〜AutoMLで実践する〜 ビジネスユーザーのための機械学習入門シリーズ 【第 1 回】Cloud AutoML 概要と事前知識

吉川 隼人
Google Cloud カスタマーエンジニア
ここ数年間で機械学習をビジネスに利用する企業が非常に増えてきました。一方で、機械学習を扱えるエンジニアが不足していたり、思ったほどビジネスでの価値を得られなかった、やろうとしていた事がそもそも機械学習に向いていなかった、といった課題や声を聞くことも多くなりました。どうしてこのような事が起こるのでしょうか?これらの課題を解決するには、機械学習に直接取り組むエンジニアだけでなく、ビジネス ユーザーも機械学習という技術に対してある程度の理解をしておく必要があります。このブログポストでは、ビジネス ユーザーを対象に、Cloud AutoML というプロダクトを通して機械学習をビジネスに役立てるための基礎知識を紹介します。
ところで、AutoML というのは技術の名前、Cloud AutoML はその技術を用いた、GCP の一部であるプロダクト群の名称です。元々 Cloud AutoML は独立したプロダクト群でしたが、AI Platform への統合が進められています。
ML (機械学習) のおさらい
AutoML とは何でしょうか? AutoML と聞くと、「ML の何か」を自動にしたと想像がつくでしょう。ということは ML の中で、自動じゃなかった部分がどこなのかを説明すると、それが自動になった AutoML についても理解が深まりそうです。ML についての詳細な説明は省きますが、ここでは簡単に ML とは何かを解説します。
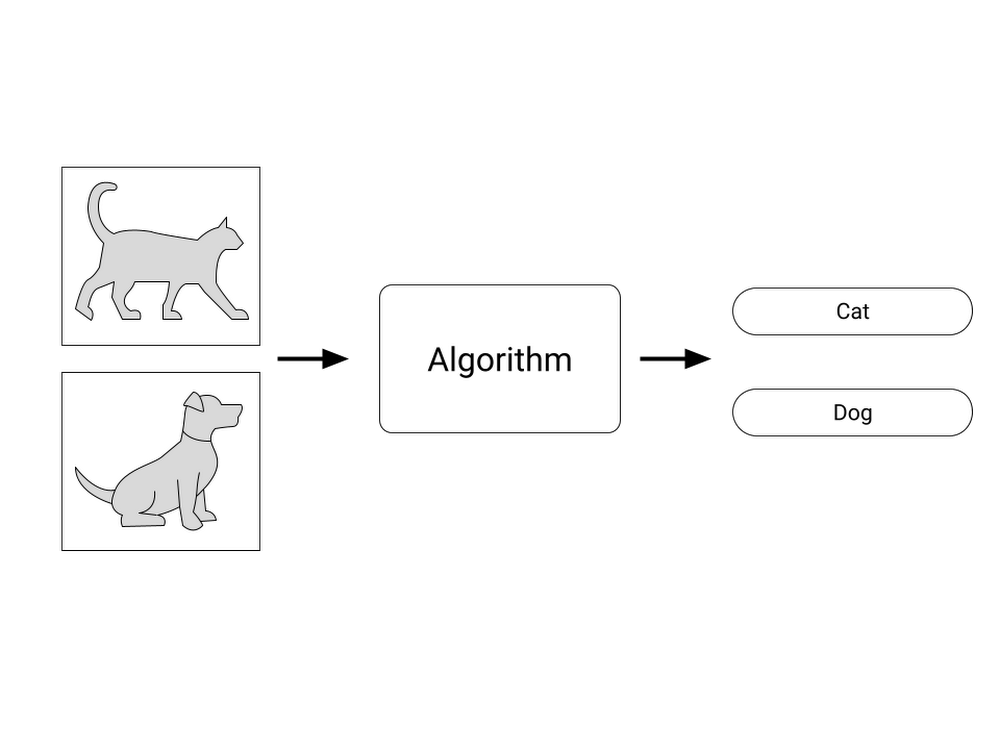
ML (Machine Learning, 機械学習) とは何でしょうか?カーネギーメロン大学でコンピュータ・サイエンスを教える Tom Mitchell 教授の書籍によると、ML とは「経験を通して改善されるコンピュータ・アルゴリズムの研究である」とあります。よく ML と AI (Artificial Intelligence, 人工知能)は区別されずに使われるケースがみられますが、ML そのものはアルゴリズムなのです。例えば、画像の識別をしたい場合を考えてみます。ここでは簡単に画像から犬と猫を識別したいとしましょう。ある画像が入力されたとき、その画像が犬なのか、猫なのかを判別するという意味です。ML では、画像を入力として期待の結果(犬なのか猫なのか)が得られるよう何らかの方法(後ほど解説します)で識別ができるようするアルゴリズムというわけです。ML の世界では、このアルゴリズムの箱のことをモデルと呼びます。
学習とハイパーパラメータ
さて、さきほど ML は期待の結果が得られるよう「何らかの方法」で識別すると述べました。この何らかの方法は、「学習」と呼ばれています。読者のみなさまも、ML はデータをたくさん与えて学習させれば、何かいい感じの結果を出してくれるというイメージを持たれている方も多いのではないでしょうか?
この学習の工程では、ML は期待の結果が得られるよう、学習用のデータをもとにたくさんのパラメータを自動的に調整します。先ほどの犬と猫の画像を例にみていきましょう。図 1 では、犬か猫の画像をアルゴリズムに入力し、「犬」もしくは「猫」というラベルを出力していました。学習の過程でも、同じように犬と猫のいろんな画像を入力します。デジタルの世界の画像は、画素と呼ばれる小さな点に数値の色情報が格納されているため、数値データとして演算することができます。犬や猫の画像も、数値データ(画素)のかたまりですし、出力結果の「犬」「猫」に対してもそれぞれ0と1とすれば入力も出力も数値で表すことができます。
入力と出力が数値で表せることがわかったので、これをどのように演算すれば期待の結果になるのかをもう少し詳しくみていきましょう。犬と猫の例のように画像の識別では、一般的に畳み込み層と呼ばれる画像フィルタと同じ動きをする層を複数重ね、入力された画像を処理していきます。最終的に「犬」、「猫」のラベル(今回、0と1の数値をあてはめました)が出力されるよう、各畳み込み層やその後に続く別の種類の層のパラメータをなんども微調整していきます。これをたくさんの画像で繰り返すと、最終的に画像の中の特徴を捉える畳み込み層が得られます。
このように、ML ではパラメータが自動的に設定されますが、全てのパラメータが自動的に設定されるわけではありません。例えば畳み込み層をどれくらいの大きさのものにするのか、何層重ねるのかなどは設計者があらかじめ学習の前に設定しておく必要があり、自動的には決まりません。このように人が設定しないといけないパラメータはハイパーパラメータと呼ばれます。ハイパーパラメータの最適値は絶対的に決まるものではなく、経験的に設定したり、複数のハイパーパラメータを試して精度の良いものを採用する(ハイパーパラメータ チューニング)などの方法がとられています。
また、上では層を重ねると表現しましたが、実際に画像処理で使われる層の構造(ニューラルネットワーク、または単にネットワーク)は層が一列に並んでいるわけではなく、分岐や結合が含まれる複雑な形状をしています。よく知られているネットワークだけでも、GoogleNet、Inception、MobileNet、VGG などなど、たくさんの構造があります。自分のやりたい識別はどれが一番適切なのか、はたまたどれをベースにどこを改良したらよいのか…これを決めるのも、設計者なのです。とてもノウハウや知識が必要なことがイメージできたのではないでしょうか。
1. ここでは簡便のため識別として説明をすすめますが、ML は識別以外にも回帰などの種類もあります。
学習と推論
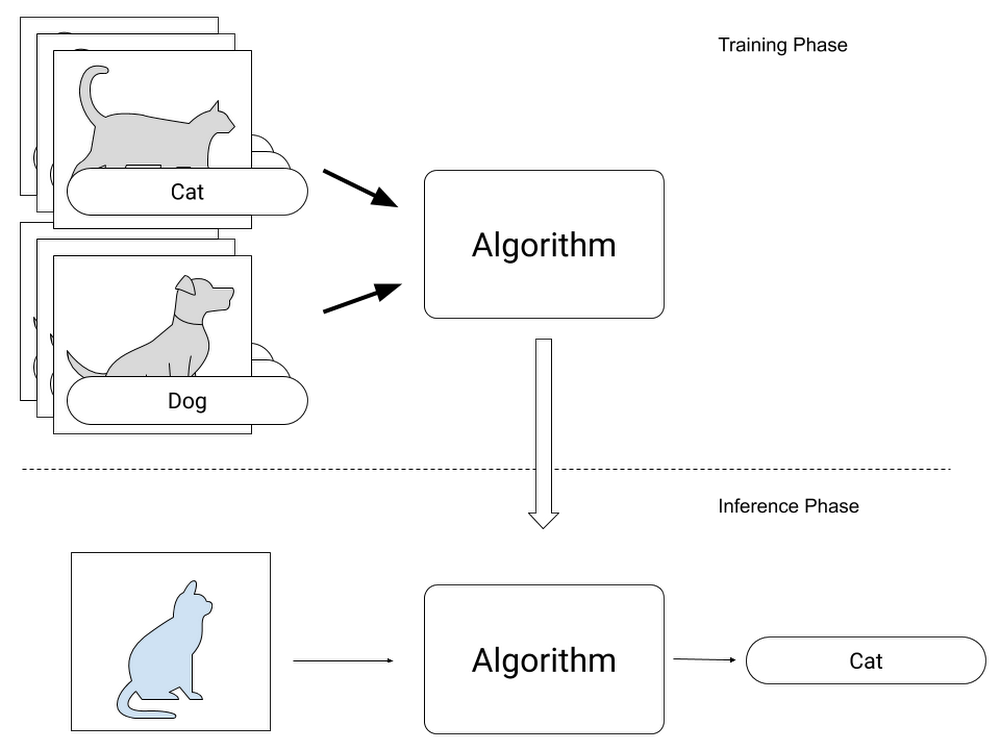
ここまでの話をいったんまとめてみましょう。ML では、入力と出力があり、たくさんのパラメータを調整することで期待の結果を得ることができました。このパラメータは、入力と出力の組み合わせのデータ(例えば犬と猫の画像と、それぞれの画像が犬なのか猫なのかを示したラベル)をたくさん使い調整します。この調整のフェーズを学習と呼びました。一度このパラメータ調整が終われば、今まで使っていない入力から出力が得られます。例えば、新たな犬の画像を入力すれば「犬」というラベルが出力されます。学習のフェーズでは、入力の犬の画像、そして出力の「犬」というラベル両方セットでしたが、このフェーズでは入力の画像だけから「犬」というラベルを得ることができました。これを推論と呼びます。このように ML では学習と推論の 2 つのフェーズがあります。
学習のフェーズでは、たくさんのデータからパラメータを調整しますが、1 つのデータから 1 回パラメータを調整して終わりではなく、通常複数回反復して行います。例えば、学習データが 100 あるとしたら、100 x 20 回といった具合です。全ての学習データを使って学習をしたとき、これを 1 エポックと数えることがあります。先の例 (100 x 20回)では、全部で 100 ある学習データを 20 回反復して学習したということなので、20 エポックと数えます。
急に学習回数の話をしましたが、どの回数が適切であるということではなく、学習データの何倍も学習を繰り返すという規模感を覚えておいてください。一方、推論の場合は、1 つの入力データに対してすでに調整されたパラメータを使って演算するだけなので、1 回の演算で推論結果を出すことができます。
学習と推論以外の処理
これまで学習と推論、つまりモデルを作る・使う部分を説明してきました。では ML をビジネスやアプリケーションで使うときに、このモデルだけあればよいでしょうか?簡単な例をもとに見ていきましょう。
犬と猫の画像の識別をするモデルができたので、犬猫発見スマホアプリを作るとします。スマホで何かの写真を取ると、犬なのか猫なのかを教えてくれるシンプルなアプリです。まずはモデルを学習しないといけないので、学習データを集めるとしましょう。社内、もしくは協力してくれるユーザーにスマホで犬と猫の画像を撮影してもらいます。ここでは「スマホで撮影」してもらうという共通点を設けましたが、スマホのカメラ性能は機種によってそれぞれ違います。保存されるフォーマットが違ったり、画像サイズも異なります。しかし、モデルに入力するにはその画像サイズとフォーマットは固定する必要があります。例えば画像サイズは 320x320 ピクセル、フォーマットは RGB(8bit) といった具合です。ですので収集した画像にそれぞれ変換処理を行い、フォーマットを統一にします。
2. 実際には複数のデータをバッチでまとめて演算します。
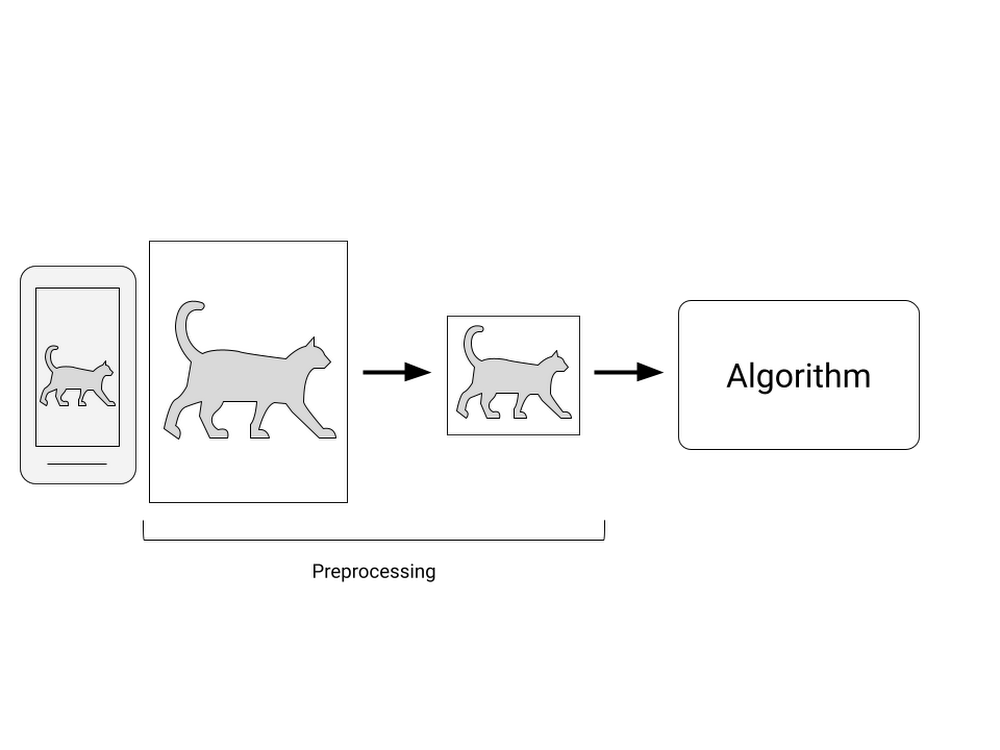
この他にもたくさんやらなければならない点がありますが、詳細は本シリーズの第 2 回目以降にとっておき、ここまで挙がった課題が AutoML でどのように解決(自動化)されるのかを確認していきましょう。
AutoML での自動化
ここまでで、既存の ML では自動でできない点がいくつか挙がりました。おさらいすると以下のようになります。
モデル(アルゴリズム)の選択
ハイパーパラメータの調整
学習データの前処理
本ブログの冒頭で触れた通り、AutoML ではこれらの作業を自動で行うことができます。ですので、学習データを用意したら(ラベル付けの作業は依然として必要ですが)あとは自動で学習されたモデルができあがります。AutoML 利用者として把握しておかなければならない点を確認していきましょう。
AutoML は便利な一方で、何でもかんでもデータさえあれば良い感じに予測してくれるモデルができるわけではありません。将来的には実現可能になるかもしれませんが、本ブログポスト執筆時点で一般的に知られている技術では取り扱うデータタイプと、推論の形式が決まっています。例えば入力形式は静止画、推論は画像に対するラベルに対応、などです。ここに例えば音声に対応していない AutoML に対して、音声データを入力することはできません。
Cloud AutoML 概要
ここまで、ML や AutoML といった技術の紹介をしてきました。ここからはプロダクトの話、Cloud AutoML について紹介します。
AutoML はモデルを作るだけでなく、データの前処理も行うと述べました。Cloud AutoML も同じくモデルの作成とデータの前処理を自動で行ってくれますが、それだけでなく学習や推論に必要な環境も作ってくれます。Cloud AutoML を使わない場合、どのような環境を自分で構築しなければならないのかを見ていきましょう。
例えば学習の際は、データが膨大になると 1 台のサーバーでは非常に時間がかかるので、複数のサーバーを使って分散処理します。これは単に同じサーバーを横に並べればいいというわけではなく、ML のパラメータをどのように更新するのか、あるサーバーがダウンした場合の復帰方法は、などなど、考慮しなければならない点が多々あります。
また推論の際は、システムからモデルにデータを入力して結果を得ますが、これも利用する量が多くなると 1 台のサーバーでは処理しきれなくなります。そのため学習の時と同じく分散処理が必要ですが、学習の時と違って利用状況によって必要なサーバー数が変動します。このようなアクセス数に合わせてリソースを変動させるスケーラブルな構成もまた、自分で作ろうと思うと大変です。
Cloud AutoML は、これらの環境を意識せずに利用することができます。学習の際、利用者は最大でどれくらいの学習時間をかけるのかを設定するのみですし、推論の際も、自動的にスケーラブルな API の環境を構築してくれます。つまり、システムとして運用する際の課題もある程度解決してくれるプロダクトです。GCP には ML の知識が不要ですでに学習済みのモデルをすぐに使えるものから、独自のモデルを独自に学習し、そのためのインフラ部分も独自に設計できるものまでプロダクトが揃っています。Cloud AutoML は、その中間の隙間を埋める位置にあります。
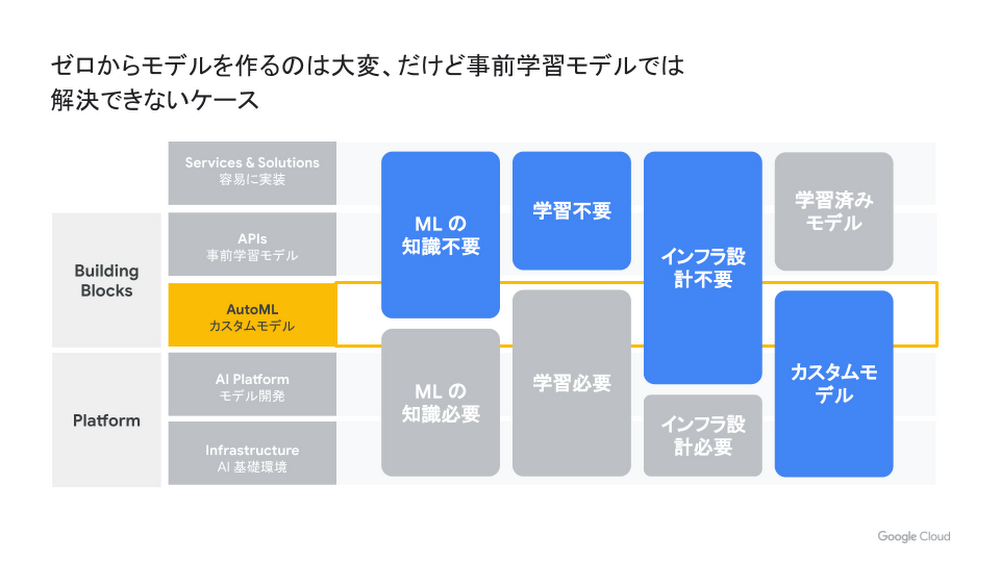
Cloud AutoML プロダクト一覧
Cloud AutoML では、5 つのカテゴリーでプロダクトがあります。それぞれが取り扱うことのできるデータ形式と、推論の種類は以下のようになっています。
Vision
AutoML Vision では、画像(静止画)を取り扱うことができます。画像の識別( 1 つの画像から 1 つのラベルを抽出、または 1 つの画像から複数のラベルを抽出)と、オブジェクト検知をすることができます。
Video
AutoML Video Intelligence では、動画を取り扱うことができます。シーンの識別と、オブジェクトトラッキング(オブジェクト検知と似ていますが、次のフレームで同一のオブジェクトを追跡します)ができます。
Translation
AutoML Translation では、文字列の翻訳を行います。業界用語が含まれる文や独自の単語を反映して翻訳したい際に使います。
Natural Language
AutoML Natural Language は、文字列を取り扱います。文章の分類分けや、エンティティの抽出、感情分析が行えます。
Tables
AutoML Tables は、表形式のデータを取り扱います。特定のカラムの値を予測します。第 2 回では、こちらをハンズオン形式で体験します。
まとめ
第 1 回では、ML そのものの簡単な解説、AutoML がそれをどう自動化しているか、そして Cloud AutoML ではさらにシステムとして便利になっているかを説明しました。次回以降、プロダクトのもう少し詳しい説明や、運用時に気をつけなければならない点などを紹介していきます。


