Google の事例: 130,000 ノードで構成される世界最大級の Kubernetes クラスタの構築
Besher Massri
Software Engineer
Maciek Różacki
Group Product Manager
※この投稿は米国時間 2025 年 11 月 22 日に、Google Cloud blog に投稿されたものの抄訳です。
Google Cloud では、ますます要求が厳しくなってきているワークロード、特に AI に対応できるように、Google Kubernetes Engine(GKE)のスケーラビリティを絶えず向上させています。GKE はすでに大規模な 65,000 ノードのクラスタをサポートしており、KubeCon では、130,000 ノードのクラスタを試験運用版モードで正常に稼働させたことを発表しました。これは、公式にサポートおよびテストされた上限の 2 倍のノード数にあたります。
このようなスケーリングは、単にノードの絶対数を増やすだけではありません。Pod の作成やスケジューリングのスループットなど、他の重要なディメンションもスケールする必要があります。たとえば、このテストでは、最適化された分散ストレージに 100 万を超えるオブジェクトを保存しながら、1,000 Pod / 秒のスループットを維持しました。このブログでは、こうしたメガクラスタの需要を牽引するトレンドを検証し、この極めて高いスケーラビリティを実現するために Google が実装したアーキテクチャのイノベーションについて詳しくご説明します。
メガクラスタの台頭
Google の大手企業のお客様は、AI ワークロードを通じて GKE のスケーラビリティとパフォーマンスの限界を積極的に押し広げています。実際、2 万~6 万 5,000 ノードの範囲でクラスタを運用しているお客様はすでに多数いらっしゃいます。また、大規模クラスタの需要は 10 万ノード前後で安定すると予想されます。
これは興味深いダイナミクスを生み出します。つまり、チップの供給が制約となる世界から、電力の供給が制約となる世界へと移行しつつあるのです。NVIDIA GB200 GPU 1 個あたり 2,700 W の電力を必要とすることを考えてみてください。チップが数万個、あるいはそれ以上搭載される場合、単一クラスタの電力消費量は数百メガワットにまで容易にスケールする可能性があります。この場合、複数のデータセンターに分散されるのが理想的です。したがって、10 万ノードを超える AI プラットフォームでは、クラスタやデータセンター全体で分散トレーニングや強化学習をオーケストレートできる、堅牢なマルチクラスタ ソリューションが必要になります。この大きな課題に対処するため、Google は MultiKueue などのツールに積極的に投資しており、さらなるイノベーションを視野に入れています。また、最近発表されたマネージド DRANET により高性能 RDMA ネットワーキングも進化しており、大規模 AI ワークロードのパフォーマンスを最大化するため、トポロジ認識を向上させています。今後の情報にご注目ください。
同時に、こうした投資は、GKE のお客様の大多数を占める、より小規模な運用を行うユーザーにもメリットをもたらします。GKE のコアシステムを過酷な使用環境に耐えられるように強化することで、平均的なクラスタに十分な余裕が生まれ、エラーに対する耐性が向上し、ユーザーによる Kubernetes API の誤用に対する許容度が高まり、一般にすべてのコントローラが最適化されてパフォーマンスが向上します。そしてもちろん、規模の大小を問わず、すべての GKE のお客様が、直感的なセルフサービス エクスペリエンスへの投資から恩恵を受けることができます。
主なアーキテクチャのイノベーション
とはいえ、このレベルのスケールを実現するには、コントロール プレーン、カスタム スケジューリング、ストレージなど、Kubernetes エコシステム全体にわたる大きなイノベーションが必要です。このプロジェクトにおいて重要であった主な領域をいくつか見てみましょう。
読み取りのスケーラビリティの最適化
大規模な運用においては、強整合性と、スナップショット可能な API サーバーのウォッチ キャッシュが必要になります。ノード数が 130,000 になると、API サーバーへの読み取りリクエストの量が膨大になり、中央のオブジェクト データストアが圧倒される可能性があります。これを解決するために、Kubernetes には、これらの読み取りリクエストを中央のオブジェクト データストアからオフロードする複数の補完的な機能が組み込まれています。
まず、こちらで詳しく説明されている「キャッシュからの整合性のある読み取り機能」(KEP-2340)により、API サーバーがそのメモリ内キャッシュから直接、強整合性のあるデータを提供できるようになります。これにより、フィルタされたリスト リクエスト(例: 「特定のノード上のすべての Pod」)などの一般的な読み取りパターンにおいて、オブジェクト ストレージ データベースへの負荷が大幅に軽減されます。これは、リクエストを処理する前にキャッシュのデータが検証可能な最新状態であることを保証することで実現されます。
これを基盤にして、スナップショット可能な API サーバー キャッシュ機能(KEP-4988)では、API サーバーが以前の状態に対する LIST リクエスト(ページネーション経由または resourceVersion の指定による)を、同じ整合性のあるウォッチ キャッシュから直接処理できるようにすることで、パフォーマンスをさらに向上させています。特定のリソース バージョンでキャッシュの B-tree「スナップショット」を生成することにより、API サーバーはデータストアに繰り返しクエリを実行することなく、後続の LIST リクエストを効率的に処理できます。
これら 2 つの機能強化を組み合わせることで、読み取り増幅の問題に対処し、強整合性のあるフィルタされた読み取りと以前の状態のリスト リクエストの両方をメモリから直接提供することで、API サーバーの高速性と応答性を維持できるようにします。これは、極めて大規模な環境においてクラスタ全体のコンポーネントの健全性を維持するために不可欠です。
最適化された分散ストレージ バックエンド
クラスタの大規模なスケールを支えるため、Google の分散データベース「Spanner」に基づく独自の Key-Value ストアを採用しました。13 万ノードでは、リース オブジェクトの更新に 13,000 QPS が必要でした。そのため、ノードのヘルスチェックなどの重要なクラスタ オペレーションがボトルネックにならず、システム全体が確実に動作するために必要な安定性が確保されました。新しいストレージ システムではボトルネックは発生せず、より大規模なスケールをサポートできない兆候もありませんでした。
高度なジョブ キューイングのための Kueue
デフォルトの Kubernetes スケジューラは個々の Pod をスケジュールするように設計されていますが、複雑な AI / ML 環境では、より高度なジョブレベルの管理が必要になります。Kueue は、Kubernetes にバッチシステム機能を提供するジョブ キューイング コントローラです。公正な共有ポリシー、優先度、リソース割り当てに基づいてジョブを承諾するタイミングを決定し、ジョブ全体に対して「オール オア ナッシング」のスケジューリングを可能にします。デフォルトのスケジューラをベースに構築された Kueue は、ベンチマークにおいて競合するトレーニング、バッチ、推論ワークロードの複雑な組み合わせを管理するために必要なオーケストレーションを提供しました。
スケジューリングの未来: ワークロード認識の強化
Kueue のジョブレベルのキューイング以外にも、Kubernetes エコシステムは、そのコアにおいてワークロードを考慮したスケジューリングへと進化しています。目標は、スケジューリングにおいて Pod 中心のアプローチからワークロード中心のアプローチに移行することです。つまり、スケジューラが利用可能な容量と潜在的な容量の両方を含めて、ワークロード全体のニーズを単一のユニットとして考慮して配置を決定します。この包括的な視点は、特に新たな AI / ML トレーニングと推論ワークロードにおいて費用対効果を最適化するために不可欠です。
新たに登場した Kubernetes スケジューラの重要な側面の一つが、Kubernetes 内でのギャング スケジューリング セマンティクスのネイティブな実装です。この機能は現在、Kueue などのアドオンによって提供されています。コミュニティは、KEP-4671: ギャング スケジューリングを通じてこの問題に積極的に取り組んでいます。
将来的には、コア Kubernetes でワークロードを考慮したスケジューリングがサポートされるようになり、GKE での大規模かつ緊密な結合アプリケーションのオーケストレーションが簡素化され、要求の厳しい AI / ML および HPC のユースケースに対応するプラットフォームがさらに強化されます。また、GKE 内で Kueue を二次レベルのスケジューラとして統合する取り組みも進めています。
データアクセス向け GCS FUSE
AI ワークロードは、データに効率的にアクセスできる必要があります。並列ダウンロードとキャッシュを有効化した Cloud Storage FUSE と、ゾーン単位の Anywhere Cache を組み合わせることで、Cloud Storage バケット内のモデルデータにローカル ファイル システムと同様にアクセスできるようになり、レイテンシが最大 70% 削減されます。これにより、分散ジョブやスケールアウト推論ワークフローにデータを供給するための、スケーラブルで高スループットのメカニズムが提供されます。あるいは、Google Cloud Managed Lustre という選択肢もあります。これは、フルマネージドの永続的なゾーン ストレージ ソリューションであり、数ペタバイトの容量、TB / 秒単位のスループット、ミリ秒未満のレイテンシを必要とするワークロードをサポートします。AI / ML ワークロード向けのストレージ オプションについて詳しくは、こちらをご覧ください。
大規模かつ動的な AI ワークロード向け GKE のベンチマーク
大規模な AI / ML ワークロードにおける GKE のパフォーマンスを検証するため、複雑なリソース管理や優先順位付け、スケジューリングの課題を伴う動的環境をシミュレートする、4 つのフェーズからなるベンチマークを設計しました。これは、前回の 65,000 ノードのスケールテストで使用されたベンチマークに基づいて構築されています。
ベンチマークをアップグレードして優先度クラスが異なるワークロードを使用することで、混合ワークロードをホストする一般的な AI プラットフォームを表すようにしました。
-
低い優先度: データ準備ジョブなどのプリエンプティブルなバッチ処理。
-
中程度の優先度: 重要ではあるが多少のキューイングは許容されるコアモデルのトレーニング ジョブ。
-
高い優先度: リソースが保証される必要がある、レイテンシの影響を受けやすいユーザー向けの推論サービス。
割り当てとリソース共有を管理する Kueue と、トレーニング ジョブを管理する JobSet を使用して、プロセスをオーケストレートしました。
フェーズ 1: 大規模なトレーニング ジョブによるパフォーマンスのベースラインの確立
まず、単一の大規模なトレーニング ワークロードをスケジュールし、クラスタの基本的なパフォーマンスを測定します。130,000 個の中優先度の Pod を同時に実行するように構成された JobSet を 1 つデプロイします。この初期テストでは、Pod の起動レイテンシや全体的なスケジューリング スループットなどの主要な指標のベースラインを確立し、クリーンなクラスタ上で大規模なワークロードを起動する際のオーバーヘッドを明らかにします。これにより、より複雑な条件下における GKE のパフォーマンスを評価する準備が整いました。実行後、この JobSet をクラスタから削除し、フェーズ 2 用に空のクラスタを残しました。

図 1: フェーズ 1: クリーンなクラスタ上に 130,000 個の Pod からなる大規模な事前トレーニング ワークロードをデプロイしてパフォーマンスのベースラインを確立する。
フェーズ 2: 現実的な混合ワークロード環境のシミュレーション
次に、一般的な MLOps 環境をシミュレートするために、リソースの競合を導入しました。まず、650 個の低い優先度のバッチジョブ(合計 65,000 個の Pod)をデプロイし、クラスタの 130,000 個のノードの容量の半分を埋めました。
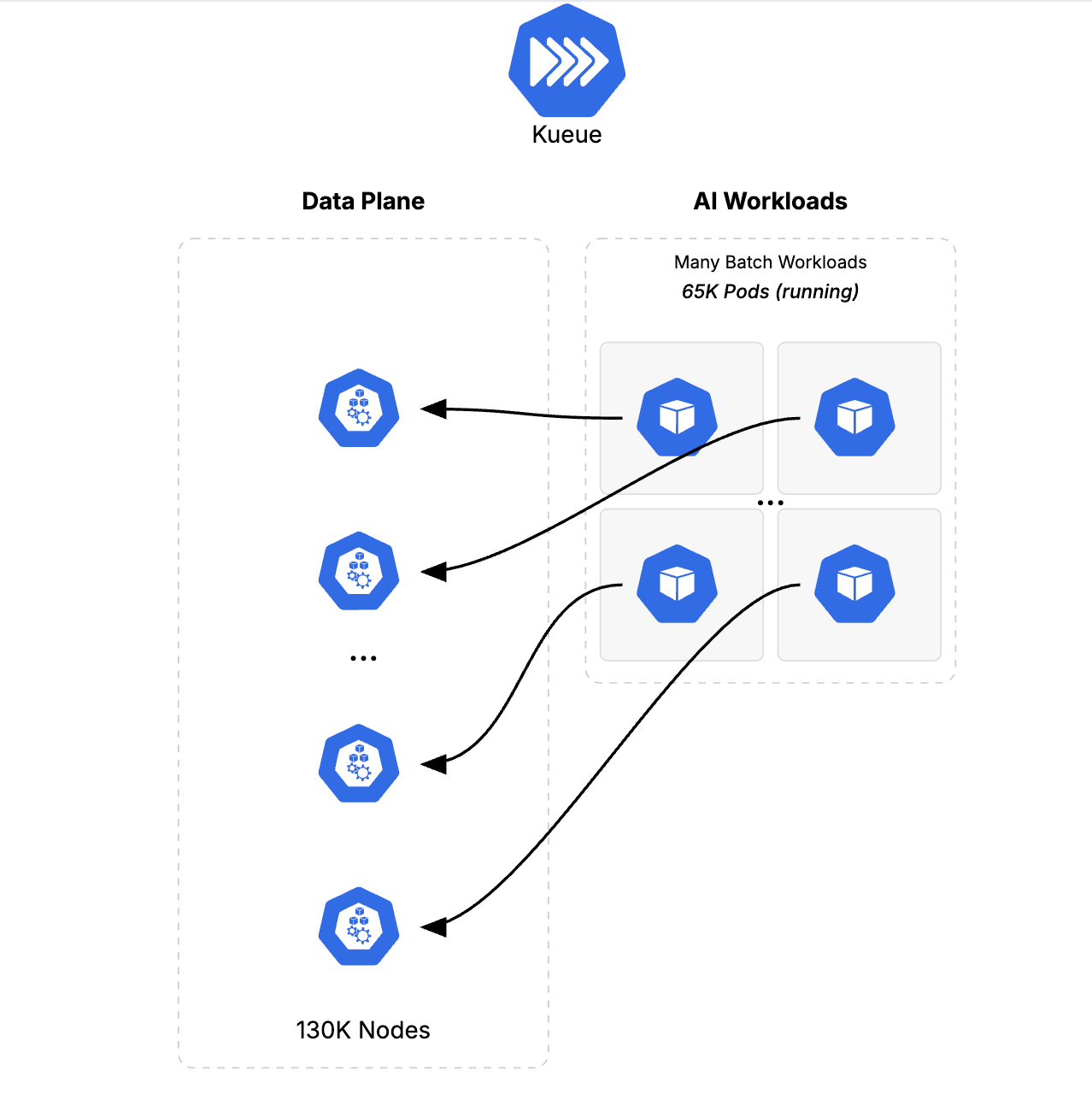
図 2: フェーズ 2: 65,000 個の低い優先度のバッチジョブ Pod を導入してクラスタ容量の 50% を埋め、現実的な MLOps 環境をシミュレートする。
次に、8 つの大規模な中優先度のファインチューニング ジョブ(合計 104,000 個の Pod)を導入し、クラスタ容量の 80% を占有して、バッチ ワークロードの 60%(クラスタ容量全体の 30% に相当)をプリエンプトしました。このフェーズでは、GKE が混合ワークロードを管理する能力と、混合ワークロード環境内でのプリエンプションをテストしました。このシナリオでは、Kueue が実際に動作して既存のワークロードをプリエンプトし、多数のバッチジョブを一度にギャング スケジューリングすることで、ファインチューニング ジョブをスケジュールできるようにする様子を確認しました。これにより、Kueue が kube-scheduler よりも優れている点が明らかになりました。プリエンプションがはるかに高速になり、ワークロードの切り替えがほぼ瞬時に行われます。

図 3: Kueue の動作: 優先度の高いファインチューニング ジョブ用に 104,000 個の Pod を確保するため、優先度の低いバッチ ワークロードをプリエンプトする。
フェーズ 3: レイテンシの影響を受けやすい推論サービスの優先順位付けとスケーリング
このフェーズでは、優先度の高いジョブをデプロイすることで、合計 26,000 個の Pod(容量の 20%)で重要な推論サービスの導入をシミュレートしました。これに対応するため、Kueue は残りの優先度の低いバッチジョブをプリエンプトしました。

図 4: フェーズ 3: 優先度の低いバッチジョブの残りをプリエンプトすることで、レイテンシの影響を受けやすい重要な推論サービス(26,000 個の Pod)を優先する。
次に、推論ワークロードをスケーリングしてトラフィックの急増をシミュレートし、まず中優先度のファインチューニング ジョブの一部をプリエンプトしました。推論ワークロードは、合計 52,000 個の Pod(容量の 40% に相当)にスケールアップされます。完全にスケールした後、10 分間のトラフィック シミュレーションを実行し、負荷がかかった状態でのパフォーマンスを測定しました。

図 5: トラフィックの急増をシミュレートする。推論ワークロードを 52,000 個の Pod(容量の 40%)にスケーリングすると、ファインチューニング ジョブの部分的なプリエンプションがトリガーされる。
フェーズ 4: クラスタの弾力性とリソースの回復の検証
最後に、ピーク需要がすぎた後、クラスタがリソースを効率的に回復して再割り当てする能力を評価しました。優先度の高い推論ワークロードを 50% スケールダウンし、元の初期フェーズに戻しました。これにより GKE の弾力性が実証され、ワークロードの需要が変化しても貴重なコンピューティング リソースがアイドル状態にならないことが保証されたため、使用率と費用対効果が最大化されました。ここでも、Kueue がクラスタキューで待機していたプリエンプトされたファインチューニング ワークロードの再承諾を処理しました。
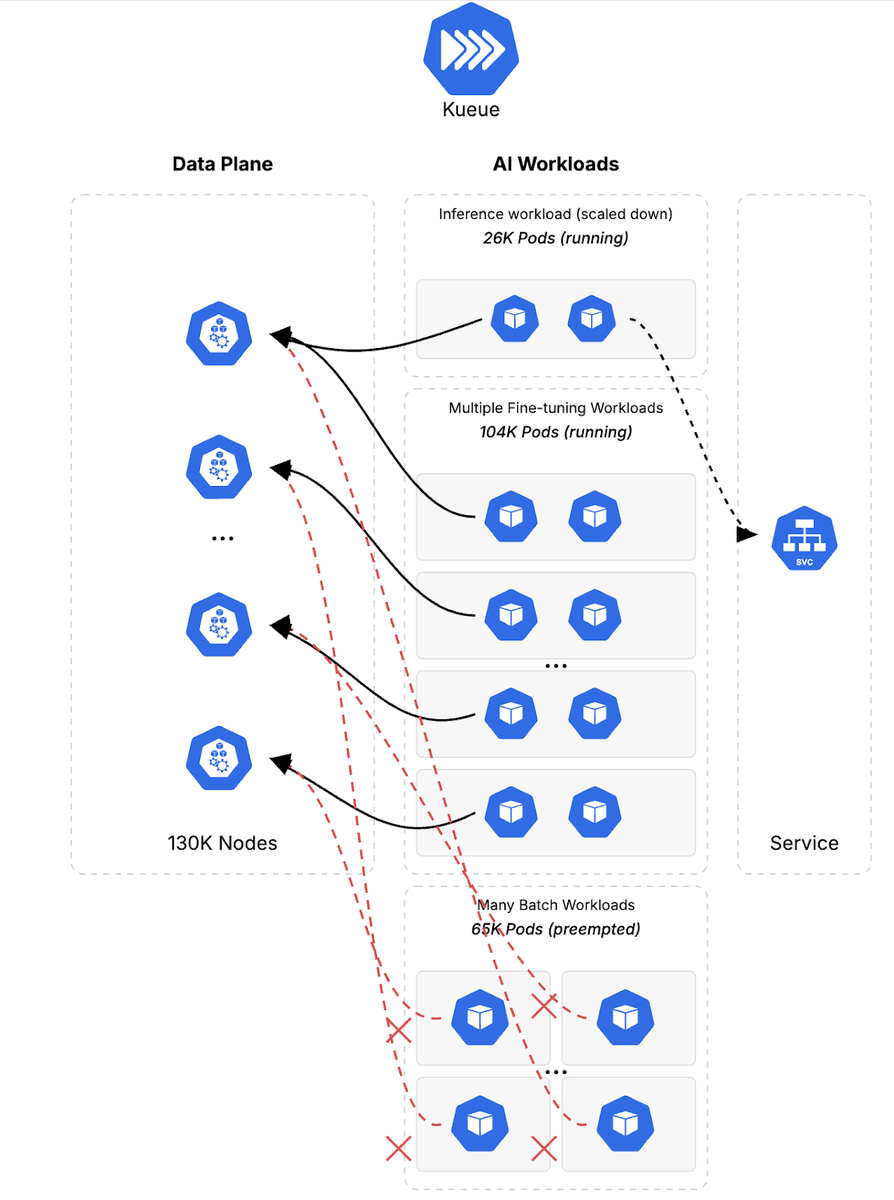
図 6: フェーズ 4: 推論ワークロードをスケールダウンし、保留中のファインチューニング ジョブのリソースを自動的に回復することで、クラスタの弾力性を実証する。
ベンチマークが完了して得られたデータから、GKE が極端なスケールのプレッシャーをどのように処理するかが明確に示されました。
GKE のさまざまな側面にわたるスケーラビリティの実証
4 つのベンチマーク フェーズで、複数のパフォーマンスの項目をテストしました。フェーズ 1 では、クラスタは 3 分 40 秒で 130,000 個の Pod にスケールされました。フェーズ 2 では、優先度の低いバッチ ワークロードが 81 秒で作成され、平均スループットは約 750 Pod / 秒でした。
ベンチマークのさまざまなフェーズが強調表示されたワークロードの実行タイムラインの図を以下に示します。

図 7: 大規模 AI ワークロード ベンチマークの 4 つの異なるフェーズが強調表示された実行タイムライン。
全体として、ベンチマークでは、優先度の低いジョブをプリエンプトして重要なトレーニング サービスと推論サービスのためのスペースを確保することで、変動する需要を管理する GKE の能力が実証され、クラスタの弾力性とリソースの再割り当ての能力が示されました。

図 8: 実行中のワークロード Pod の総数の推移。動的なプリエンプションとリソースの再割り当てを通じて GKE が高い使用率を維持できることを示している。
Kueue によるインテリジェントなワークロード管理
このベンチマークでは、Kueue はワークロードの優先順位付けを可能にする重要なコンポーネントでした。フェーズ 2 では、Kueue はバッチ ワークロードの 60%(クラスタ容量の 30%)をプリエンプトして、中優先度のジョブのスペースを確保しました。残りはフェーズ 3 でプリエンプトされ、優先度の高い推論ワークロードのスペースが確保されました。緊急タスクが優先されるこのシミュレーションは一般的な運用シナリオであり、この大規模なプリエンプションは、GKE と Kueue の組み合わせによって、最も重要なジョブにリソースを動的に割り当てられることを示しています。フェーズ 2 のピーク時には、93 秒で 39,000 個の Pod がプリエンプトされました。バッチ ワークロードのプリエンプションと、ファインチューニング ワークロードの承諾および作成中の Pod のチャーンは、以下のように、中央値が 990 Pod / 秒、平均が 745 Pod / 秒に達しました。
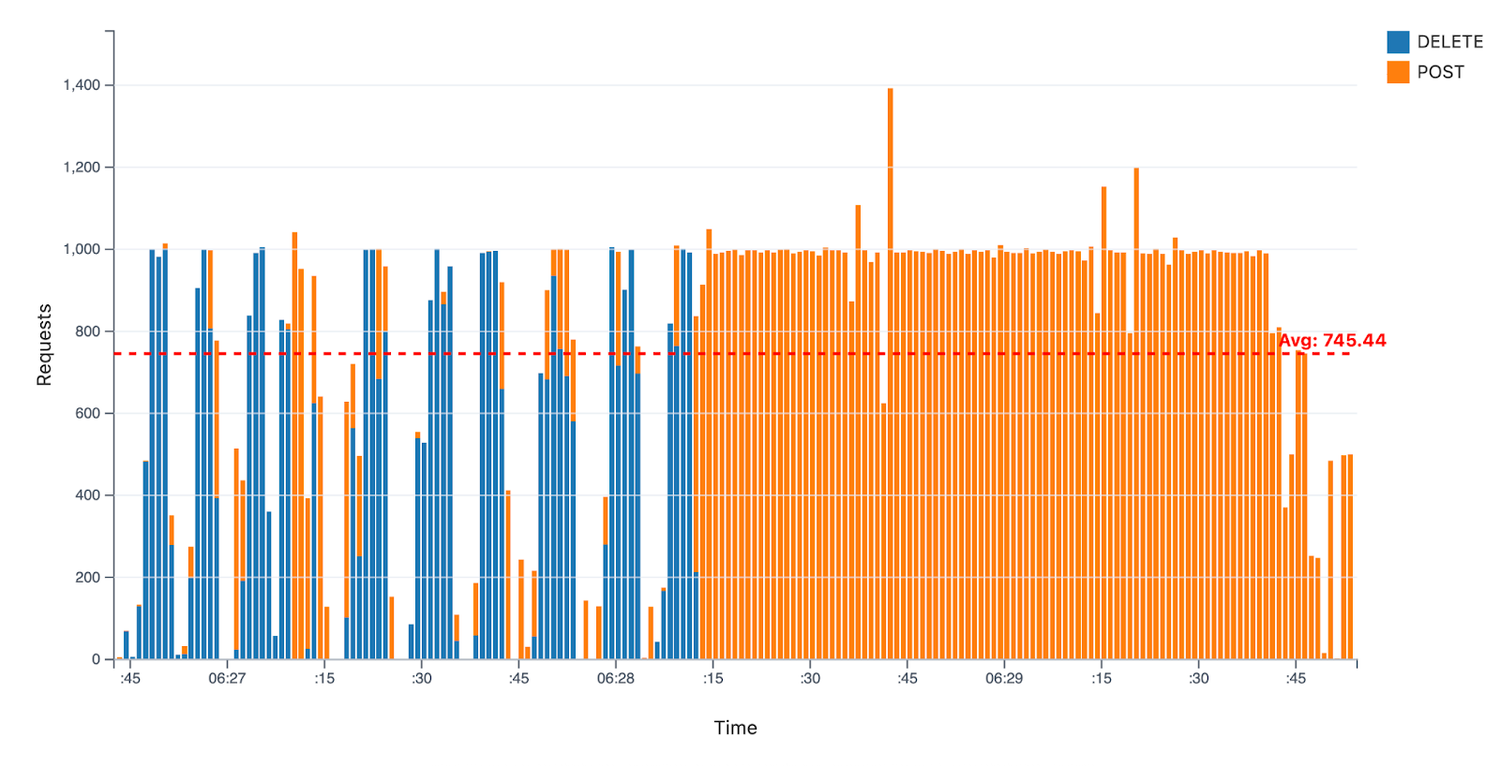
図 9: プリエンプション イベント中の API リクエスト スループット。POST リクエストと DELETE リクエストが混在しており、Pod のチャーンは平均 745 Pod / 秒。
Kueue からの承諾済みワークロードと削除済みワークロードのステータスを確認すると、多くのバッチ ワークロードが最初は承諾されたものの、その後ファインチューニングと推論ワークロードによってプリエンプトされたことがわかります。
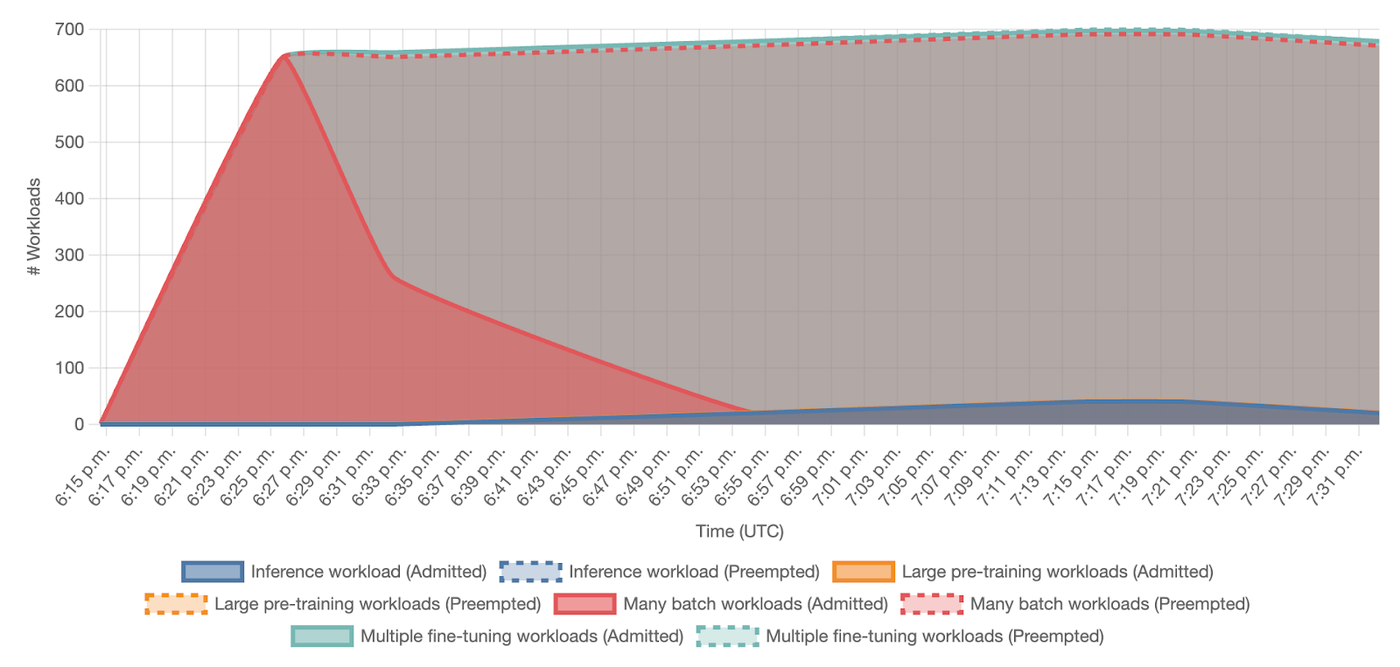
図 10: ワークロードのステータスの推移。優先度の変化に伴い、Kueue によって受け入れられたジョブ数とプリエンプト(削除)されたジョブ数を可視化している。
1,000 Pod / 秒の超高速スケジューリング
Kubernetes のコントロール プレーンのパフォーマンスを測る重要な指標は、Pod を迅速に作成してスケジュールする能力です。ベンチマーク全体を通して、特に最も負荷の高いフェーズでは、GKE は Pod の作成と Pod のバインディング(Pod をノードにスケジュールする行為)の両方で、最大 1,000 オペレーション / 秒のスループットを安定して達成しました。

図 11: コントロール プレーンのスループット: スケジューリングが集中するフェーズで、Pod の作成と Pod のバインディングの両方で最大 1,000 オペレーション / 秒を維持する。

図 12: 大規模な事前トレーニング、バッチ、ファインチューニングのワークロードにおける、Pod 作成のスループットに関する詳細な統計情報(平均、最大、P50、P90、P99)。
Pod の低い起動レイテンシ
同時に、Pod 作成のスループットは、あらゆるワークロード タイプにおいて Pod の低い起動レイテンシと一致していました。レイテンシの影響を受けやすい推論ワークロードの場合、99 パーセンタイル(P99)の起動時間は約 10 秒で、需要に応じてサービスを迅速にスケールできることが保証されています。
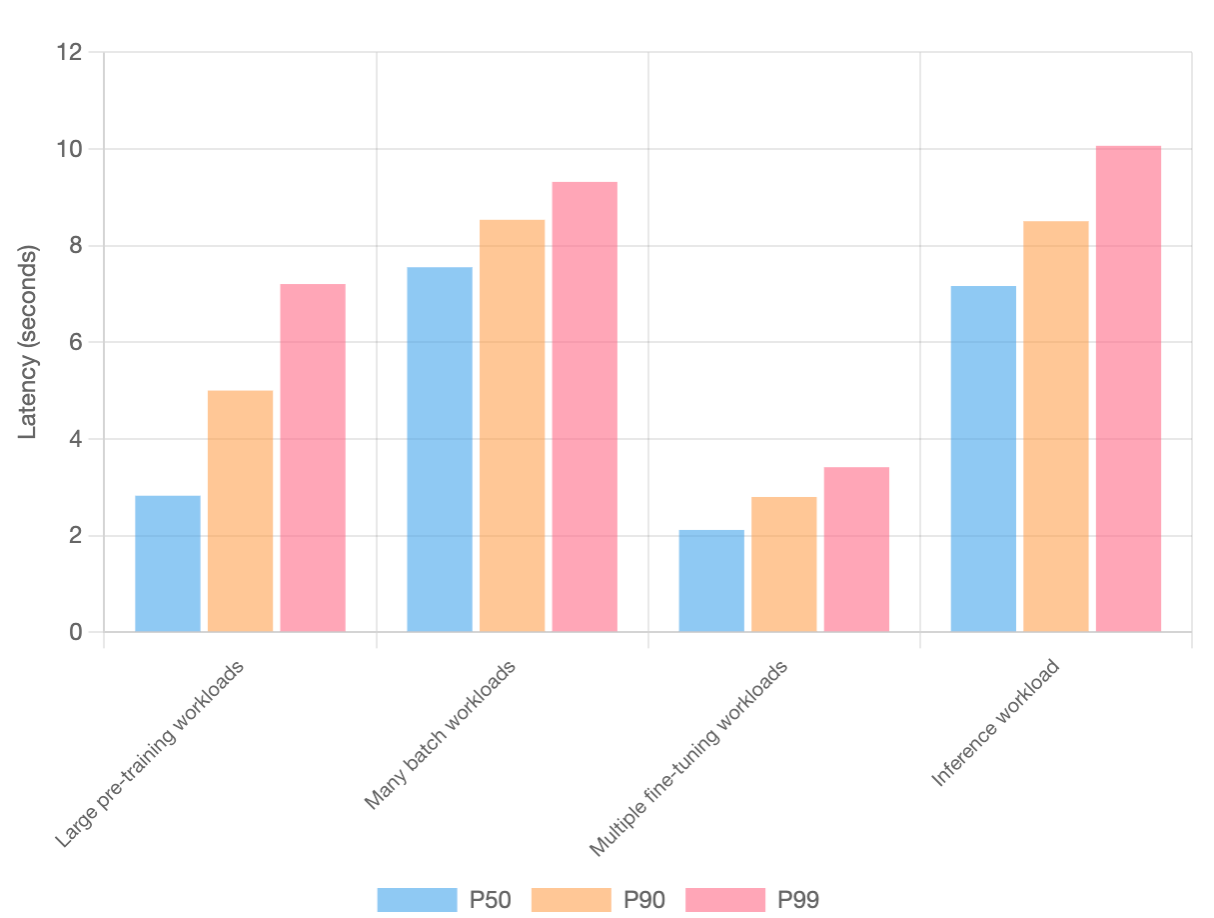
図 13: ワークロード タイプ別の Pod の起動レイテンシ。
極端な負荷下におけるコントロール プレーンの安定性
テスト全体を通して、GKE のクラスタ コントロール プレーンは安定していました。単一のデータベース レプリカ内のオブジェクトの合計数はピーク時に 100 万を超えましたが、重要なオペレーションにおける API サーバーのレイテンシは、定義されたしきい値を大幅に下回っていました。これにより、この規模であってもクラスタが応答性と管理性を維持できることが確認されました。
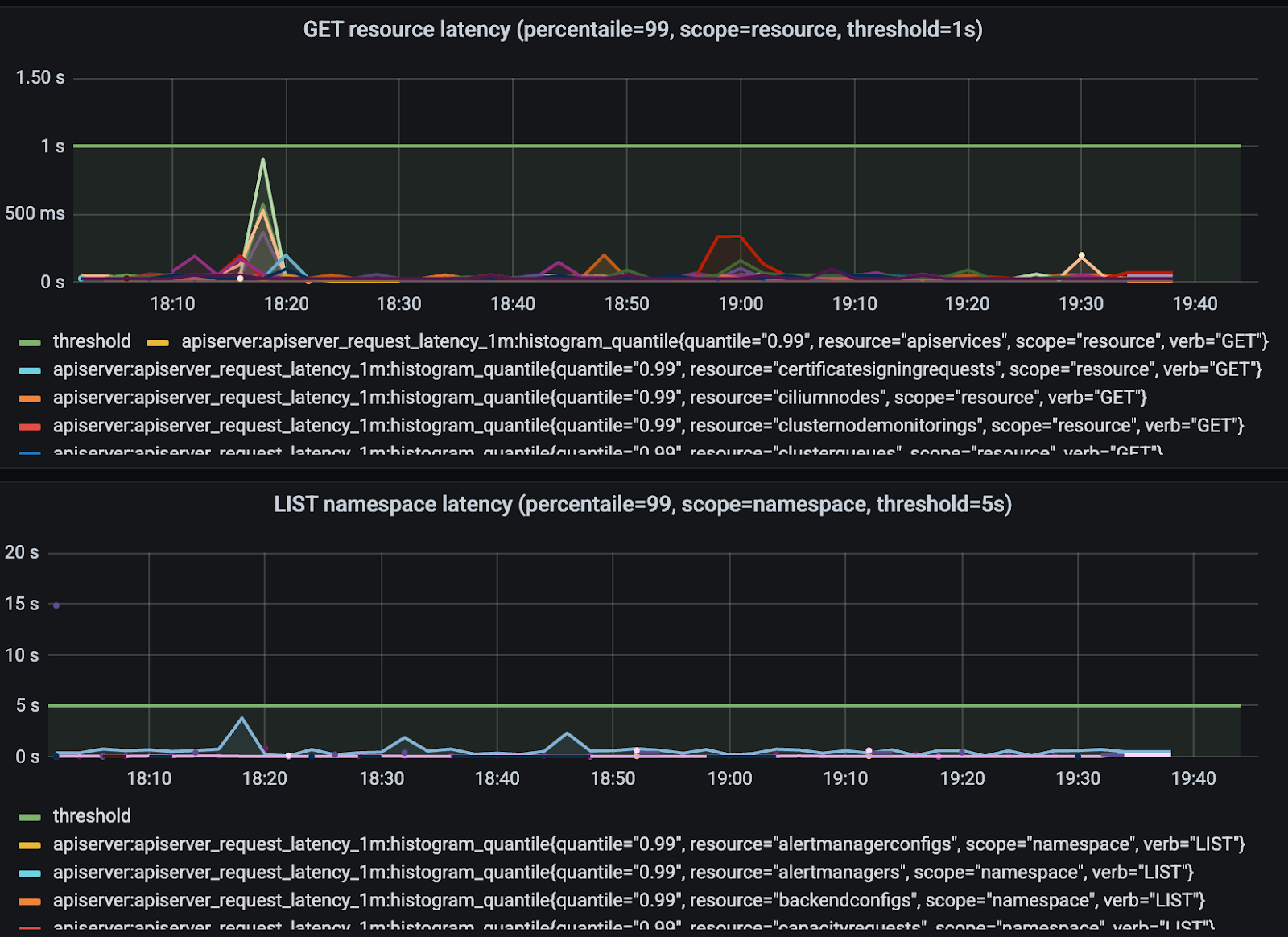
図 14: GET オペレーションと LIST オペレーションにおける API サーバーのレイテンシ。クラスタが大規模であるにもかかわらず、定義されたしきい値を大幅に下回り、安定している。
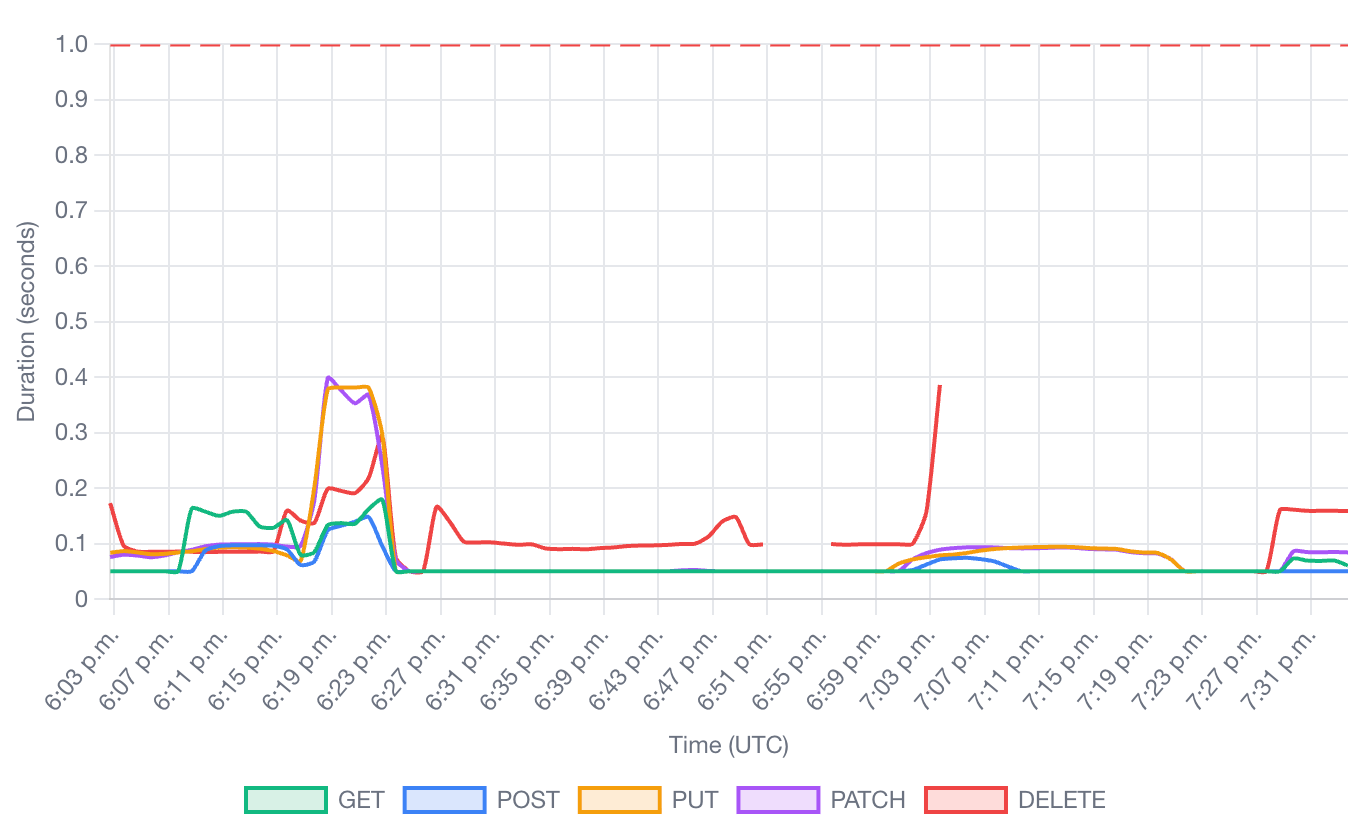
図 15: 動詞(GET、POST、PUT、PATCH、DELETE)別に分類された API リクエストの所要時間。負荷下でも応答時間が一定であることが確認できる。

図 16: LIST オペレーションの所要時間。ベンチマークのフェーズ全体で安定している。

図 17: データベース内の Kubernetes オブジェクト(Pod、Lease、Node を含む)の総数。100 万個を超えている。
リンク先: 大規模なスケール
この実験では、GKE が現在のパブリック制限をはるかに超える規模で AI および ML ワークロードをサポートできることが実証されました。さらに、この規模で運用したことで得られた分析情報は、GKE の今後の開発計画に役立っています。13 万ノードはまだ正式にはサポートされていませんが、非常に心強い調査結果が得られました。ワークロードでこのレベルのスケールが必要な場合は、Google にお問い合わせのうえ、具体的なニーズについてご相談ください。また、アトランタで開催された KubeCon では、Google のスペシャリストやアナリストが、スケーリングやその他のトピックに関する素晴らしい対談を行いました。こちらからぜひご覧ください。
-ソフトウェア エンジニア Besher Massri
-グループ プロダクト マネージャー Maciek Różacki
