Cloud SQL: Vertex AI による AI 搭載アプリの迅速なプロトタイピング
Gunjan Juyal
Software Engineer
※この投稿は米国時間 2024 年 5 月 23 日に、Google Cloud blog に投稿されたものの抄訳です。
PostgreSQL データで ML の力を活用する方法を模索しているデベロッパーは、複雑なインテグレーションや長い習得時間の問題に直面することが少なくありません。Cloud SQL for PostgreSQL によってこうしたギャップが埋まり、Vertex AI が提供する最先端の ML モデルとベクトル生成手法を SQL クエリ内で直接利用できるようになりました。テキストデータからのベクトル生成、大規模なベクトル コーパスに対する効率的な検索、リアルタイム予測の取得を簡単に行うことができるため、インテリジェント アプリケーションを推進し、運用の複雑さを軽減できます。
このブログ投稿は、ML で使用するエンベディングとベクトルの基本的な知識を持っている方を対象としています。詳細については、Vertex AI のドキュメントをご覧ください。
Cloud SQL for PostgreSQL の google_ml_integration 拡張機能
google_ml_integration 拡張機能は Google の Vertex AI プラットフォームへのブリッジを提供し、SQL 環境内から ML モデルを直接呼び出すことができます。セマンティック分析用テキスト エンべディングの生成、リアルタイムの予測、LLM に関する膨大な知識と理解の活用を、いずれも Cloud SQL for PostgreSQL データベースの環境内から簡単に行えます。
google_ml_integration 拡張機能で提供される Vertex AI のインテグレーションにより、Cloud SQL for PostgreSQL インスタンスを Vertex AI に接続するための外部パイプラインが必要なくなります。これにより、長時間実行されるベクトル インデックス生成時やトランザクションのベクトル検索クエリ実行時のエンべディング生成が大幅に簡素化されます。
インスタンスの設定手順については、このブログ投稿のサンプル アプリケーションの構築をご覧ください。
PostgreSQL の pgvector 拡張機能
pgvector 拡張機能では、IVFFLAT や HNSW などのさまざまな近似最近傍(ANN)インデックス タイプとともに、ベクトルタイプのサポートが追加されます。これにより、効率、速度、再現率、パフォーマンスが最適化されたベクトルストアを設計できます。詳細については、この内容について詳述した以前のブログ投稿をご覧ください。
pgvector と google_ml_integration を使用した AI 搭載アプリ
以前のブログ投稿(および対応する Colab)では、Vertex AI と pgvector を使用した AI 対応アプリケーションの構築について紹介しました。google_ml_integration により、こうしたアプリケーションの開発とメンテナンスがさらに簡素化されました。その理由は、インデックス作成時と検索時に、エンべディングの生成向けに外部パイプラインでデータベースを LLM と統合する必要がなくなり、SQL の使いやすさとトランザクション保証を利用できるようになったためです。主なメリットをいくつかご紹介します。
-
Vertex AI を統合するアプリケーション側の「接着剤」をなくすことで、アプリケーション アーキテクチャを簡素化
-
開発時間を短縮
-
列の生成やエンベディング生成のインテグレーションにより、インデックスの作成と維持を容易化
- Vertex AI で生成されるエンベディングを利用して検索クエリのトランザクション保証を改善
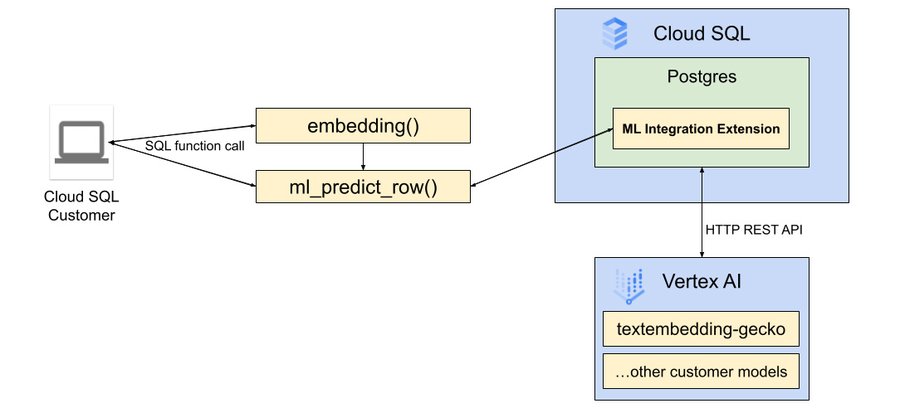
Vertex AI とのネイティブ インテグレーションによって簡素化された制御フロー
サンプル アプリケーションの構築
以降のセクションでは、Vertex AI のインテグレーションを使用して pgvector と LLM でアプリケーションを構築する手順を詳しく説明します。
Vertex AI とデータベースのインテグレーションを有効にする
1.google_ml_integration 拡張機能を使用して Cloud SQL for PostgreSQL インスタンスの作成やパッチ適用を行う必要があります。
-
--enable-google-ml-integration(この機能の有効化) -
–database-flags cloudsql.enable-google-ml-integration=on(PostgreSQL 拡張機能の有効化)
2.Vertex AI にアクセスするための Identity and Access Management(IAM)権限を Cloud SQL サービス アカウントに付与します。関連する IAM ロールは aiplatform.user であり、これらの変更が反映されるまでに 5 分ほどかかる場合があります。
3.インスタンスに接続し、プライマリ Cloud SQL インスタンスのデータベースに google_ml_integration 拡張機能をインストールします。このデータベースには、予測を実行するデータが含まれています。
上記の手順が完了したら、embedding メソッドと ml_predict_row メソッドの使用を開始して、Vertex AI からテキストのエンベディングと予測を取得し、データベースでそれらの保存と検索を行えます。
「toy」データセットの読み込み
PostgreSQL と LLM を使用した AI 搭載アプリの構築に関する以前のブログ投稿では、「『toy』データセットの読み込み」セクションでこの内容について詳しく説明しました。続行する前に、そこに記載されている手順に沿って操作してください。
Vertex AI のインテグレーションを使ったベクトル エンベディングの生成
Vertex AI Text Embedding モデルを使用してベクトル エンベディングを生成します。次の例は、使い慣れた SQL インターフェースからのエンベディング生成を示しています。google_ml_integration は、Vertex AI モデルとのインテグレーション、エラー処理、型変換を透過的に処理します。いずれも SQL の表現力と、PostgreSQL による ACID 保証を使用して行われます。
次に、「products」テーブルのさまざまなおもちゃを説明するテキストのエンベディングを生成してみましょう。エンベディングの保存に使用する新しい列を既存の「products」テーブルに追加し、Vertex AI のインテグレーションを利用してバックグラウンドでエンベディングを自動的に計算する生成された列の式を追加します。これにより、データの進化に応じてエンベディングを入力し同期するための便利なメカニズムが得られます。また、類似ベクトルを効率的に検索できる pgvector 拡張機能によって提供されるパワフルな ANN インデックス タイプである HNSW インデックスも作成します。
公開時に、Vertex AI Text Embedding モデルが 1 つの API リクエストで受け付けるのは、3,072 入力トークンのみです。そのため、長い商品説明は 2,000 文字まで切り捨てられます。また、説明の全文を適切なサイズのバイトに分割し、各チャンクを別のエンベディング テーブルに行として保存することもできます。ただし、このデモでは引き続き、上記の簡単な例で説明します。
pgvector 検索演算子を使用して類似のおもちゃを見つける
pgvector は次のような複数の距離関数をサポートしています。
-
ユークリッド距離(<->)
-
コサイン距離(<=>)
自然言語検索クエリのベクトル エンベディングを生成し、これらの類似性検索演算子によって効率的な ANN 検索を実行して関連商品を見つけることが、すべて 1 つの SQL ステートメント内で済みます。次の例では、コサイン距離関数を使用して、クエリのセマンティックな意味に一致する商品を検索します(たとえば、入力クエリ「Indoor games」に対してカードゲームやミニチュア卓上ゲームが返されます)。効率的な ANN 検索の例については、pgvector に関する以前のブログ投稿をご覧ください。
上記のコード スニペットでは、Vertex AI とのインテグレーションとエンベディングの生成のシンプルな例をいくつかご紹介しました。ただし、embedding メソッドと ml_predict_row メソッドの使用は、シンプルなエンベディング生成だけにとどまりません。急速に拡大する LLM のポートフォリオの力を活用して、テキストの分類、予測の呼び出し、感情分析、プロンプトからのテキスト生成などを行うことができます。これらをさらに SQL UDF にカプセル化して、ビジネス ドメインに合わせてカスタマイズされたシンプルなインターフェースを提供できます。
まとめ
詳細については、テキスト エンベディングとテキスト分類に関する Vertex AI Colab をご覧ください。または、Colab の完全なライブラリをご確認ください。
-ソフトウェア エンジニア Gunjan Juyal



