Digitec Galaxus は、いかにして強化学習と Google Cloud によってパーソナライズされたニュースレターを配信しているのか
Google Cloud Japan Team
※この投稿は米国時間 2021 年 8 月 4 日に、Google Cloud blog に投稿されたものの抄訳です。
Digitec Galaxus AG はスイス国内で最大のオンライン小売業者であり、家庭用電化製品とメディア製品を取り扱うスイスの大手オンライン マーケットである Digitec と、ほぼすべての日用品を一貫した低価格帯で販売し、日々取り扱い製品を拡大し続けているスイス最大のオンライン ショップである Galaxus の 2 つのオンライン ショップを運営しています。
優れた効率性とパーソナライズされたショッピング体験によって認知されている Digitec Galaxus が、買い物客の興味を引く適切な商品を常に提示するプラットフォームを実現するために何が必要であるかを理解していることは明白です。
問題: あらゆる状況で決定をパーソナライズする
Digitec Galaxus は、買い物客が Google Cloud にアクセスしたときのエクスペリエンスをパーソナライズするためのエンジンを構築していました。同社は複数のレコメンデーション システムを活用しており、Recommendations AI を大規模に導入するアーリー アドプターでもありました。これによって、すでにホームページ、プロダクトの詳細ページ、ニュースレターなどにパーソナライズされたコンテンツを提供できる状態でした。
しかし同時に、それら複数のシステムをどのように組み合わせて最適化すれば、最大限にパーソナライズしたエクスペリエンスを買い物客に提供できるのかを理解するのが困難な場面もありました。同社の要件は次の 3 つでした。
パーソナライズ: 同社は 12 種類以上のレコメンデーション機能をアプリ上に表示できましたが、コンテキストに基づいてユーザーごとに異なるレコメンデーション機能を選択し、異なる商品を表示できるようにしたいと考えていました。さらに、既存のトレンド機能を活用するとともに、新たなトレンド機能を試すことも検討していました。
レイテンシ: 同社はソリューションを構築し、レコメンデーション機能のランキング リストを 50 サブミリ秒のレイテンシで取得できるようにしたいと考えていました。
維持が容易で、一般化可能なモジュラー形式のエンドツーエンド アーキテクチャ: Digitec は、維持が容易なオープンソース スタックを使用してソリューションを構築することを必要としていました。また、コンテキスト ベースのバンディット モデルをトレーニングして使用するために必要な MLops 機能をすべて備えていることもオープンソース スタックの条件として挙げていました。さらに、モジュラー形式でビルドされており、想定している他のユースケース(ホームページ、Smartag などのレコメンデーションなど)に対しても容易に適用できることも同社にとって重要でした。
前述した各種要件を考慮して状況を改善し、パーソナライズ機能をさらに強化するため、同社は Google にサポートを依頼しました。具体的なリクエストは、機械学習(ML)を活用した、コンテキストに基づくバンディット ベースのレコメンデーション システムを Google Cloud に実装する、というものでした。
コンテキスト ベースのバンディット アルゴリズムは、簡略化された形式の強化学習であり、ウェブサイト訪問者に関する追加情報(コンテキスト)を考慮して、各ユーザーに対してエンゲージメントを最大化するコンテンツを把握し、現実世界における決定を支援するものです。同社は適切に機能しているトレンドを活用し、さらに優れた結果をもたらす可能性を秘めたテスト未実施のトレンドを試すことにも長けていました。たとえば、快適なリビングルーム用のカウチやペット用品を表示できるようにホームページの画像をパーソナライズしているとします。
コンテキスト ベースのバンディット アルゴリズムを採用しない場合は、これらの画像の 1 つがランダムにユーザーに表示され、その際に以前の訪問中に観察したユーザーに関する情報を保有していたとしても考慮されません。コンテキスト ベースのバンディットによって、企業は以前に訪問したページや他の購入アイテムなど、コンテキスト外の情報も検討することができ、最終的な結果(画像をクリックするなど)を観察して何が最適な結果をもたらすかを特定できるようになります。
コンテキスト ベースのバンディットを使用するパーソナライズ システムの作成
Digitec Galaxus は同社のウェブサイトのホームページを大幅にパーソナライズする一方で、非常に多くの機密情報が存在することから、チーム間の連携を強化して更新と変更を行う必要もありました。
Google は Digitec Galaxus のチームと提携して、取り組む範囲を狭め、まずニュースレターを対象とするコンテキスト ベースのバンディット パーソナライズ システムをビルドすることにフォーカスしました。Digitec Galaxus のチームは、ニュースレターに関する決定事項を完全に制御しており、ニュースレターに対してさまざまな ML テストを実施することによって収益に対してマイナスの影響が生じる可能性は、ウェブサイトのホームページの場合と比較して低いと考えられました。
主な目標は、最小限の調整を行うだけで容易にホームページや Digitec が提供する他のサービスに移植できるシステムを構築することでした。ホームページとその他の社内ユースケースにおける機能面と機能面以外の要件を満たすことも必要でした。
以下にニュースレターのパーソナライズ レコメンデーション システムが機能する仕組みを示す図を掲載します。
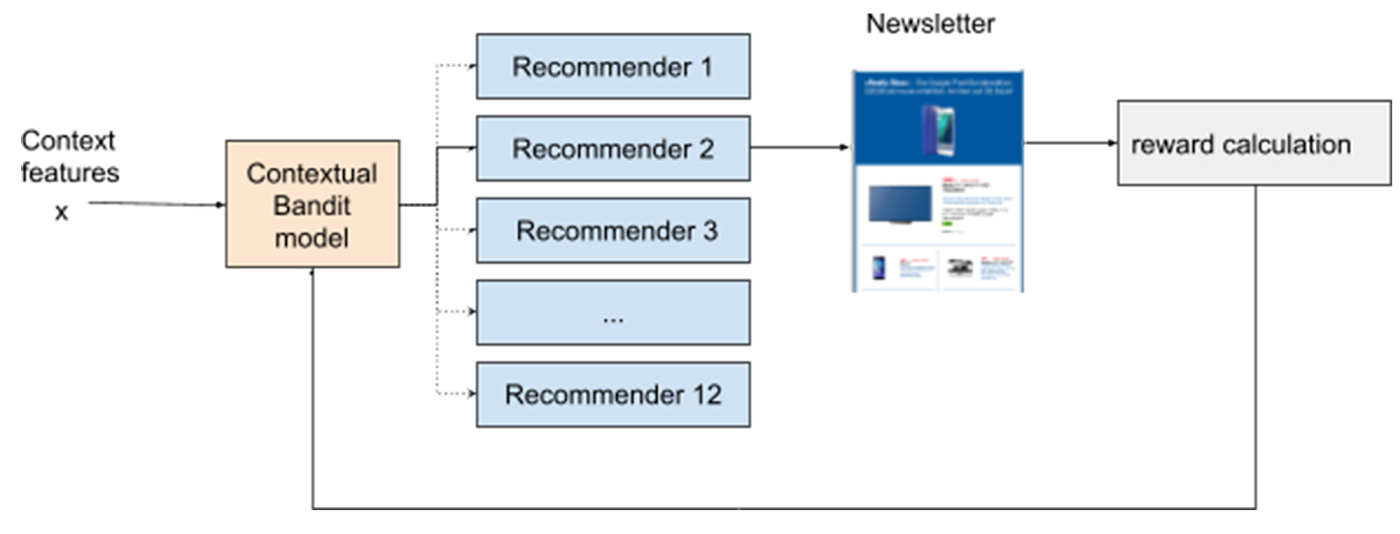
システムに、ニュースレターの登録ユーザーに関していくつかのコンテキスト特徴(購入履歴やユーザー属性など)が提供されます。これらの特徴は、変数または属性と呼ばれることもあり、分析対象のデータによって大きく異なります。
コンテキストに基づくバンディット モデルは、前述のコンテキスト特徴と利用可能な 12 個のレコメンデーション機能(可能性があるアクション)を使用してレコメンデーションをトレーニングします。
モデルは、どのアクションが最も報酬(ユーザーがニュースレターをクリックする)の機会を増大させ、どのアクションが問題(登録解除)を最小化するかを計算します。
クリックの対象がニュースレターか登録解除のどちらであるかを算出することによって、システムはクリック数の増加を目的として最適化を行い、ユーザーに関連性のないコンテンツ(クリックベイト)が表示されることを回避できるようになりました。これによって、Digitec Galaxus は一般的なトレンドを活用する一方で、パフォーマンスの改善につながる可能性のあるトレンドを試すこともできました。
Google Cloud によるサポート体制
コンテキストに基づくニュースレターのパーソナライズ システムは、ML レコメンデーション トレーニングと Google のエコシステム内で利用可能な予測ソリューションを使用して Google Cloud アーキテクチャ上にビルドされました。
使用されているアーキテクチャの概要図を以下に示します。
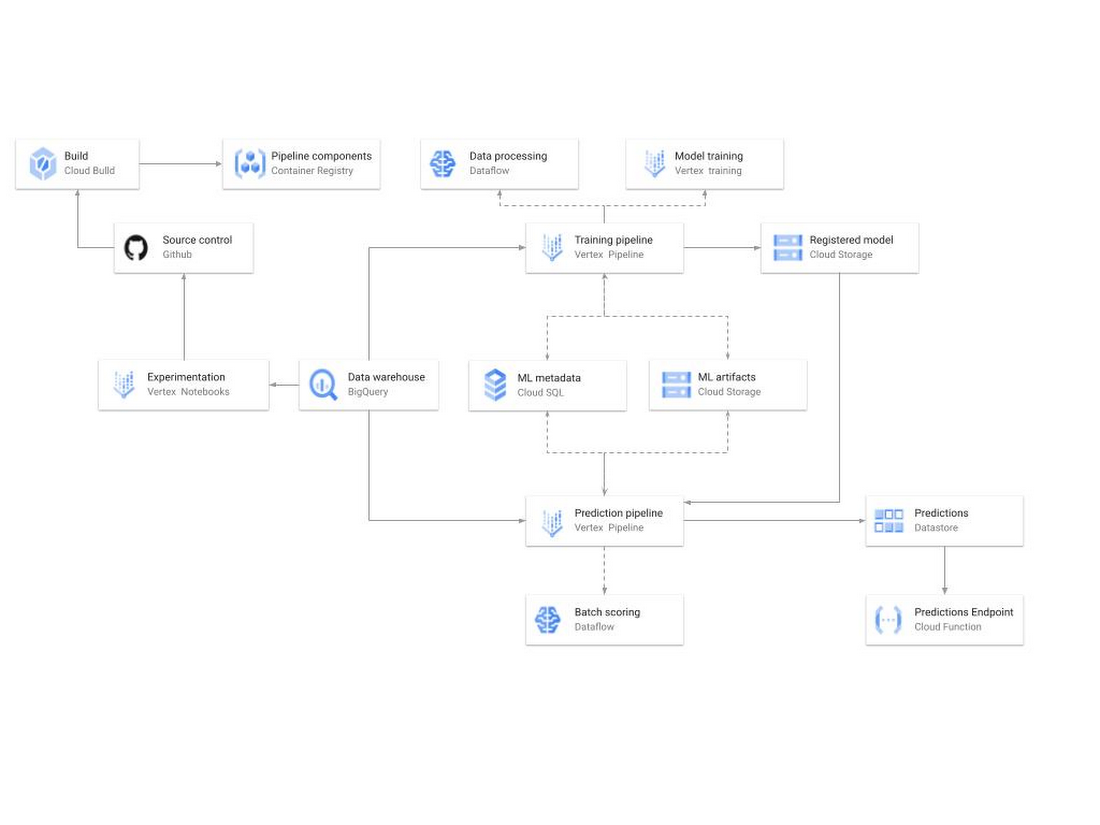
このアーキテクチャは、コンテキストに基づく ML 予測の生成において、次の 3 つの段階に対応しています。
ML の開発: ML のモデルとパイプラインの設計およびビルド
Vertex Notebooks は、テストとプロトタイピングを行うためのデータ サイエンス環境として使用します。Notebooks は、モデル トレーニング、スコアリング コンポーネント、パイプラインを実装するためにも使用します。ソースコードのバージョンは GitHub で制御されます。継続的インテグレーション(CI)パイプラインは、自動的に単体テストを実行し、パイプライン コンポーネントをビルドしてコンテナ イメージを Cloud Container Registry に保存するように設定されています。
ML トレーニング: ML モデルの大規模なトレーニングと保存
トレーニング パイプラインは Vertex Pipelines で実行されます。基本的に、パイプラインは BigQuery から抽出した新しいトレーニング データを使用してモデルをトレーニングし、トレーニングと検証が完了したコンテキスト ベースのバンディット モデルを生成してモデル レジストリに保存します。Google のシステムでは、このモデル レジストリはキュレートされた Cloud Storage です。
トレーニング パイプラインは Dataflow を使用して大規模なデータの抽出、検証、処理、およびモデルの評価を行い、Vertex Training を使用して大規模な分散化されたモデルをトレーニングします。AI Platform パイプラインもさまざまなパイプラインのステップで生成されたアーティファクト、トレーニング モデルの出力を Cloud Storage に保存します。これらのアーティファクトに関する情報は、次に Cloud SQL のメタデータ データベースに保存されます。継続的トレーニング パイプラインをビルドする方法について詳しくは、ドキュメント ガイドをご覧ください。
ML の配信: 本番環境での新しいアルゴリズムとテストのデプロイ
トレーニング パイプラインは、AI Platform パイプラインを通じてバッチ予測によって一度に多数の予測を生成し、Digitec Galaxus が大規模なデータセットをスコアリングできるようにします。生成された予測データは、Cloud Datastore に保存され、使用可能になります。パイプラインは、モデル レジストリに存在する、コンテキストに基づく最新のバンディット モデルを使用して BigQuery 内の推論データセットを評価し、各ユーザーに対して最適なニュースレターをランク付けしたリストを提供して Datastore に保持します。Cloud Functions は、事前に計算された予測データを Datastore から取得するための REST/HTTP エンドポイントとして使用します。
コードとアーキテクチャのすべてのコンポーネントは、容易に使用できるモジュール型のコンポーネントであり、企業内の他の複数のユースケースにも対応できるように適応、調整することが可能です。
数百万件のニュースレターを対象とする予測の改善
ニュースレターの予測システムはまず 2 月に本番環境にデプロイされ、Digitec Galaxus はこのシステムを使用して、毎週 200 万件を超えるニュースレターを登録ユーザー向けにパーソナライズしました。結果はベースラインを 50% 上回るという素晴らしいものでした。ただし、結果をさらに改善するための共同作業は引き続き行われています。
「Google の機械学習エキスパートと直接連携しながらこのレベルの作業を実施することは、私たちにとってまたとない機会です。Digitec Galaxus のレコメンデーションのターゲティングにコンテキストに基づくバンディットを使用することで、ユーザーへの各種レコメンデーション システムの提供をパーソナライズし、まったく新しいアプローチを探求できます。すでに最初のテストでニュースレターについて良好な結果を達成しており、現在はバンディット アームに関するコンテキスト ベースのデータをさらに追加することで、このアプローチの対象をニュースレター全体に拡大するための取り組みを進めています。さらに次のステップとして、ユーザーに対してよりパーソナライズされたエクスペリエンスを実現するために、オンライン ストアにもこのシステムを適用する予定です。このスケーラブルなソリューションを構築するため、TFX や TF Agents などの Google のオープンソース ツールに加えて、Compute Engine、Cloud Machine Learning Engine、Kubernetes Engine、Cloud Dataflow などの Google Cloud サービスを使用しています」 パーソナライズ担当プロダクト オーナー、Christian Sager 氏(Digitec Galaxus)
既存のアーキテクチャとシステムは動的でもあることから、新たなアクション、トレンド、ユーザーに自動的に適応できます。そのため、Digitec Galaxus は同じコンポーネントを再利用して既存のシステムを拡張し、ホームページと企業内で保有するその他の現在のユースケースにおけるパーソナライズを改善するための取り組みを計画しています。システムが柔軟であるため、クリックやユーザー エンゲージメント以外の条件の最適化も将来的に可能です。この取り組みは実に興味深いものであり、今後 Digitec Galaxus がどんなものを構築していくのか非常に楽しみです。
-機械学習シニア スペシャリスト エンジニア Anant Nawalgaria
-機械学習ソリューション アーキテクト スタッフ Khalid Salama





{kind=link}
{kind=link}