Vertex AI PaLM API と LangChain で容易になった生成 AI アプリケーションの構築
Google Cloud Japan Team
※この投稿は米国時間 2023 年 8 月 12 日に、Google Cloud blog に投稿されたものの抄訳です。
Google I/O 2023 で、Google は、テキストとエンべディング向け Vertex AI PaLM 2 基盤モデルの一般提供への移行、基盤モデルの新しいモダリティ(コードを生成する Codey、画像の Imagen、音声の Chirp)の拡張、モデルを活用して調整する新しい方法を発表しました。これらのモデルは、安全性、セキュリティ、プライバシーを含むエンタープライズ対応の機能を基盤とする、高性能かつ信頼性の高い生成 AI アプリケーションを開発するために役立ちます。
LangChain は、言語モデルを活用した生成 AI アプリケーションに対応する新しいインターフェースを開発できる、オープンソース フレームワークとして注目されています。これにより、言語モデルを扱うために必要な抽象化やコンポーネントの置き換えが容易になります。LangChain はオープンソース コミュニティに広く普及し、他のツールとのさまざまなインテグレーションや新機能の追加が行われています。言語モデルは簡単に使用できますが、より複雑なアプリケーションを開発するにつれて、すぐに課題に直面する可能性があります。その課題の解決に LangChain が役に立ちます。
テキストとチャット向け Vertex AI PaLM 2 基盤モデル、Vertex AI Embeddings、Vector Store としての Vertex AI Matching Engine は、LangChain Python SDK と正式に統合されており、Vertex AI PaLM モデルを基盤としたアプリケーションの構築を容易にします。
このブログ投稿では、生成 AI アプリケーション(ドキュメントベースの Q&A)を Vertex AI PaLM Text と Embedding API、Matching Engine、そして何よりも LangChain を使用して構築する方法をご紹介します。それでは詳しく見ていきましょう。
生成アプリケーションを構築する
近年、大規模言語モデル(LLM)はかなり進歩し、かなりの程度まで人間の言語を理解し、論理的に判断できるようになっています。効果的な生成 AI アプリケーションを構築するには、LLM が外部システムを操作できるようにすることが重要です。それにより、モデルがデータアウェアかつエージェント的になります。つまり、モデルがデータを理解し、データの状況を判断し、データを使用して、有意義な方法で対処できるようになります。外部システムとしては、一般公開のデータコーパス、非公開の知識リポジトリ、データベース、アプリケーション、API、Google 検索からの公共のインターネットへのアクセスなどが挙げられます。
次に、LLM を他のシステムで強化できるパターンをいくつか示します。
自然言語を SQL に変換し、データベースで SQL を実行し、結果を分析して提示する
ユーザークエリに基づいて外部の Webhook や API を呼び出す
複数のモデルから出力を合成したり、特定の順序でモデルをチェーンさせたりする
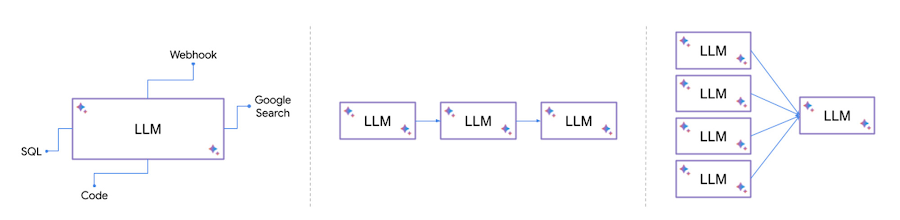
こうした呼び出しを組み込んでオーケストレートするのはささいなことに見えるかもしれませんが、異なるデータコネクタや新しいモデルのためにいちいち何度もグルーコードを記述するのは面白いものではありません。そこで役立つのが LangChain です。
LangChain のコンポーネントのモジュール型の実装と、それらのコンポーネントを組み合わせた一般的なパターンにより、言語モデルに基づく複雑なアプリケーションの構築が容易になります。LangChain により、こうしたモデルはエージェントとしてデータソースやシステムに接続し、操作できるようになります。
コンポーネントは、ドキュメント、データベース、アプリケーション、API などの外部データを言語モデルに取り込むために機能する抽象化です。
エージェントによって言語モデルが環境と通信することが可能になり、そこでモデルが次に取るべきアクションが決定されます。
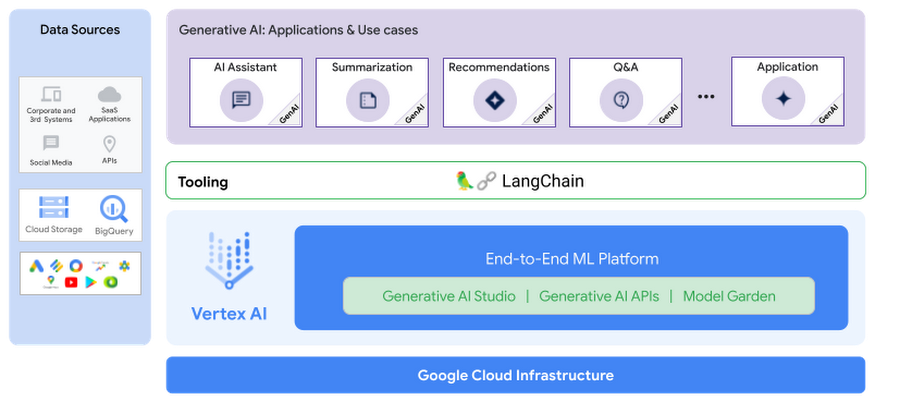
LangChain の Vertex AI PaLM 2 基盤モデルと Vertex AI Matching Engine とのインテグレーションにより、Vertex AI PaLM 2 基盤モデルのパワーと LangChain の使いやすさと柔軟性を活用して、生成 AI アプリケーションを作成できるようになりました。
LangChain のコンセプトの概要
LangChain フレームワークと知っておくべきコンセプトについて簡単に見ていきましょう。LangChain は、言語モデル アプリケーションの作成に使用できるさまざまなモジュールを備えています。それらのモジュールは、組み合わせてさらに複雑なアプリケーションを作成することも、個別にシンプルなアプリケーションを作成するために使用することもできます。
モデルは LangChain の構成要素であり、さまざまな種類の AI モデルへのインタフェースになるものです。サポートされているモデルタイプは、大規模言語モデル(LLM)、チャットやテキストのエンベディング モデルです。
プロンプトはモデルへの入力を意味し、通常は複数のコンポーネントで構成されます。LangChain では、プロンプト テンプレート、例セレクタ、出力パーサーなど、プロンプトを簡単に作成して操作できるインタフェースが用意されています。
メモリは、会話中のメッセージを保存し、取得するための構造です。短期的なメモリと長期的なメモリがあります。
インデックスによってドキュメントの構成方法を提供することで、LLM がドキュメントを処理できるようになります。LangChain には、ドキュメントを読み込む Document Loader、ドキュメントを小さなチャンクに分割する Text Splitter、ドキュメントをエンべディングとして保存する Vector Store、関連ドキュメントをフェッチする Retriever があります。
チェーンを使うと、モジュール型コンポーネント(または他のチェーン)を特定の順序で組み合わせてタスクを完了できます。
エージェントは、LangChain の強力な構造であり、LLM がツールを介して外部システムと通信し、特定のタスクを完了するための最適なアクションを観察して決定できます。
次に、Vertex AI PaLM API と LangChain のインテグレーションを示すスニペットを示します。
- LangChain LLM と言語タスク向けの Vertex AI PaLM API for Text
- LangChain チャットモデルとマルチターン チャット向け Vertex AI PaLM API for Chat
- LangChain テキスト エンべディング モデルと Vertex AI Text Embedding API
詳細は、LangChain コンセプト ガイドを参照してください。
「ドキュメントに質問する」: Vertex AI PaLM API、Matching Engine、LangChain を使用して質問応答アプリケーションを構築する
Google Cloud でドキュメント Q&A システムを実装する方法はいくつかあります。すぐに利用できる簡単な機能として、Cloud AI のフルマネージド Enterprise Search ソリューションを使用すれば、数分で作業を開始し、Google 独自の検索技術を活用した検索エンジンを作成できます。このセクションでは、Vertex AI スタックで提供されるコンポーネントを使用して、Q&A システムを独自に構築する方法も説明します。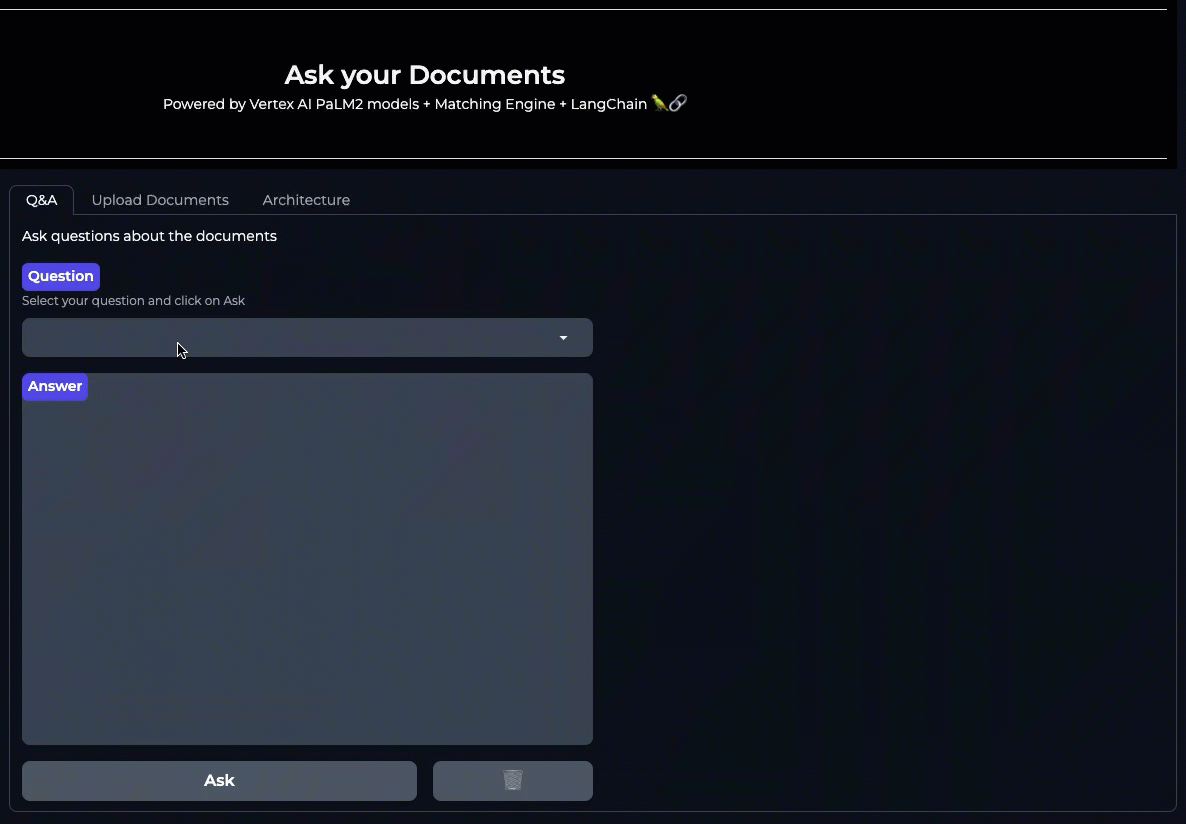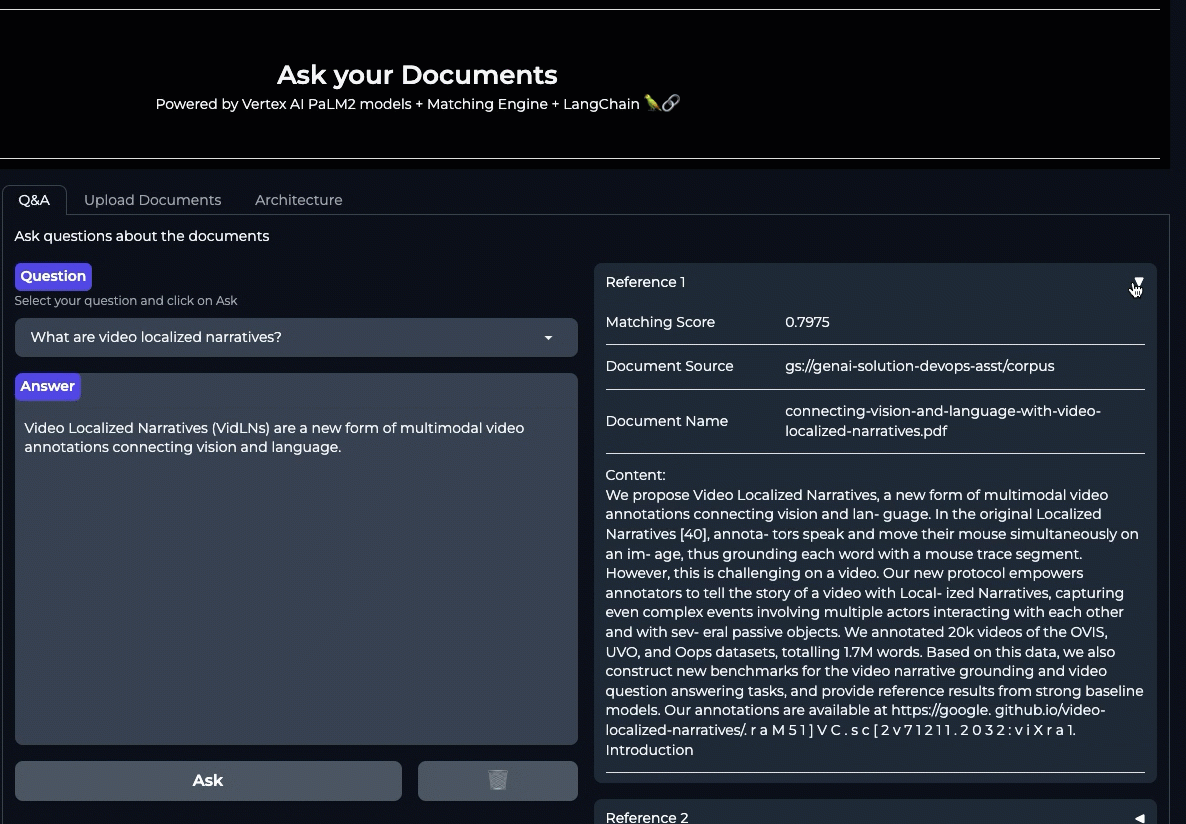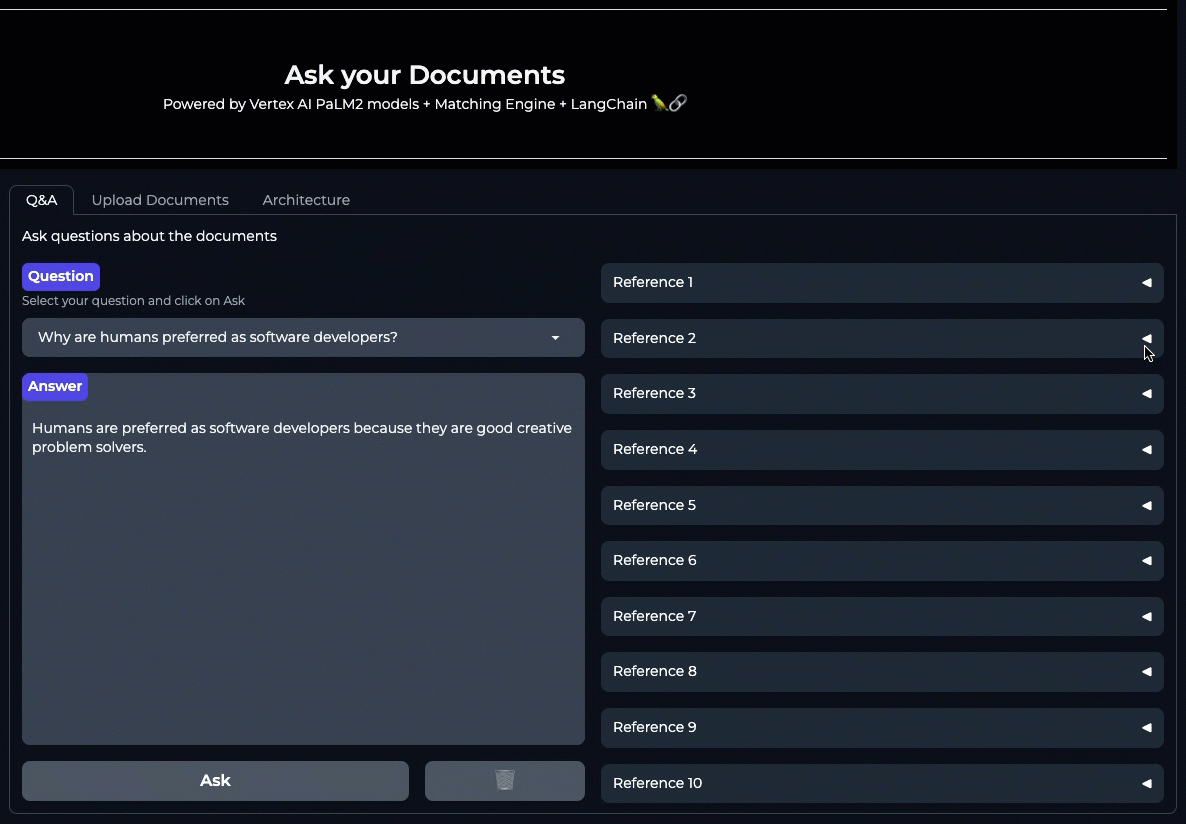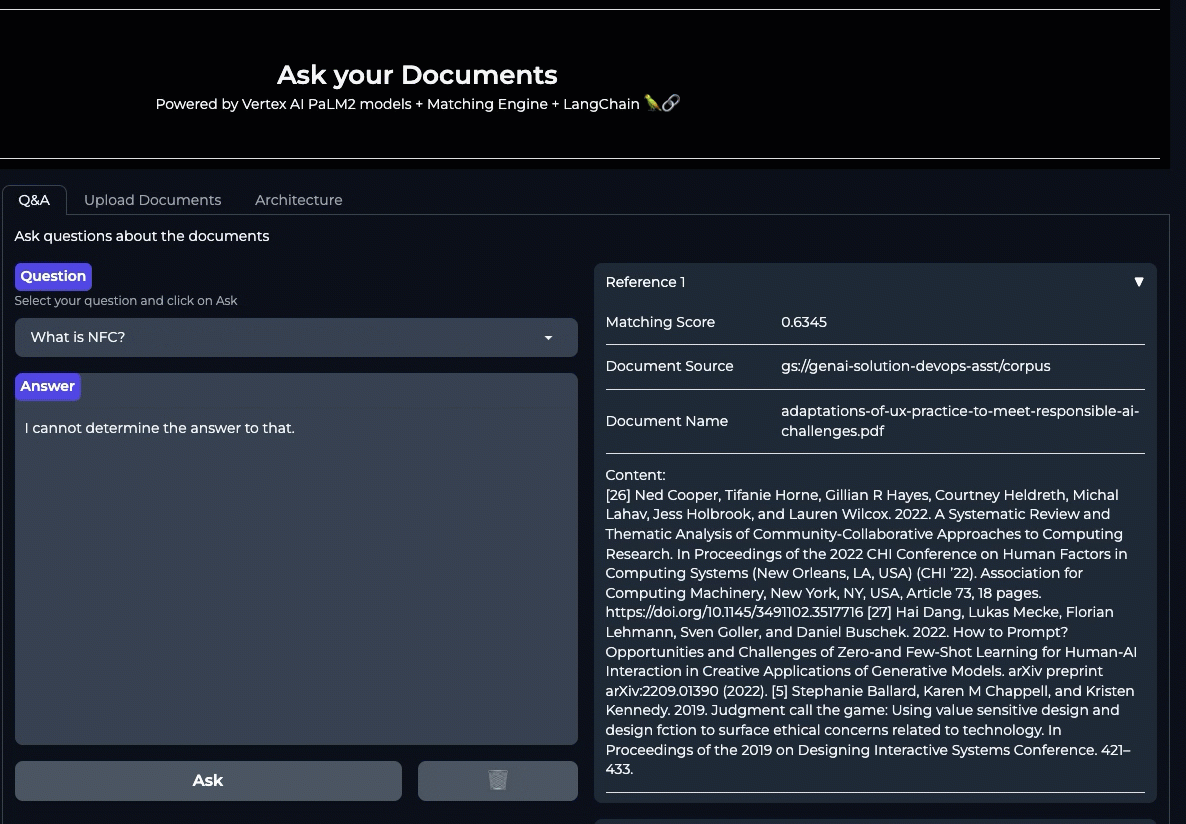
LLM は、質量ともに大幅に改善されました。この拡張によって創発的機能を利用できるようになったため、LLM は質問応答、要約、コンテンツ生成などの機能を直接トレーニングされなくても、自然言語を理解するだけで学習します。ただし、LLM には次のいくつかの制約があります。
LLM は膨大なコーパスによってオフラインでトレーニングされるため、トレーニング カットオフ後のイベントを認識しません。たとえば、2022 年までのデータでトレーニングされたモデルでは、今日の株価に関する情報が得られません。
LLM がトレーニング データから学習した知識はパラメトリック メモリと呼ばれ、ニューラル ウェイトに保存されます。LLM はパラメトリック メモリからのクエリに応答しますが、ほとんどの場合、情報源は不明であり、LLM は逐語的な引用を提供できません。LLM ベースのシステムが「参照元を引用」し、出力が事実に「根拠を持つ」(つながっている)ようにします。
LLM は、一般的なコーパスからテキストを生成することに適していますが、企業は限定公開のナレッジベースからテキストを生成する必要があります。AI アシスタントは、正確で関連性のある回答を提供するために、ナレッジベースに基づいて質問に答える必要があります。
この制約を解決するためのアプローチの一つは、情報検索(IR)メカニズムを通じて外部のナレッジベースから取得した関連データを使用して、LLM に送信されるプロンプトを強化することです。このプロンプトは、関連するデータを質問とともにコンテキストとして使用し、パラメトリック メモリの使用を回避または最小化するように設計されています。外部のナレッジベースは、ノンパラメトリック メモリと呼ばれます。このアプローチは、検索拡張生成(RAG)と呼ばれ、QA タスクのコンテキストでは生成 QA とも呼ばれます。このタイプのアプローチは、『Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks』という論文で発表されました。
このセクションでは、RAG パターンに基づく QA システムを構築する方法を説明します。このシステムは、非公開のドキュメントのコレクションに基づいて質問に応答し、関連するドキュメントへの参照を追加します。Google が公開した研究論文のサンプルを非公開のドキュメント コーパスとして使用し、そのコーパスで QA を実行します。付属コードは、GitHub リポジトリでご覧いただけます。
RAG ベースのアーキテクチャには、(1)Retriever と(2)Generator の 2 つの主要コンポーネントがあります。
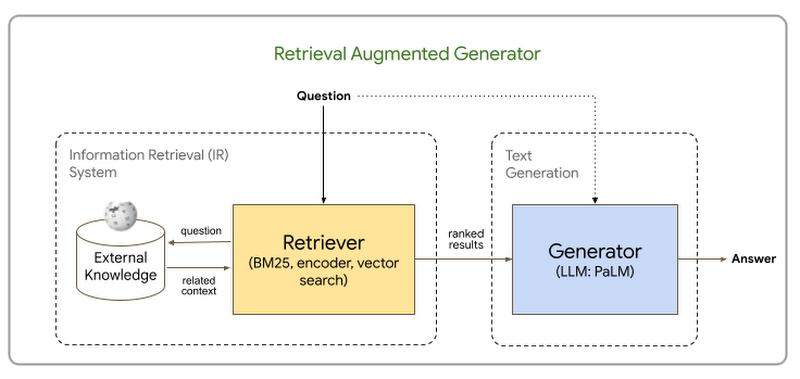
Retriever: ナレッジベースは、ユーザーのクエリに基づいてドキュメントから関連するスニペットを取得するために、Retriever とも呼ばれる IR メカニズムと統合されています。ナレッジベースには、独自のドキュメント コーパス、データベース、または API を使用できます。Retriever は、キーワード、TF-IDF、BM25、ファジー一致などの用語ベースの検索を使って実装できます。もう一つのアプローチは、密エンべディングに基づくベクトル検索を使用することです。これにより、テキスト内の意味的に豊富な情報を取得し、より効率的な情報検索を可能にします。IR メカニズムから取得された関連するスニペットは、次のステージである Generator に「コンテキスト」として渡されます。
Generator: コンテキスト(ナレッジベースから取得された関連するスニペット)は、情報源であるドキュメントに根拠づけられた適切な形の応答を生成するために、LLM に渡されます。
このアプローチは、LLM メモリの制限を回避し、クエリに応答するためにナレッジベースから関連情報のみを抽出することにより、幻覚などの予期せぬ動作を軽減します。新しいドキュメントとそのエンベディング表現を追加することで、ナレッジベースを常に最新の状態に保つことができるというメリットがあります。これにより、常に根拠があり、正確で、関連性のある回答ができるようになります。
アーキテクチャの概要
検索拡張生成パターンのアーキテクチャは、Google Cloud 上で次の Vertex AI スタックによって実現されています。
Vertex AI Embeddings for Text: 3,072 トークンまでの長さのドキュメントやテキストが与えられると、API は Vector Store に保存できる 768 次元のテキスト エンべディング(浮動小数点ベクトル)を生成します。
Vertex AI Matching Engine: Google Cloud でフルマネージドの Vector Store を使うと、インデックスにエンべディングを追加し、キー エンベディングを使用して検索クエリを実行することで、非常に高速なベクトル検索ができます。Vertex AI Matching Engine は、10 億以上のベクトルから最も類似したベクトルを見つけます。ローカルで動作する Vector Store とは異なり、Matching Engine はスケール(数百万、数十億のベクトル)に最適化された、エンタープライズ向けの Vector Store です。
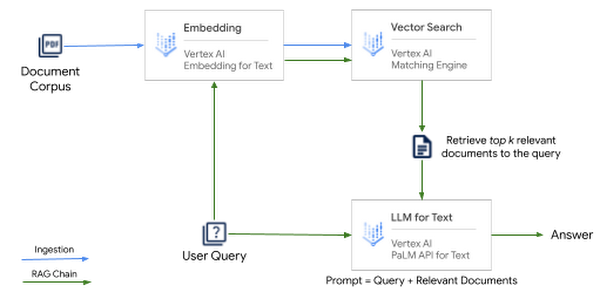
LangChain は、Vertex AI PaLM API for Text、Vertex AI Embeddings、Matching Engine と統合された Retrieval QA チェーンを使用して、これらのコンポーネントのすべてをシームレスにオーケストレートします。質問をされたときに次の手順を行います。
まず、検索ステップを実行し、関連するドキュメントをフェッチします。
次に、LLM に元の質問とともに関連ドキュメントを送信し、回答を生成させます。
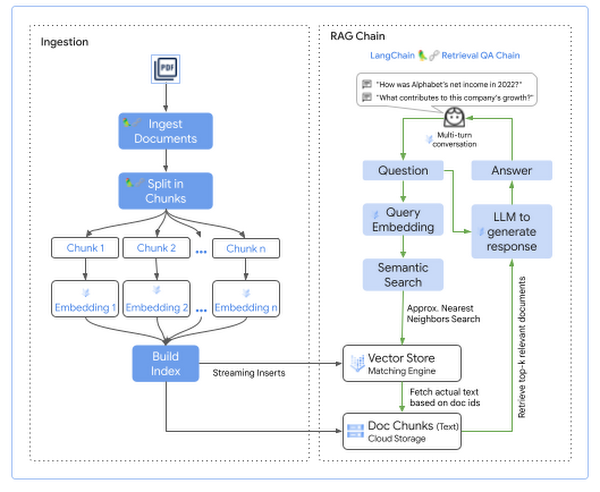
ドキュメントに対するクエリを実行する前に、まずそのドキュメントを検索可能な形式にしておく必要があります。大きく分けて次の 2 つのステージがあります。
クエリ可能な形式へのドキュメントの取り込み
検索拡張生成チェーン
実装
初期設定の一環として、Matching Engine Index が作成され、Index Endpoint にデプロイされてドキュメントを取り込み、近似最近傍探索を返すためにインデックスに対してクエリを実行します。
Matching Engine Index は、ストリーミング インデックスの更新を使用して作成され、インデックスへのドキュメントの追加、更新、削除を行います。ストリーミング更新により、数秒以内にインデックスを更新してクエリを実行できます。
Matching Engine Index Endpoint は、パブリック エンドポイントまたはプライベート エンドポイントとしてデプロイできます。
取り込みのステージで、ドキュメントはコーパスからエンべディングに変換され、後でセマンティック検索を使用してクエリを実行するために Matching Engine Index に追加されます。手順は次のとおりです。
Cloud Storage に保存されているナレッジベースからドキュメントを読み取ります。
各ドキュメントを分割し、プロンプトに関連する部分をコンテキストとして含めます。通常、これらのチャンクのいくつかをコンテキストとして渡し、それぞれのチャンクのサイズが LLM のコンテキストに収まるようにします。
ドキュメントのチャンクごとに次を行います。
Vertex AI Embedding for Text を使用してエンべディングを生成する。
Index Endpoint 経由で Matching Engine Index に生成したエンべディングを追加する。
元のドキュメント テキストを Cloud Storage に追加して、検索結果とともに取得する。
ドキュメントを取り込む際には、次の点を考慮してください。
ドキュメントのチャンクサイズの選択: ドキュメントを分割するときは、必ず各チャンクが LLM のコンテキストの長さに収まるようにしてください。
ドキュメント パーサーの選択: ドキュメント内のコンテンツ タイプに応じて、LangChain や LlamIndex から適切なドキュメント ローダを選択するか、Document AI プロセッサなどを使用して独自のカスタムローダを構築します。
ユーザーのクエリに対して回答を生成するステップは次のとおりです。
Vertex AI Embeddings for Text を使用して、ユーザーのクエリに対するエンべディングを生成します。
Matching Engine Index を検索して、ユーザークエリのエンべディングを使用し、エンべディングの空間から上位 k 件の最近傍を取得します。
ユーザーのクエリに追加のコンテキストとして追加するために、Cloud Storage から取得されたエンべディングの実際のテキストをフェッチします。
取得されたドキュメントをコンテキストとしてユーザーのクエリに追加します。
回答を生成するために、LLM にコンテキストの拡張クエリを送信します。
生成された回答を、ドキュメント ソースへの参照とともにユーザーに返します。
検索拡張生成チェーンでは、次の点を考慮してください。
ドキュメント チャンクの長さと検索結果の数は、回答の費用、パフォーマンス、精度に影響します。ドキュメントのチャンクが長いということは、コンテキストに追加できる検索結果が少ないことを意味し、これは回答の質に影響を与える可能性があります。回答の価格は、コンテキストの入力トークンの数に応じて増加するため、回答を生成する際に、検索結果をいくつ含めるかを検討することが重要です。
チェーンタイプの選択: 関連ドキュメントをコンテキストの一部として LLM へ渡す方法を考慮することが重要です。LangChain は、スタッフィング、MapReduce、調整といったさまざまなメソッドを提供しています。スタッフィングは最もシンプルな方法で、すべての関連ドキュメントがユーザーのクエリとともにプロンプトにスタッフィングされます。
コーパスに関連した質問を実行しましょう。
LLM から返される回答には、答えとその回答につながった情報源の両方が含まれます。これにより、LLM からの回答は常に情報源に対して根拠のあるものになります。
コーパスの外で質問をした場合はどうなるでしょうか?
LLM は、その質問が LLM の領域外である場合、「その答えは私には判断できません」と回答します。これは、プロンプトを通じて、コンテキストにそぐわない質問には答えないように出力が条件付けられるからです。これは、取得されたコンテキストで質問に答えられない場合に、幻覚を軽減するためのガードレールを実装する一つの方法です。LLM で使用するように構成されたプロンプト テンプレートの手順を以下に示します。
以上、Vertex AI PaLM API、Matching Engine、LangChain を使用してドキュメントに対して根拠のある QA システムを構築する方法を示しました。
ご利用方法
LangChain は、さまざまな生成 AI アプリケーションを構築するための柔軟性の高い便利なツールです。LangChain の Vertex AI PaLM 基盤モデルや API とのインテグレーションにより、これらの高性能なモデルを基盤としたアプリケーションの構築がさらに便利になりました。この投稿では、Vertex AI PaLM API for Text、Vertex AI Embedding for Text、Vertex AI Matching Engine、LangChain を使用して、検索拡張生成パターンに基づいた QA アプリケーションを実装する方法をご紹介しました。
GitHub リポジトリをクローニングし、ノートブックを使って独自のドキュメントでお試しください。
テキストとエンべディング モデルの生成 AI のサポートに関する Vertex AI ドキュメントを参照してください。
Vertex AI PaLM API for Text、Embedding API、Matching Engine とのインテグレーションについては、LangChain ドキュメントをご覧ください。
LangChain の Vertex AI PaLM API、Vertex AI Embedding API、Vertex AI Matching Engine とのインテグレーションに協力してくれた、Crispin Velez、Leonid Kuligin、Tom Piaggio、Eugenio Scafati に感謝します。このブログ投稿に協力し、記事を推敲してくれた Kalyan Pamarthy と Jarek Kazmierczak に感謝します。
- Vertex Generative AI、グループ プロダクト マネージャー Anand Iyer
- 生成 AI ソリューション、ソリューション アーキテクト Rajesh Thallam



