GKE Inference Gateway で Vertex AI のレイテンシを 35% 削減した方法
Fisayo Feyisetan
Product Manager
Yao Yuan
Software Engineer
※この投稿は米国時間 2026 年 2 月 7 日に、Google Cloud blog に投稿されたものの抄訳です。
生成 AI が試験運用から本番環境に移行するにつれて、プラットフォーム エンジニアは、低レイテンシ、高スループット、管理可能なコストの実現という、推論サービングに関する共通の課題に直面します。
バランスを取るのは簡単ではありません。トラフィック パターンは、大量のデータを処理する必要がある複雑なコーディング タスクから、即座の返信が求められるくだけた会話まで、多岐にわたります。標準的なインフラストラクチャでは多くの場合、両方を効率的に処理するのは簡単ではありません。
Google のソリューション: この問題を解決するため、Vertex AI エンジニアリング チームは GKE Inference Gateway を採用しました。標準の Kubernetes Gateway API をベースに構築された Inference Gateway は、2 つの重要なインテリジェンス レイヤを追加することで、スケーリングの問題を解決します。
-
負荷認識ルーティング: モデルサーバーの Prometheus エンドポイントからリアルタイムの指標(KV キャッシュ使用率など)を直接スクレイピングし、リクエストを最も迅速に処理できる Pod にルーティングします。
-
コンテンツ認識ルーティング: リクエストの接頭辞を検査し、そのコンテキストが KV キャッシュにすでに存在する Pod にリクエストをルーティングすることで、費用のかかる再コンピューティングを回避します。
Vertex AI は、本番環境のワークロードをこのアーキテクチャに移行することで、この二重型のインテリジェンスが大規模なパフォーマンスを実現する鍵であることを証明しています。
ここでは、Vertex AI によってサービング スタックがどのように最適化されたかについて説明し、これらのパターンを独自のプラットフォームに適用して厳格なテールレイテンシ保証を実現する方法、キャッシュ効率を最大化してトークンあたりのコストを削減する方法、カスタム スケジューラの構築に伴うエンジニアリング オーバーヘッドを排除する方法をご紹介します。
結果: 本番環境規模で実証済み
Vertex AI モデルサーバーの前に GKE Inference Gateway を配置することで、標準的なロード バランシング アプローチと比較して、速度と効率の両面で大きな成果を上げることができました。
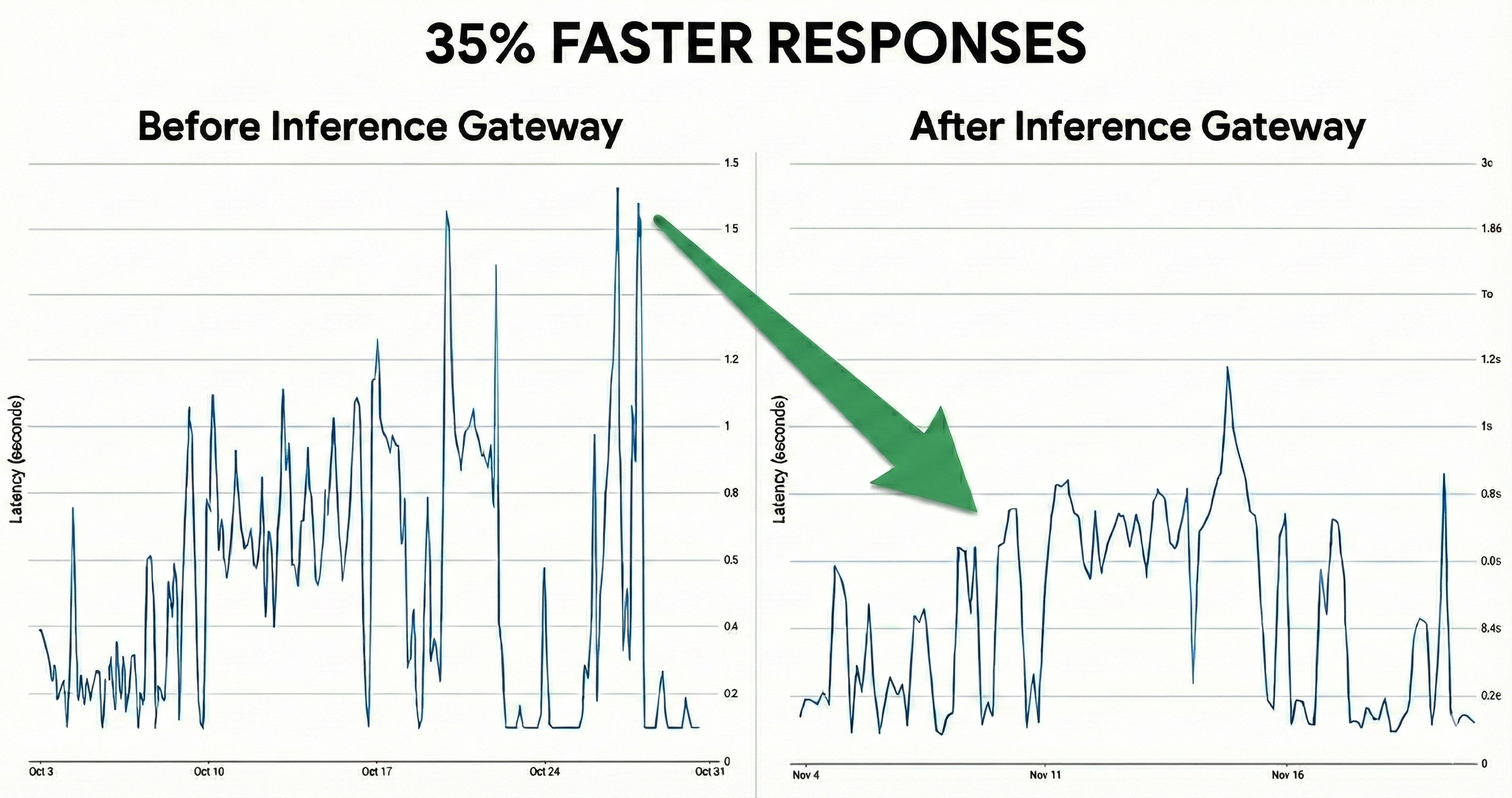
これらの結果は、コンテキストを多用するコーディング エージェントから高スループットの会話モデルまで、さまざまな AI ワークロードの本番環境トラフィックで実証されました。
-
レスポンス速度が 35% 向上: GKE Inference Gateway を使用することで、Vertex AI は Qwen3-Coder の最初のトークンまでの時間(TTFT)のレイテンシを 35% 以上短縮しました。
-
テール レイテンシが 2 分の 1 に改善: バースト性の高いチャット ワークロードの場合、Vertex AI は GKE Inference Gateway を使用することで、Deepseek V3.1 の最初のトークンまでの時間(TTFT)P95 レイテンシを 2 分の 1(52%)に改善しました。
-
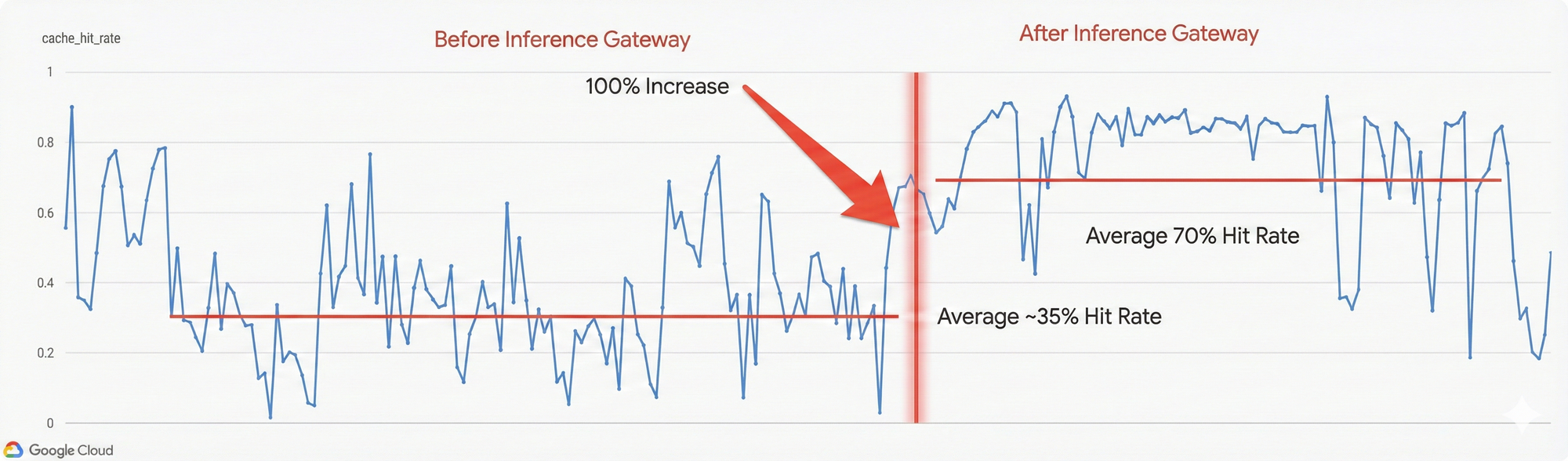
効率が 2 倍: ゲートウェイの接頭辞キャッシュ保存対応機能を活用することで、Vertex AI は GKE Inference Gateway を採用して接頭辞キャッシュ ヒット率を 2 倍(35% から 70%)にしました。
詳細: 高パフォーマンスなサービングのための 2 つのパターン
本番環境グレードの推論ルーターの構築は、AI トラフィックが単一のプロファイルではないため、見かけよりも複雑です。Vertex AI では、ワークロードが 2 つの異なるトラフィック パターンに分類され、それぞれに異なる最適化戦略が必要であることがわかりました。
-
コンテキストを多用するワークロード(コーディング エージェントなど): これらのリクエストには、持続的なコンピューティング負荷を生み出す大規模なコンテキスト ウィンドウ(コードベース全体の分析など)が含まれます。ここでボトルネックとなるのは、再コンピューティングのオーバーヘッドです。
-
バースト性の高いワークロード(例: チャット): これは、短いクエリの予測不可能で確率的な急増です。ここでボトルネックとなるのは、キューの輻輳です。
両方のトラフィック プロファイルを同時に処理するために、Vertex AI が GKE Inference Gateway を使用して解決した 2 つの具体的なエンジニアリング上の課題を以下に示します。
1. 多目的ロード バランシングのチューニング
標準的なラウンドロビン ロードバランサは、特定のプロンプトのキャッシュされた KV ペアをどの GPU が保持しているかを認識しません。これは、キャッシュミスが発生すると大量の入力を最初から再処理しなければならなくなる「コンテキストを多用する」ワークロードでは特に非効率的です。ただし、キャッシュ アフィニティのみを考慮したルーティングは危険な場合があります。全員が同じ人気のドキュメントをリクエストすると、1 つのノードが過負荷になり、他のノードはアイドル状態になります。
解決策: GKE Inference Gateway の多目的チューニングでは、競合するシグナルのバランスをとる構成可能なスコアラーを使用します。新しいチャットモデルのロールアウト中、Vertex チームは prefix:queue:kv-utilization の重みを調整しました。
比率をデフォルトの 3:3:2 から 3:5:2 に変更(キューの深さをわずかに優先)することで、キャッシュ ヒットが発生した場合でも、スケジューラが「ホット」ノードをバイパスするようにしました。この構成変更により、トラフィックの分散がすぐにスムーズになり、高い効率が維持されました。接頭辞キャッシュ ヒット率は 35% から 70% に倍増しました。
2. バースト性の高いトラフィックのキュー深度の管理
推論プラットフォームは、特に突然の同時バーストによる負荷の変動に対処するのが難しいことがよくあります。保護がないと、これらのリクエストによってモデルサーバーが飽和状態になり、リソースの競合が発生して、キュー内のすべてのユーザーに影響が及ぶ可能性があります。
解決策: これらのリクエストがモデルサーバーに直接到達するのを防ぐために、GKE Inference Gateway は、Ingress レイヤでアドミッション コントロールを適用します。キューを上流で管理することで、個々の Pod がリソース不足になるのを防ぐことができます。
データは価値を証明しています。レイテンシの中央値は安定したままですが、P95 レイテンシが 52% 改善されたことは、負荷が高いときに AI アプリケーションを悩ませることの多い分散をゲートウェイがうまく吸収したことを示しています。
プラットフォーム構築者にとっての意味
ここから得られる教訓は、スケジューラを再発明する必要はないということです。
カスタム インフラストラクチャを維持する代わりに、GKE Inference Gateway を使用できます。これにより、Google 社内のワークロードで実績のあるスケジューラにアクセスできるようになり、メンテナンスのオーバーヘッドなしで、飽和から確実に保護できます。
準備ができたら、GKE Inference Gateway をワークロード用に構成する方法をご確認ください。
- プロダクト マネージャー、Fisayo Feyisetan
- ソフトウェア エンジニア、Yao Yuan
