Efficient PyTorch training with Vertex AI
Xiang Xu
Software Engineer, Google
Rajesh Thallam
Solutions Architect, Generative AI Solutions
Try Google Cloud
Start building on Google Cloud with $300 in free credits and 20+ always free products.
Free trialVertex AI provides flexible and scalable hardware and secured infrastructure to train PyTorch based deep learning models with pre-built containers and custom containers. For model training with large amounts of data, using the distributed training paradigm and reading data from Cloud Storage is the best practice. However, training with data on the cloud such as remote storage on Cloud Storage, introduces a new set of challenges. For example, when a dataset consists of many small individual files, randomly accessing them can introduce network overhead. Another challenge is data throughput, the speed at which data is fed to the hardware accelerators (GPU) to keep them fully utilized.
In this post, we walk through methods to improve training performance step-by-step, starting first without distributed training followed by distributed training paradigms using data on cloud. Finally we can boost the training by 6x faster with data on Cloud Storage approaching the same speed as data on a local disk. We will show how Vertex AI Training service with Vertex AI Experiments and Vertex AI TensorBoard can be used to keep track of experiments and results.
You can find the accompanying code for this blog post on the GitHub Repo.
PyTorch distributed training
PyTorch natively supports distributed training strategies.
DataParallel (DP) is a simple strategy often used for single-machine multi-GPU training, but the single process it relies on could be the bottleneck of performance. This approach loads an entire mini-batch on the main thread and then scatters the sub mini-batches across the GPUs. The model parameters are only updated on the main GPU and then broadcasted to other GPUs at the beginning of the next iteration.
DistributedDataParallel (DDP) fits multi-node multi-GPU scenarios where the model is replicated on each device which is controlled by an individual process. Each process loads its own mini-batch and passes them to its GPU. Each process also has its own optimizer with no parameter broadcast reducing the communication overhead. Finally, an all-reduce operation is performed across GPUs unlike DP. This multi-process benefits the training performance.
FullyShardedDataParallel (FSDP) is another data parallel paradigm similar to DDP, which enables fitting more data and larger models by sharding the optimizer states, gradients and parameters into multiple FSDP units, unlike DDP where model parameters are replicated on each GPU.
Different distributed training strategies can ideally fit different training scenarios. However, sometimes it is not easy to pick the best one for specific environment configurations. For example, effectiveness of data loading pipeline to GPUs, batch size and network bandwidth in a multi-node setup can affect performance of a distributed training strategy.
In post, we will use PyTorch ResNet-50 as the example model and train it on ImageNet validation data (50K images) to measure the training performance for different training strategies.
Demonstration
Environment configurations
For the test environment, we create custom jobs on Vertex AI Training with following setup:
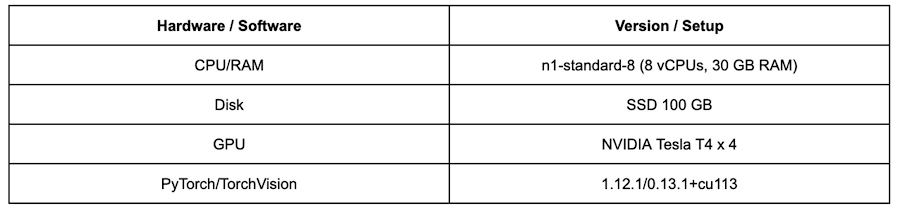
Here are training hyperparameters setup for all of the following experiments:

For each of the following experiments, we train the model for 10 epochs and use the averaged epoch time as the training performance. Please note that we focused on improving the training time and not on the model performance itself.
Read data from Cloud Storage with gcsfuse and WebDataset
We use gcsfuse to access data on Cloud Storage from Vertex AI Training jobs. Vertex AI training jobs have Cloud Storage buckets already mounted via gcsfuse and there is no additional work required to use gcsfuse. With gcsfuse training jobs on Vertex AI can access data on Cloud Storage as simply as files in the local file system. This also provides high throughput for large file sequential reads.
Data loading pipeline could be a bottleneck of distributed training when it reads individual data files from the cloud. WebDataset is a PyTorch dataset implementation designed to improve streaming data access especially in remote storage settings. The idea behind WebDataset is similar to TFRecord, it collects multiple raw data files and compiles them into one POSIX tar file. But unlike TFRecord, it doesn’t do any format conversion and doesn’t assign object semantics to data and the data format is the same in the tar file as it is on disk. Refer to this blog post for key pipeline performance enhancements we can achieve with WebDataset.
WebDataset shards a large number of individual images into a small number of tar files. During training, each single network request will be able to fetch multiple images and cache them locally for the next couple of batches. Thus the sequential I/O allows much lower overhead of network communication. In the below demonstration, we will see the difference between training using data on Cloud Storage with and without WebDataset using gcsfuse.
NOTE: WebDataset has been incorporated into the official TorchData library as torchdata.datapipes.iter.WebDataset. But the TorchData lib is currently in the Beta stage and doesn’t have a stable version. So we stick to the original WebDataset as the dependency.
Without distributed training
We train the ResNet-50 on one single GPU first to get a baseline performance:
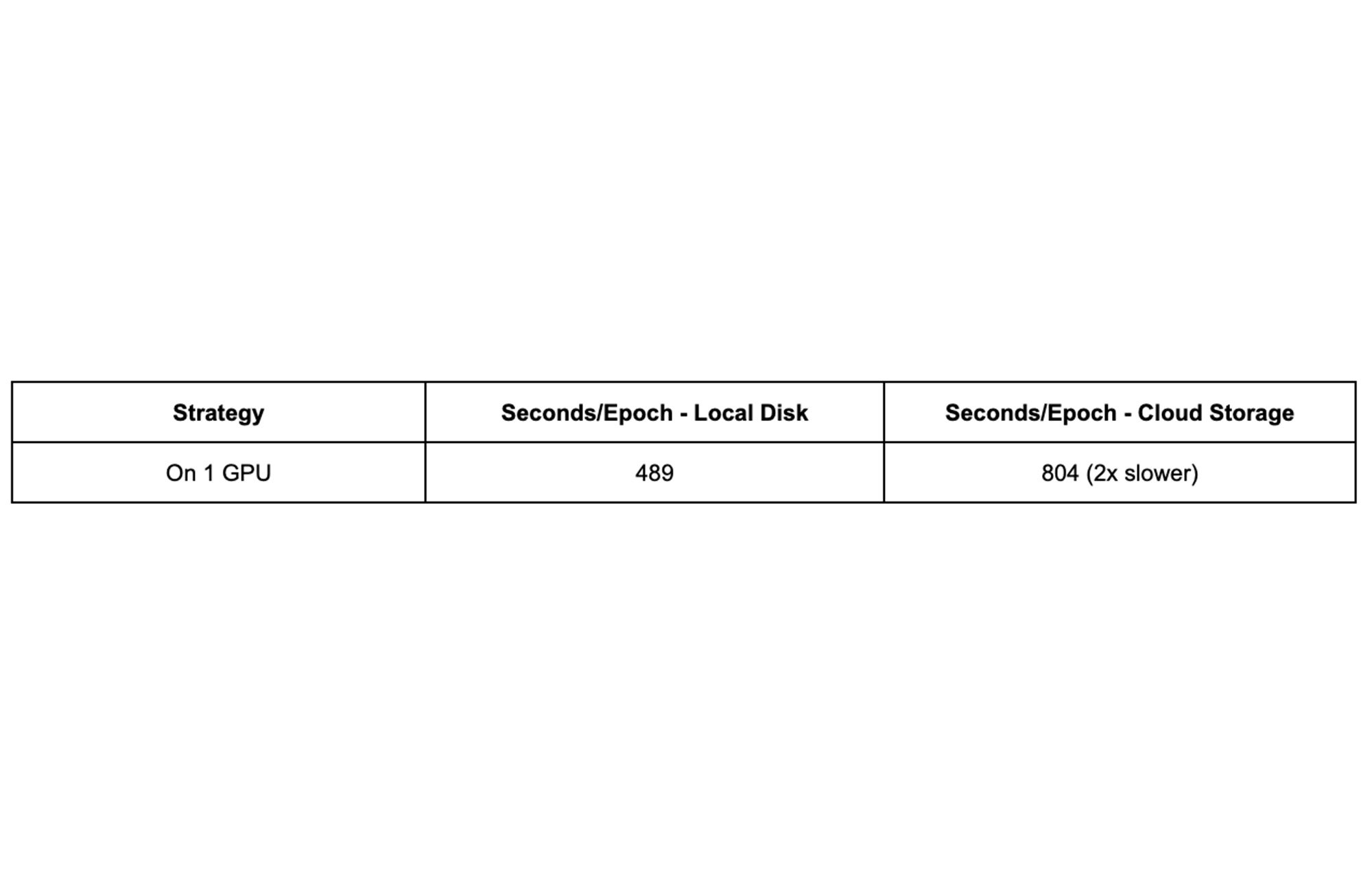
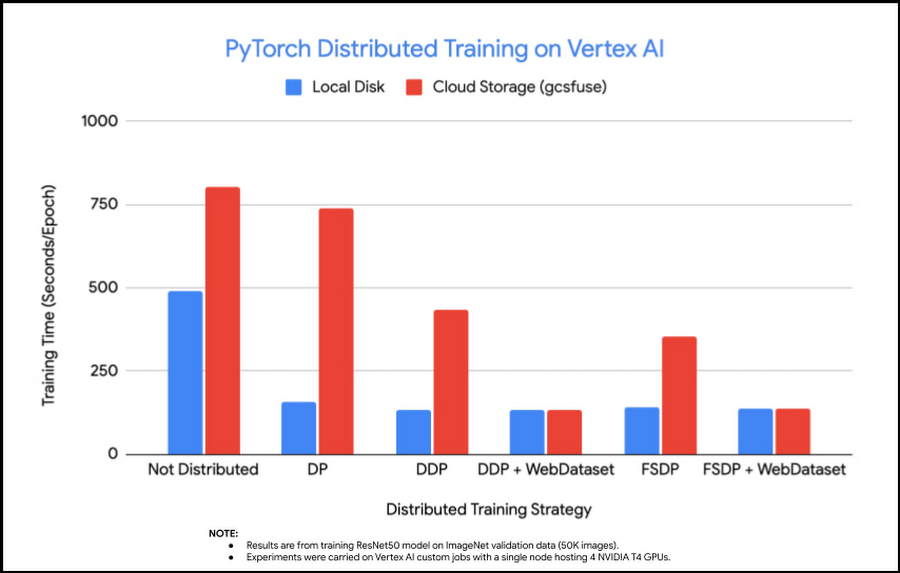
From the result we can see that, when training on one single GPU, using data on Cloud Storage takes about 2x the time of using a local disk. Keep this in mind, we will use multiple methods to improve the performance step by step.
DataParallel (DP)
The DataParallel strategy is the simplest method introduced by PyTorch to enable single-machine multiple-GPU training with the smallest code change. Actually as small as one line code change:
We train the ResNet-50 on single node with 4 GPUs using the DP strategy:

After applying DP on 4 GPUs, we can see that:
Training with data on the local disk gets 3x faster (from 489s to 157s).
Training with data on Cloud Storage gets faster a little bit (from 804s to 738s).
It’s apparent that the distributed training with data on Cloud Storage becomes an input bound training, waiting for data to be read due to network bottleneck.
DistributedDataParallel (DDP)
DistributedDataParallel is more sophisticated and powerful than DataParallel. It’s recommended to use DDP over DP, despite the added complexity, because DP is single-process multi-thread which suffers from Python GIL contention and DDP can fit more scenarios like multi-node and model-parallel. Here we experimented with DDP on a single node with 4 GPUs where each GPU is handled by an individual process.
We use the nccl backend to initialize the process group for DDP and construct the model:
We train the ResNet-50 on 4 GPUs using the DDP strategy and WebDataset:
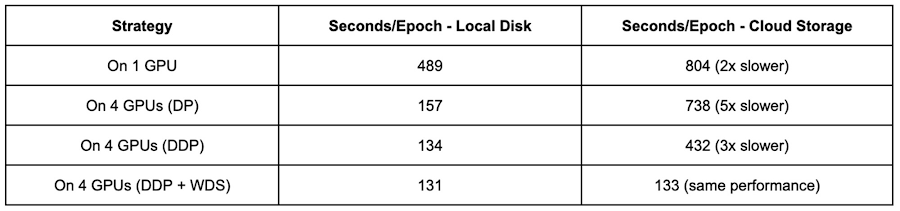
After enabling DDP on 4 GPUs, we can see that:
Training with data on the local disk gets further faster than DP (from 157s to 134s).
Training with data on Cloud Storage gets much better (from 738s to 432s), but it is 3x times slower than using a local disk.
Training with data on Cloud Storage gets a lot faster (from 432s to 133s) when using source files in WebDataset format, which is very close or as good as to the speed of training with data on the local disk.
The input bound problem is kind of relieved when using DDP, which is expected because there’s no Python GIL contention any more for reading data. And despite the addition of data preprocessing work, sharding data with WebDataset benefits the performance by removing the overhead of network communication. Finally, DDP and WebDataset improve training performance by 6x (from 804s to 133s) in comparison to without distributed training and individual smaller files.
FullyShardedDataParallel (FSDP)
FullyShardedDataParallel wraps model layers into FSDP units. It gathers full parameters before the forward and backward operations and runs reduce-scatter to synchronize gradients. It achieves lower peak memory usage than DDP with some configurations.
We train the ResNet-50 on 4 GPUs using the FSDP strategy and WebDataset:
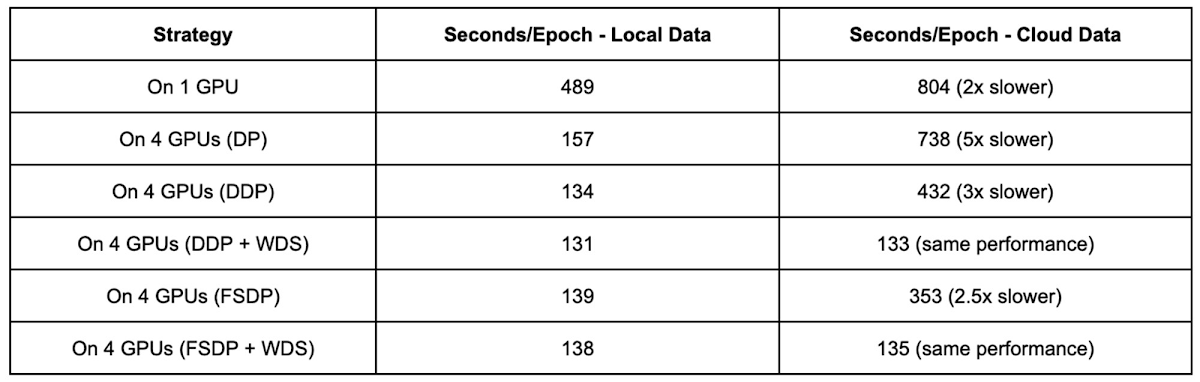
We can see that using FSDP achieves a similar training performance as DDP in this configuration on a single node with 4 GPUs.
Comparing performance across these different training strategies, with and without WebDataset format, we see an overall 6x performance improvement with data on Cloud Storage using WebDataset and choosing DistributedDataParallel or FullyShardedDataParallel distributed training strategies. The training performance with data on Cloud Storage is similar to when trained with data on a local disk.
Tracking with Vertex AI TensorBoard and Experiments
As you have seen so far, we carried out performance improvement trials step-by-step and it was necessary to run the experiments with several configurations and track the development and outcome. Vertex AI Experiments enable seamless experimentation along with tracking. You can track parameters, visualize and compare the performance metrics of your model and pipeline experiments.
You would use Vertex AI Python SDK to create an experiment, and log both parameters, metrics, and artifacts associated with experiment runs. The SDK provides a handy initialization method to create a TensorBoard instance using Vertex AI TensorBoard for logging model time series metrics. For example, we tracked training loss, validation accuracy and training run times for each epoch.
Below is the snippet to start an experiment, log model parameters, run the training job and track metrics at the end of the training session:
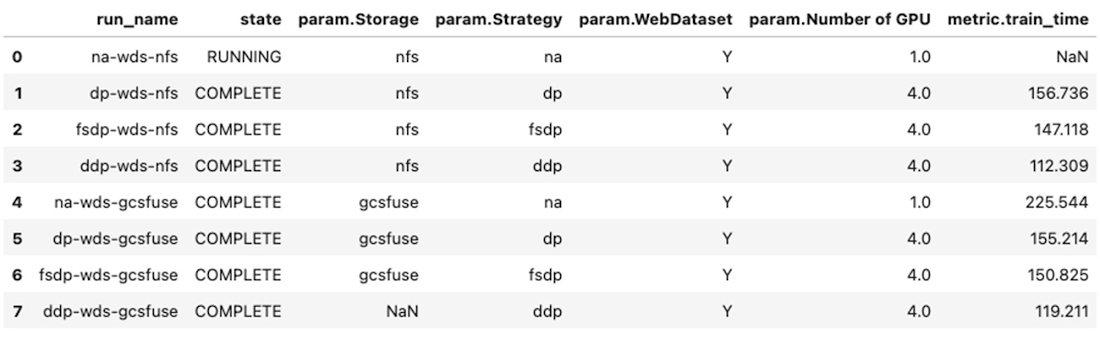
The SDK supports a handy get_experiment_df method to return experiment run information as a Pandas dataframe. Using this dataframe, we can now effectively compare performance between different experiment configurations:
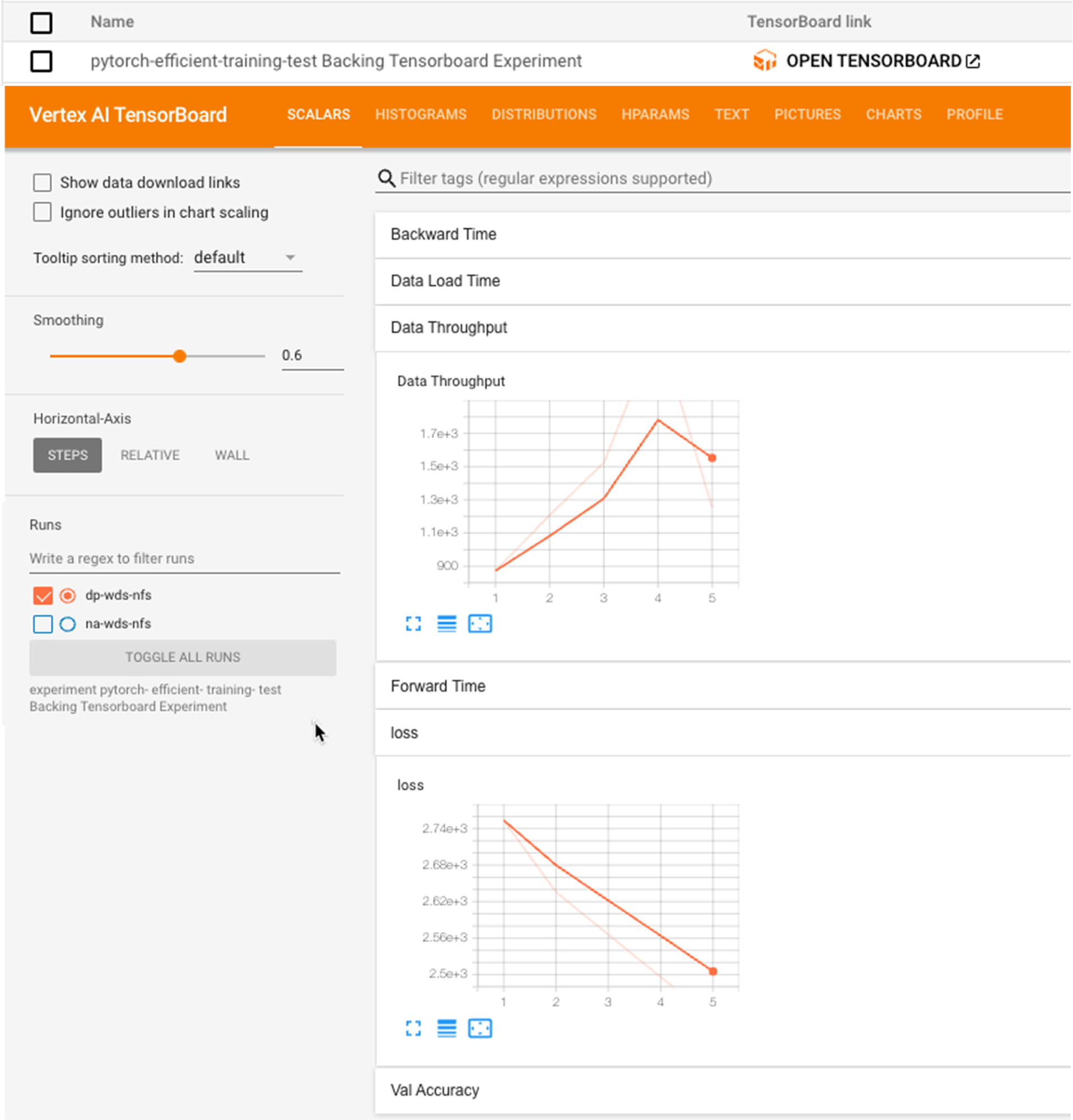
Since the experiment is backed with TensorBoard using Vertex AI TensorBoard, you can access TensorBoard from the console and do a deeper analysis. For the experiment, we modified training code to add TensorBoard scalars with metrics that we were interested in.
Conclusion
In this post, we demonstrated how PyTorch training could be input bound when data is read from Google Cloud Storage and showed approaches to improve performance by comparing distributed training strategies and introducing WebDataset format.
Use WebDataset to shard individual files which can improve sequential I/O performance by reducing network bottlenecks.
When training on multiple GPUs, choose
DistributedDataParallelorFullyShardedDataParalleldistributed training strategies for better performance.For large-scale datasets you cannot download to the local disk. Use
gcsfuseto simplify implementation of data access to Cloud Storage from Vertex AI and use WebDataset to shard individual files reducing network overhead.Vertex AI improves productivity when carrying out experiments while offering flexibility, security and control. Vertex AI Training custom jobs make it easy to run experiments with several training configurations, GPU shapes and machine specs. Combined with Vertex AI Experiments and Vertex AI TensorBoard, you can track parameters, visualize and compare the performance metrics of your model and pipeline experiments.
You can find the accompanying code for this blog post on this GitHub Repo.



