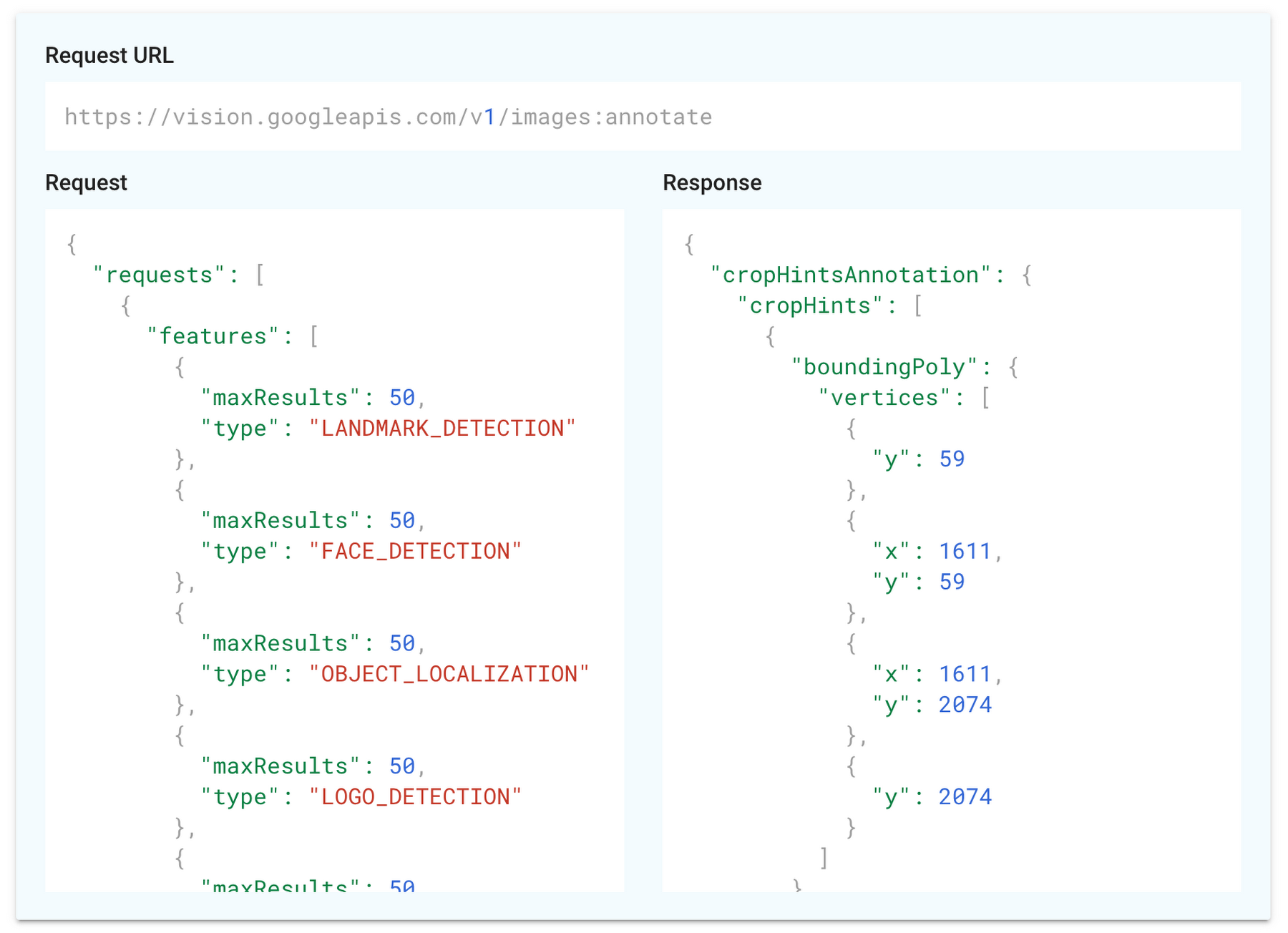
ワークフローの起点は、Vision API による OCR(文字起こし)です。Vision API は多彩な機能を適用しており、画像分類、物体や顔の検出、製品ロゴや有名な場所の検出、不適切画像検出、そして OCR などに対応しています。Vision API の製品ページにある Try the API を使うと、これらの機能を実際に試せます。例えば書籍ページの画像をアップロードすると、以下のような OCR 結果が得られます。
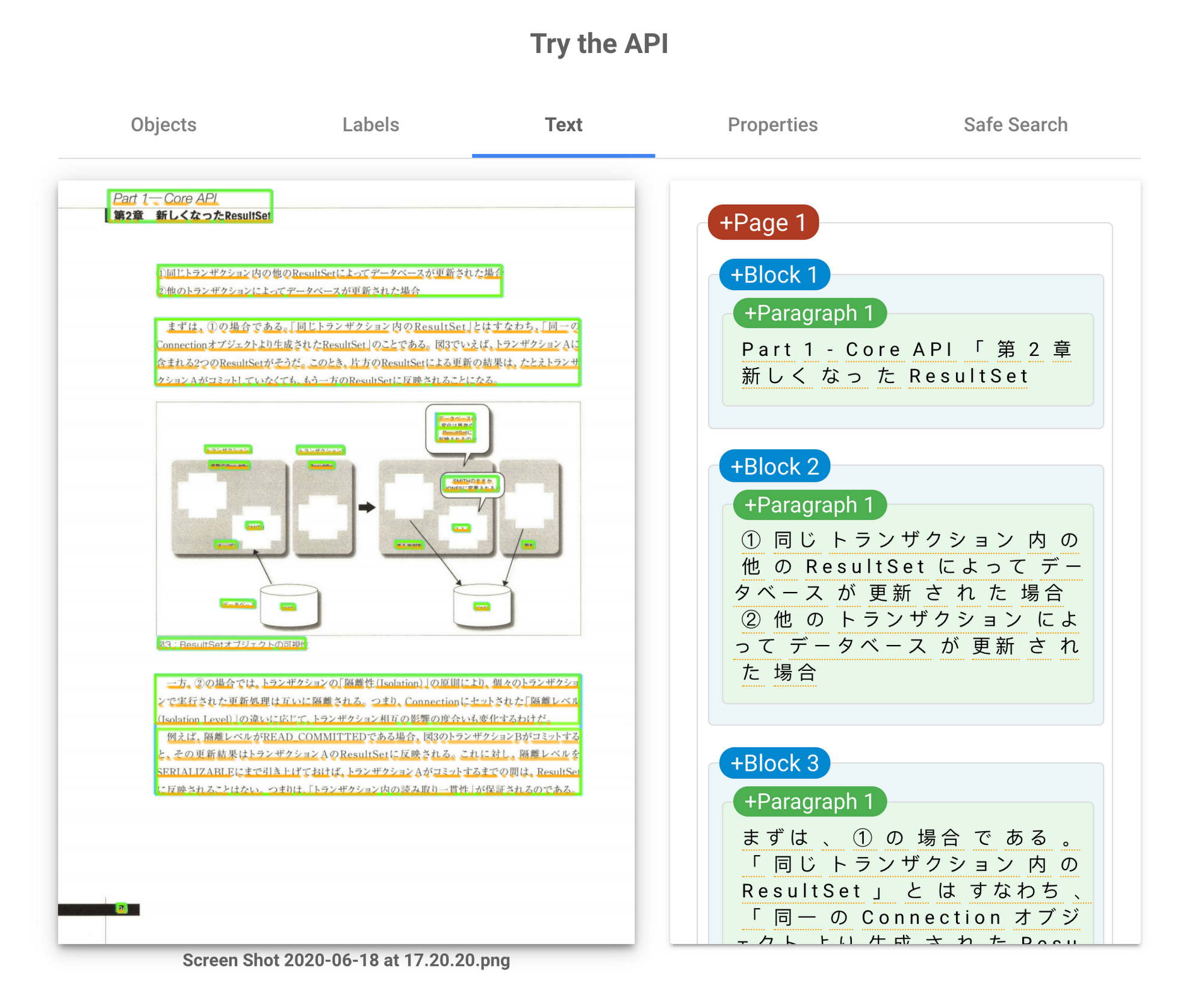
このように、ページ上の文字列がパラグラフ単位で認識されます。同じリクエストを API 経由で送信すると、以下の図の右側にあるような JSON 形式でパラグラフ情報を含むレスポンスが返ります。
この Try the API と同じように Vision API を呼び出すために、上述の p2a_gcs_trigger 関数から呼び出される p2a_ocr_pdf 関数を以下のように記述します。
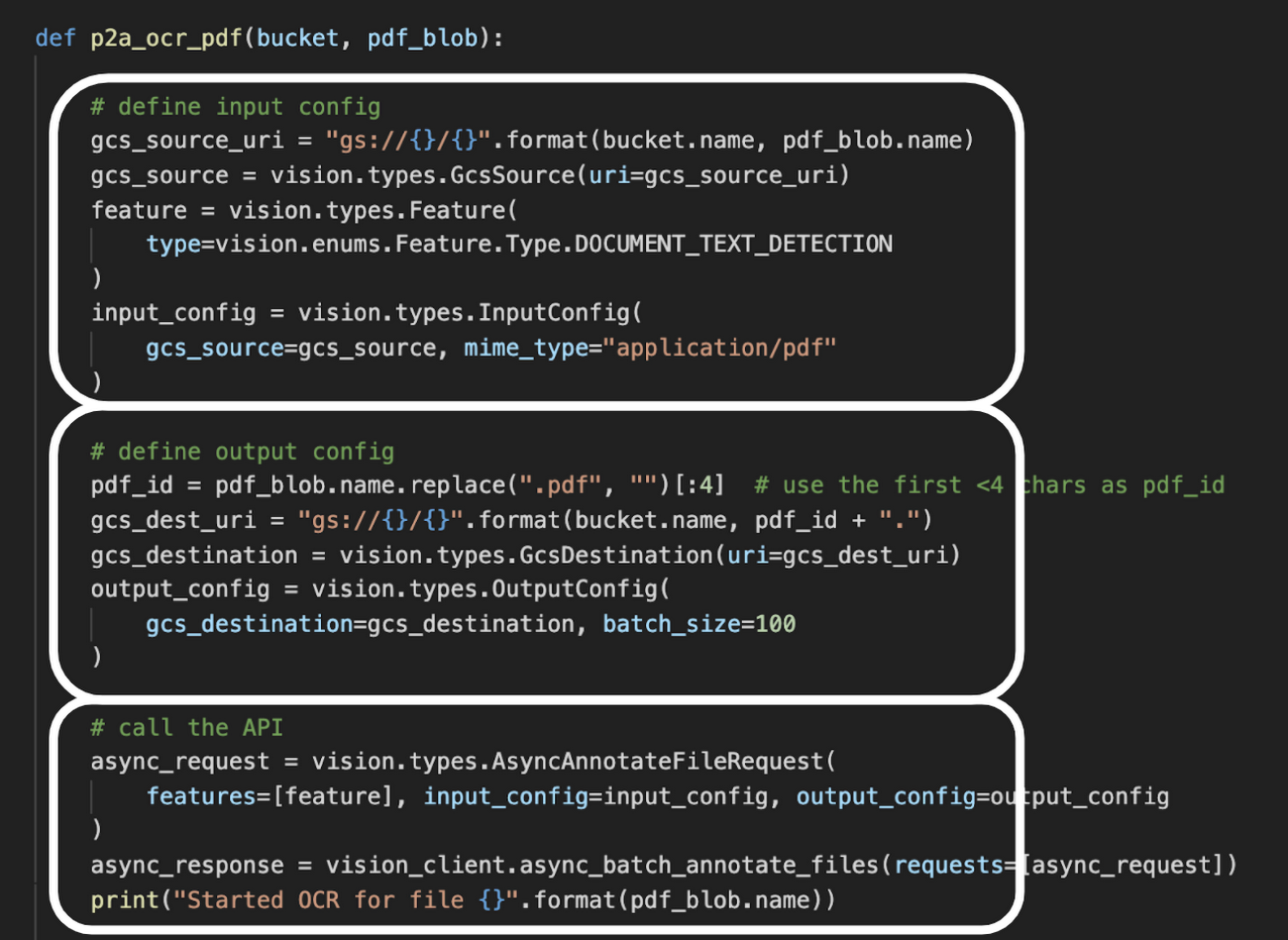
ここでは、1) OCR に必要な設定項目(PDF ファイルの場所、 OCR 機能の指定、ファイル種別は PDF)を指定し、2) 出力先の指定、そして 3) API を呼び出ししています。この呼び出しは非同期(async)呼び出しなので、 OCR 処理を起動したらその完了を待たずにすぐに制御が戻ります。
AutoML Tables で不要文字列を除去
あとは、Vision API が 出力するファイルの文字列を読み上げ音声に変換すればいいわけですが、話はそう簡単ではありません。なぜならこの OCR 結果には、たくさんの「読み上げたくない文字列」が含まれてるからです。
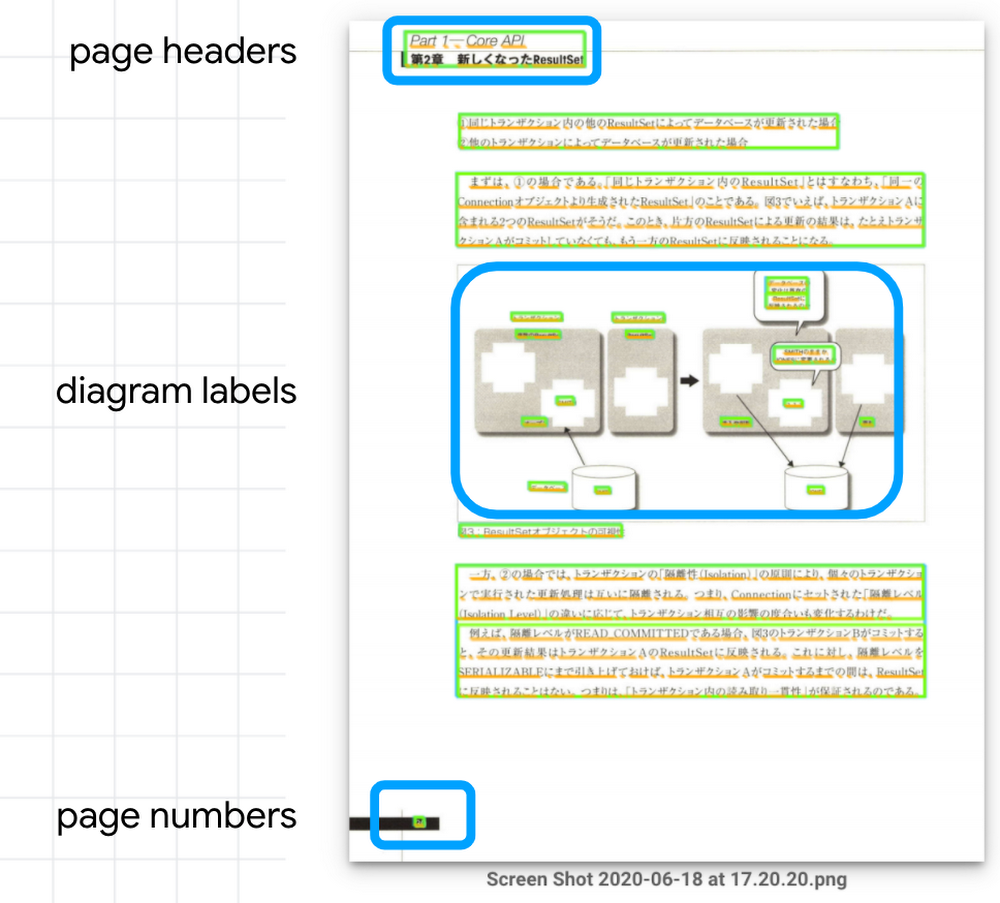
たとえばこの本では、ページ上部に必ず「第 2 章 XXX」といったヘッダーが入り、図の部分には細かなラベルやキャプション、そしてページ下部にはページ番号が入ります。また脚注や索引には「https://www.google.com/... 」のような URL が数多く入りますし、技術書なのでサンプルコードも多く含まれます。
こうした不要な文字列をそのまま残してしまうと、とてもオーディオブックとして快適に聴くことはできません。実際、このツールを作る前はスマートフォンに付属の読み上げ機能も試してみましたが、この問題のために使い物にはなりませんでした。これを AutoML Tables で解決しよう! と思い立ったのがことの始まりでした。
前回のブログポストでも解説されているとおり、AutoML Tables はデータベースのテーブルや表計算シートなどの「表形式データ」について分類や回帰を行う機械学習モデルを自動作成してくれるサービスです。ですので、それ単体では「書籍の画像を認識して不要な文字列を学習する」ような機能はありません。ですが、今回の例では Vision API をいわば特徴量エンジニアリング(機械学習のための学習データを加工・抽出する作業)の手段として使うことで、画像から得られた様々な特徴に基づいて「不要な文字列かどうか」を識別する機械学習モデルを AutoML Tables で作成しています。具体的には、以下の図の features(特徴量)の各値から target(分類結果)を予測するモデルです。
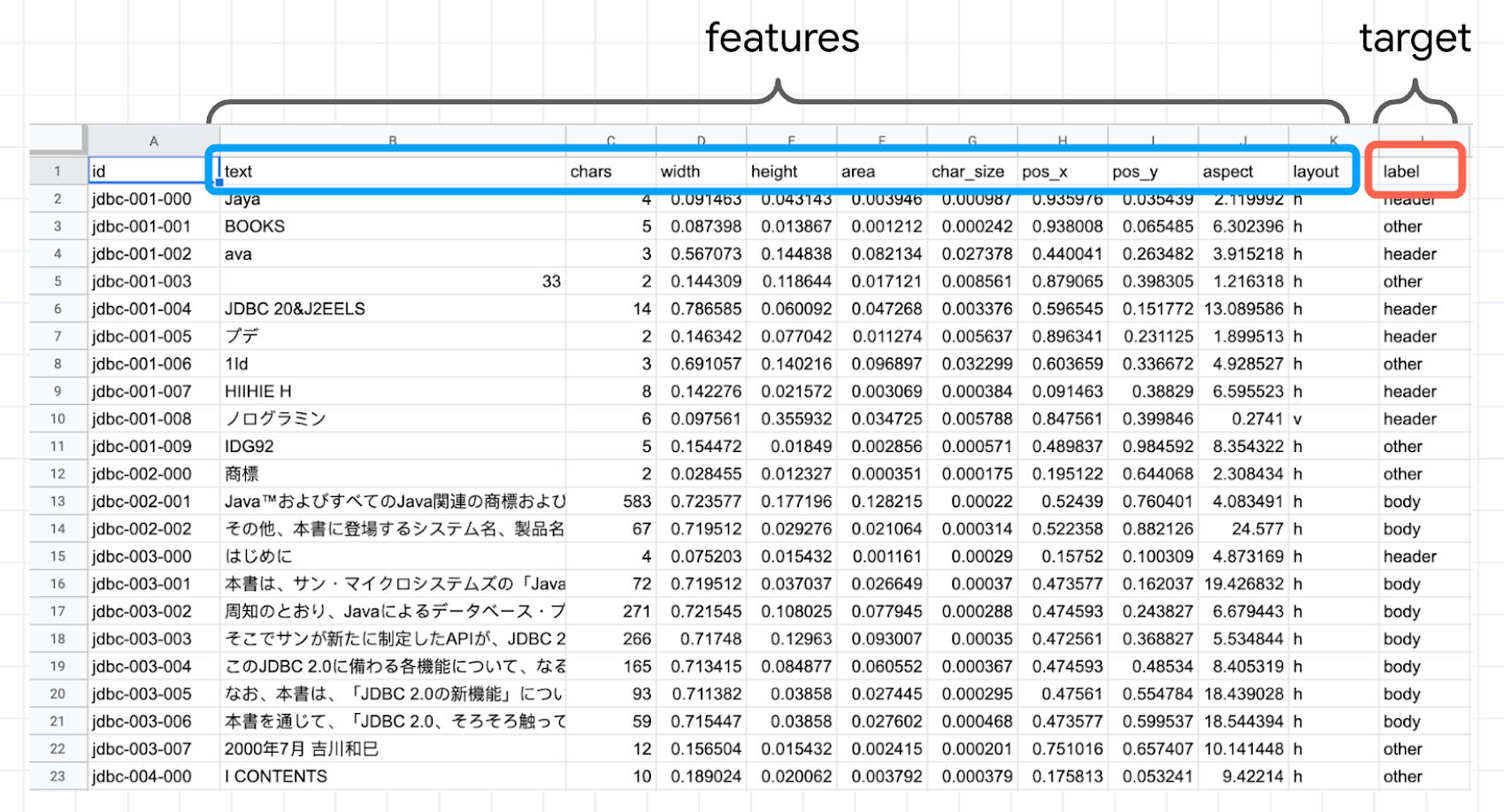
ここで、特徴量としては以下の各値を Vision API の OCR 結果から得ています。
text:パラグラフの文字列
chars:パラグラフの文字数
width, height, area:パラグラフの縦横サイズと面積(縦×横)
char_size:パラグラフの文字サイズ(面積÷文字数)
pos_x, pos_y:パラグラフ中心の位置
aspect, layout:パラグラフの縦横比、縦長か横長か
これらの特徴量から、label の値を以下のいずれかから予測します。
body:本文
header:セクションの見出し
caption:図の見出し
other:その他(読み上げ不要な文字列)
ここでポイントは、パラグラフに含まれる文字列そのもの(text)も特徴量として AutoML Tables に与えていることです。このドキュメントでも解説されているとおり、AutoML Tablesでは個々の特徴量のデータ型に応じて適切な特徴量エンジニアリングを自動的に実行してくれます。今回の text 属性のような文字列の場合は、AutoML Tables が内蔵する自然言語処理(NLP)機能による特徴量抽出が行われるため、NLP のためのコードを自作する必要はありません。これにより、例えば「https://www... 」や「p. 10」、「public static void main(...」といった明らかに読み上げに相応しくない英数字の羅列かどうかを判断してくれると期待できます。
もうひとつのポイントは、パラグラフの縦横のサイズ、配置位置、文字数といった図形情報も特徴量に加えている点です。例えば、各ページに振られたページ番号には「ページの左下か右下にある」「面積は小さく文字数は少ない」といった特徴がある一方で、本文パラグラフには「ページの中央付近にある」「面積は大きく文字数は多い」といった特徴があります。これらも、読み上げ不要なパラグラフかどうかを判断する要素として加味してくれることを期待できます。
一方、AutoML Tables でも自動化できない作業は、学習データの作成です。1 冊の PDF 書籍を Vision API により OCR すると、約 5000 個のパラグラフが出力されます。これらを Google スプレットシートに読み込み、パラグラフごとに label の値を手入力していきました。この作業には 1 冊あたり 2 〜 3 時間かかります。数冊分の学習データを作成したところで筆者は音を上げてしまい、後述するアノテーション ツール(ラベル入力支援ツール)の開発を始めてしまいました。このツールのおかげで、最終的には 12 冊分、約 6 万パラグラフの学習データを用意できました。
さて、ここでひとつ注意した点は、機械学習の落とし穴のひとつであるリークの発生です。もし、この 12 冊分の学習データをそのまま AutoML Tables に渡してしまうと、6 万件のパラグラフが学習データ 80%、検証データ 10%、テストデータ 10%と自動的に分割されます。しかしこれでは、個々の書籍の内容が学習・検証・テストに分散してしまうため、「書籍のある部分で学習した、同じ書籍の別の部分を予測するモデル」を作成することになります。これは、機械学習で発生する典型的なリークです。
pdf2audiobook の機械学習モデルに本来求められるのは、「これまで見たことのない書籍についても十分な精度で予測できる汎化性能」です。そこで、AutoML Tables に対してデータ分割列を明示的に指定し、学習・検証・テストの各段階で別々の書籍を割り当てるようにしました。
AutoML Tables で学習
学習データを用意したら、AutoML Tables を使って学習を行います。以下の動画では、データのインポートから特徴量とターゲットの選択、学習開始までを紹介しています。
開発中であれば、とりあえず学習時間を 1 時間に設定したお試しの学習を行うことで、一回あたりの課金は 19.32 ドル(2021 年 3 月現在)に抑えられます。このお試し学習で得られたモデルの評価レポートを見て「使い物になりそうだ」と判断したら、学習時間を 3〜4 時間程度(データ件数が 10 万件以下の場合)に設定することで、より高い精度のモデルが得られます。
学習が終わると、メールにて終了の通知が届きます。評価レポートを見ると、Precision は 95.0%、Recall は 94.3% と、なかなか高い精度のモデルができた様子が分かります。
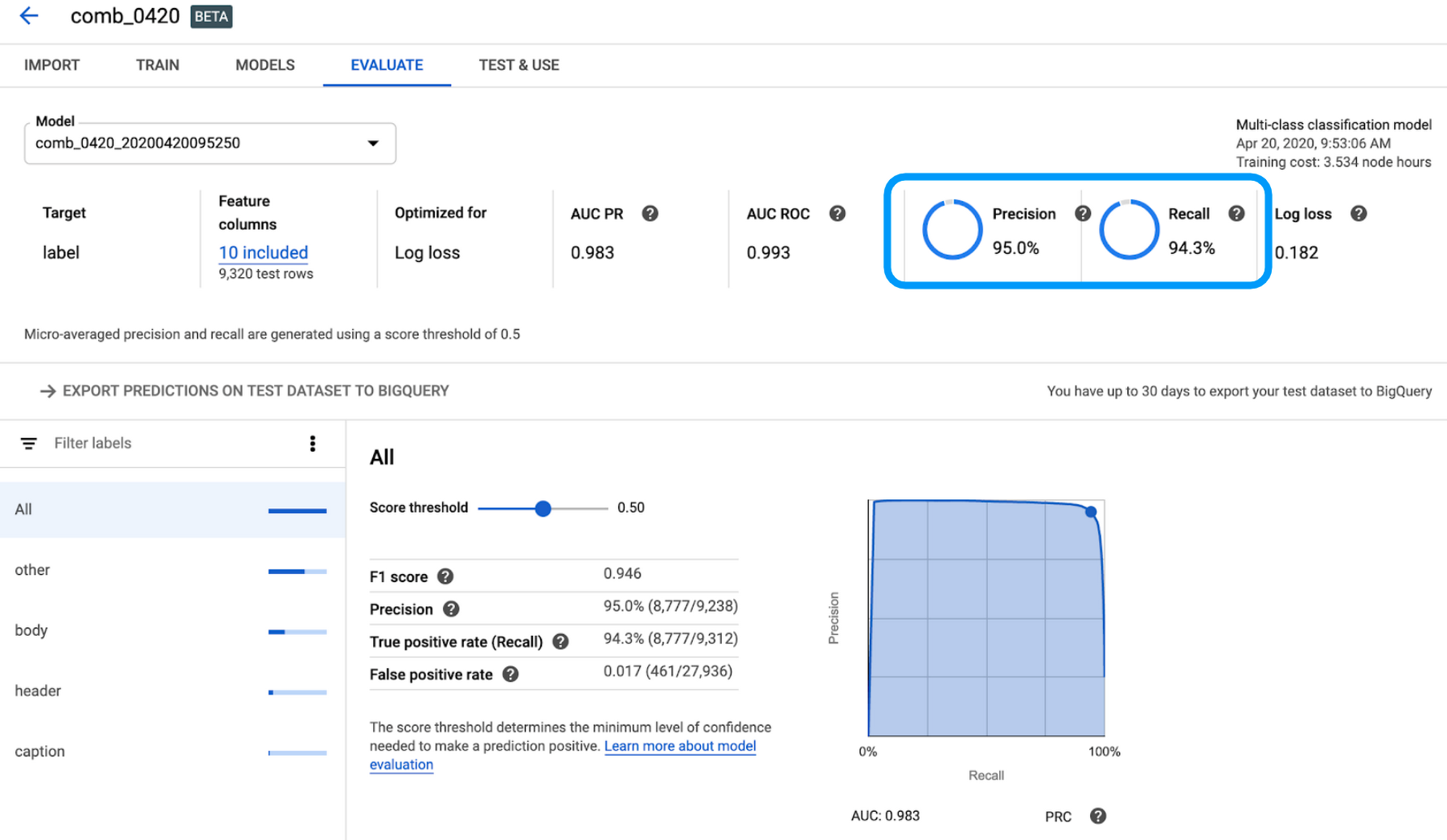
また、評価レポートには混同行列(confusion matrix)と特徴量重要度(feature importance)も記載されています。
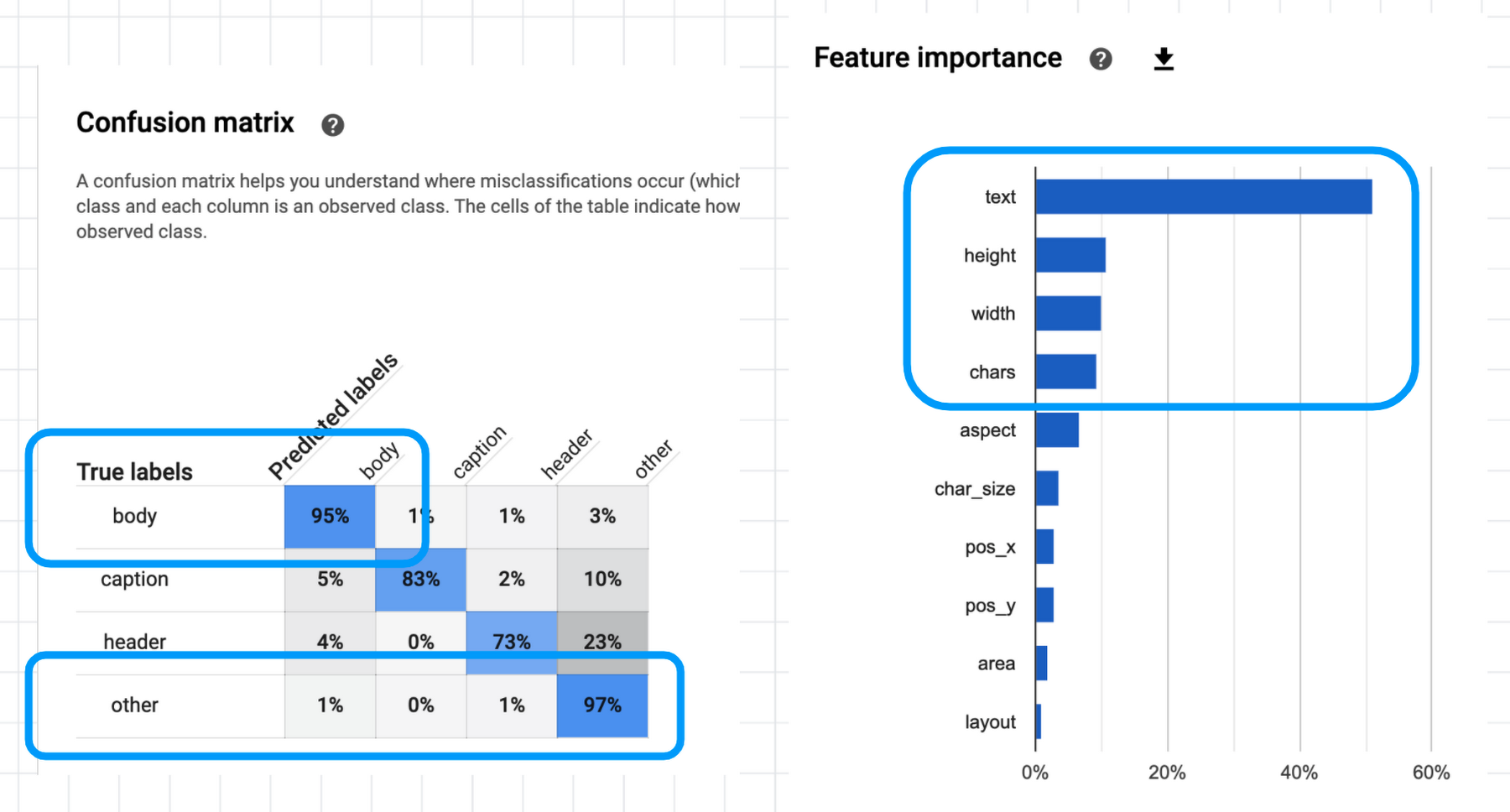
混同行列を見ると、例えば body (本文)は 95%、other(不要文字列)は 97% 精度で予測できることがわかります。学習とテストに別々の書籍を指定した上でこの程度の精度が得られるのであれば、十分実用になりそうです。
また特徴量重要度では、やはり text(パラグラフの文字列)がいちばん重要な特徴量として参照され、つづいて height, width(パラグラフの縦横サイズ)、chars(文字数)を見て判断していることがわかります。一方、area(面積)や layout(縦長か横長か)はあまり使われてなさそうなので、特徴量から外してもいいかもしれません。
不要文字列を除去、音声読み上げ生成
AutoML Tables によるモデル学習が完了したら、それを使って不要文字列を除去するコードを記述します。Vision API で得られた文字列を特徴量データに変換して Cloud Storage に保存したのち、以下のコードで AutoML Tables によるバッチ推論を実施します。
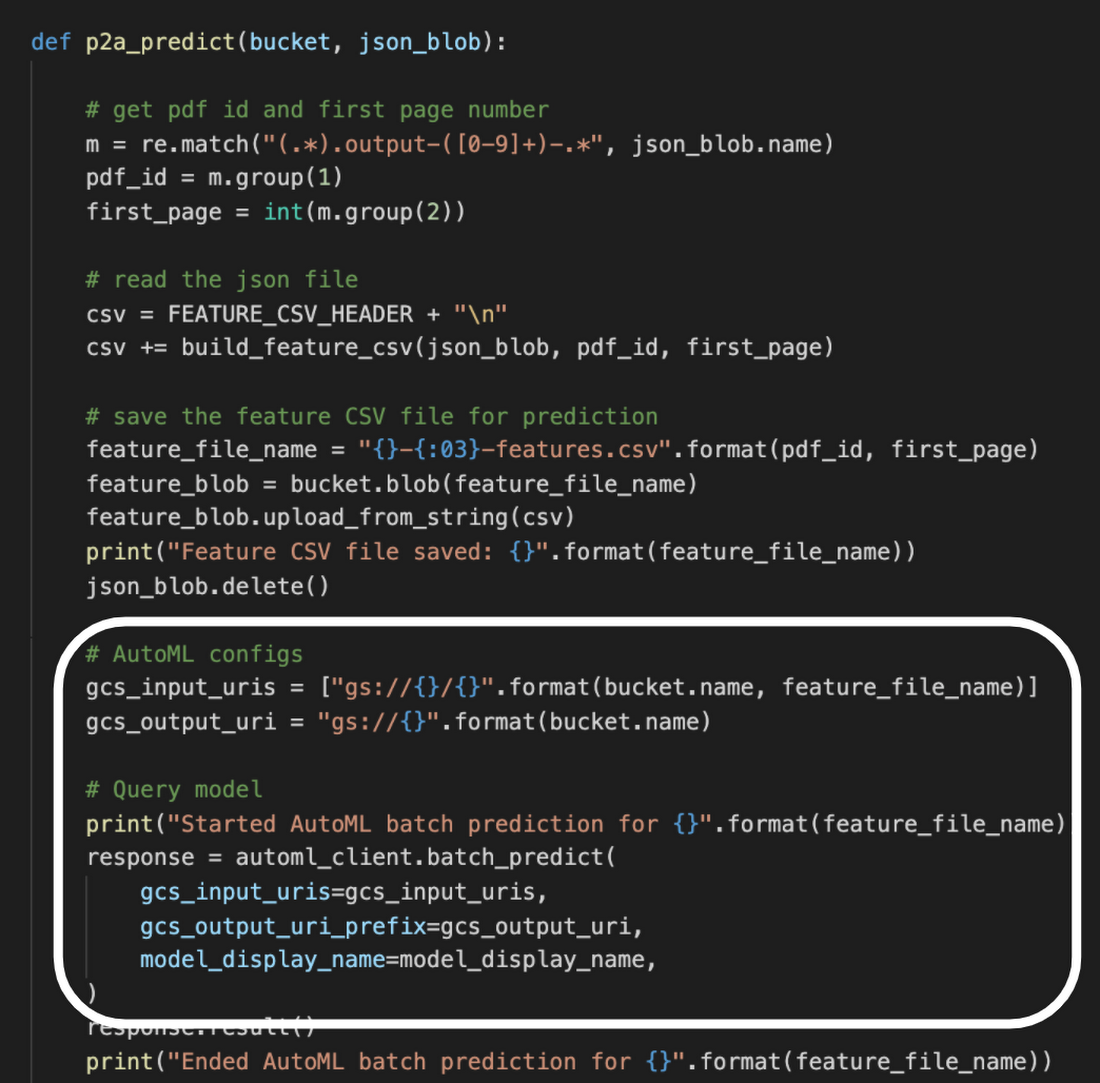
これにより、数分後には個々のパラグラフに推論結果の label が付加された CSV ファイルが Cloud Storage 上に出力されます。
最後に、Text-to-Speech API による音声合成を行います。その準備として、個々のパラグラフを SSML(Speech Synthesis Markup Language)の break タグで括り、パラグラフの種類に応じて間を空ける指示を追加します。例えばセクション見出しの場合は 1.5 秒ほど間を開けるとセクションの始まりが聴いて分かるようになり、棒読みが延々と続くのではなく緩急のついた聴きやすいオーディオブックになります。
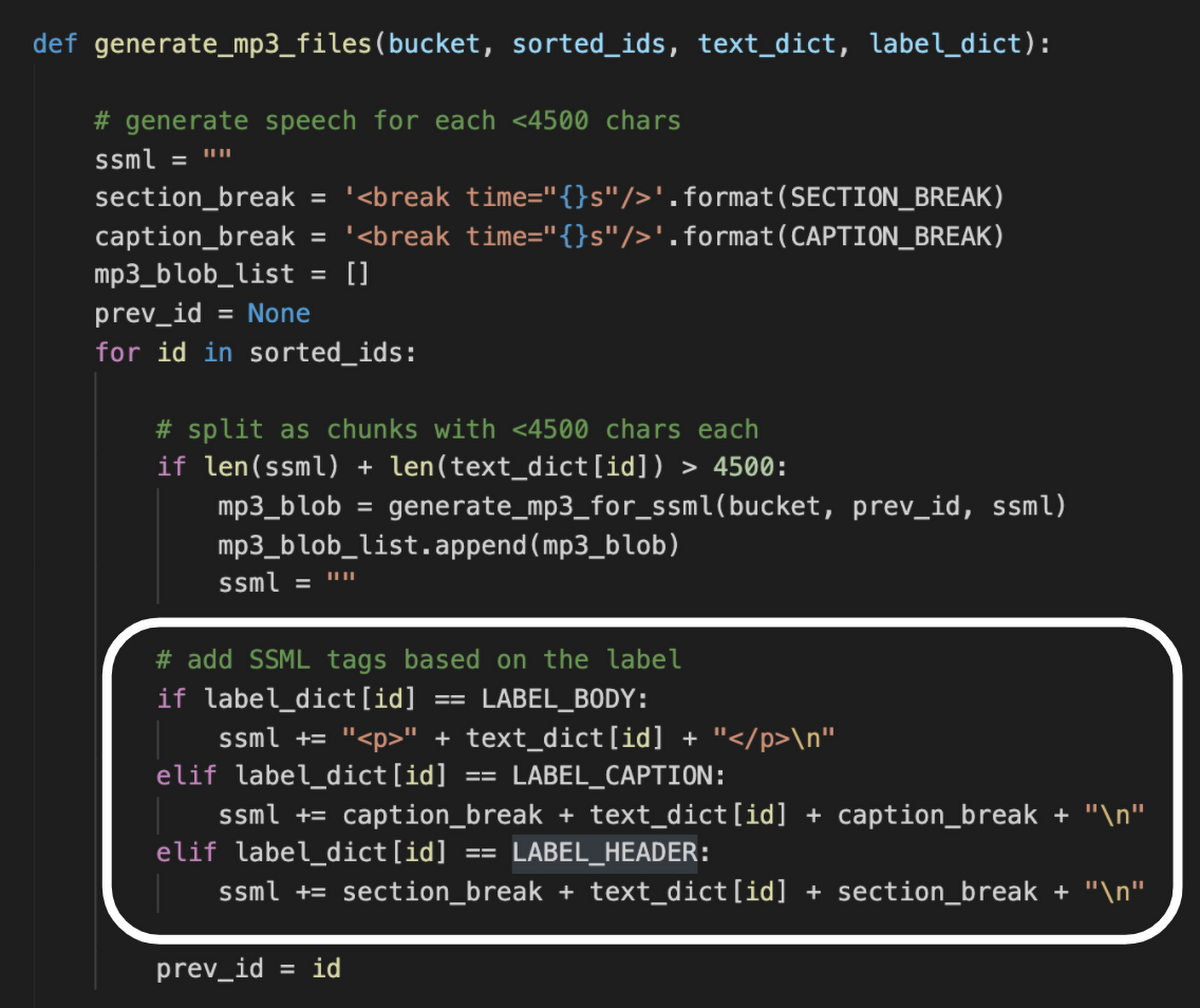
SSML を付加したら、音声合成を開始します。しかし、ここでちょっと実装に手間取りました。Speech-to-Text API では、渡せる文字数が 1 回あたり 5000 文字に制限されています。そのため、1 冊の書籍全体を 4,500 文字単位に分割して API 呼び出しを行う必要があります。これにより生成された細切れの mp3 ファイルを連結し、1 冊あたり 3〜4 個の大きな mp3 ファイルに変換しています。この連結処理に時間がかかりメモリ消費も大きいため、Cloud Functions のメモリサイズと処理時間を最大値に指定することで対応しました。
Apps Script でアノテーション ツール開発
pdf2audiobook 本体は以上のような仕組みです。が、じつは開発期間の大幅短縮に威力を発揮したのがアノテーション ツール(ラベル入力支援ツール)でした。
アノテーションとは、学習データのラベルを人の手で入力する作業のことです。前述のとおり、pdf2audiobook の 1 冊分のパラグラフ データに対して Google スプレッドシート上で label を手入力するには 2〜3 時間かかります。この大量のアノテーション作業を実際に自分でやってみて初めて気づいたのは、「アノテーション作業の集中力を持続できるのは 1 日 3〜4 時間が限界」ということです。それ以上続けてもアノテーションのミスが増えてしまい、学習データの品質がどんどん下がってしまいます。しかし学習データの量は機械学習モデルの精度を大きく左右するので、少なくとも 10 冊以上のデータを短い休暇期間中に用意する必要がありました。
そこで急遽作成したのが、「機械学習の学習データ作成を機械学習で支援するアノテーションツール」です。以下の動画のような UI を提供します。
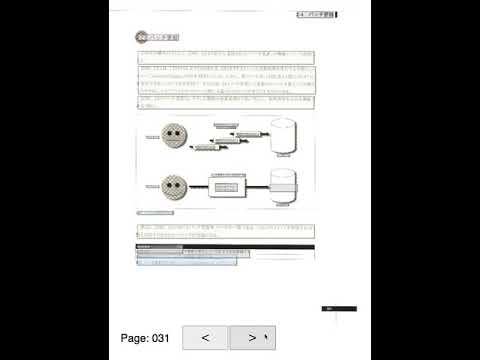
このように、読み込んだ書籍のページが表示され、Vision API によって認識された各パラグラフが色分け表示されます。緑=本文、灰色=不要文字列、といった具合です。この UI 上で、個々のパラグラフが正しく色分けされているか確認し、間違っている場合はクリックしてラベルを切り替える、という操作です。このパラグラフの色分けは、AutoML Tables による予測結果をもとに表示されています。つまり、それまでに作成した少量の学習データで AutoML Tables の学習を行い、そのモデルを使ってアノテーション ツールの UI 上でパラグラフを色分け表示します。
初期段階ではモデルの精度が低いので、色分けには間違いが多く含まれます。とはいえ、モデルの予測が間違えている部分だけをクリックして直せばよいので、すべてのラベルを手入力するアノテーション作業に比べれば格段にラクになります。そして 1 冊分のデータを作成したら、再度 AutoML Tables で学習し、精度が向上したモデルで次のアノテーション作業を行い、継続的に作業効率を上げていく......というループを形成できます。これは素朴なアクティブラーニング(機械学習モデルと人間が協調しながら学習データを作成しモデル精度を上げていく手法)と言えるかと思います。
このアノテーション ツールは、Google Apps Script を使い実装しました。Apps Script には簡単な Web アプリ開発の機能があります。これを活用し、Google スプレッドシートから学習データを読み込み、個々のパラグラフに対応するボタンを HTML ページ上の DOM を操作する短いコードを書きました。

このアノテーション ツールの導入によって、1 冊のラベル付けにかかる時間が 15 分ほどにまで短縮できました。およそ 10 倍の生産性向上です。
以上、今回は AutoML Tables を身近な課題の解決に使ってみた事例を紹介しました。前述の通り、学習データ作成やアノテーション ツール構築も含めて開発期間は 2 週間ほど、コストは 2 万円弱で収まりました。Excel マクロ感覚で機械学習を手軽に活用できる AutoML 技術、ぜひ皆さまもお試しください。




