pgvector、LLM、LangChain を使用して Google Cloud データベースで AI 搭載アプリを構築する
Google Cloud Japan Team
※この投稿は米国時間 2023 年 6 月 27 日に、Google Cloud blog に投稿されたものの抄訳です。
Cloud SQL for PostgreSQL と AlloyDB for PostgreSQL で pgvector 拡張機能がサポートされるようになり、PostgreSQL データベースでベクトル検索操作ができるようになりました。お知らせの全文はこちらでお読みいただけます。
このチュートリアルでは、Google Cloud で pgvector、LangChain、LLM を使用してわずか数行のコードを記述するだけでアプリケーションにジェネレーティブ AI の機能を追加する方法を順を追ってご紹介します。ガイド付きチュートリアル動画もご覧いただけます。PostgreSQL データベースに保存されているデータに関する人間の言語によるクエリを理解し、それに応答できるサンプル Python アプリケーションを構築します。次に、子どものおもちゃに関する既存のデータセットに基づいて、AI 生成の新しい商品の説明を作成するようアプリケーションに学習させることで、アプリケーションのクリエイティブ リミットをさらに押し広げます。昔の「オレンジと白の猫のぬいぐるみ」のような退屈な説明は忘れてください。AI を活用することにより、「ベビーベッドから幼稚園まで、小さなお子さまのずっとそばにいてくれる、ワイルドでとってもキュートなお友だち」のような商品説明を生成できるようになります。では、AI が生成したキャッチフレーズを見てみましょう。
Cloud SQL と AlloyDB for PostgreSQL に pgvector をインストールする方法
pgvector 拡張機能は、Cloud SQL for PostgreSQL および AlloyDB for PostgreSQL の既存のインスタンス内に、以下のように CREATE EXTENSION コマンドを使ってインストールできます。既存のインスタンスがない場合は、Cloud SQL と AlloyDB のインスタンスを作成します。
新しい「vector」データ型
内部では、pgvector 拡張機能は PostgreSQL の「CREATE TYPE」コマンドを使用して「vector」という新しいデータ型を登録します。PostgreSQL のテーブル列はこの新しい「vector」データ型を使って定義できます。以下に示すように、カンマ区切りされた数値を角括弧で囲んだ文字列を使用すると、この列に値を挿入できます。
次のコード スニペットでは、例として 3 次元ベクトルを使用しています。実際の AI / ML アプリケーションでは、ベクトルの次元はもっと多くなり、一般的には数百程になります。
pgvector の新しい類似性検索演算子
pgvector 拡張機能では、ベクトルに対して類似性のマッチングを行うための新しい演算子も導入されており、意味的に似ているベクトルを見つけることができます。このような演算子には次の 2 つがあります。
‘<->’: 2 つのベクトル間のユークリッド距離を返します。ユークリッド距離は、ベクトルの大きさが重要なアプリケーション、たとえばマッピングやナビゲーション アプリケーション、あるいは ML で K 平均法クラスタリング アルゴリズムを実装する場合に適しています。
‘<=>’: 2 つのベクトル間のコサイン距離を返します。コサイン類似度は、ベクトルの方向が重要なアプリケーションに適しています。たとえば、レコメンデーション システムや自然言語処理タスクを実装するために、特定のドキュメントに最も類似したドキュメントを見つけようとする場合などです。
このサンプル アプリケーションでは、コサイン類似度検索演算子を使用します。
サンプル アプリケーションの構築
pgvector と LLM を使ってアプリケーションを構築してみましょう。LangChain も使用します。LangChain はオープンソースのフレームワークで、LLM を使用して複雑なアプリケーションを簡単に作成できるようにする、いくつかの事前構築済みコンポーネントを提供しています。
アプリケーション全体は Cloud SQL PostgreSQL 用のインタラクティブな Google Colab ノートブックとして利用できます。このサンプル アプリケーションは、追加のインストールやコードを 1 行も記述することなく、ウェブブラウザから直接実行できます。
Colab ノートブックの指示に沿って、環境をセットアップします。必要な名前のインスタンスが存在しない場合、ノートブックによって Cloud SQL PostgreSQL インスタンスが作成されることに留意してください。ノートブックを実行すると、Google Cloud の料金が発生することがありますが、その費用分のクレジットを提供する無料トライアルをご利用いただける場合があります。
「toy」データセットの読み込み
サンプル アプリケーションでは、子どものおもちゃを売買するオンライン マーケットプレイスを運営する e コマース企業の例を使用しています。このノートブックのデータセットは Kaggle で入手可能な大規模な公開小売データセットからサンプリングして作成されています。このノートブックで使用されているデータセットには約 800 のおもちゃ関連商品しか含まれていませんが、公開されているデータセットにはさまざまなカテゴリの 37 万以上の商品が含まれています。
Colab ノートブックに記載されている手順に沿って環境をセットアップした後、提供されたサンプル データセットを Pandas データフレームに読み込みます。参考までに、データセットの最初の 5 行を以下に示します。

「products」という PostgreSQL テーブルにデータセットを保存します。このテーブルは、product_id、product_name、description、list_price の 4 つのフィールドを持つシンプルなスキーマを有しています。
Vertex AI を使ったベクトル エンベディングの生成
Vertex AI Text Embedding モデルを使用して、「products」テーブルのさまざまなおもちゃを説明するベクトル エンベディングを生成します。公開時に、Vertex AI Text Embedding モデルが 1 つの API リクエストで受け付けるのは、3,072 入力トークンのみです。そのため、最初のステップでは、長い商品説明を 500 文字ずつの小さなチャンクに分割します。
LangChain で長いテキストを小さなチャンクに分割する
LangChain ライブラリから RecursiveCharacterTextSplitter メソッドを使用できます。これは、長いテキストを小さなチャンクに分割する便利で簡単な方法を提供します。
Vertex AI を使用してベクトル エンベディングを取得する
長い商品説明を小さなチャンクに分割したら、Vertex AI で利用可能な Text Embedding モデルを使用して、各チャンクのベクトル エンベディングを生成できます。わずか数行のコードでこれが実現できることに注目してください。
pgvector を使用して生成したエンベディングを保存する
pgvector 拡張機能を作成し、新しいベクトルデータ型を登録すると、NumPy の配列を PostgreSQL テーブルに直接格納できます。
pgvector コサイン検索演算子を使用して類似のおもちゃを見つける
上記のステップを完了することで、簡単な英語を使っておもちゃのデータセット全体を検索できるようになりました。下の画像をご覧ください。特定の価格帯に基づいておもちゃをフィルタすることもできるハイブリッド検索機能を実演しています。
では、その仕組みについて説明します。詳しく見ていきましょう。
ステップ 1: 受信した入力クエリに対するベクトル エンベディングを生成する。
ステップ 2: 新しい pgvector コサイン類似度検索演算子を使用して、関連商品を見つける
パワフルな PostgreSQL と pgvector のクエリ セマンティクスを使用して、ベクトル検索操作と「list_price」列の通常の SQL フィルタをどのように組み合わせることができるかに注目してください。
ユースケース 1: AI がキュレートするコンテキスト型ハイブリッド検索の構築
類似のおもちゃ関連商品の見つけ方を習得したところで、次は AI でアプリケーションを強化しましょう。大規模言語モデル(LLM)を使ってアプリケーションをもっとインテリジェントにし、これらの商品に関するユーザークエリに答えられるようにします。
次の例では、祖父母が AI を搭載した検索インターフェースを使用して、簡単な英語でニーズを説明することで、孫のために完璧なおもちゃを見つける様子を示しています。
ユースケース 2: AI によるクリエイティブなコンテンツ生成の追加
ハイブリッド セマンティック検索の構築は、LLM とベクトル エンベディングを使用する一般的で非常に役立つ例です。ただし、この新しいテクノロジーを使ってできることは他にもまだまだたくさんあります。
LLM プロンプト入力とモデルの温度設定を調整することで、AI を活用したクリエイティブなコンテンツ生成ツールを作成できます。温度はその範囲を 0~1 とする LLM プロンプトの入力パラメータで、モデルの出力のランダム性を定義します。温度が高いほど、よりクリエイティブなレスポンスが得られ、温度が低いほど、より明確で事実に基づく出力が得られます。
次の例では、販売者がジェネレーティブ AI を使用して、プラットフォームに追加する新しい自転車関連商品の自動生成された商品説明を取得する方法をお見せします。
ユースケース 2: AI によるクリエイティブなコンテンツ生成の追加
ハイブリッド セマンティック検索の構築は、LLM とベクトル エンベディングを使用する一般的で非常に役立つ例です。ただし、この新しいテクノロジーを使ってできることは他にもまだまだたくさんあります。
LLM プロンプト入力とモデルの温度設定を調整することで、AI を活用したクリエイティブなコンテンツ生成ツールを作成できます。温度はその範囲を 0~1 とする LLM プロンプトの入力パラメータで、モデルの出力のランダム性を定義します。温度が高いほど、よりクリエイティブなレスポンスが得られ、温度が低いほど、より明確で事実に基づく出力が得られます。
次の例では、販売者がジェネレーティブ AI を使用して、プラットフォームに追加する新しい自転車関連商品の自動生成された商品説明を取得する方法をお見せします。
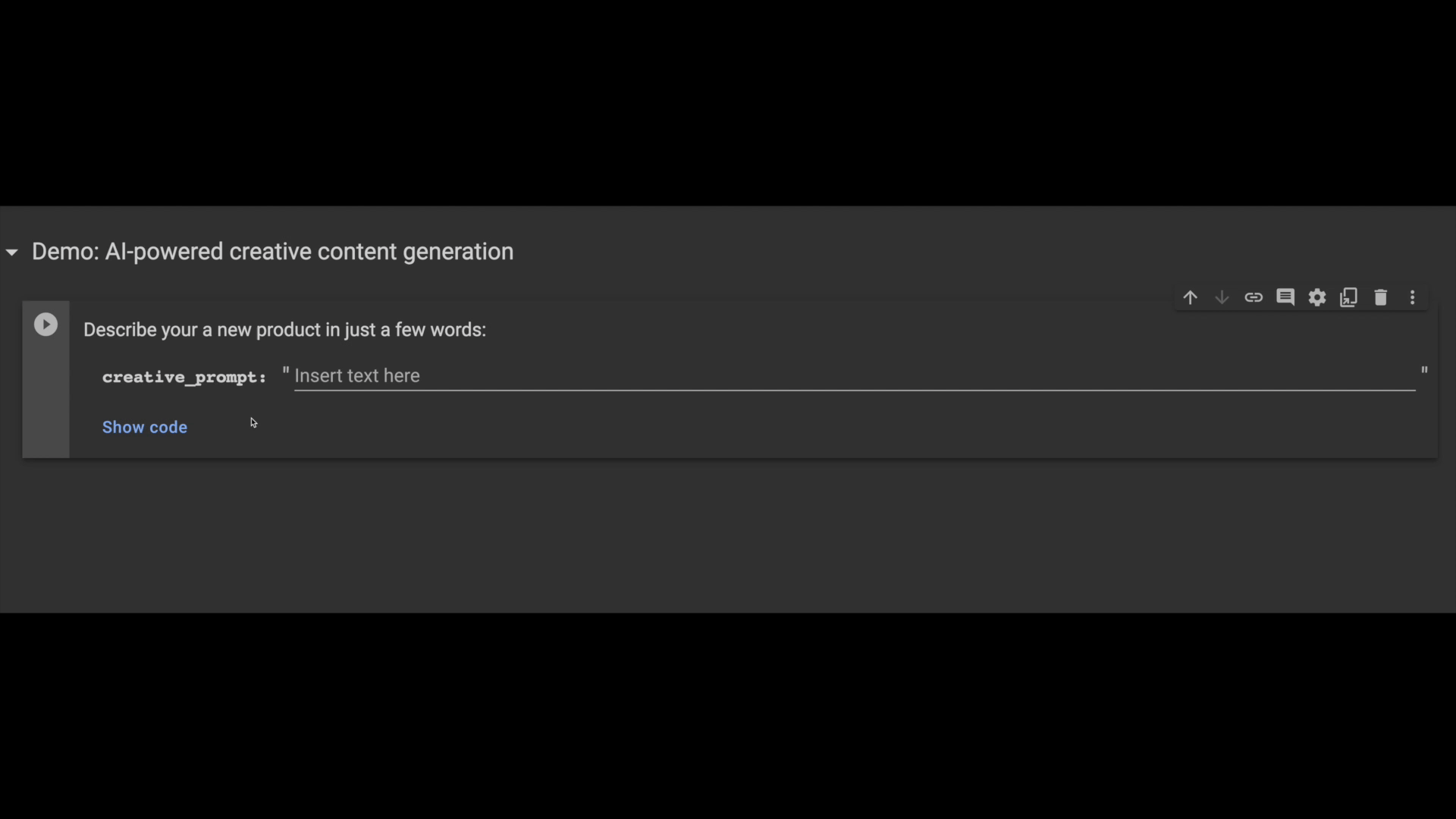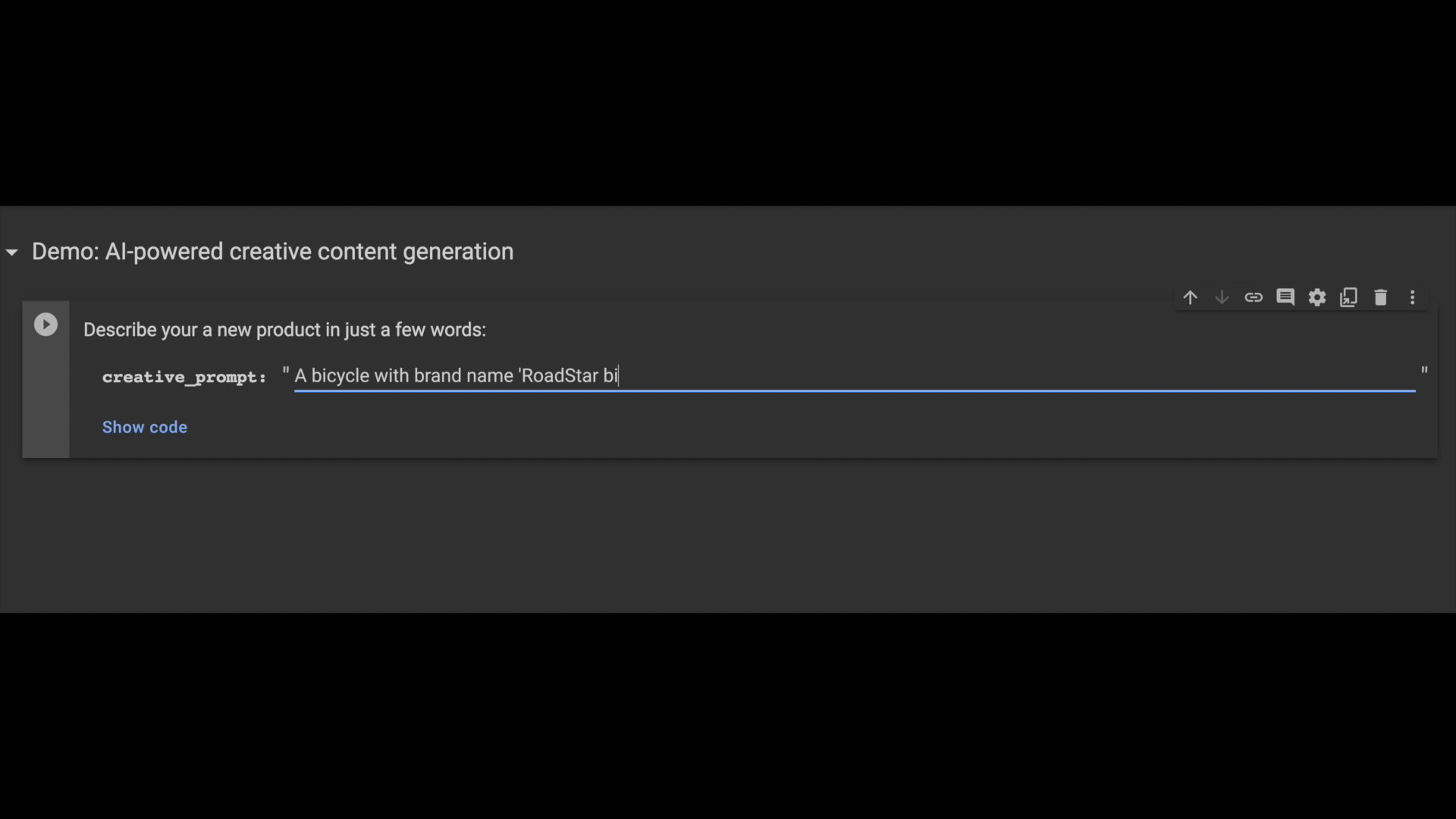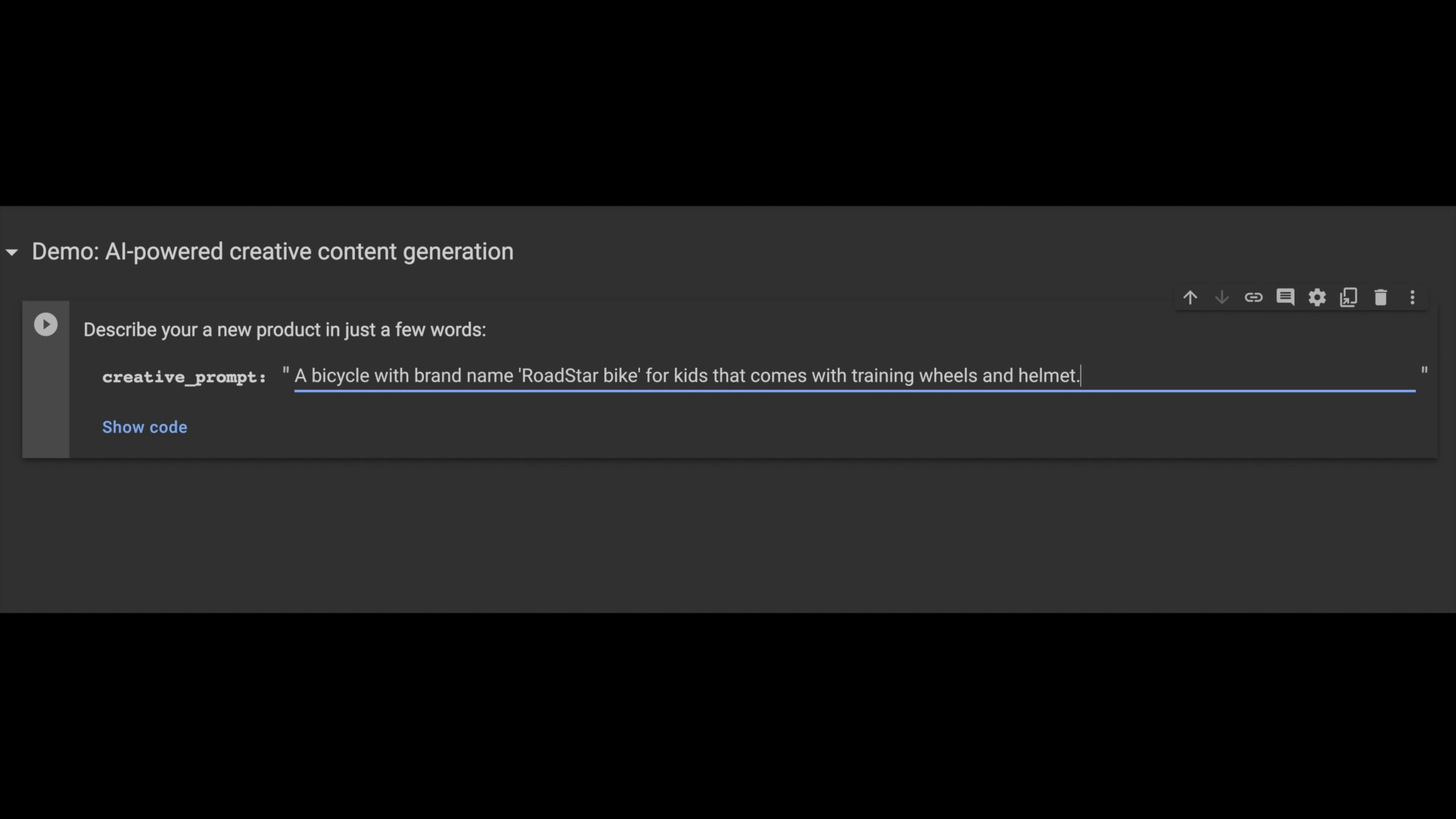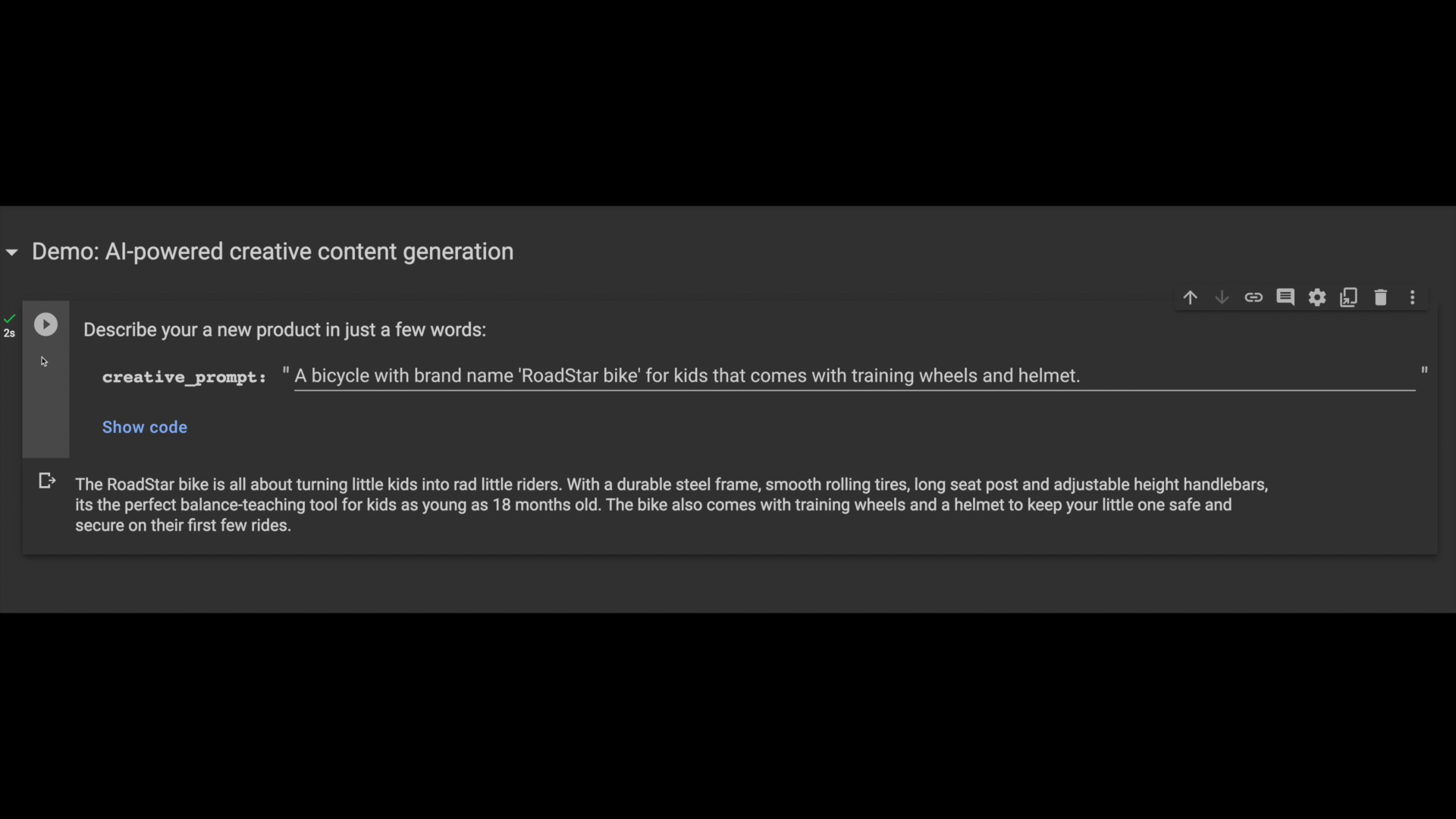
以前と同様に、pgvector 類似性検索演算子を使用して、似ている商品説明を見つけ、それをプロンプト コンテキストとして使って新しいクリエイティブな出力を生成します。上記の出力に使用した LLM プロンプトのコード スニペットは以下のとおりです。
まとめ
このブログ記事では、リレーショナル データベースの能力と LLM を組み合わせることで実装できるパワフルな機能の例を 2 つだけ紹介しました。
ジェネレーティブ AI はアプリケーション開発における大きなパラダイム シフトであり、患者からの複雑な医学的質問への回答から企業のサイバー攻撃分析の支援まで、新しい方法でユーザーにサービスを提供する斬新なアプリケーションを作成できます。今回ご紹介したのは、ジェネレーティブ AI が持つ可能性のほんの一例です。皆様がジェネレーティブ AI を使って何を構築するのかに大いに期待しています。
このブログ記事でご紹介した Google Colab ノートブックを試用して、今すぐ構築を開始しましょう。

