Cloud TPU Pods break AI training records
Zak Stone
Senior Product Manager for Cloud TPUs, Google Brain Team
Google Cloud’s AI-optimized infrastructure makes it possible for businesses to train state-of-the-art machine learning models faster, at greater scale, and at lower cost. These advantages enabled Google Cloud (GCP) to set three new performance records in the latest round of the MLPerf benchmark competition, the industry-wide standard for measuring ML performance.
All three record-setting results ran on Cloud TPU v3 Pods, the latest generation of supercomputers that Google has built specifically for machine learning. These results showcased the speed of Cloud TPU Pods— with each of the winning runs using less than two minutes of compute time.
AI-optimized infrastructure
With these latest MLPerf benchmark results, Google Cloud is the first public cloud provider to outperform on-premise systems when running large-scale, industry-standard ML training workloads of Transformer, Single Shot Detector (SSD), and ResNet-50. In the Transformer and SSD categories, Cloud TPU v3 Pods trained models over 84% faster than the fastest on-premise systems in the MLPerf Closed Division.
The Transformer model architecture is at the core of modern natural language processing (NLP)—for example, Transformer has enabled major improvements in machine translation, language modeling, and high-quality text generation.
The SSD model architecture is widely used for object detection, which is a key part of computer vision applications including medical imaging, autonomous driving, and photo editing.
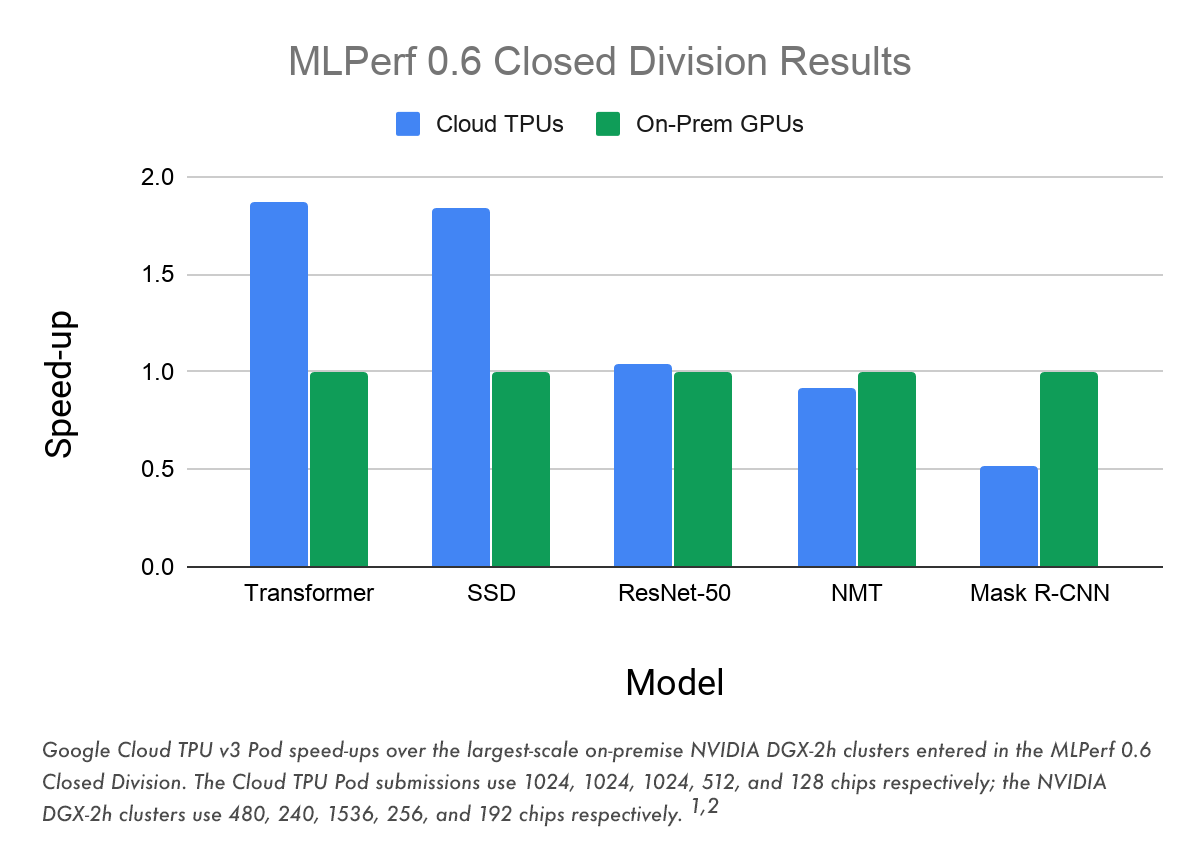
To demonstrate the breadth of ML workloads that Cloud TPUs can accelerate today, we also submitted results in the NMT and Mask R-CNN categories. The NMT model represents a more traditional approach to neural machine translation, and Mask R-CNN is an image segmentation model.
Scalable
GCP provides customers the flexibility to select the right performance and price point for all of their large-scale AI workloads. The wide range of Cloud TPU Pod configurations, called slice sizes, used in the MLPerf benchmarks illustrates how Cloud TPU customers can choose the scale that best fits their needs. A Cloud TPU v3 Pod slice can include 16, 64, 128, 256, 512, or 1024 chips, and several of our open-source reference models featured in our Cloud TPU tutorials can run at all of these scales with minimal code changes.

Get started today
Our growing Cloud TPU customer base is already seeing benefits from the scale and performance of Cloud TPU Pods. For example, Recursion Pharmaceuticals can now train in just 15 minutes on Cloud TPU Pods compared to 24 hours on their local GPU cluster.If cutting-edge deep learning workloads are a core part of your business, please contact a Google Cloud sales representative to request access to Cloud TPU Pods. Google Cloud customers can receive evaluation quota for Cloud TPU Pods in days instead of waiting months to build an on-premise cluster. Discounts are also available for one-year and three-year reservations of Cloud TPU Pod slices, offering businesses an even greater performance-per-dollar advantage.
Only the beginning
We’re committed to making our AI platform—which includes the latest GPUs, Cloud TPUs, and advanced AI solutions—the best place to run machine learning workloads. Cloud TPUs will continue to grow in performance, scale, and flexibility, and we will continue to increase the breadth of our supported Cloud TPU workloads (source code available).To learn more about Cloud TPUs, please visit our Cloud TPU homepage and documentation. You can also try out a Cloud TPU for free, right in your browser, via this interactive Colab that applies a pre-trained Mask R-CNN image segmentation model to an image of your choice. You can find links to many other Cloud TPU Colabs and tutorials at the end of our recent beta announcement.
1. MLPerf v0.6 Training Closed. Retrieved from www.mlperf.org 10 July 2019. MLPerf name and logo are trademarks. See www.mlperf.org for more information.
2. MLPerf entries 0.6-6 vs. 0.6-28, 0.6-6 vs. 0.6-27, 0.6-6 vs. 0.6-30, 0.6-5 vs. 0.6-26, 0.6-3 vs. 0.6-23, respectively.
3. MLPerf entries 0.6-3, 0.6-4, 0.6-5, 0.6-6, respectively, normalized by entry 0.6-1




