Cloud TPU、AI による推論でスケーラビリティの新記録を樹立
Google Cloud Japan Team
※この投稿は米国時間 2019 年 11 月 7 日に、Google Cloud blog に投稿されたものの抄訳です。
MLPerf は ML のパフォーマンスを測定する業界基準ですが、このほど新しい MLPerf Inference ベンチマークの結果が公表されました。これらのベンチマークが示すのは、さまざまなシナリオに基づいて機械学習による予測を行った場合のパフォーマンスです。Google が提出した測定結果を見ると、Google の Cloud TPU プラットホームは機械学習を利用するお客様が絶対に必要とする開発スピード、スケーラビリティ、柔軟性の要件を満たしていることがわかります。
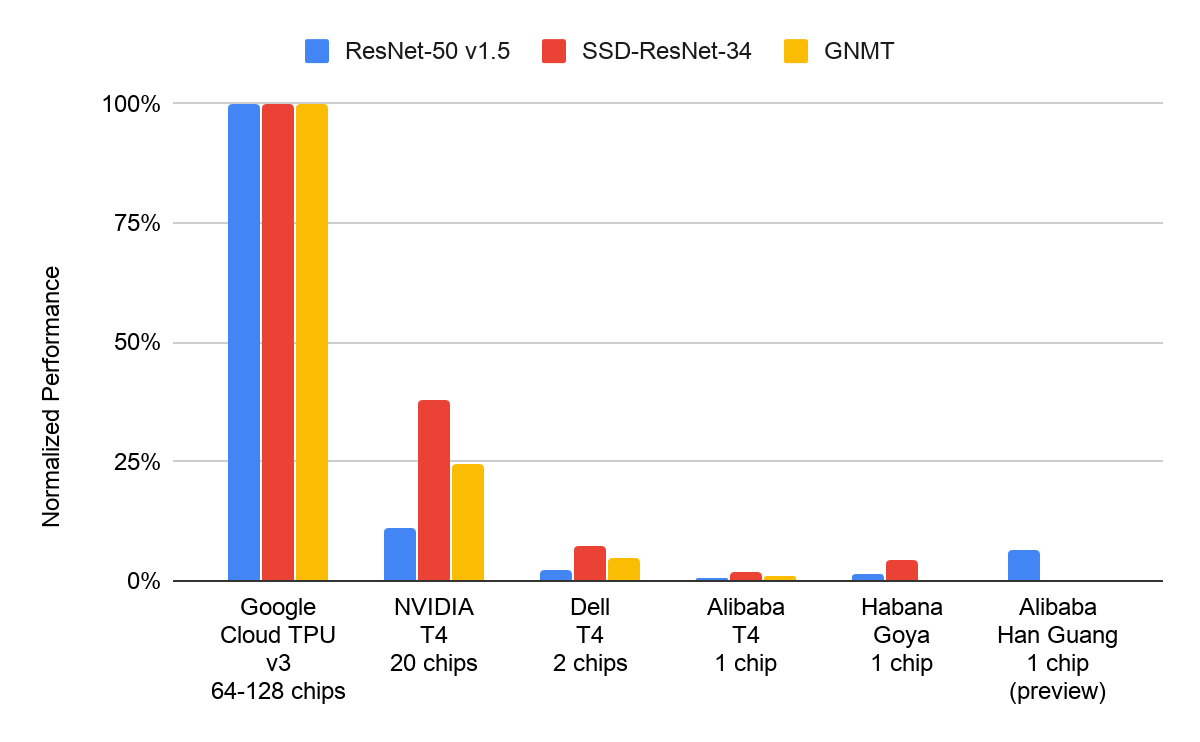
MLPerf Inference v0.5 はデータセンター クラスのベンチマークとして、ResNet-50 v1.5(画像分類)、SSD-ResNet-34(オブジェクト検出)、GNMT(言語翻訳)の 3 つを定義しています。Google は Cloud TPU v3 デバイスを使用して測定したこれら 3 つのベンチマークすべての結果を提出し、ResNet-50 v1.5 に対して 32 個の Cloud TPU v3 デバイスを使用した場合に、1 秒あたりの画像処理件数が 100 万件という記録的な値までほぼ線形にスケールすることを実証しました1。
Cloud TPU は Google Cloud のお客様にベータ版で一般提供されています。この同じ TPU は Google 検索をはじめとする多数の大規模な Google サービスでも使用されています。
開発スピード: トレーニングからサービスへ
Cloud TPU のアーキテクチャは、ML ワークロードをよりシームレスにトレーニングからサービスへと移行できるよう、ゼロから設計されています。Cloud TPU では bfloat16 浮動小数点数値を使用できるため、整数値よりも高い精度が得られます。同じハードウェア プラットホーム上でトレーニングとサービス提供を行うことで、推論時に精度が損なわれる恐れがなくなり、量子化や再較正、再トレーニングの必要もなくなります。これに対し、精度の低い(8 ビットなど)数値を使ったサービスでは難易度が膨大に膨れ上がり、開発者はこれを克服するために多大な労力を注ぐ必要に迫られます。たとえば、モデルを量子化するのに数週間の労力とプロジェクトへのリスクが増える可能性があるうえ、量子化したモデルで元のモデルと同じ精度を常に達成できるとは限りません。推論ハードウェアの導入は ML 開発者の労力軽減につながるため低コストな選択肢です。高精度の ML モデルを提供することで開発スピードが向上すれば、コスト削減と同時にアプリケーションの品質も向上します。
たとえば、TPU v3 プラットホームをトレーニングと推論の両方に使用すれば、Google 翻訳の新しいモデルを、モデルの検証から数時間以内に本番環境にプッシュすることも可能です。これにより、カスタム推論グラフの開発に要していたエンジニアリング時間が不要になり、Google のチームは機械翻訳研究から得られた新たな知見をより短期間で本番環境にデプロイできるようになりました。この同じテクノロジーは Google Cloud のお客様にも提供され、お客様の機械学習チームの生産性向上に貢献しており、コールセンター ソリューション、ドキュメント分類、工業検査、ビジュアル商品検索といった一般的なユースケースの開発のスピードアップを図ることができます。
大規模な推論
機械学習による推論は高度な並列処理であり、入力されるデータ同士に依存関係はありません。MLPerf Inference v0.5 はデータセンターの推論シナリオとして、「オフライン」(大量のバッチデータを一晩で処理するなど)と「オンライン」(リアルタイムでユーザーのクエリに応答するなど)という 2 つの異なるシナリオを定義しています。Google が提出したオフラインの測定結果は大規模な並列処理を活用したものであり、3 つのデータセンター クラスのベンチマークすべてで高いスケーラビリティを示しています。ResNet-50 v1.5 では、Cloud TPU デバイスを 1 個から 32 個まで増やした場合のスケーラビリティがほぼ線形になっています。Google Cloud のお客様は、推論に対する固有のニーズをこの MLPerf の結果を使用して評価したうえで、それぞれの推論の要件に最適な Cloud TPU ハードウェア構成を選択することが可能です。

クラウドの柔軟性: オンデマンド プロビジョニング
企業の推論ワークロードではアクセラレータ リソースの需要レベルが時間によって変動します。Google Cloud は、変動する需要に適応するための柔軟性を備えており、コストを最小限に抑えながら、リソースのプロビジョニング / プロビジョニング解除を自動的に実行します。Google Cloud を使用する場合は、処理対象が社内チームによる散発的なクエリなのか、世界各地で行われる毎秒数千件にものぼるクエリなのか、毎晩実行される巨大なバッチ推論ジョブなのかに関係なく、需要に見合った最適な量のハードウェアだけを所有できるため、リソースを遊ばせて無駄が発生するということがほとんどありません。
たとえば、MLPerf Inference v0.5 Closed に対して提出した Cloud TPU による ResNet-50 v1.5 オフラインの測定結果によると、わずか 32 個の Cloud TPU v3 デバイスで毎秒合計 100 万件以上の画像を処理できます。この規模とスピードがどのくらいかというと、地球上にいる 77 億人全員がそれぞれ 1 枚の写真をアップロードしたとしても、この地球規模のフォト コレクション全体を 2.5 時間未満で分類できるほどです。しかも、600 ドルにも満たないコストでこれを実現できてしまいます。これほどのパフォーマンスと柔軟性と低価格で企業ユーザーの機械学習ニーズに応えられるのは Google Cloud だけです。
今すぐ利用を開始
Cloud TPU は今やトレーニングと推論の両方で新記録を樹立しています。Google Cloud は企業向けの幅広い推論ソリューションを提供しており、選択できる GPU と Cloud TPU の種類も豊富です。たとえば、量子化したモデルを使った推論には、抜群のコスト パフォーマンスを誇る NVIDIA T4 GPU もご利用いただけます。
Google Cloud のお客様は、高速化された ML 推論を今すぐご利用いただけます。何か月もかけてオンプレミスの ML ハードウェア クラスタを構築する必要はありません。最新のディープ ラーニング ワークロードを中心にビジネスを展開するお客様の場合は、Cloud TPU または GPU のクイックスタート ガイドに沿って Google の ML アクセラレータ プラットホームの知識を習得することをおすすめします。
- by TPU テクニカル プログラム マネージャー、Pankaj Kanwar
1.MLPerf v0.5 Inference Closed オフライン; www.mlperf.org に 2019 年 11 月 6 日付で掲載されたエントリ、Inf-0.5-20 から取得したものです。MLPerf の名称とロゴは商標です。詳細については、www.mlperf.org をご覧ください。
*2.MLPerf v0.5 Inference Closed オフライン; www.mlperf.org に 2019 年 11 月 6 日付で掲載されたエントリ、Inf-0.5-19、Inf-0.5-20、Inf-0.5-26、Inf-0.5-2、Inf-0.5-1、Inf-0.5-21、Inf-0.5-31 からそれぞれ取得したものです。MLPerf の名称とロゴは商標です。詳細については、www.mlperf.org をご覧ください。
*3.MLPerf v0.5 Inference Closed オフライン; www.mlperf.org に 2019 年 11 月 6 日付で掲載されたエントリ、Inf-0.5-15、Inf-0.5-16、Inf-0.5-17、Inf-0.5-18、Inf-0.5-19、Inf-0.5-20 からそれぞれ取得したものです。MLPerf の名称とロゴは商標です。詳細については、www.mlperf.org をご覧ください。


