〜AutoMLで実践する〜 ビジネスユーザーのための機械学習入門シリーズ 【第 2 回】AutoML Tables ではじめる LTV 分析入門

葛木 美紀
Google Cloud カスタマーエンジニア
前回のブログポストでは、ビジネスユーザーを対象に、Cloud AutoML というプロダクトを通して機械学習をビジネスに役立てるための基礎知識を紹介しました。ここでは、具体的な製品の利用例として AutoML Tables を活用して EC サイトの LTV 予測モデルを作成する手順をご案内します。
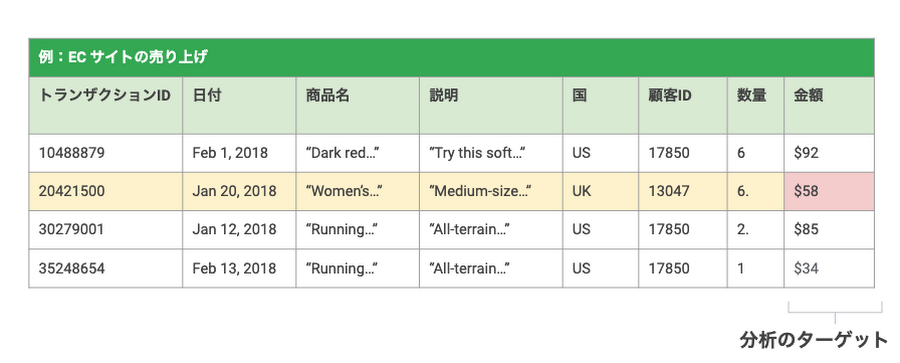
AutoML Tables は CSV のような表形式の構造化データに対応しています。構造化データは、Excelやcsvといったテーブルのような形をしたデータを意味しています。例えば、以下のようなECサイトのトランザクションデータが存在し、サイトの訪問数や国などの要素から金額(売上)を予測したい場合、回帰分析という手法で予測を行う方法があります。
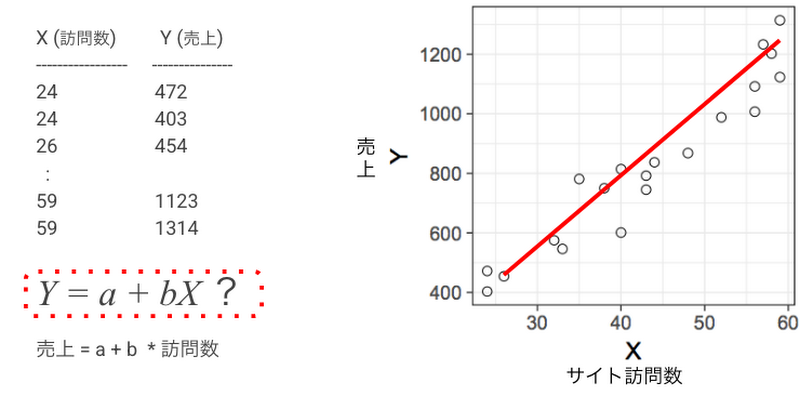
例えば、上記のようなデータでサイトの訪問数をX軸、売上をY軸にプロットして下記のような図になったとしましょう。サイト訪問数が50の時、売上はいくらになるかということを考えると、赤い線を思い描き、およそ 1100 程度になる(X 軸が 50 の時に Y 軸が赤い線と交差するポイント)と予想される方も多いのではないでしょうか。回帰分析は、この赤い線を Y=a+bX(a, b は数値) のような式で表現し、X の値によって Y の数値を予測するイメージとなります。
今回は、このような構造化データに対する実際のユースケース例として AutoML Tables を使った LTV 分析を行ってみましょう。
LTV(Life Time Value)とは顧客がサービスを使う上で生涯で合計どのくらいの額を使うかの指標です。例えば、下記の図で短期的には高額な商品を買ってくれるBさんよりも、長期間継続して購入 / 利用するAさんの方がLTVが高いということになります。ここでは、このような、顧客が生涯を通して購入する金額や継続期間のことを生涯価値と呼びます。
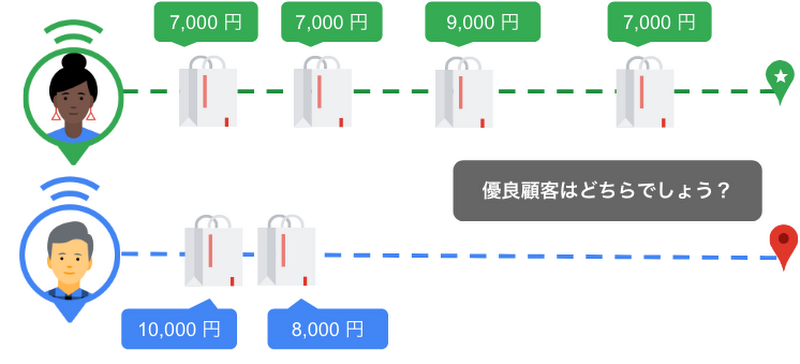
図2. 消費者ごとの購買パターン例
この顧客生涯価値を計算する方法として、RFMと呼ばれるアプローチがあります。これは、顧客の直近の注文時期(Recency)、購入頻度(Frequency)、購入金額(Money)から生涯価値を予測する方法です。
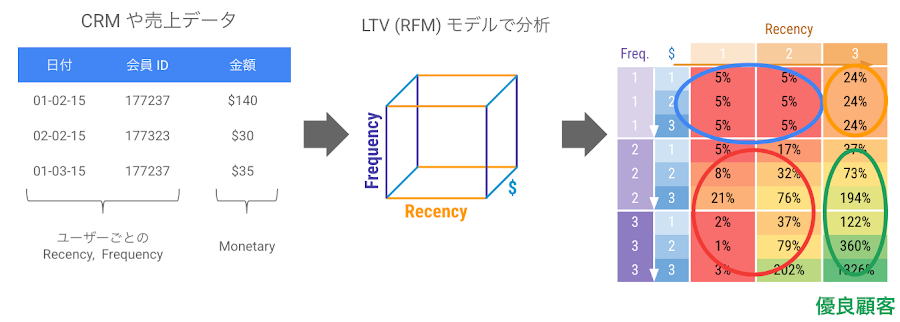
LTV 分析には主に2種類のアプローチがあり、負の二項分布など複数の確率モデルを組み合わせて消費者の購買行動を表現する方法と、機械学習や DNN で上述のように回帰分析的なアプローチで生涯価値を予測する方法があります。この記事では、後者の方法を AutoML Tables で行う方法をご紹介しています。1
ここでは、 UCI Machine Learning Repository で一般公開されている Online Retail Data Set の過去の売上データを加工したサンプルデータから顧客の生涯価値として「Target Monetary」という値を予測するモデルをトレーニングする方法について説明します。なお、事前にブラウザからこちらのURLからサンプルデータ(automl_ltv_sample.csv)にアクセスし、別名で保存を選択してダウンロードしてください。
1 LTVを計算する様々な手法に関してはこちらを参照してください。
表形式のデータセットを作成する
Google Cloud コンソールのメニュー [ストレージ > ブラウザ] 画面を開き、以下のような Google Cloud Storage バケットを作成します。
バケット名:グローバルに一意な任意の名称(例:ltvtest_0109)
ロケーションタイプ:Region
ロケーション:us-east1
データのデフォルトのストレージクラス:Standard
2. Google Cloud Consoleのメニューを開き、[AIプラットフォーム(統合型)]セクションで、[データセット]ページに移動します。
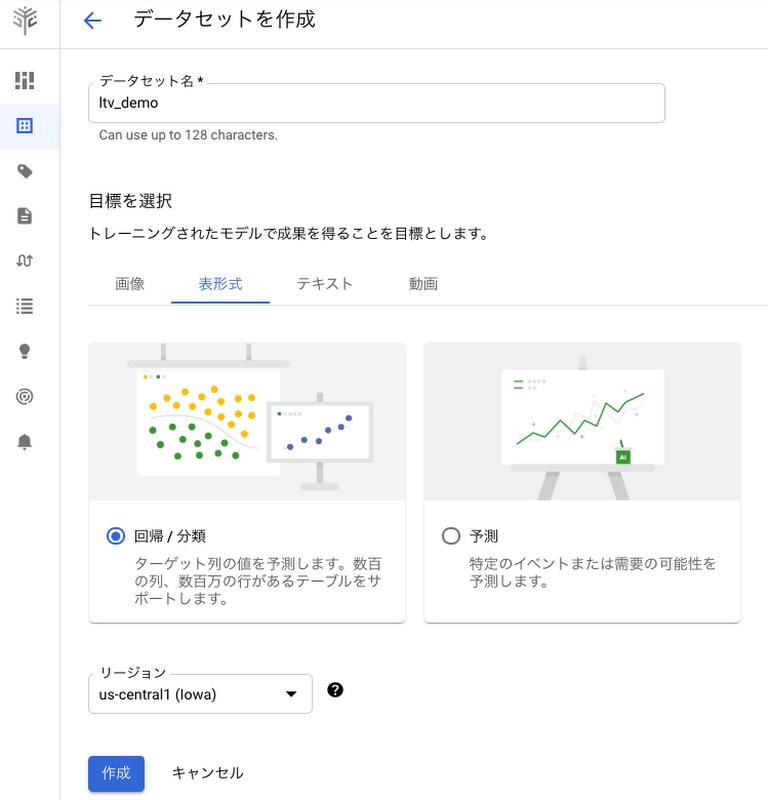
4. 任意のデータセット名(例:ltv_demo) を入力し、タブから [表形式 > 回帰 / 分類]を選択し、リージョンはデフォルトの us-central1 のままで[作成]をクリックしてデータセットを作成します。
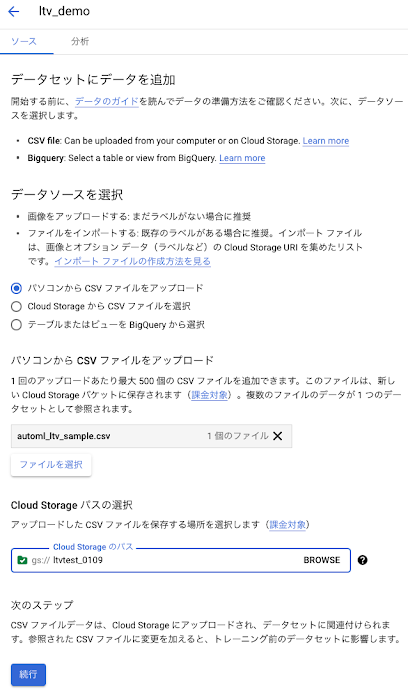
5. [パソコンから CSV ファイルをアップロード] を選択し、automl_ltv_sample.csv をアップロードします。
6. [Cloud Storage パスの選択] 欄に 1. で作成した Cloud Storage バケット名を入力し[続行]をクリックします。
7. データの読み込みが成功すると、以下のような [分析] ペインが開きます。2
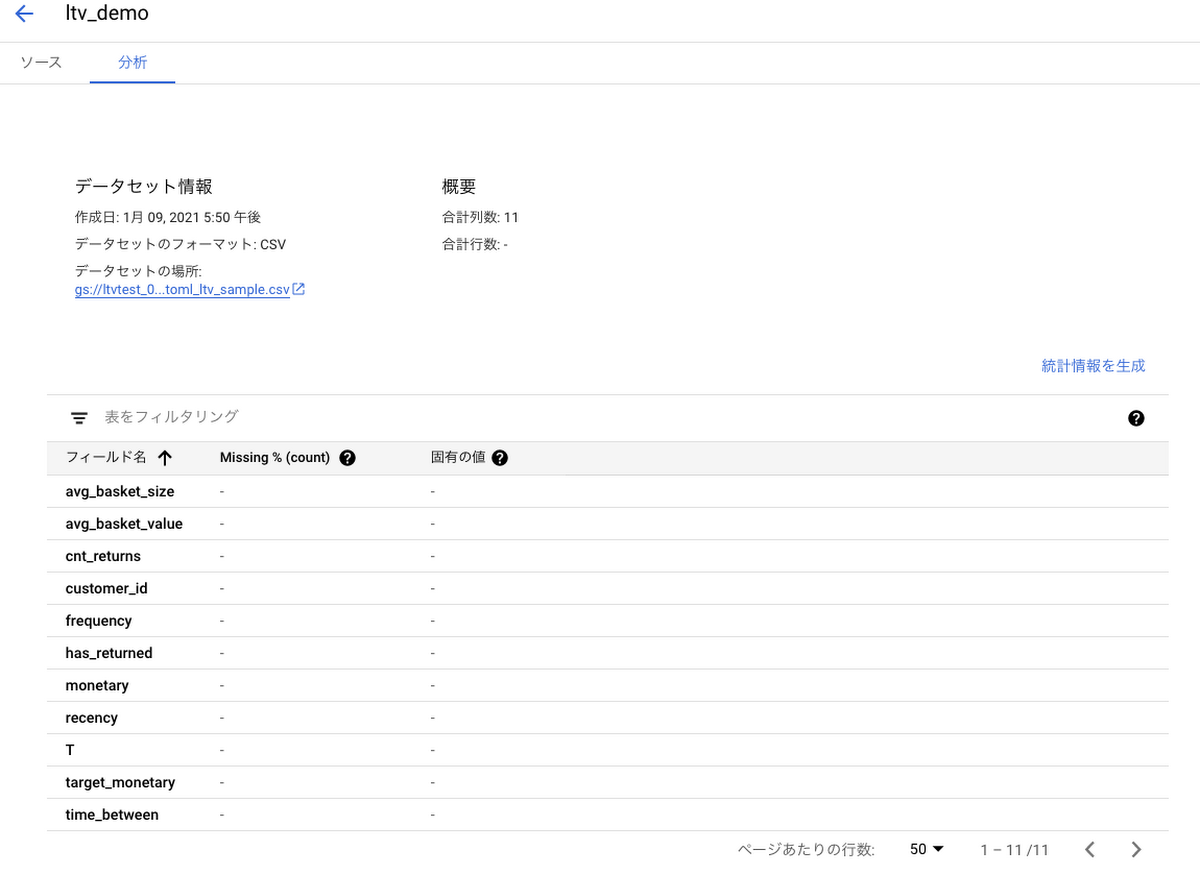
今回は、顧客ごとに一定期間で収集された以下の特徴量を使って生涯価値 (target_monetary) を予測します。target_monetary は、トレーニング期間とターゲット期間を含め、顧客が使った金額の総額です。また、それ以外の項目は以下の意味を持ちます。
monetary 該当顧客のすべての注文の合計金額
recency 初回購入から直近の購入の間の期間
frequency 期間内の注文回数
T 初回購入から現在までの期間
time_between 注文間の平均時間
avg_basket_value カートの平均金額
avg_basket_size カートに入っている平均商品数
cnt_returns 返品した注文数
has_returned 少なくとも 1 つ以上の注文を返品したかどうか
2 データセットの統計を生成するには、任意の特徴量を選択し[統計情報を生成]をクリックします。統計が生成された後に任意の特徴量をクリックすると、データに関する詳細を表示できます。
AutoMLでモデルをトレーニングする
1. 右上にある [<|] アイコンを展開し[新しいモデルのトレーニング]をクリックします。
2. [新しいモデルのトレーニング]ペインでObjectiveに [Regression] を選択し[続行]を選択します。
3. ターゲット列に[target_monetary]を選択して[続行]をクリックします。
4. データセットで全ての特徴量が選択されていることを確認して、もう一度[続行]をクリックします。
5. [モデルのトレーニングに費やすノード時間の最大値]欄に[1]をトレーニング予算として入力し[トレーニングを開始]をクリックします。Enable early stopping はオンのままにしてください3。その後約 1 時間前後でトレーニングが完了します。なお、AutoML Tablesの学習には、1ノード時間あたり19.32ドルが課金されます(2021年1月時点)。最大72ノードまで指定できますが、問題設定やデータによっては、最小の 1ノード時間だけでも期待した指標に近いモデルを作成できる場合もあります。
3 このオプションを有効にしておくと、モデルトレーニング中にこれ以上改善ができなくなったときにトレーニングを終了し、残りの予算が返金されます。Early Stoppinが無効になっている場合、予算がなくなるまでトレーニングが続行されます。
モデルのデプロイと予測
1. Google Cloud Consoleの[AIプラットフォーム]セクションで、[モデル]ページに移動します。トレーニングが完了すると、[モデル] タブに該当モデルが表示されるので、リンクをクリックして[評価]パネルを開きます。
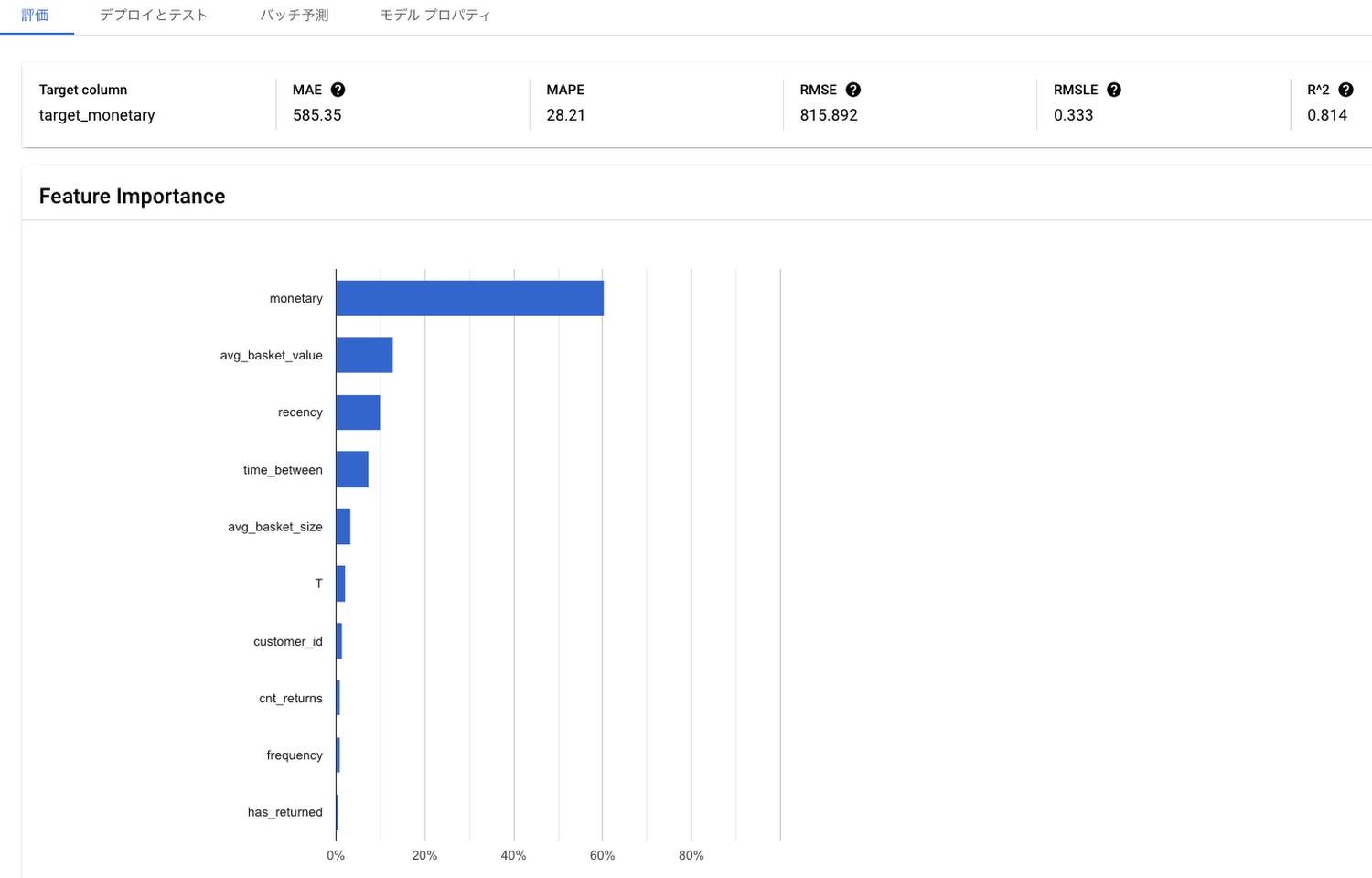
2. このパネルには、学習したモデルの品質を示す様々な回帰分析の評価指標が表示されます。ここでは、一回のトレーニング結果だけでもモデルの指標として比較的判断しやすい 2 種類の指標をご紹介します。4 5
a. MAPE(平均絶対パーセント誤差):ラベルと予測値との平均絶対パーセント差です。この指標の範囲はゼロから無限大までで、値が低いほど高品質のモデルであることを示します。今回は「28.21」となりました。
b. R^2(決定係数):ラベルと予測値間のピアソン相関係数の 2 乗で、単純に平均値を使って予測した場合と比較してどれくらい精度が高いかを示しています。この指標の範囲は 0~1 で、値が高いほどモデルが高品質であることを示しますが、今回作成されたモデルの場合「0.814」となりました。
c. Feature Importance(特徴量の重要度):各特徴量がモデルのトレーニングにどれだけ寄与したかを確認できます。ここでは、生涯価値には該当顧客が支払った金額に該当する monetary が最もモデルに影響を与えていることが分かります。
4 RMSE など絶対値だけでは単純にモデルの指標として判断が難しいものもあります。ここでご紹介した以外の回帰モデルの評価指標について詳細はこちらを参照ください。
5 この指標はあくまで例となり、実行頂いたタイミングによって異なる値になる場合もあります。
トラフィック分割などその他のオプションは全てデフォルトのままで[続行]をクリックし、[デプロイ]をクリックしてエンドポイントを作成し、モデルをエンドポイントにデプロイします。*モデルのデプロイには数分かかります。

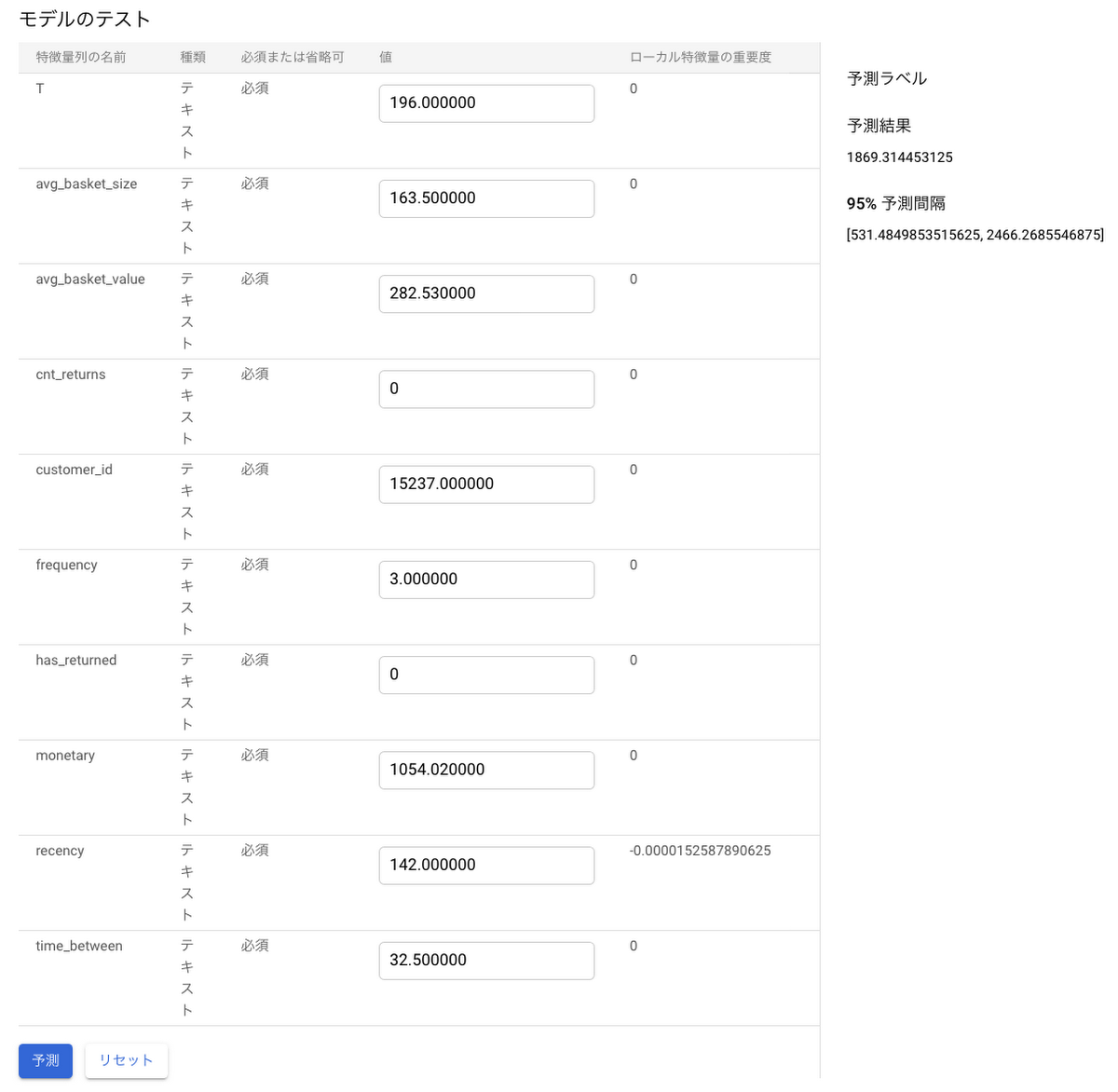
4. デプロイが開始すると、[デプロイとテスト] タブに[モデルのテスト] というフィールドが画面に表示されます。これは、1行の入力データからモデルに基づいて予測結果を表示する機能です。
5. モデルのテスト画面では、初期設定でサンプルの特徴量が入力されています。モデルのデプロイが完了したら、これらのデフォルト値を入力した状態で「 [予測] 」ボタンを選択すると、予測結果が表示されます。下記の例では、顧客の生涯価値(target_monetary)が 1869 と予測されていることを示します。
AIプラットフォームリソースの削除
ここでは、予期せぬ課金を回避するため、この手順で利用したエンドポイント、モデル、データセットを削除する方法について説明します。
1. Google Cloud Consoleの[AIプラットフォーム > エンドポイント]ページに移動し、エンドポイントをクリックして、詳細ページを開きます。
2. 右端にあるゴミ箱のアイコン(モデルのデプロイ解除)から [デプロイの解除] をクリックし、エンドポイントを削除します。
3. [AIプラットフォーム > モデル]ページに移動します。
4. 該当モデルの右端にあるアイコンから[モデルを削除]をクリックします。
5. [AIプラットフォーム > データセット]ページに移動します。
6. 該当データセットの右端にあるアイコンから[データセットの削除]をクリックします。
7. [ストレージ > ブラウザ] 画面を開き、AutoML Tables 用に作成したバケットの右端にあるアイコンから[バケットの削除] をクリックします。
運用時の注意点
Google Cloud ではカスタム機械学習モデルを作成する際、AutoML を含め主に以下の表1. に記載されている 3 つの方法があり、用途や目的によって使い分けて頂くことが可能です。
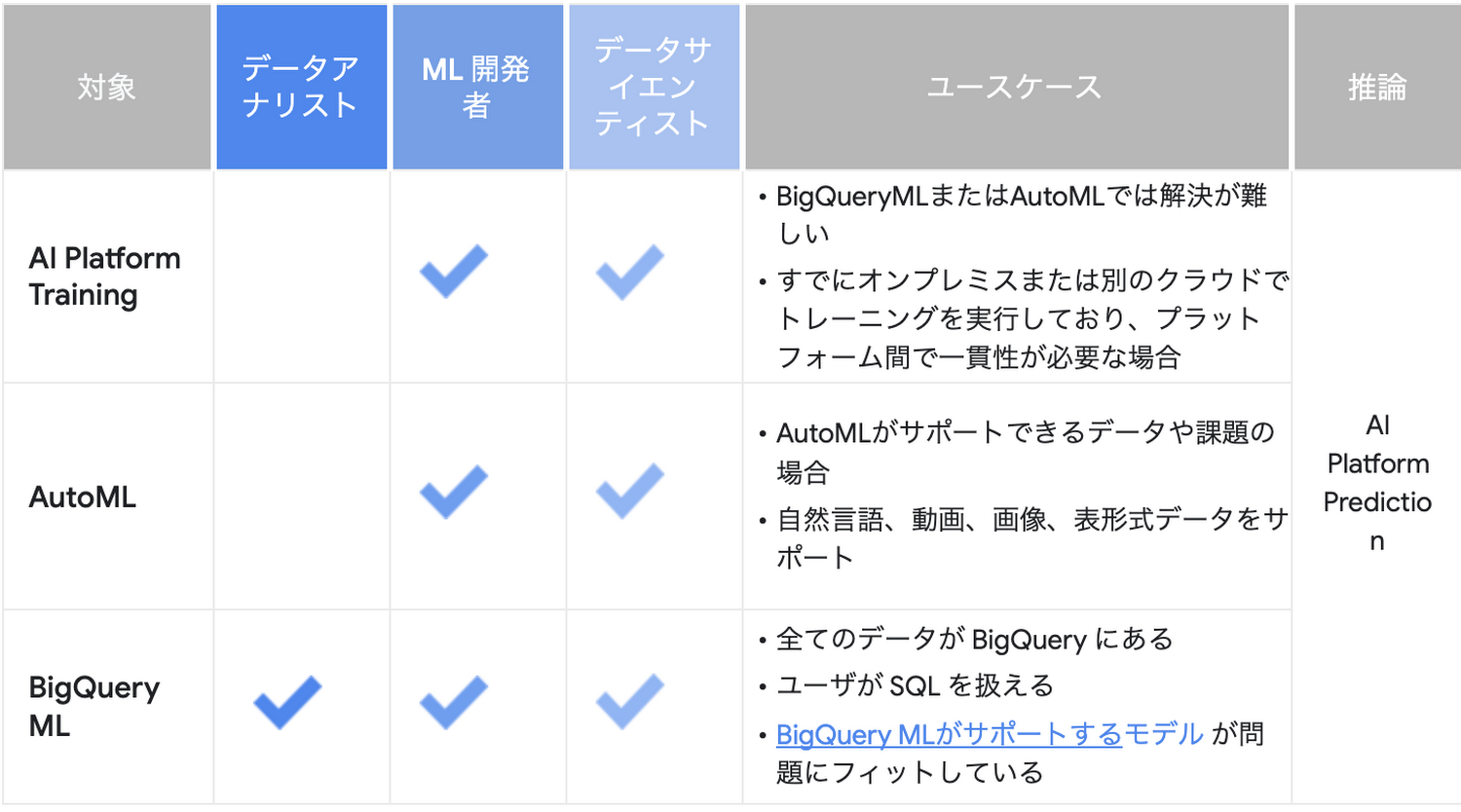
この中でもAutoML の特徴は、従来人間が多くの工数を割いてきたデータの前処理やパラメーターチューニング、モデル選択、アンサンブルなどを自動化してくれる点があげられます。このため、以下のような用途に適しています。
データを自前で準備できる
学習時間として1時間以上許容できる
機械学習モデル開発の工数をできるだけ削減しながら、一定の精度のモデルを作成したい
一方、以下のような用途には向いていません。
モデル設計やハイパーパラメータチューニングを自分で行いたい
結果を数秒〜数分で得たい
データが少数しかない(例:構造化データの場合1000件以下)
まとめ
Cloud AutoMLを使うと、必要最低限の設定とわずか数クリックのステップで機械学習モデルを作成できるということを実感いただけたかと思います。また、モデルの詳細をログから確認したり、特徴量の重要度を確認することで、単に予測を行うだけでなく、よりモデルの解釈性が高まります。今回は数値を予測する回帰モデルを作成しましたが、カテゴリ値をターゲットに選ぶことで分類モデルも作成可能です。




