Vertex AI で公開ウェブサイトのインデックス作成を自動化し、効率的なセマンティック検索を実現する
Google Cloud Japan Team
※この投稿は米国時間 2024 年 2 月 3 日に、Google Cloud blog に投稿されたものの抄訳です。
はじめに
非構造化データの扱い方を刷新したいとお考えですか?今回のテーマは、そうした方にぴったりです。このブログ投稿では、生成 AI という注目の分野において、とりわけベクトル検索や大規模言語モデル(LLM)などのツールがどのように検索機能を変革しているのかをご紹介します。
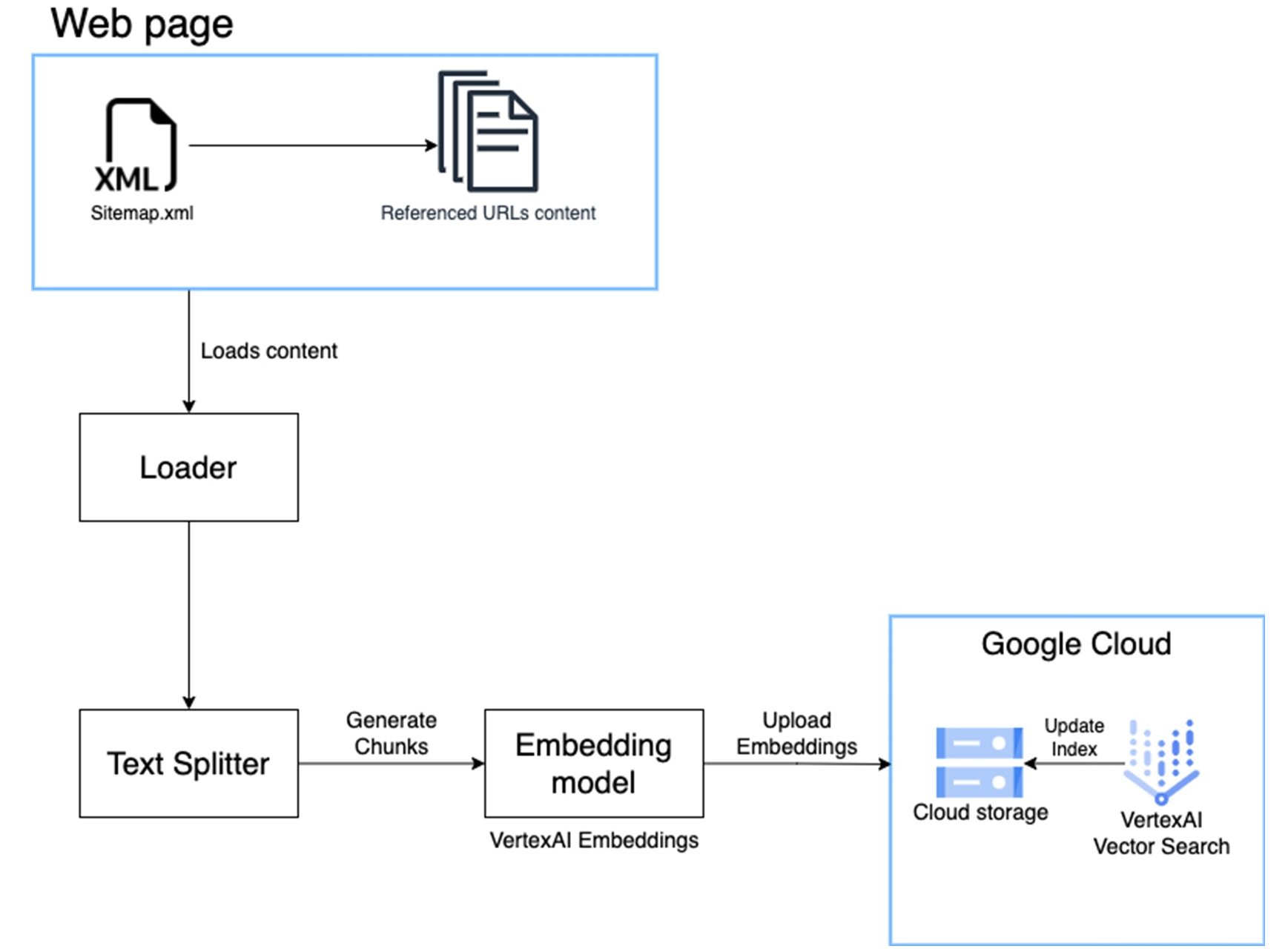
具体的には、ベクトル検索の威力を紹介しながら、ウェブページなどの非構造化データを高速に取り込んで検索やチャット システムの効率を高める方法について説明します。
一般公開されているウェブページへのクエリを受け付ける会話型検索ソリューションには、通常、以下のようなステップが含まれます。
- ウェブページをクロールして読み込む: ウェブページの内容を抽出して整理、処理します。
- ドキュメントを分割し、ベクトル エンベディングを作成する: ウェブページを分割し、各部分を表すベクトルを生成します。
- ドキュメントの各部とエンべディングを安全な場所に格納する: テキストの各部とベクトル エンベディングを安全な方法で格納して、効率的に取得できるようにします。
- ベクトル検索のインデックスを構築してエンベディングを格納し、クエリに対応できるようにする: ベクトル検索のインデックスを構築して、類似度に応じてベクトル エンベディングを取得できるようにします。
- ベクトル検索のインデックスを定期的に更新し、新しいページの内容を反映させる: インデックスを定期的に更新し、新しいウェブページの内容を取り込んで、検索の的確性を維持します。
- ベクトル検索のインデックスに対して検索クエリを実行し、関連のあるウェブページを取得する: ベクトル検索のインデックスを使って、検索クエリに合致するウェブページを特定、取得します。
データの取り込みプロセスを維持し続けることは、非常に大変な作業と感じるかもしれません。扱うウェブページの数が多い場合はなおさらです。
しかし、恐れることはありません。Google Cloud にお任せください。
ソリューションの概要
Google Cloud のソリューションなら、データの取り込みプロセスを効率化して会話型検索ソリューションを簡単にデプロイし、対象のウェブページから役立つ情報を引き出すことが可能です。具体的には、Vertex AI Vector Search、Vertex AI Text Embedding モデル、Cloud Storage、Cloud Run、Cloud Logging などの Google Cloud サービスを組み合わせたアプローチを採用しています。
利点:
- デプロイが簡単: 手順ガイドに沿って、Google Cloud プロジェクトにシームレスに統合できます。
- 柔軟に設定: プロジェクト、リージョン、インデックスの接頭辞、インデックス、エンドポイント名を必要に応じてカスタマイズできます。
- リアルタイムのモニタリング: Cloud Logging を使って、データの取り込みパイプラインを詳しく把握できます。
- スケーラブルなストレージ: テキストの各部およびエンベディングを Cloud Storage に安全に格納し、効率的に取得できます。
リファレンス アーキテクチャ
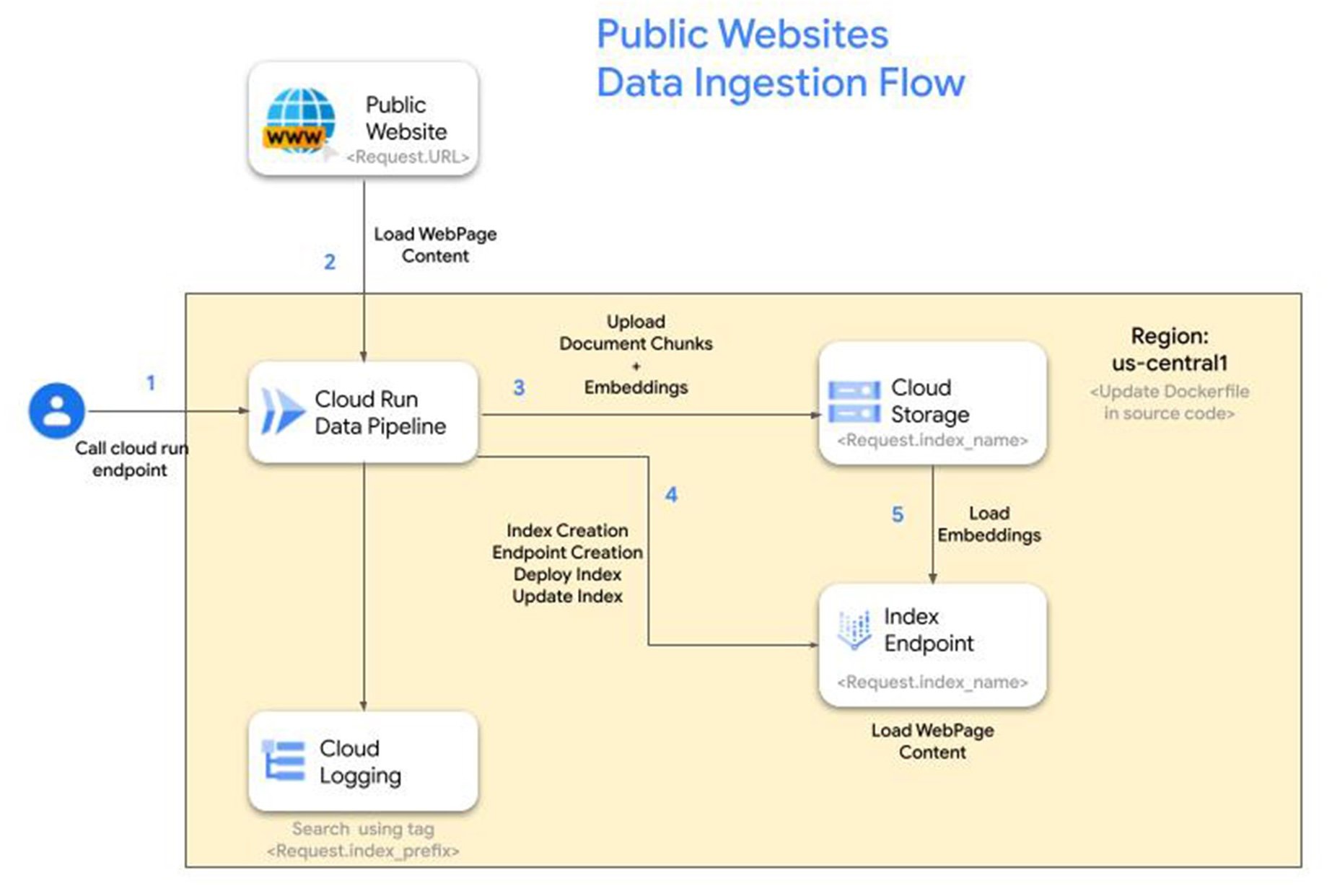
手順
1. API を有効にする
Google Cloud コンソールまたは以下に示す gcloud コマンドを使って、以下の各 API を有効にします。
2. リポジトリのクローンを作成する
このリポジトリに、python で fastapi フレームワークを使って記述されたアプリケーションがあります。このアプリケーションには、公開されている REST エンドポイントが 1 つあり、上記の「はじめに」で説明したステップを実行します。アプリケーションの詳細は、README.md ファイルでご確認いただけます。
3. DockerFile でプロジェクトとリージョンを設定する
github リポジトリをダウンロードし、サポートされているテキスト エディタで開きます。Dockerfile 内の REGION と PROJECT_ID の値を適宜更新します。
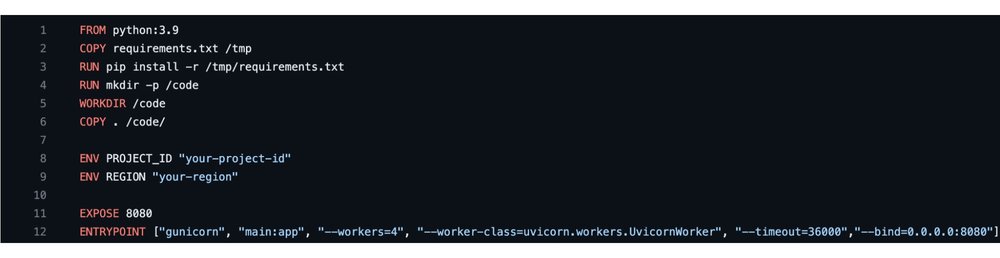
4. イメージをビルドして Cloud Run アプリをデプロイする
5. エンドポイントを呼び出してインデックスを作成する
GCP のインデックス エンドポイントに公開ウェブサイトを読み込むには、http post のエンドポイントを呼び出し、必要な設定パラメータを本文に指定します。
- Index_name => str : このパラメータは、インデックスおよび indexEndpoint DisplayName を GCS バケットと照合します。
この名前の GCS バケットが存在しない場合は、新しいバケットおよびインデックスを作成します。
GCS バケット名がユニバーサルに一意でない場合は、400 が返されます。 - Url => str : コンテンツを埋め込む URL。URL の末尾は sitemap.xml にする必要があり、そうでない場合は 400 が返されます。
- Prefix_name => str : Cloud Logging のタグとして使用されます。ジョブの進行状況を調べるほか、GCS バケット内にフォルダを作成して後でエンベディングを格納することもできます。
CuRL コマンドを使ってエンドポイントを呼び出す例を以下に示します。
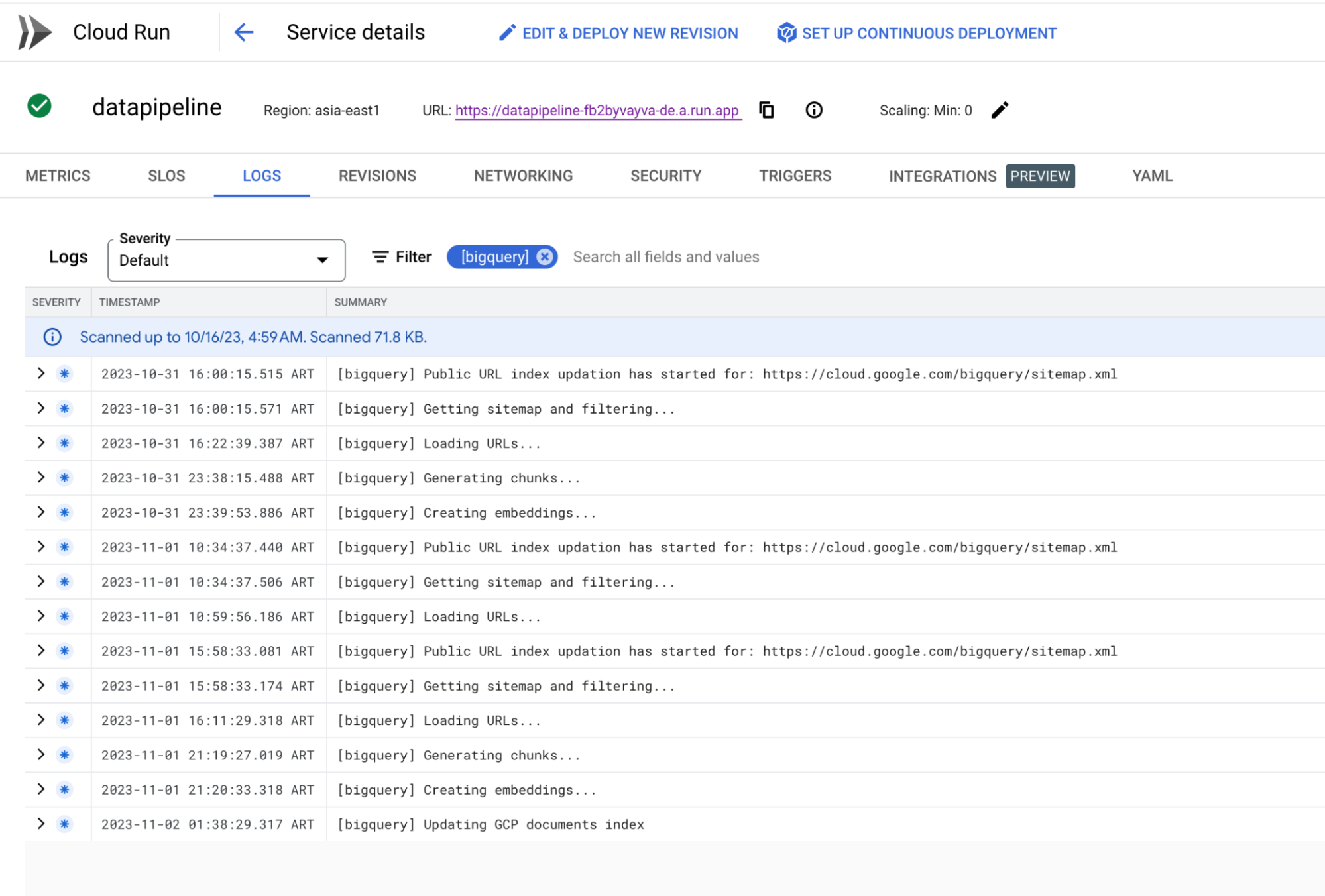
6. Cloud Logging で進行状況を確認する
上記の CuRL コマンドを使ってインデックスの作成を開始したら、Cloud Logging のログを接頭辞名でフィルタリングして、取り込みの進行状況を確認できます。
7. インデックスに対してクエリを実行し、検索結果を取得する
パイプラインの完了後、取り込み対象のウェブサイトにもよりますが、およそ 3~4 時間で Google Cloud プロジェクトのインデックスおよびインデックス エンドポイントが作成され、Vertex AI のベクトル検索オプションに表示されるようになります。
これで、ベクトル検索の Python ライブラリの match 関数を使って、インデックス エンドポイントに対してクエリを実行できるようになります。
ベクトル検索の既存のインデックス エンドポイントに対してクエリを実行する方法については、以下のコードを参照してください。

まとめ
ソリューションの効率をさらに高めるには、並列処理を実装し、大量または複数のウェブサイトからデータを同時に取り込むようにします。そうすれば、データの取り込みにかかる全体的な時間を大幅に短縮できます。
インデックス エンドポイントを作成すると、ベクトル検索のインデックスを活用して最も内容が近いものを特定し、テキスト生成モデルを使ってクエリへの回答を文脈とともに示すことができる生成 AI アプリケーションを開発できます。詳しくは、こちらのブログをご覧ください。
ー AI、自動化担当アーキテクト Robin Singh
ー クラウド エンジニア Ivan Rufino



