Vertex AI による効率的な PyTorch のトレーニング
Google Cloud Japan Team
※この投稿は米国時間 2022 年 12 月 16 日に、Google Cloud blog に投稿されたものの抄訳です。
Vertex AI は、PyTorch ベースのディープ ラーニング モデルを学習するための柔軟でスケーラブルなハードウェアと安全なインフラストラクチャを、事前構築されたコンテナおよびカスタム コンテナで提供します。大量のデータを扱うモデル トレーニングの場合、分散トレーニングのパラダイムを使用し、Cloud Storage からデータを読み込むことをおすすめします。しかし、Cloud Storage のリモート ストレージのようなクラウド上のデータを使ったトレーニングでは、新たな課題が発生します。たとえば、データセットが多数の小さな個別ファイルによって構成されている場合、ランダムにファイルにアクセスすると、ネットワークのオーバーヘッドが発生することがあります。また、ハードウェア アクセラレータ(GPU)をフル活用するためには、データを送り込む速度であるデータ スループットも課題です。
この投稿では、トレーニング パフォーマンスを向上させるための方法を、分散トレーニングなしから始めて、クラウド上のデータを使用した分散トレーニング パラダイムまで、順を追って説明します。最終的には、Cloud Storage 上のデータをローカル ディスク上のデータと同じ速度に近づけることで、トレーニングを 6 倍高速化できました。Vertex AI Training サービスと Vertex AI Experiments および Vertex AI TensorBoard による実験と結果を記録する方法を紹介します。
このブログ投稿の付属コードは、GitHub リポジトリでご覧いただけます。
PyTorch 分散トレーニング
PyTorch はネイティブに分散トレーニング戦略をサポートしています。
DataParallel(DP)は、1 つのマシンのマルチ GPU トレーニングによく使われるシンプルな戦略です。しかし、依存する単一のプロセスがパフォーマンスのボトルネックになる可能性があります。この方法は、メインスレッドでミニバッチ全体を読み込み、サブミニバッチを GPU に分散させるものです。モデル パラメータはメイン GPU でのみ更新され、次の反復処理の開始時に他の GPU にブロードキャストされます。
DistributedDataParallel(DDP)は、マルチノード / マルチ GPU のシナリオに適合し、モデルは個々のプロセスによって制御される各デバイス上に複製されます。各プロセスは独自のミニバッチを読み込み、それを独自の GPU に渡します。また、各プロセスには独自のオプティマイザがあり、パラメータのブロードキャストを行わないため、通信のオーバーヘッドを削減できます。最後に、DP とは異なり、GPU 間で全削除演算を行うことができます。このマルチプロセスにより、トレーニングのパフォーマンスを向上できます。
FullyShardedDataParallel(FSDP)も DDP と同様のデータ並列パラダイムです。しかし、モデル パラメータが各 GPU に複製される DDP とは異なり、オプティマイザの状態、勾配、パラメータを複数の FSDP ユニットにシャーディングすることにより、より多くのデータや大きなモデルへのフィットを可能にします。
異なる分散トレーニング戦略は、異なるトレーニング シナリオに理想的に適合できます。しかし、特定の環境構成に最適なものを選ぶのは容易でない場合もあります。たとえば、GPU へのデータ読み込みパイプラインの有効性、マルチノード環境でのバッチサイズやネットワーク帯域幅は、分散トレーニング戦略のパフォーマンスに影響を与える可能性があります。
この投稿では、PyTorch ResNet-50 をモデル例として、ImageNet 検証データ(50K 画像)でトレーニングさせ、異なるトレーニング戦略でのトレーニング パフォーマンスを測定します。
デモ
環境の構成
テスト環境として、Vertex AI Training 上に以下の設定でカスタムジョブを作成します。
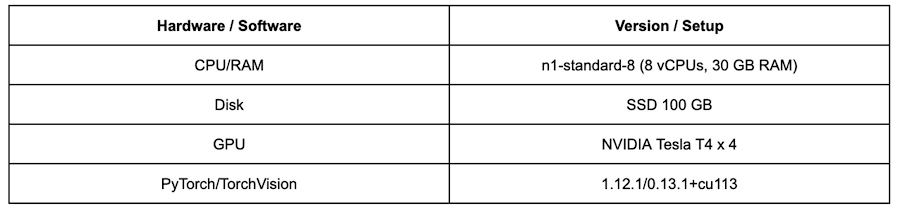
以下は、以下のすべての実験に設定された学習用ハイパーパラメータです。

以下の各実験では、10 エポック分のモデルのトレーニングを行い、平均化したエポック時間をトレーニング パフォーマンスとします。なお、今回はトレーニング時間の短縮に重点を置いており、モデルのパフォーマンスそのものに重点を置いていません。
gcsfuse および WebDataset で Cloud Storage からデータを読み込む
Google Cloud は gcsfuse を使用して Vertex AI Training のジョブから Cloud Storage 上のデータにアクセスします。Vertex AI のトレーニング ジョブには、すでに gcsfuse 経由で Cloud Storage バケットがマウントされているため、gcsfuse を使用するための追加作業は必要ありません。Vertex AI のトレーニング用ジョブである gcsfuse は、ローカル ファイル システム上のファイルと同様に、Cloud Storage 上のデータにも簡単にアクセスできます。これにより、大容量ファイルの順次読み取りでも高いスループットが可能です。データ読み込みパイプラインは、クラウドから個々のデータファイルを読み込む際に、分散トレーニングのボトルネックとなる可能性があります。WebDataset は PyTorch のデータセット実装で、特にリモート ストレージ環境でのストリーミングのデータアクセスを改善するために設計されています。WebDataset の考え方は、TFRecord 同様で、複数の未処理データファイルを収集し、1 つの POSIX tar ファイルにコンパイルするというものです。しかし、TFRecord とは異なり、フォーマット変換を行わず、データにオブジェクトのセマンティクスを割り当てないため、データのフォーマットは tar ファイルでもディスク上と同じになります。WebDataset で実現できるパイプラインのパフォーマンス向上のポイントについては、こちらのブログ投稿をご覧ください。
WebDataset は、大量の個別画像を少数の tar ファイルに分割します。トレーニング中は、1 つのネットワーク リクエストで複数の画像を取得し、次の数回のバッチのためにローカルでキャッシュに保存できます。そのため、シーケンシャル I/O は、ネットワーク通信のオーバーヘッドを大幅に削減できます。以下のデモでは、WebDataset を使用した場合と使用しない場合の、Cloud Storage 上のデータを使用したトレーニングの違いを gcsfuse で確認しています。
注: WebDataset は公式の TorchData ライブラリに torchdata.datapipes.iter.WebDataset として取り込まれました。しかし、TorchData lib はベータ版の段階であるため、安定版がありません。そのため、依存関係としてオリジナルの WebDataset にこだわります。
分散トレーニングなし
まず、ResNet-50 を 1 つの GPU でトレーニングさせ、ベースラインのパフォーマンスを求めます。
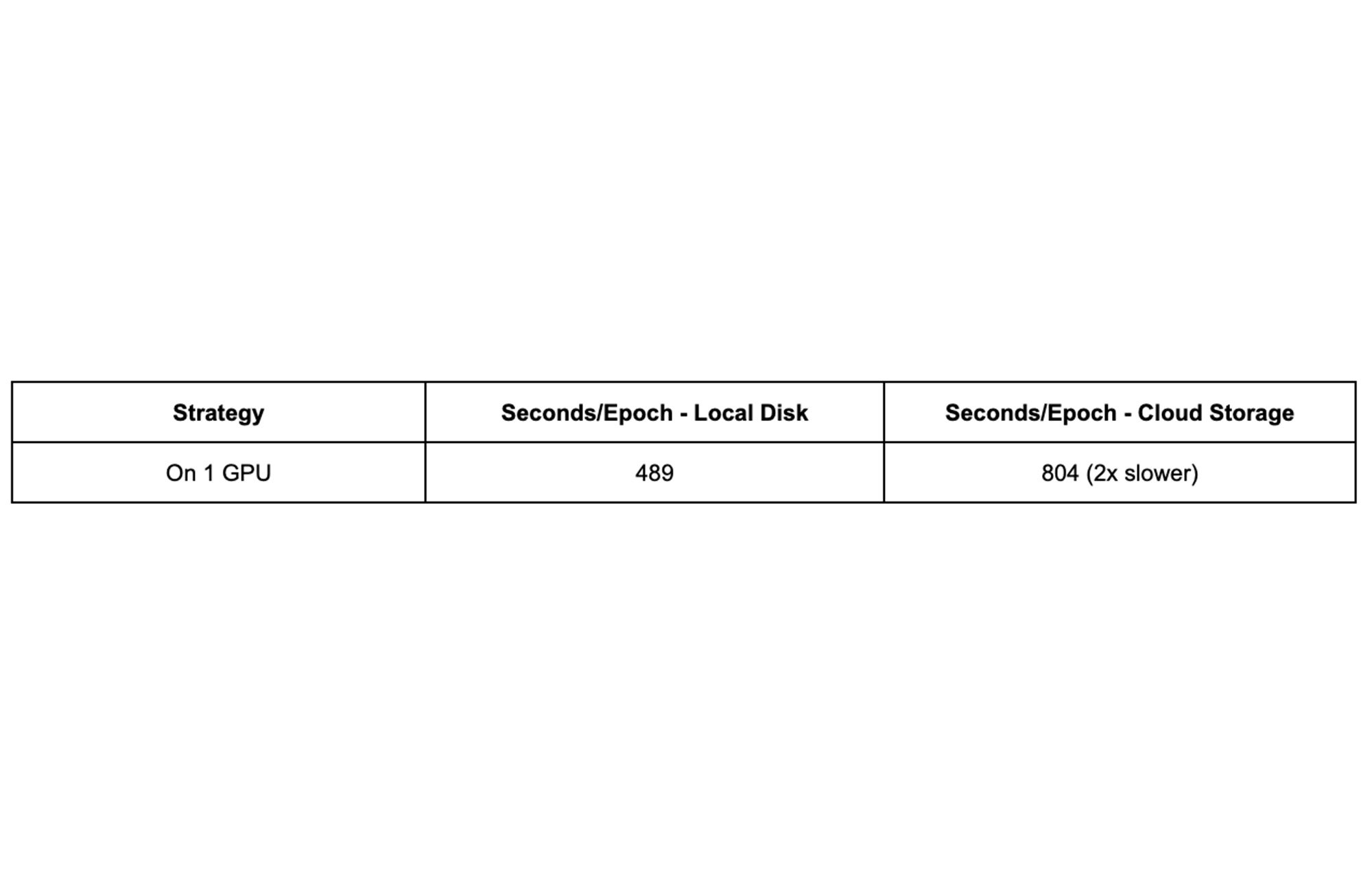
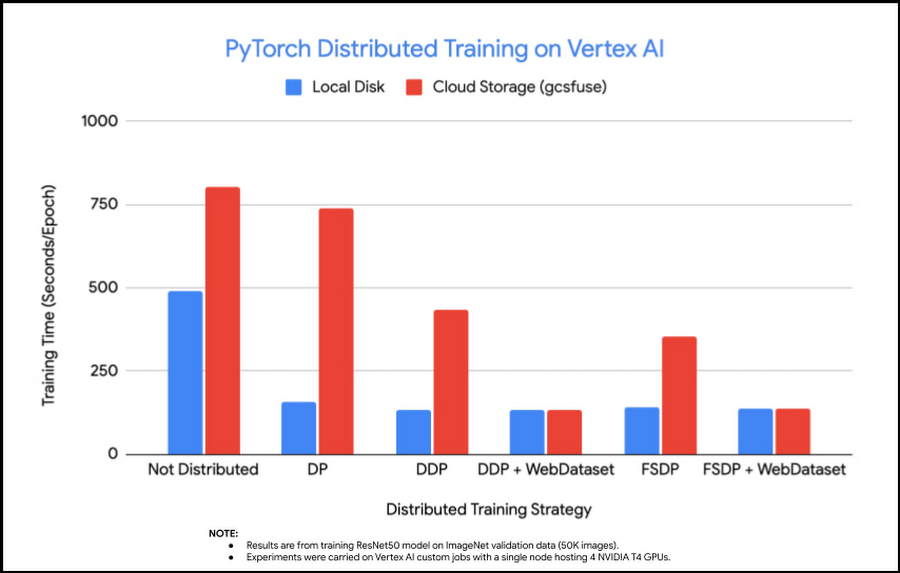
この結果から、1 つの GPU で学習する場合、Cloud Storage のデータを使用すると、ローカルディスクを使用する場合の約 2 倍の時間がかかることがわかります。これを念頭に置きながら、複数の手法で段階的にパフォーマンスを高めていきます。
DataParallel(DP)
DataParallel 戦略は、最小限のコード変更で 1 台のマシンに複数の GPU デバイスをトレーニングするために PyTorch が導入した最もシンプルな方法です。実際には、1 行のコード変更と同じくらい小さなものです。4 台の GPU で DP を適用した結果、以下のようになります。

ローカル ディスクのデータによるトレーニングが 3 倍高速化(489 秒から 157 秒)。
Cloud Storage 上のデータを使ったトレーニングがわずかに高速化(804 秒から 738 秒)。
Cloud Storage 上のデータを使った分散トレーニングは、ネットワークのボトルネックによりデータの読み込み待ちという入力に縛られたものになってしまうことが見て取れます。
DistributedDataParallel(DDP)
DistributedDataParallel は、DataParallel よりも高機能で強力です。DP はシングル プロセスのマルチスレッドで Python GIL の競合に悩まされています。一方、DDP はマルチノードやモデルの並列処理などより多くのシナリオに対応できるため、複雑さは増すものの、DP よりも DDP を使うことが推奨されます。ここでは、4 台の GPU を備える単一ノードで DDP の実験を行い、各 GPU は個別のプロセスで処理されるようにしています。
Google Cloud は nccl バックエンドを使用して、DDP 用のプロセス グループを初期化し、モデルを構築しています。
DDP 戦略と WebDataset を用いて、4 台の GPU で ResNet-50 をトレーニングします。
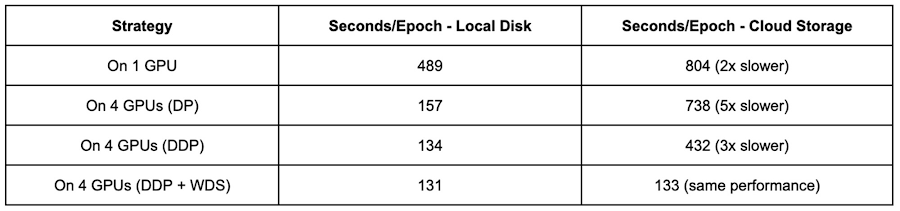
4 台の GPU で DDP を有効にした結果、以下のようになります。
ローカル ディスクのデータを用いたトレーニングにより、DP よりもさらに高速化(157 秒から 134 秒)。
Cloud Storage のデータを使ったトレーニングでは、738 秒から 432 秒と大幅に改善(しかしローカル ディスクを使ったトレーニングに比べると 3 倍遅い)
WebDataset 形式のソースファイルを使用した場合、Cloud Storage 上のデータを使ったトレーニングが大幅に高速化され(432 秒から 133 秒)、ローカル ディスク上のデータを使ったトレーニングと非常に近い、あるいは同等の速度を達成。
入力制限の問題は、DDP を使用することで緩和されます。これは、データを読み込む際に Python GIL の競合が発生しないためと予測できます。また、WebDataset によるデータのシャーディングは、データの前処理作業が加わるにもかかわらず、ネットワーク通信のオーバーヘッドを除去することでパフォーマンスにメリットをもたらします。最後に、DDP と WebDataset は、分散トレーニングや個々のファイルを小さくしない場合と比較して、トレーニングのパフォーマンスを 6 倍(804 秒から 133 秒)に向上させました。
FullyShardedDataParallel(FSDP)
FullyShardedDataParallel は、モデルレイヤを FSDP 単位でラップしています。前進・後退操作の前にフルパラメータを収集し、勾配を同期させるために reduce-scatter を実行します。一部の構成では、DDP よりも低いピークメモリ使用量を実現しています。FSDP 戦略と WebDataset を用いて、4 台の GPU で ResNet-50 をトレーニングさせます。
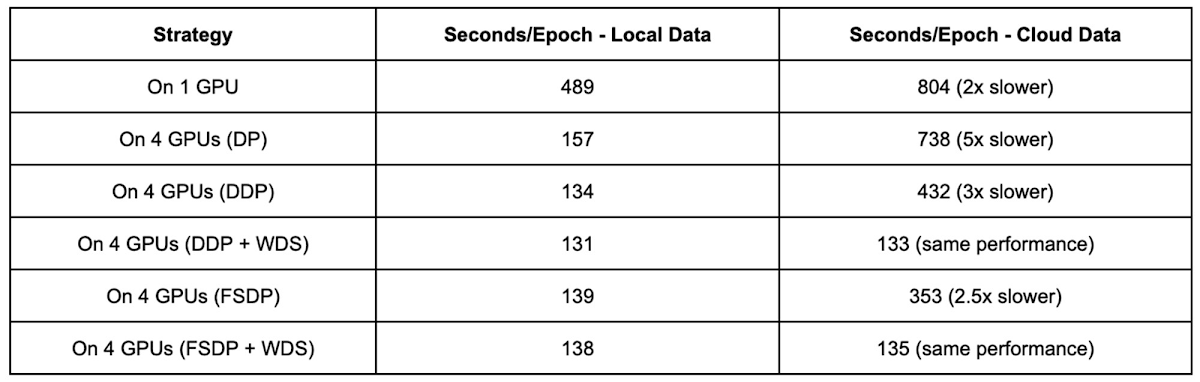
この構成で FSDP を使うと、4 台の GPU を備える単一ノードで DDP と同等のトレーニング パフォーマンスを達成できることがわかります。
WebDataset 形式の有無にかかわらず、これらの異なるトレーニング戦略のパフォーマンスを比較すると、WebDataset を使用し、DistributedDataParallel または FullyShardedDataParallel の分散トレーニング戦略を選択した場合、Cloud Storage 上のデータで全体的に 6 倍のパフォーマンスの向上が見られました。Cloud Storage 上のデータを用いたトレーニング パフォーマンスは、ローカル ディスク上のデータを用いたトレーニング パフォーマンスとほぼ同等です。
Vertex AI TensorBoard によるトラッキングと実験
これまで見ていただいたように、パフォーマンス向上の試みは段階的に行っていました。そのため、いくつかの構成で実験を行い、その展開と結果を追跡する必要がありました。Vertex AI Experiments は、トラッキングと同時にシームレスな実験を可能にします。モデルやパイプラインの実験について、パラメータの追跡、パフォーマンス指標の可視化、比較を行うことができます。
Vertex AI Python SDK を使用して実験を作成し、実験の実行に関連するパラメータ、指標、およびアーティファクトの両方を記録します。この SDK には、モデルの時系列指標をロギングするために Vertex AI TensorBoard を使用して TensorBoard インスタンスを作成する便利な初期化メソッドが用意されています。例えば、トレーニングの損失、検証精度、トレーニング実行時間などをエポックごとに追跡しました。
以下は、実験を開始し、モデル パラメータを記録し、トレーニング ジョブを実行し、トレーニング セッションの終了時に指標を追跡するためのスニペットです。
SDK は実験の実行情報を Pandas のデータフレームとして返す便利な get_experiment_df メソッドをサポートしています。このデータフレームを使うことで、異なる実験構成間のパフォーマンスを効果的に比較できるようになりました。
Vertex AI TensorBoard を使った TensorBoard で実験が裏打ちされているため、コンソールから TensorBoard にアクセスし、より深い分析ができます。実験では、TensorBoard のスカラーに興味のある指標を追加するようにトレーニング コードを修正しました。
まとめ
この投稿では、Google Cloud Storage からデータを読み込むと PyTorch のトレーニングが入力に縛られることを説明し、分散トレーニング戦略の比較と WebDataset 形式の導入によりパフォーマンスを向上させるアプローチを示しました。
WebDataset を使用して個々のファイルをシャーディングすることで、ネットワークのボトルネックを軽減し、シーケンシャル I/O のパフォーマンスが向上します。
複数の GPU でトレーニングを行う場合、
DistributedDataParallelまたはFullyShardedDataParallel分散トレーニング戦略を選択すると、より良いパフォーマンスを得ることが可能になります。大規模なデータセットの場合、ローカル ディスクにダウンロードすることはできません。Vertex AI から Cloud Storage へのデータアクセスの実装を簡素化するために
gcsfuseを使用し、WebDataset を使用して個々のファイルをシャーディングすることで、ネットワーク オーバーヘッドを削減します。Vertex AI は、柔軟性、安全性、制御性を備えながら、実験を行う際の生産性を向上させます。Vertex AI Training のカスタムジョブでは、複数のトレーニング構成、GPU 形状、マシンのスペックを用いた実験を簡単に実行できます。Vertex AI Experiments や Vertex AI TensorBoard と組み合わせることで、モデルやパイプラインの実験におけるパラメータの追跡、パフォーマンス指標の可視化、比較などが可能です。
このブログ投稿の付属コードは、GitHub リポジトリでご覧いただけます。
- 機械学習ソリューション アーキテクト Rajesh Thallam



